こんにちは、松尾研究所 データサイエンティストの浮田です。この記事は、松尾研究所Advent Calendar 2025の記事です。
RAG (Retrieval-Augmented Generation) と聞くと、「ベクトルDBを構築する」という話に意識が向きがちです。もちろんベクトルDBはRAGの基盤になる重要な要素ですが、実際に使われるRAGプロダクトを作ろうとすると、ベクトルDB構築以外にも様々な工夫が必要となります。
本記事では、私が実務でRAGプロダクトを構築する中で遭遇した様々な障壁とその対応を紹介します。
プロダクト概要:社内プロジェクト検索ボット
松尾研究所は様々な企業様と共同でプロジェクトを進めています[1]。過去・現在を含めて多くのプロジェクトがあるため、自分が担当していないプロジェクトの理解はどうしても浅くなってしまいます。もちろんお互いのプロジェクトを共有する活動はしていますが、過去のプロジェクトまで共有するのは難しいですし、例えば以下のように横断的に聞かれるとなかなか答えにくいものです。
- 拡散モデルを使ったプロジェクトはあるか
- 営業向けのプロジェクトはあるか
そこで、Google Drive上にあるプロジェクトの資料 (定例会議の資料、最終資料など) をソースとして、社内プロジェクトをSlackから対話的に検索できるボットを作り、社内のユーザに展開しました。
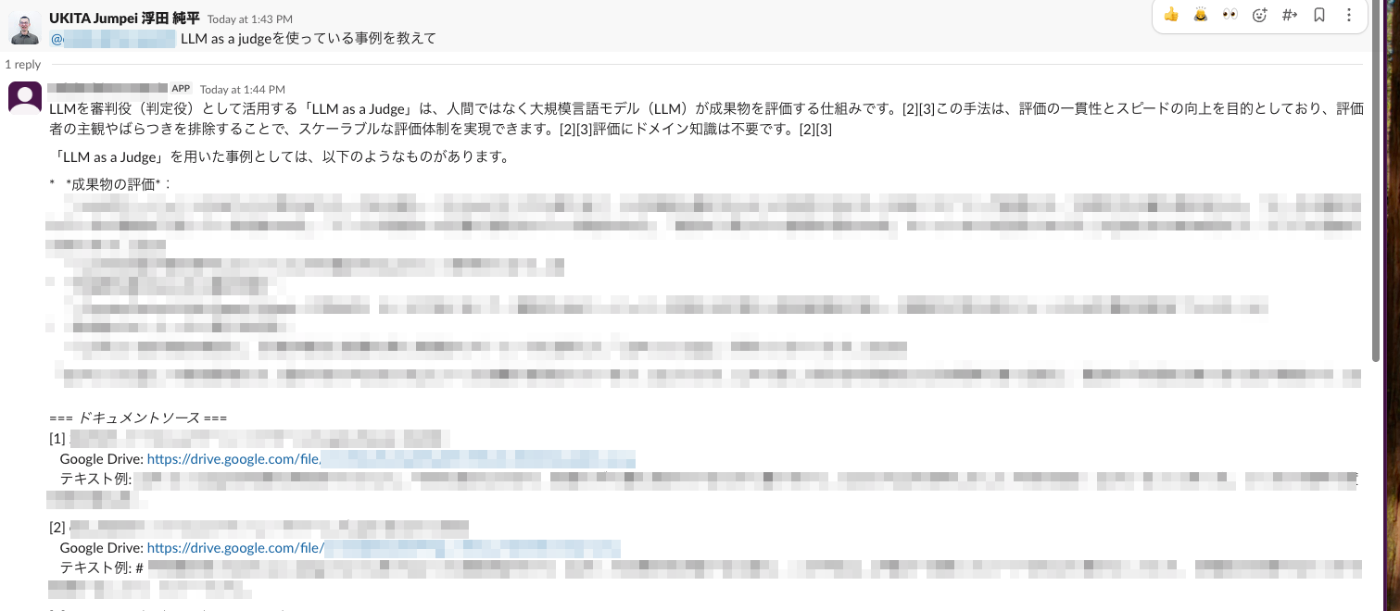
作った社内プロジェクト検索ボット。Slackでメンションすると、引用付きで検索結果を取得できます
アーキテクチャ
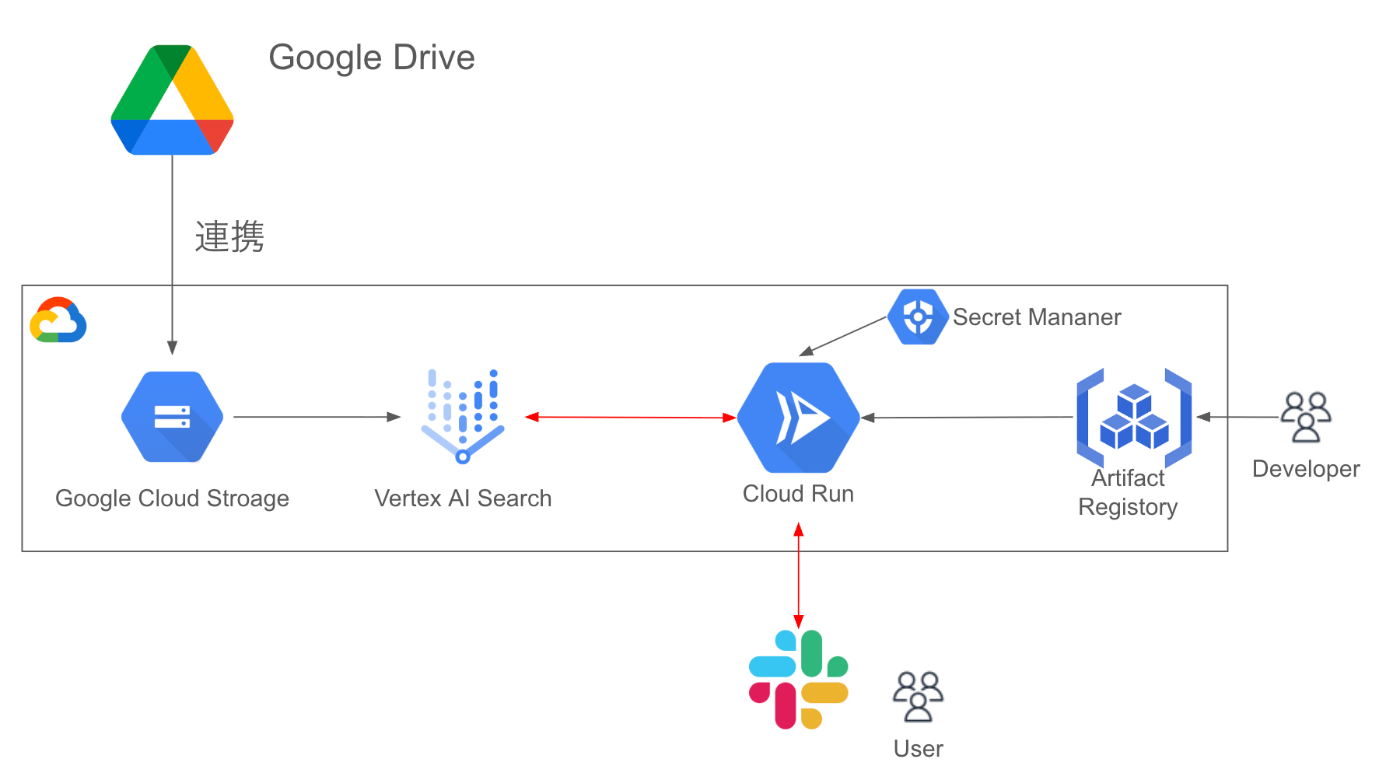
アーキテクチャ図
今回の社内プロジェクト検索ボットのアーキテクチャ図は上記のとおりです。
- Google CloudのVertex AI Searchを中心に構築しました。Vertex AI SearchはGoogle Driveとの相性が良いだけでなく、RAG検索の機能が充実していることから採用しました。
- Google DriveのデータはVertex AI Searchに直接連携もできますが、後述のように「Google Driveの資料のうち新しいものを重点的に検索したい」という意図があったので、一旦Google DriveのファイルをCloud Storageに連携したものを検索対象にしています
- SlackからのリクエストはCloud Runで受け付けています
特に1点目は重要で、今回ソースとしている資料には図表が多く含まれていますが、Vertex AI Searchはドキュメントのパーサーが充実しており、図表・段落・表などの形式をパースできます。今回は以下のようにデータストアを設定しました。

データストアの設定:レイアウトパーサーでドキュメント解析している
このようにVertex AI Searchを使えばサクッとデモアプリは作れますが、実ユーザに使ってもらうにはまだまだ不十分です。特に実ユーザからの入力はそのままクエリにするには適していないことが多いため、様々な方法で言い換える必要があります (問題点2~問題点5)。クエリ言い換えには色々な研究がありますが、ここではすぐに試せるもの・実際に効果があったものを紹介しています。
データ側の問題
問題点1. 古いソースから古い情報を引っ張ってくることがある
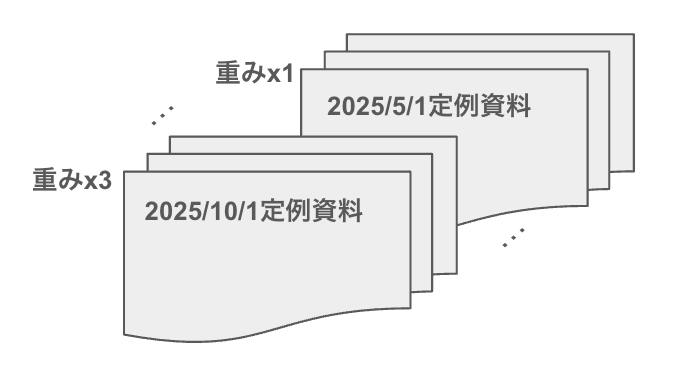
新しいコンテンツを優先するイメージ
Google Driveにはどうしても古い内容のファイルも含まれています。例えば定例会議の資料が複数ある場合、古い資料にはその後の議論で却下された情報が残っていることがあります。
以下のような手順を踏むことで、RAG検索時に古い情報がヒットしづらくなります。
- Google DriveのファイルをCloud Storageにコピー
- Cloud Storageのファイルパスと作成日時 (
created_date) の対応表をNDJSON形式で作成する - 2の対応表をメタデータとして扱い、Vertex AI Searchにデータを登録する。
手順3は以下の公式ドキュメントに詳しいです。
Vertex AI Searchでの検索時に boostSpec というフィールドを使って、以下のように「 created_date が新しいものをboostする」という設定ができます。
"boostSpec": {
"conditionBoostSpecs": [
{
"condition": 'created_date >= "1900-01-01T00:00:00Z"',
"boostControlSpec": {
"fieldName": "created_date",
"attributeType": "FRESHNESS",
"interpolationType": "LINEAR",
"controlPoints": [
{"attributeValue": "30D", "boostAmount": 0.20},
{"attributeValue": "90D", "boostAmount": 0.10},
{"attributeValue": "180D", "boostAmount": 0.00},
],
},
},
]
}
ユーザクエリ側の問題
問題点2. 汎用LLMにはビジネスモデルが分からない

例えば「弊社でのロボット案件のクライアントをリスト化して」という入力がユーザから来たとします。汎用LLMには「弊社」のビジネスモデルを教えていないため、文脈がわからない可能性があります。また「クライアント」のような多義語を文脈に沿って解釈できていない場合もあります。
この問題には、RAG検索の前にクエリを言い換えるLLMを挟むことで対応しました。
具体的には、以下のプロンプトを使ったLLMを用いてユーザ入力を変換し、このLLMの出力を検索時にクエリとして使うようにしました。こうすることで回答の質を向上させることができました。
## タスク
ユーザ入力 ($INPUT) を簡潔に要約して下さい。また、松尾研究所の社内用語を知らない人でも理解できる表現に言い換えてください。
## 前提
* この出力はRAG検索で使える自然言語クエリに使う予定です。
* RAGのデータベースには松尾研究所が過去に実施した「プロジェクト(クライアントとの共同研究事例など)」の資料が格納されています。
## 言い換えルール
以下の表現はすべて指定の言葉に置き換えてください:
| 元の言葉 | 言い換え後 |
|--------|----------|
・・・(略)・・・
## 入力
$INPUT
問題点3. 冗長なクエリの弊害
例えば「今ロボットに世界モデルを使えないか考えています。松尾研究所で世界モデルを使ったような事例をたくさん挙げてください」という入力がユーザから来たとします。
RAGではクエリを埋め込みモデルにかけた上でデータベース上のchunkとの距離を計算します。このユーザ入力をそのままクエリにしてしまうと、「ロボット」といった検索には関係ない単語も含めて埋め込まれてしまう可能性があります。したがって「松尾研究所での世界モデルの事例を多数挙げて」のような簡潔なクエリに言い換えることが必要です。
このような言い換え処理はVertex AI Searchの「クエリの言い換え」機能に実装されているため、この機能を有効化することで対応しました。
問題点4. クエリとチャンクの非対応
例えば「ロボット案件とLLM案件の事例を挙げて」という入力がユーザから来たとします。
「ロボットの案件」と「LLMの案件」の詳細は別のソースファイルに存在する可能性が高いため、ユーザ入力の文字列をそのままクエリにすると、欲しい情報がヒットしない可能性が高いです。この例では、ユーザの意図を正しく反映するために「ロボット案件の事例を教えて」と「LLM案件の事例を教えて」の2つの独立なクエリに分解する必要があります。
このような処理は、問題点3と同じ「クエリの言い換え」機能に実装されているため、同じ方法で対応しました。
問題点5. 少しクエリを変えるだけでヒットすることがある
例えば「ロボット案件を教えて」のクエリだとヒットしないが、「ロボット案件の事例を教えて」のクエリだとヒットする場合があります。
このようにRAGではほんの少しクエリを変えるだけで結果が変わることがあるため、ヒットしない場合はクエリを少しだけ変えてリトライさせるようにしました。
問題点2のようにクエリを生成するLLMが検索の前段にあり、このLLMの出力が確率的であることから、ヒットしない場合には再度クエリ生成LLMに入力することで対応しました。

リトライを含めたユーザ入力処理のワークフロー
まとめ
本記事では、社内プロジェクト検索ボットを題材に、実務でRAGプロダクトを構築する際に直面した課題と、その具体的な対応策を紹介しました。RAGは「ベクトルDBを作れば終わり」ではなく、クエリ変換・検索ロジック・データの鮮度管理などユーザが本当に使える状態に仕上げるための細かな工夫が欠かせません。
これらの工夫が、皆様のRAGプロダクト開発の一助となれば幸いです。

Discussion