始めに
株式会社松尾研究所インターン生の水口です。本稿では、生成AI(ChatGPTなど)の進化を支える技術の一つ、「自己教師あり学習(Self-Supervised Learning: SSL)」について概観します。本節では、簡単に背景をお伝えします。
まず従来の機械学習の分野では、入力(データ)とそれに対応する出力(ラベル)のペアを用いる「教師あり学習」が広く利用されてきました。例えば、画像(データ)そのもののクラス(ラベル)を判定する分類タスクや、時系列(データ)から将来の値(ラベル)を見積もる回帰タスクなど、各タスクごとに正確なラベルが必要とされます。
現在の生成AIについては、モデル規模・計算資源・データの質と量を総合的に拡大することで性能が向上するというスケーリング則が経験的に確認されており、モデルの学習に大規模なデータセットを用いることが多いです。入力データに関しては、インターネットやセンシングデバイスなどの技術発展に伴い、膨大な数を収集・活用できるようになっています。しかし、そのデータに対する正確なラベル付けは、大きな手間やコストがかかることがあり、ラベル付きのデータの活用は、規模に関する課題に直面していました。
(ラベルの例:医療診断ではデータに対する医師からの診断結果、動画から顔の検出では、フレームごとのアノテーション(ラベル付け)など。)
こうした状況下で注目されているのが「自己教師あり学習(Self-Supervised Learning, SSL)」です。自己教師あり学習は、ラベルのないデータでもモデルの学習に活用できる手法として期待を集めています。次節以降では、自己教師あり学習の概要や代表的なアプローチ、さらにどのような領域で役立てられているのかを順に見ていきます。
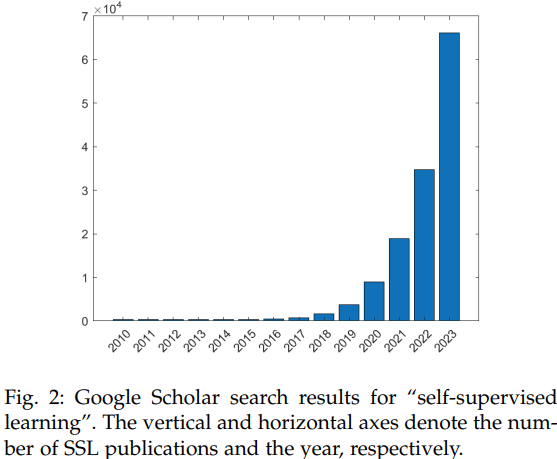
Google Scholarでの"自己教師あり学習"の検索結果(出典:[1])
自己教師あり学習とは
自己教師あり学習 (Self-Supervised Learning, SSL) とは、「外部からのラベルに依存せずに、データそのものからラベルやタスクを作成し、学習を行うパラダイム」のことを指します(Kumar et al., 2024)。
自己教師あり学習は、人手によるラベルを使わずに、有用な特徴を抽出する方法を学習できる(Shwartz-Ziv & LeCun, 2023)ため、真に解きたいタスクの事前準備として幅広く活用されています。そのため、自己教師あり学習におけるタスクは、Pretext taskと呼ばれることが一般的です。
以下にて、詳細をご紹介します。
自己教師あり学習の適用のパイプラインは、主に次の2つのフェーズに分けられます。
-
事前学習 (Pre-training) フェーズ
- 大量のラベルなしデータを用いて、Pretext taskを解かせる形で学習し、データの内在的な特徴表現を抽出する方法を学ぶ(特徴抽出器・エンコーダーを訓練させる)。自己教師あり学習は、この事前学習部分に利用されます。
-
下流タスク (Downstream Task) フェーズ
- 画像分類・物体検出・医療診断・レコメンドなど、実際に解きたいタスク・下流タスクに合わせて、事前学習で得た特徴抽出器(エンコーダー)を活用し、ラベル付きデータを用いた追加の学習・チューニングを行う。
1のフェーズで訓練されたエンコーダーにより抽出された表現は、様々なタスクに利用できる汎用性やノイズ等に対する堅牢性を持つことが確認されており、下流タスクを実行する際に、効果的に活用されます(Ericsson et al., 2020; Hendrycks et al., 2019)。
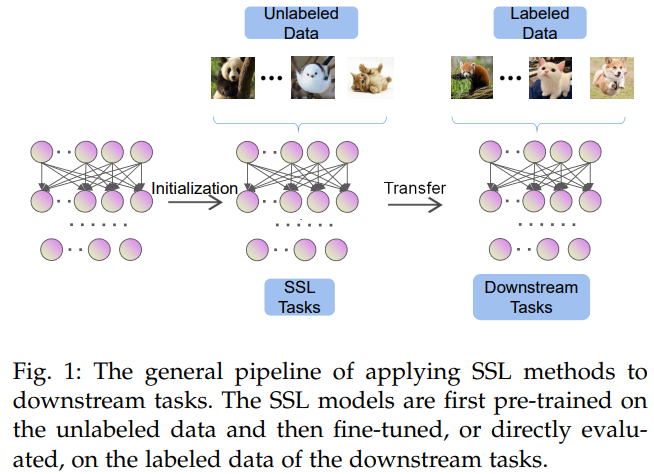
自己教師あり学習適用のパイプライン(出典:[1])
コラム:自己教師あり学習と教師あり学習と教師なし学習
自己教師あり学習は教師あり学習とは異なり、下流タスクを行うためのラベルを必要としないという点で、教師なし学習のサブクラスとしてみなせます。しかしながら、自己教師あり学習は、データそのものから教師信号(疑似的なラベルやタスク)を作成するという点で、教師なし学習とは区別されています(Jing & Tian, 2019)。
様々な学習手法
自己教師あり学習では、非常に多くの手法が提案されています。ここでは、主要なアプローチである、生成的(Generative)アプローチと対照的(Contrastive)アプローチを簡単にご紹介します。さらに詳しく知りたい方は、自己教師あり学習のサーベイ論文(Liu et al., 2020; Gui et al., 2023)などから、確認してみてください。
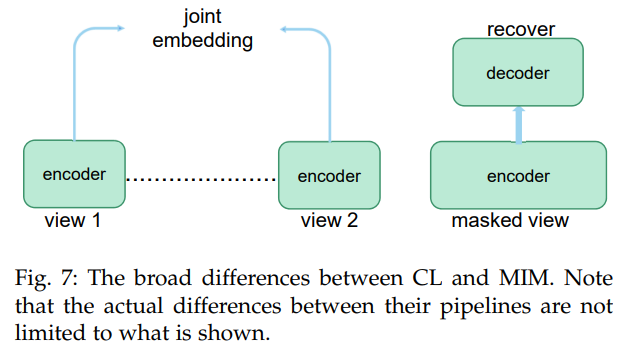
左は対照的アプローチの概要図
右は生成的アプローチの代表例、Masked Image Modelingの概要図(出典:[1])
1. 生成的(Generative)自己教師あり学習
生成的自己教師あり学習では、特徴表現を抽出するニューラルネットワーク(エンコーダー)に対して、元データ(あるいは、それに加工を加えたもの)を入力し、その後得られた表現に対して、もう一つの比較的軽量なニューラルネットワーク(デコーダー)を働かせることで、元データの再構成を試みます。この一連の流れを上手くこなせるように、モデルを訓練させると、エンコーダーはデータのみから、重要な内在的表現を抽出する役割を獲得します。
-
Masked Autoencoder (MAE), CVPR2022
画像の一部にマスクをかけた状態でエンコーダーに入力し、マスクされた部分を再構成するタスクで学習する手法です (He et al., 2022)。このシンプルな仕組みによって、入力画像が持つ内在的なパターンを学習し、有用な特徴表現を獲得できることがわかっています。(Kong et al., 2023)。

Masked Autoencoderの概要図(出典:[2])
2. 対照的(Contrastive / JEA)自己教師あり学習
この方法では、まず各入力データに対して、異なる変換(例:画像の回転や一部の切り取り等)を施したペア(正例ペア)を作成します。そして、変換が行われた各データに対して、それぞれ特徴抽出器(エンコーダー)を働かせ、抽出・作成された表現を近づけるようにするなどして、学習を行います。データが内在的に持つ、変換に対する不変的な表現や特徴を捉えられる方法になっており、シンプルな手法から多種多様な変種が存在します(Grill et al., 2020; Caron et al., 2020; Chen & He, 2021)。このアプローチは、対照学習あるいはJEA(Joint Embedding Architecture)とも知られています。
-
A Simple Framework for Contrastive Learning of Visual Representations (SimCLR), ICML2020
この手法では、同一画像から得られる異なる変換を施した結果・正例ペアと、他の画像から得られる拡張結果・負例ペアを用意します。その後、ペアの各画像に対して、エンコーダーやプロジェクターと呼ばれるニューラルネットワークを働かせます。こうして得られた表現について、正例ペア同士を近づけ、負例ペア同士を離すように学習を行い、ラベルなしのデータから意味的特徴を獲得します(Chen et al., 2020)。

左図:対照的自己教師あり学習の概要図(出典1:[3])
右図:SimCLRの概要図(出典2:[4])
自己教師あり学習の特徴
自己教師あり学習の本質は、データが内在的に持つ本質的な特徴や構造・パターンを明らかにし、ラベル情報に依存しない有用な表現を抽出することにあると考えられます。ここで「有用な表現」とは、タスク実行の性能向上に効果的である、あるいは様々なタスクに汎用的に活用できることを指しています(Bengio et al., 2012)。
データが複雑なパターンを示すように見えても、本質的な情報は低次元でシンプルに表現できることが多く(Bengio & LeCun, 2007)、大体のSSLのアルゴリズムは、データから様々なタスクに役立つ情報を保持・抽出したり、冗長な表現を圧縮したりする設計になっています(Shwartz-Ziv & Tishby, 2017; Shwartz-Ziv & LeCun, 2023)。
自己教師あり学習の利点
-
ラベルなしの大規模データを有効に活用できる。
これまでの研究によって、事前学習のデータ規模が大きくなると、下流タスクの性能が向上すること(スケーリング則)が観察されています(Kaplan et al., 2020; Hernandez et al., 2021; Zhai et al., 2021; Cherti et al., 2022)。(これについては、十分にデータ分布をカバーすると、不可避な誤差の下限に近づいて性能が飽和するという話もあります。(Bahri et al.,2024))
ラベルを持つデータが少ない場合においては、自己教師あり学習は非常に有用なアプローチの内の一つといえるでしょう。 -
データの特徴を捉えた表現を抽出したり、不要な情報を圧縮したりすることで、様々な下流タスクへの応用や、ドメインシフトへの対応ができる汎用的な表現を獲得しうる。
自己教師あり学習による事前学習を活用すると、下流タスクに依存しない有用なデータの表現を獲得でき、モデルの多様なタスクに対する転用可能性やドメインシフトに対する汎化性能を高められます。
この特性は時系列タスクでも有効に働き、ノイズや欠損を含む複雑な時系列データに対しても予測性能を向上させる(Wang et al., 2022; Shao et al., 2022)ほか、予測・分類・異常検知・欠損補完など幅広いタスクにも効果的であるような、汎化能力を向上させることが観察されています(Senane et al., 2024)。
事前学習の観点から見る自己教師あり学習
事前学習として、ラベル付きの他データセットを活用した教師あり学習を行うことも可能です。このアプローチを含む事前学習における各種手法は、事前学習と下流タスクにおける、タスクの性質、データセットの規模、分布に応じて、得手不得手が存在します(Yang et al., 2020)。
例えば、教師あり学習はタスクに直結した特徴抽出方法を学習するため、事前学習時のタスクと下流タスクのドメインやタスク形式がとても近い場合に、有効になる傾向があります。一方、そうではない場合においては、自己教師あり学習が汎用的な特徴を捉えやすいため、より高い性能を発揮する傾向にあります。さらに、近年の研究では、教師あり学習が得意とされる領域においても、自己教師あり学習がそれに匹敵する性能を示す例が報告されています。(Tomasev et al., 2022)
また、自己教師あり学習の手法間の違いに着目すると、各手法ごとに固有のバイアスが存在し、全てのタスクにおいて一貫して最良の結果をもたらす手法はないことが示されています(Ericsson et al., 2020; Kotar et al., 2021; Huang et al., 2025)。
従って、実際に利用する際には、状況に応じて適切なアプローチや手法を選択する必要があります。
自己教師あり学習の活用例
自己教師あり学習の応用分野は拡大しており、その活用事例の数も非常に増してきています。本稿では、自己教師あり学習の様々な応用分野を挙げると共に、2024年の国際会議にて発表された、身近な活用事例を二つご紹介します。
様々な応用分野
- 交通流、金融などの時系列データ解析(Zhang et al., 2023)
- 推薦システム(Yu et al., 2022)
- 自然言語処理(Devlin et al., 2018)
- コンピュータビジョン(Jing & Tian, 2019, Schiappa et al., 2022)
- 医療健康(Spathis et al., 2022)
- ロボティクス(Nair et al., 2022)
- リモートセンシング(Wang et al., 2022)
- 自然科学(蛋白質の機能予測(Rives et al., 2021)、分子の物性予測(Rong et al., 2020))
活用事例
-
画像を利用した自己教師あり学習 - 子供の絵画の美的評価 - AAAI2024
Jiang et al., 2024
子供の絵画の美的評価は芸術教育における重要な要素となっており、子どもの認知過程や芸術的能力をより包括的に理解する手がかりとなります。この研究では、子供の絵画についてラベルなしのもの2万点以上と、専門家が評価したラベル付きのもの1200点を利用しています。事前学習では、ラベルなしデータでマスク再構成(ConvMAE(Gao et al. 2022))に類似したマスキング画像の再構成を行い、その後、専門家による8項目の評価スコアを推定する下流タスクを実行しています。これにより、ラベル付きデータが限られた状況でも、高精度かつ安定的な、評価の推定を実現しました。
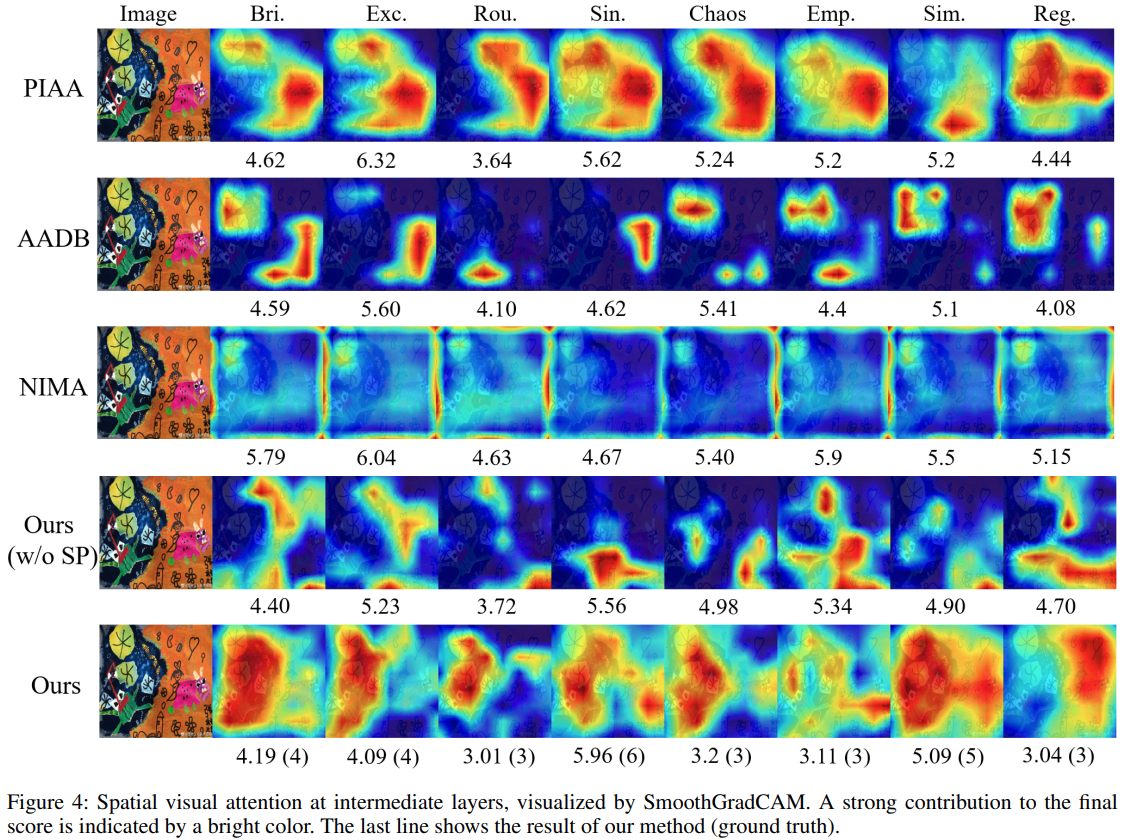
ある画像に対する各種手法の評価推定値と注意を向けた箇所の比較(真の値は()に表示)(出典:[5] )
-
ウェアラブルデータ・PPG&ECGを利用した医療健康大規模基盤モデルの形成 - ICLR2024
Abbaspourazad et al., 2024
PPGは動脈血流の体積変化を、ECGは心臓の電気活動を表します。これらの生体信号には大きな利用可能性がありますが、モデルの構成に必要な、専門家によるラベル付けには多大なコストがかかります。一度、生体信号の基盤モデルが開発されれば、医療モデル訓練時のラベル付きデータの必要量を減らせたり、下流タスクの性能を向上させたり、計算リソースを削減できたりするなどのメリットがあります。
この研究では14.1万人の参加者から得られた生体信号データから、対照的SSLでモデルを訓練させ、健康状態を予測するような下流タスクの性能向上に寄与しています。正例は同じ参加者のセグメントデータにデータ拡張(Iwana & Uchida, 2021)を行ったものとしています。
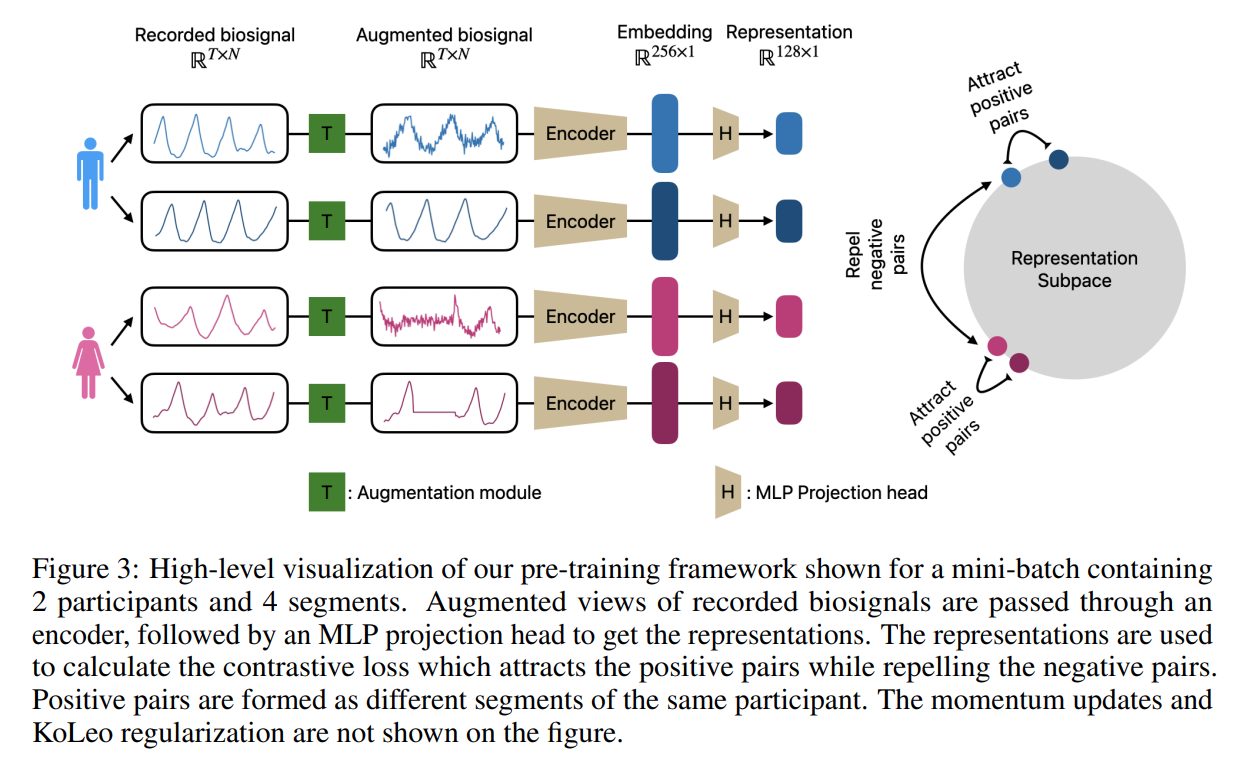

上図:この研究の事前学習の概要図
下図:各種項目線形分類におけるROC AUC
(縦軸:生体信号の埋め込み表現を利用、横軸:ベースラインとなる特徴量を利用)(出典:[6])
終わりに
ここまで、自己教師あり学習の概要、最近の活用例の紹介についてお話してきました。
本稿では取り挙げることができませんでしたが、自己教師あり学習の「下流タスクに依らない汎用的な表現を獲得できる」という利点には、もう一つ重要な側面があると考えています。この特性は、様々な情報源(モダリティ)からの情報・表現を上手く抽出・活用(固有表現の分離、共通表現の抽出、あるいはそれらの効果的な融合)することに役立つと考えられ、人間のような知的活動が行える汎用人工知能(Artificial General Intelligence, AGI)の実現に貢献するかもしれません。
最後になりますが、少ないラベル付きデータ下での活用という観点や、データからの汎用的な表現抽出という観点で、自己教師あり学習は今後さらに活用されていく技術になると感じています!ぜひ、この記事や他の媒体をきっかけに、自己教師あり学習について興味を持っていただけると幸いです。
最後までご覧いただきありがとうございました!
出典
[1] J. Gui et al., “A Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends,” arXiv:2301.05712 [cs.LG], 2023. Available: https://arxiv.org/abs/2301.05712.
[2] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked Autoencoders Are Scalable Vision Learners,” arXiv:2111.06377 [cs.CV], 2021. Available: https://arxiv.org/abs/2111.06377.
[3] H. Wang et al., “Scientific discovery in the age of artificial intelligence,” Nature, vol. 620, no. 7972, pp. 47–60, Aug. 2023. doi: https://doi.org/10.1038/s41586-023-06221-2.
[4] X. Chen and K. He, “Exploring Simple Siamese Representation Learning,” arXiv:2011.10566 [cs.CV], 2020. Available: https://arxiv.org/abs/2011.10566.
[5] S. Jiang, N. Li, C. Shi, L. Guo, C. Wang, and C. Li, “AACP: Aesthetics assessment of children’s paintings based on self-supervised learning,” arXiv:2403.07578 [cs.CV], 2024. Available: https://arxiv.org/abs/2403.07578.
[6] S. Abbaspourazad, O. Elachqar, A. C. Miller, S. Emrani, U. Nallasamy, and I. Shapiro, “Large-scale Training of Foundation Models for Wearable Biosignals,” arXiv:2312.05409 [eess.SP], 2023. Available: https://arxiv.org/abs/2312.05409.

Discussion