こんにちは、9月から松尾研究所でシニアデータサイエンティストをしている北です。
本記事は、松尾研究所 Advent Calendar 2025の記事です。
近年、Computer Use Agent(CUA)の研究や評価手法が急速に整備されつつあり、新しいモデルの性能がベンチマークとともに語られる機会が増えてきました。しかし、それぞれのベンチマークが測定している能力や前提条件を正しく理解しておかないと、評価結果から業務での適用可能性を判断することは難しいと感じています。
実際に、業務プロセスのどの部分をCUAが代替できるのか、またどこに限界があるのかを見極めることは、エージェント開発に携わる立場として重要です。そのため、まずは既存のベンチマークを俯瞰し、それらが何を測り、どのように読み解けるのかを整理する目的で本記事を書きました。
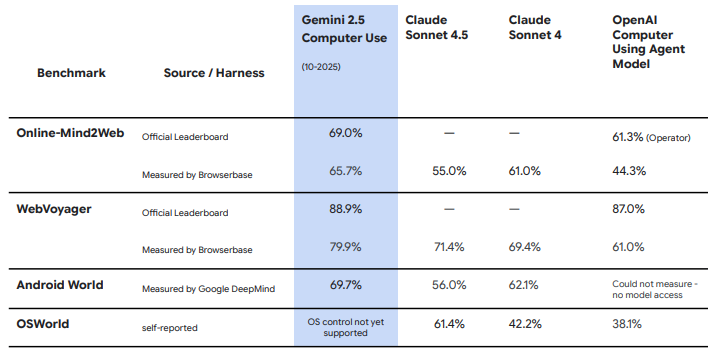
こういった比較表を見た際の理解度を上げたい!というのが本記事のモチベーションです (Gemini 2.5 Computer Useのモデルカードから引用)
WebArena[1]
WebArenaは、AIエージェントが現実的かつ再現性のあるWeb環境でタスクを遂行できるかを測るために設計されたベンチマークです。
特徴としては次の通りです:
- GitLabやReddit等のWebアプリのクローンをDocker上で動作させ、決定論的な評価を可能にする
- テキスト一致ではなく、タスク実行後のデータベース状態を確認する「機能的正しさ(Functional Correctness)」を評価指標とする
- 長期タスク(long-horizon tasks)を含み、計画性と正確な操作が要求される
論文中のタスク例:
Create an efficient itinerary to visit all of Pittsburgh's art museums with minimal driving distancestarting from Schenley Park. Log the order in my “awesome-northeast-us-travel” repository”
安定した(画面構成や手順が一定の)Webアプリでの確実な操作に適したベンチマークと言えます。
WebVoyager[2]
WebVoyagerは、静的なスナップショットではなく、実際のオンラインWebサイト上でエージェントを動作させるマルチモーダルなベンチマークです。
- Amazonなど15の実在Webサイト上でタスクを実行。動的なコンテンツやポップアップなどの現実的な課題を含む評価が可能
- 人手評価のコストを抑えるためLLM-as-a-judgeを採用。エージェントの操作軌跡とスクリーンショットをGPT-4Vに入力し、タスクの成否を判定させる自動評価プロトコルを導入した
- DOM情報に依存しない、視覚的情報(スクリーンショット)を用いた操作を評価可能
タスク例:
Search Apple for the accessory Smart Folio for iPad and check the closest pickup availability next to zip code 90038.

上記タスクをエージェントが6つのステップで解決する様子(WebVoyagerの提案論文より引用)
特定の店舗の在庫など、シミュレーション環境では再現しづらいリアルタイムな情報取得が要求されるタスクです。
Online-Mind2Web[3]
WebVoyager等の既存ベンチマークはタスクが単純でGoogle検索だけで解決可能なものも多く、自動評価の信頼性も低いという問題がありました。Online-Mind2Webは、エージェントの性能に対する過度な楽観視("illusion"であると指摘)を正す、より多様で厳密なタスク設定と信頼できる評価手法として開発されました。
- 136サイトにまたがる300のタスクからなる多様で現実的なタスクセット
- Google検索だけで達成できるようなショートカット可能なタスクを排除し、実際にウェブサイト内の探索や操作が必要な難易度の高いタスクを選定
- Web上の複雑な操作(画像編集、フィルタリング、フォーム作成など)が多数
- LLM-as-a-judge手法「WebJudge」を開発。人間の判断との一致率を約85%まで向上
実際のタスクとしては、サイト上の複雑な機能を正しく操作しなければ正解に辿り着かないようなものが見られます。
Create a meme with a frog as the background and leave the only text “Enjoy your life.” (imgur.com)
ベンチマークの読み解き方:業務タスクとの対応付け
3つのベンチマークは、それぞれ異なる能力を測定しています。業務タスクと照らし合わせて、次のように整理しました。
| ベンチマーク | 主に測っている能力 | 対応する業務の例 |
|---|---|---|
| WebArena | 安定したWebサイト上でのタスク遂行、機能的正確性、長期計画 | ・CMSを用いたコンテンツ管理 ・カスタマーサポート、フォーラム管理 |
| WebVoyager | 視覚的理解、ライブウェブ適応、主要なサイトの操作 | ・市場調査、勾配代行 ・ニュースモニタリング |
| Online-Mind2Web | 広いドメインへの対応、複雑な操作を含むタスクの遂行、視覚理解 | ・物件等の複雑な調査 ・クリエイティブ作成等のSaaSを用いた業務 |
モデルのスコアを確認する際には、どのベンチマークが自分たちの業務タスクと近い性質を持っているかを意識すると、結果を解釈しやすくなると感じています。
既存ベンチマークの限界
現在のベンチマークを見ると、評価できている領域と、まだ十分に扱われていない領域があるようです。
測れている能力
- ゴールの意図理解
- UIの構造・視覚的特徴の把握
- 数ステップ〜十数ステップ規模の手順を実行する能力
- 変化する実サイトへの適応
まだ測りきれていない能力
- 失敗からのリカバリー(誤遷移や操作ミスからの立て直し)
- 安全性・リスク感度(削除・送信などの高リスク操作の扱い)
- 計画の透明性・説明可能性
- 人との協働
特に「人との協働」については、現状のベンチマークの多くが人の介入なしで最後まで自動実行する前提で設計されています。しかし、実際の業務では、
- わからない部分を人に確認する
- 危険な操作の前にレビューを求める
といった利用シナリオが自然に発生します。
個人的には、「CUAが人と協働しながらタスクを進められるか」を評価できる枠組みが、今後出てきてもよいのではないかと考えています。WebVoyagerで評価をLLMが代替したように、CUAとのインタラクションをLLMが代替するベンチマークが登場するかもしれません。
まとめ
本記事では、Computer Use Agent(CUA)の代表的なベンチマークであるWebArena、WebVoyager、Online-Mind2Webを取り上げ、それぞれの狙いと特性、業務適用を考えるうえでの読み解き方を整理してみました。
- WebArena:安定したWebアプリでの正確な操作
- WebVoyager:視覚理解・探索力・変化への適応
- Online-Mind2Web:現実タスクに近いより複雑な操作
一方で、失敗からの復帰、人との協働、安全性、説明可能性など、実務で求められる能力の多くはまだ十分にカバーされていないと言えそうです。
また今回はWeb系に議論が偏りましたが、業務自動化を考えるとOSWorld[4]のように複数アプリケーションを横断するタスクを扱うベンチマークも重要になってきます。
今後もベンチマークは技術進歩や利用シーンの変化に応じて再定義され続けるはずです。モデルの進化とともに、ベンチマークの進化も継続的にウォッチしていきたいと思います。
-
WebArena: A Realistic Web Environment for Building Autonomous Agents ↩︎
-
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
↩︎ -
An Illusion of Progress? Assessing the Current State of Web Agents ↩︎
-
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments ↩︎

Discussion