本記事は、「Google Cloud」を用いた「LLM・生成AI活用型アプリケーション」の実装スキルを身につけるための学習方法と学習コンテンツの紹介・解説シリーズの最終記事、「上級編」となります
執筆:小川 雄太郎
本シリーズは「初級編」、「中級編」、「上級編」の計3記事から構成されています
本シリーズの概要
シリーズ第1回の「初級編」はこちらです -> 初級編へ
シリーズ第2回の「中級編」はこちらです -> 中級編へ
シリーズ最終回の「上級編」は本記事となります
本シリーズの目次
「章のタイトル」に英語表記が多いですが、基本的には日本語での学習コンテンツです
| No. | Lv. | 章のタイトル |
|---|---|---|
| 01 | 初級 | Google Cloud Skills Boost とは |
| 02 | 初級 | Introduction to Vertex AI Studio |
| 03 | 初級 | Prompt Design in Vertex |
| 04 | 初級 | Vector Search and Embeddings |
| 05 | 初級 | Explore Generative AI with the Vertex AI Gemini API |
| 06 | 初級 | Vertex AI Gemini 1.0 Pro を活用してアプリを開発する |
| 07 | 中級 | 生成AIモデルの選定とMLモデルのトレーニング手法 |
| 08 | 中級 | Build and Deploy Machine Learning Solutions on Vertex AI |
| 09 | 中級 | Inspect Rich Documents with Gemini Multimodality and Multimodal RAG |
| 10 | 中級 | Develop GenAI Apps with Gemini and Streamlit |
| 11 | 上級 | Build Generative AI Agents with Vertex AI and Flutter |
| 12 | 上級 | Integrate Search in Applications using Vertex AI Agent Builder |
| 13 | 上級 | BigQueryでの生成AI・Geminiの活用手法(Gemini in BigQuery) |
| 14 | 上級 | Build LangChain Applications using Vertex AI |
| 付録 | 上級 | GenAI journey図 と GenOpsの解説 |
本記事では「上級編」として、No. 11~No.14 および付録のコースについて、紹介と解説を実施します
11. Build Generative AI Agents with Vertex AI and Flutter
| コンテンツ名 | |
|---|---|
| コース名 | Build Generative AI Agents with Vertex AI and Flutter |
| スライド | Introduction |
| モジュール |
Flutter, Gemini, and Vertex AI (概要)タイトルに記載されている各サービス・プロダクトについてスライドを通して学習します |
| ラボ |
Integrate an AI Agent with a Flutter App Using Vertex AI Agent Builder (概要)実際にLLM・生成AI活用型アプリケーションを開発します |
本コースは最新コースのため、まだ英語版しか用意されていません
しかしながら、ここまでの進め方と変わらないため、英語を読みながら取り組んでみてください
コース概要は以下の通りです(※ブラウザ機能による日本語翻訳)
このコースでは、Geminiモデルとその生成AIアプリケーションでの使用方法を学びます。生成AIアプリケーションの「検索および推論エージェント」機能を構築するために使用可能なVertex AIプラットフォームのツール群について学びます。
コースの序盤では、以下の画像に示すようなドキュメントスライドを読みながら理解を深めます

本章のコースの最後、ラボ「Integrate an AI Agent with a Flutter App Using Vertex AI Agent Builder」では、以下に示すような構成の AI Agent を構築します
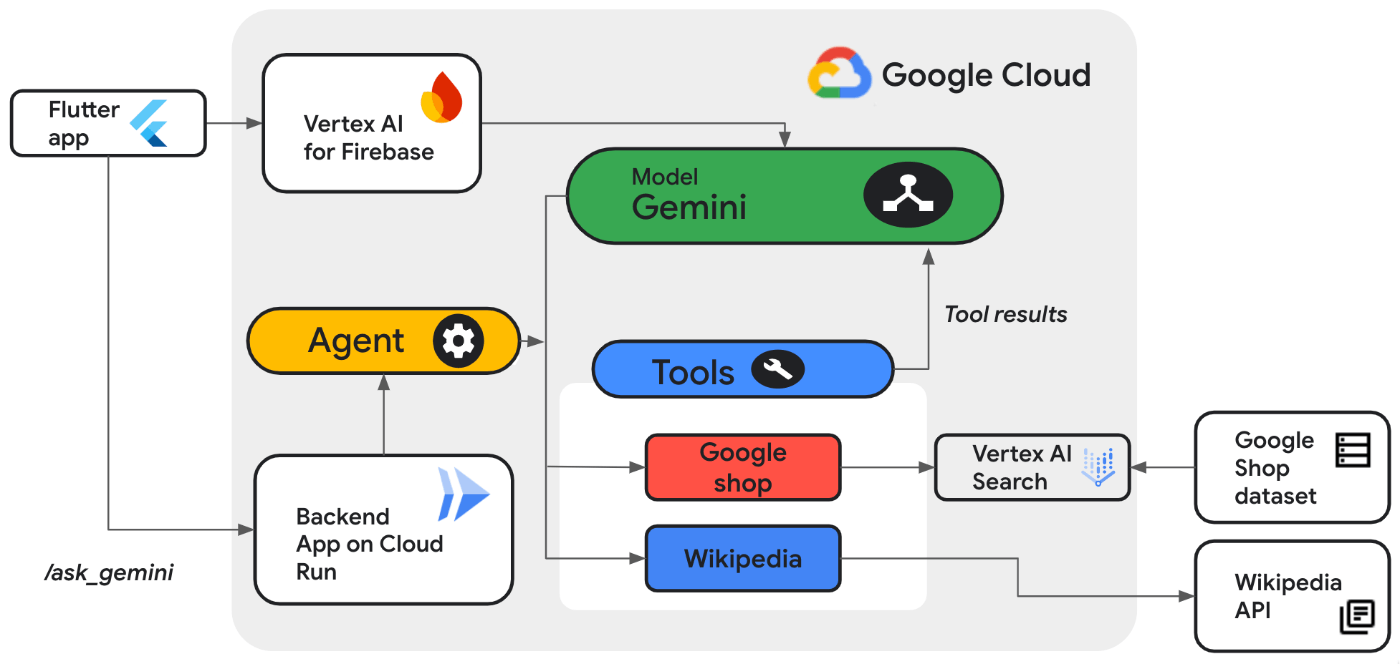
ラボの解説・指示も英語ですが、読みながら進めてください
- 「Vertex AI Search」をベクトルDBに
- 「Gemini 1.5 pro」を生成AIに
- 「Vertex AI Agent Builder」のSearch AgentをAgentクラスその1に
- 「Agent with LangChain on Vertex AI」をAgentクラスその2に
- 「PythonのFlask」をWebアプリのフレームワーク(バックエンド)に
- 「Cloud Run」をサーバーレスのコンテナ実行でのAPI作成に
- 「Flutter」をアプリケーション開発フレームワークに
- 「Vertex AI for Firebase Dart SDK」をフロントエンドに
それぞれ、使用します
以下は、「Vertex AI Agent Builder」の画面の様子です

以下に本ラボで最終的に構築するアプリケーションの様子を示します(Gif画像です)。動作概要は、
- 画像をアップロードする
- マルチモーダルなAgentが画像を解析し、「画像内の製品名」と「その概要」を生成します
- チャットにて「Where can I buy this pin?」とAgentに質問します
- AgentはDB内の情報からこのピンのURLを回答します

12. Integrate Search in Applications using Vertex AI Agent Builder
| タイプ | コンテンツ名 |
|---|---|
| ラボ | Integrate Search in Applications using Vertex AI Agent Builder |
本章では「ラボ」コース1本のみに取り組みます
前章で実施した、Vertex AI Agent Builder を利用した「検索Agent」の作成方法の復習的な内容です
なお、本コースも最新コースのため、まだ英語版しか用意されていません
以下の画像は、「Vertex AI Agent Builder」の「Search Agent」を作成して、映画情報のDatasetを作成しAgentに組み込んだあと、プラットフォーム画面(コンソール画面)で ”Harry Potter” と入力して、検索機能を試している様子です

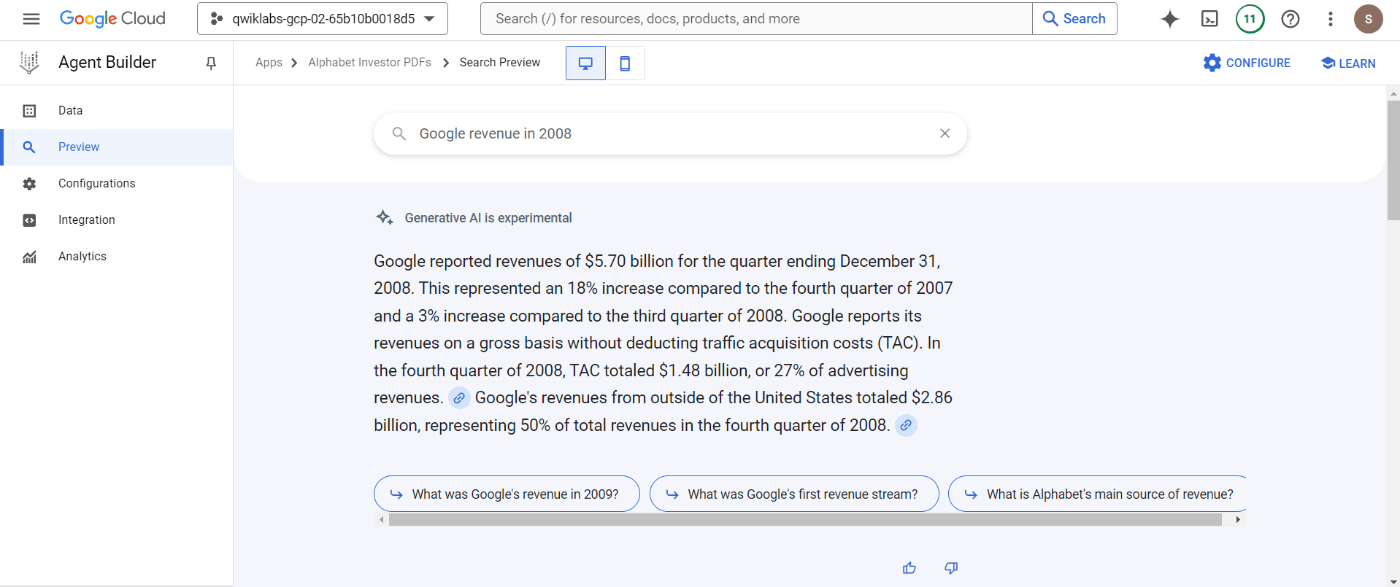
以下の画像は、使用するDatasetをPDF群に変更し、”Google revenue in 2008”という文章に対して、セマンティック検索を実施し、回答と関連PDFを求めている様子です
前章では Agent へのAPIまで構築し、APIを叩くフロントエンドなどシステム全体を構築しましたが、本章のラボは Agent を構築する部分までの復習的な内容となります
13. BigQueryでの生成AI活用手法 (Gemini in BigQuery)
| コンテンツ名 | |
|---|---|
| ラボ | Python ノートブックを使用して Gemini で購入者レビューを分析する |
| ラボ | SQL を使用して Gemini で購入者レビューを分析する |
本章もGoogleの公式コースではなく、執筆者が2つのラボをピックアップしています
これらのラボではBigQuery(BigQuery ML)と生成AI「Gemini」を連携させて使用する方法を解説します
これらは、Google CLoud Next '24(2024年4月)に発表された「Gemini in BigQuery」に関するラボとなります
なお本章のラボは日本語となります
BigQuery は Google Cloudが提供する「データウェアハウス」という位置づけです
その一機能として「BigQuery ML」が用意されており、格納データを訓練データや推論データに使用して、SQL的なクエリから MLモデルを構築できる機能がありました
この4月からは、さらに生成AI(Gemini)とも連携できるようになりました(Gemini in BigQuery)
1つ目のラボである、「Python ノートブックを使用して Gemini で購入者レビューを分析する」のラボの概説と、手が止まりやすいポイントの補足を解説します
タスク4.3「[エクスプローラ] で customer_reviews テーブルをクリックし、スキーマと詳細を確認します。」は、指示されている場所が分かりづらいです
以下に画像で示します。左側メニューの「gemini_demo」のメニューを開いた中にテーブルができています

Gemini を BigQuery と連携して使用する部分は、タスク6「購入者レビューのキーワードや感情を分析するよう Gemini に指示する」と、タスク7「購入者レビューに返信する」です
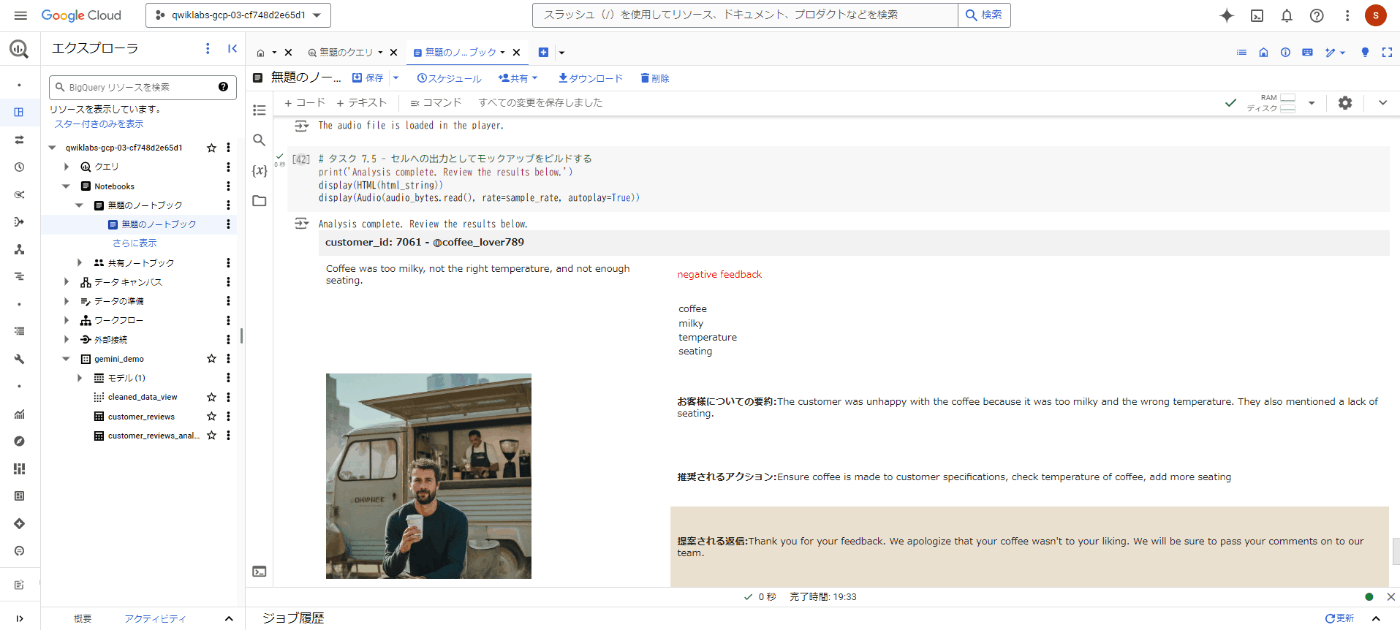
以下の画像は、タスク7の音声データを文字起こしし、ポジネガ判定をさせて、購入者のレビュー内容を要約し、返信文を自動生成した様子です
2つ目のラボである、「SQL を使用して Gemini で購入者レビューを分析する」は、1つ目のラボとほぼ同じ内容ですが、少し手法を変えて実現させます
2つ目のラボはPython Notebookからではなく、プラットフォーム画面上で各種操作やSQL(およびGemini と統合したSQL)を実行していきます
以下にて本ラボの概要と、手が止まりやすいポイントの補足を解説します
概要:本ラボではBigQueryにて文章データ等を含むテーブルを作成し、その文章データ部分等に対して、Gemini による解析をBigQuery上で実施させます
以下、手が止まりやすいポイントの補足です
タスク1.3「接続を作成するには、[+ 追加] をクリックし、[外部データソースへの接続] をクリックします。」は以下の画像のように、「エクスプローラー」の横にある「3点が縦に並んだ、閉じたメニューアイコン」をクリックすると、[+ 追加] が表示されます

ラボ1ではPython Notebookから実行していた「Gemini との外部接続」を、プラットフォーム画面から実施します(こちらの方が早いですし、分かりやすいです)

続いて作成した「外部接続」のサービスアカウントに IAM で、「Vertex AI ユーザー」のロールを割り当てて、BigQuery(の外部接続)から Vertex AI を使用できるように権限を付与します

画像やcsvファイルが格納された「Cloud Storage」がラボ用に用意されているので、「Storage オブジェクト管理者」のロールも権限付与します(タスク2)
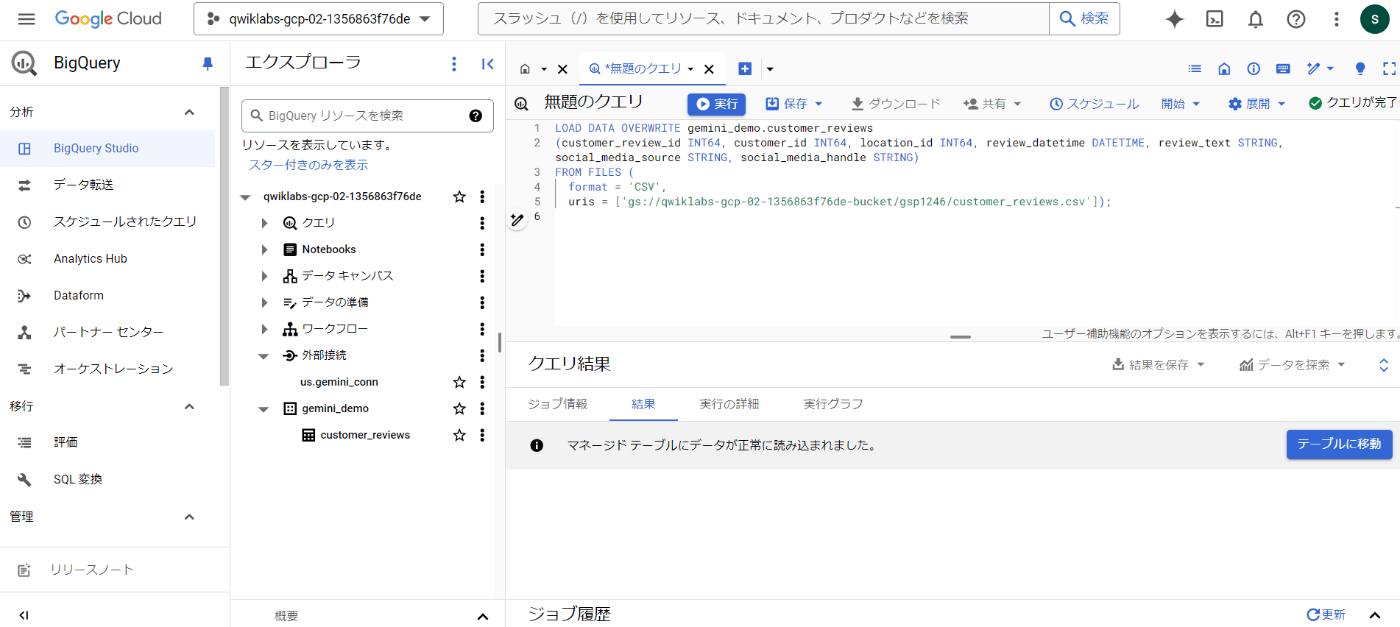
タスク3では、BigQuery用のデータセットを作成し、その中に、購入者レビューに関する「テーブル」を作成します
この操作も1つ目のラボではPython Notebookから実行していましたが、今回はプラットフォーム画面上から実施します
以下の画像は、左側メニューに「gemini_demo」のデータセットが作成され、その中に「customer_reviews」というテーブルが作成されたのを示す結果です
実際に使用する生成AIとして、Gemini Pro モデル、Gemini Pro Vision モデルを設定するのも、本ラボではプラットフォーム画面上からSQLとして実行します(タスク4後半)
タスク5では、SQLにて、customer_reviews テーブルから購入者レビューを取得し、gemini_pro モデルが各レビュー内のキーワードを識別するためのプロンプトを構築します。取得したキーワードは、新たなテーブル customer_reviews_keywords に保存させるようにします。以下の画面にその様子を示します

タスク6では、customer_reviewsテーブル内の「顧客のレビュー文章」(customer_id = 5576)に対して、返信の文章をGemini と統合したSQLで生成し、「customer_reviews_marketing」テーブルとしを新規作成してそこに生成結果を格納します
最後のタスク7では、BigQuery上からマルチモーダルな生成AI(今回はGemini Pro Vision モデル)を使用し、各画像のキーワードと要約を生成させます
以上、BigQuery と Gemini(生成AI)を統合した使用方法(Gemini in BigQuery)に関するラボ解説でした
生成AIをBigQueryで活用する方法は他にもあります
例えば、テーブルに格納されているデータ内容について自然言語で質問文を作成し、それをSQLに変換させて実行する(Text to SQL)など
本章のこの2つのラボを通して、BigQuery と Gemini(生成AI)の連携(Gemini in BigQuery)に慣れることで、今後は公式ドキュメントを読んでさらなる活用方法も簡単に実行できるようになるでしょう
公式ドキュメント:
14. Build LangChain Applications using Vertex AI
| コンテンツ名 | |
|---|---|
| コース名 | Build LangChain Applications using Vertex AI |
| ラボ | Create Text Embeddings for a Vector Store using LangChain |
| ラボ | Enhance Text Generation with RAG, LangChain, and Vertex AI |
| ラボ | Build a Knowledge Based System with Vertex AI Vector Search, LangChain and Gemini |
| ラボ | Build LangChain Applications using Vertex AI: Challenge Lab |
「上級編」の最後のコンテンツです
本コースでは Gemini(生成AI)とLangChainを使用して、アプリケーションを構築していく手法を学びます
本コースは英語のみになります
1つ目のラボである、「Create Text Embeddings for a Vector Store using LangChain」では、「Webページを読み込み、チャンクに分割、ベクトル化、ベクトルDBに格納後、LLMに質問を投げかけ、LLMがそのWebページから回答内容をよしなに文章化して生成する」という流れを構築します
最初に、以下のWebページをLangChainの「WebBaseLoader」を使用して、ドキュメントとしてロードします
その後、「RecursiveCharacterTextSplitter」で文書をチャンクに分割し、「VertexAIEmbeddings」でベクトル化します
ベクトルを格納するベクトルDBには、本ラボではOSSの「Chroma」を使用します(エンタープライズ向けに本番環境として作成する場合は、これまでの章でも解説・使用した「Vertex AI Vector Search」などの使用を推奨します)
そして、LangChainの「RetrievalQA」で「What is a TPU?」などと質問し、以下の画像に示すように、「A TPU is a Tensor Processing Unit, a custom-designed AI accelerator developed by Google」と、Webページから要約された回答を取得します

なお、今回利用したパッケージの各バージョンは、Langchainが0.3.1、langchain-google-genaiが2.0.0でした(本記事執筆時点:2024年10月)
2つ目のラボである、「Enhance Text Generation with RAG, LangChain, and Vertex AI」の注意点です
最初の、「Using Gemini directly with Python SDK」の直下のセルで、
model = genai.GenerativeModel('gemini-pro')
は、
model = genai.GenerativeModel('gemini-1.5-pro')
に修正してください(私が実施した際は、'gemini-pro'ではきちんと回答が返って来ませんでした)
以降も、gemini-proの部分は、gemini-1.5-pro を使用して進めると良いです
2つ目のラボでは最初に、以下のコードに示すような「LangChainの基本的なChainの使用方法(Gemini版)」を確認します
注意:以下のコードは執筆者が分かりやすいようにラボのNotebookから一部を抜き出し、コメントを追記しています
# [1] 引数でプロンプトが変わるようにプロンプトテンプレートを作成
prompt = ChatPromptTemplate.from_template(…)
# [2] LLMモデルを作成:
model = ChatGoogleGenerativeAI(model="gemini-1.5-pro", temperature=0.7)
# [3] langchain.schema.output_parserのStrOutputParserでLLMの回答を整形
output_parser = StrOutputParser()
# [4] chainの作成
chain = prompt | model | output_parser
# [5] chainの最初のプロンプトに引数を与えて、chainを駆動させる
chain.invoke({"topic": "machine learning"})
次に、「LangChainの複雑なChain、今回はRAGの使用(Gemini版)」を学習します
なお、以下のコードも執筆者が分かりやすいようにラボのNotebookから抜き出し、コメントを追記しています。またretrieverは、"Machine Learning"、"Deep Learning"、"Neural Networks"のそれぞれに関連するWikipediaページを10個ずつRAG元の文書として用意し、そこから情報を抜き出します
# [1] RAGした文章をcontextに埋め込み、引数questionのプロンプトテンプレートを作成
template= """Answer the question a a full sentence,
based only on the following context:{context}
Return you answer in three back ticks
Question: {question}"""
prompt = ChatPromptTemplate.from_template(template)
# [2] LLMモデルを作成:
model = ChatGoogleGenerativeAI(model="gemini-1.5-pro", temperature=0.7)
# [3] langchain.schema.output_parserのStrOutputParserでLLMの回答を整形
output_parser = StrOutputParser()
# [4] chainの作成。今回はRunnableMapを使用して並列処理させる
chain = RunnableMap({
"context": lambda x: retriever.get_relevant_documents(x["question"]),
"question": lambda x: x["question"]
}) | prompt | model | output_parser
# [5] chainの最初のプロンプトに引数を与えて、chainを駆動させる
chain.invoke({"question": "When was the transformer invented?"})
以下の画像に示すように、questionとして、「When was the transformer invented?」と質問を与えてchainを駆動させると、「'\nThe transformer was invented in 2017.\n'」と回答が得られます

3つ目のラボである、「Build a Knowledge Based System with Vertex AI Vector Search, LangChain and Gemini」では、ベクトルDBとして「Vertex AI Vector Search」を使用します
以下にラボの概要を解説します
RAG元となる文書群には、Anthropic(アンソロピック)の関連のWebページ36個を使用します
LangChain の RecursiveCharacterTextSplitter でチャンク化し、Googleの「embedding-001」モデルでチャンクをベクトル化して、embeddings.json というファイルにまとめます
このJSONファイルを Cloud Storage に保存した後、「Vertex AI Vector Search」をベクトルDBとして、このJSONの中身についてindex化を実施します(index化とはDBの各項目への検索を高速化するための処理です)
そしてこのベクトルDBへアクセスするエンドポイントを作成し、デプロイします(約20分かかります)
ここまでをタスク1からタスク3で実施します(ここまではLangChainは使用しません)
タスク4ではLangChainを使用せずに、「Vertex AI Vector Search」をRAGして回答を得る方法、そしてタスク5ではLangChainを使用し、かつ「Vertex AI Vector Search」をRAGして回答を得る方法を学習します
最終的には、以下のように、RAGをして回答が得られます

最後のラボは、「Build LangChain Applications using Vertex AI: Challenge Lab」という「チャレンジラボ」になります
ここまで学習した内容を定着させます
1つ目から3つ目までのラボの Jupyter Notebook を見返しながら取り組むと、進めやすいです
付録. GenAI journey図 と GenOpsの解説
ここまでの14章を通して、LLM・生成AIのモデルを利用したアプリケーションの実装に向けて、「以前よりも多くの知識と確かなスキルが身に着いた(かな)」と感じていただけたなら、望外の喜びです
とはいえ、やはり「LLM・生成AIのモデル活用型アプリケーション」の実装は簡単ではありません
とくに、エンタープライズで LLM・生成AI を、「企業内で活用する」、「自社製品やサービスに組み込む」、「社会実装する」というレベル感に対しては、本シリーズを終えてやっと入口に立てたかな、というのが私の正直な実感です
本記事は「上級編」とはいえ、本番環境への実装までを考えると、あまりにカバーできていない領域が多すぎます(そしてそれらをブログ記事でカバーするのはさすがに不可能です)
そこで本シリーズの「さいごに」として、本シリーズを終えたのち次に読むと良いであろうGoogleの公式ブログ記事を紹介します(なお、以下に掲載する図はそれぞれのブログ記事より引用)
(1) Google Cloud Japanの公式ブログ
日本語でGoogle Cloudに関するLLM・生成AI関連の情報を集めるならまずはここから
(2) GenOpsをビジネスに導入する際の流れ、「GenAI journey図」の概説
※「GenOps」とはMLOpsに対応する生成AI版の言葉であり、"Generative AI Ops" や "MLOps for Gen AI"の略称です
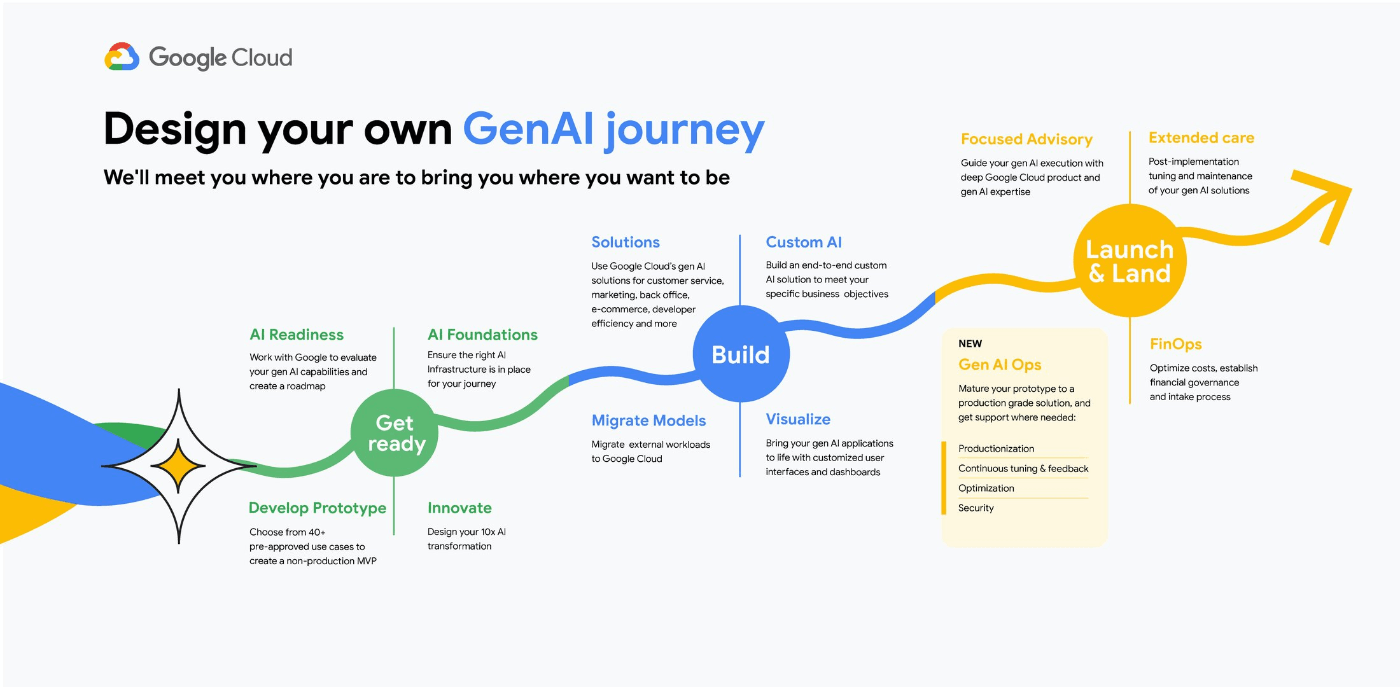
(3) GenOpsのより詳細な解説 その1(日本語)

(4) GenOpsのより詳細な解説 その2(英語)
※英語版公開が2024年9月21日のため、日本語版は(おそらく)もう少し遅れます
「GenOps: the evolution of MLOps for gen AI」
上記記事ではとくに以下の2点を詳しく解説しています
- AI活用型アプリケーションを構築する際の「Hidden Technical Debt(隠れた技術的負債)」として、MLOpsにおいては「MLモデル(ML Core)」以外に9項目の要素を考慮する必要があったのに対して、GenOpsにおいては「Gen AI model」を中心に、他14項目が存在するという点の整理
- MLOpsもGenOpsも「CI/CD」ではなく、「CI/CD/CT」(Continuous: Integration、Deployment、Training)であるが、パイプラインの複雑さが段違いである点


以上、本記事シリーズを終えたのち次に読むと良いであろうGoogleの公式ブログ記事4本の紹介でした
さいごに
「Google Cloud」を用いた「LLM・生成AI活用型アプリケーション」の実装スキルを身につけるための学習方法と学習コンテンツの紹介、第3回上級編、そしてシリーズ全体は以上となります
お疲れ様でした
「LLM・生成AI活用型アプリケーションの実装」および「そのための知識習得とスキル獲得」は簡単なことではありませんが、本記事シリーズが少しでもお役に立てば幸いです
以上3記事にわたり、ご一読いただき、誠にありがとうございました
【本シリーズの再掲】
シリーズ第1回の「初級編」はこちらです -> 初級編へ
シリーズ第2回の「中級編」はこちらです -> 中級編へ
小川 雄太郎
株式会社松尾研究所 シニア・リサーチャー。「知能を創る」PJTに従事

Discussion