近年、大規模言語モデル(LLM)のオープンソース化が進み、大小さまざまなモデルが利用できるようになりました。
これらのモデルは汎用性が高い一方で、特定分野に特化したモデルを作るためのファインチューニングの需要も増えています。
そこで注目されているのが、パラメータ効率的ファインチューニング(PEFT)です。特にLoRA(Low-Rank Adaptation) という手法が広く使われています。LoRAは学習するパラメータ数を大幅に削減できる優れた手法ですが、フルファインチューニング(すべてのパラメータを学習する方法)と比べると性能が劣るという課題があります。
この課題を解決するため、ICLR2025でLoRA-Proという新手法が提案されました。論文を確認する過程でLoRAには派生手法が数多くあることが分かったので、備忘録も兼ねて記事を書いています。
本記事では、LoRAの基本概念から始め、様々な派生手法を整理しながら、LoRA-Proについて解説します。
サマリー
-
LoRA派生手法の分類
- スケーリング・学習率調整型:
- LoRAのアダプター行列に適用されるスケーリングファクターや学習率を調整し、学習の安定性と速度を改善
- 構造変更型:
- LoRAの基本構造そのものを改良し、性能向上
- 勾配最適化・初期化型:
- LoRAの最適化プロセスやアダプター行列の初期化を改良することで、フルファインチューニングの学習を模倣(LoRA-Proはここに分類)
- スケーリング・学習率調整型:
-
LoRA-Proの特徴
- LoRAの勾配をフルファインチューニングの勾配に近づける最適化を実現
- 性能面では既存手法を上回る結果を達成
- ただし、現時点ではDeepSpeedの独自実装のみ公開されており、既存のPEFTエコシステムとの統合に課題
主要な派生手法の比較表 (LoRA-Pro論文でベンチマーク対象手法)
| 手法 | 公開年 | 中心的なアイデア | アプローチ分類 | PEFT公式実装 |
|---|---|---|---|---|
| AdaLoRA | 2023 | 重要度スコアに基づきモジュールごとに動的にランクを調整 | 構造変更 | ⚪︎ |
| rsLoRA | 2023 | スケーリングファクターの修正で高ランクでの勾配崩壊を防ぐ | スケーリング調整 | ⚪︎ |
| DoRA | 2024 | 重み行列をマグニチュードと方向に分解して最適化 | 構造変更 | ⚪︎ |
| LoRA+ | 2024 | AとB行列に異なる学習率を適用 | 学習率調整 | ⚪︎ |
| PiSSA | 2024 | 重み行列の主要な特異ベクトルでアダプターを初期化 | 初期化(静的最適化) | ⚪︎ |
| LoRA-GA | 2024 | 訓練の最初のステップで勾配方向をフルFTに近似 | 初期化(静的最適化) | × |
| LoRA-Pro | 2024 | LoRAの最適化をフルFTの「低ランク仮想勾配」に近似 | 勾配最適化(動的最適化) | × |
各図表は言及がない場合、対応する論文から引用しています。
LoRA(2021)
LoRA(Low-Rank Adaptation)は、ファインチューニング中にモデルの重み行列で生じる変化が、実は低ランクの構造を持つという仮説に基づいています。
LoRAの仮説背景
このアイデアを実装するために、事前に訓練された重み行列

この関係は、スケーリングファクター
これにより、訓練パラメータ数を
LoRAの派生手法:様々なアプローチ
LoRAの性能をさらに高めるため、さまざまな改良手法が提案されてきました。これらの手法は、主に以下の3つのアプローチに分類できます。
1. スケーリング・学習率調整に基づく手法
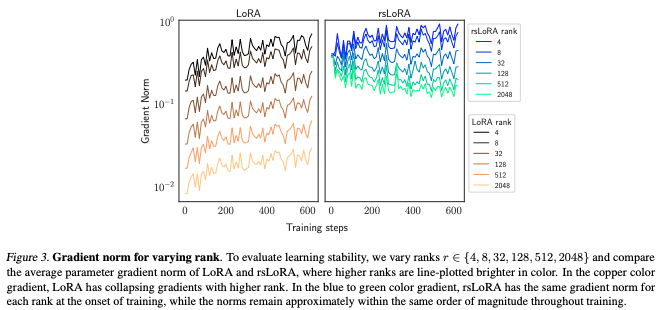
rsLoRA (2023)
- モチベーション: LoRAの性能・学習安定性向上
-
中心的なアイデア: 従来のLoRAのスケーリングファクター
s = \alpha/r r -
アプローチ: 新しいスケーリングファクター
s = \alpha/\sqrt{r}
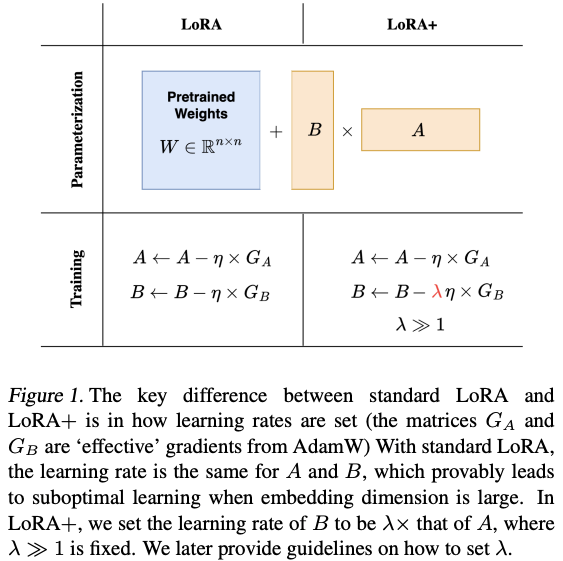
LoRA+ (2024)
- モチベーション: LoRAの性能・学習安定性・収束速度向上
-
中心的なアイデア: アダプター行列
A B -
アプローチ:
A B
2. 構造変更に基づく手法
AdaLoRA (2023)
- モチベーション: LoRAの性能向上
-
中心的なアイデア: すべてのモジュールに一律のランク
r -
アプローチ: アダプター行列をSVD(特異値分解)の形式に変更し、重要度の低い特異値を動的に刈り込む
-
W = W_0 + \Delta W = W_0 + P\Lambda Q - ここで、
W_0 \Delta W P \in \mathbb{R}^{d_1 \times r} \Lambda \in \mathbb{R}^{r \times r} Q \in \mathbb{R}^{r \times d_2}
- ここで、
-

SVDとは
SVD(Singular Value Decomposition, 特異値分解)は、任意の行列を3つの行列の積に分解する手法です。
行列
-
P -
\Lambda -
Q
特異値(
DoRA (2024)
- モチベーション: LoRAの性能・学習安定性向上
-
中心的なアイデア: フルファインチューニングが重み行列の「大きさ(マグニチュード)」と「方向」を独立して最適化するのに対し、LoRAはこれらを同時に変更するため非効率だと指摘
- 大きさ:重みベクトルの全体的な強さ・スケールに相当
- 方向:モデルがどのような特徴を学習しているかに相当
-
アプローチ: 事前学習済みモデルの重み(パラメータ)をマグニチュードと正規化された方向行列に分解し、LoRAを方向成分にのみ適用。マグニチュード側は学習可能なスカラーで調整。

3. 勾配最適化・初期化に基づく手法
LoRA-GA (2024)
- モチベーション: LoRAの性能・収束速度向上
- 中心的なアイデア: LoRAの収束が遅いのは、学習初期の勾配方向がフルファインチューニングの勾配と乖離しているためだと仮定
-
アプローチ: 訓練の最初のステップで、フルファインチューニングの勾配行列の固有ベクトルを 使用してアダプター行列
A B

PiSSA (2024)
- モチベーション: LoRAの性能・収束速度向上
-
中心的なアイデア: LoRAの「Noise & Zero」初期化(
A B -
アプローチ: 訓練開始前に重み行列
W_0 W_0 W_{pri} W_{res} A B W^{pri}

LoRA-Pro: フルファインチューニングの勾配を追跡するアプローチ
- モチベーション: LoRAの性能・収束速度向上
- 中心的なアイデア: LoRAによる最適化が、フルファインチューニングにおける「仮想的な低ランク勾配」によるパラメータ更新と数学的に等価であるという発見に基づく

上記理論の仮定
LoRA-Proの理論は、アダプター行列 A と B が学習中にフルランクであるという仮定に基づいています。大規模なファインチューニングデータや特定の事前学習モデルではこの仮定が成立しない可能性があり、性能に影響を与える可能性があります。
LoRA-Proの著者たちはこの仮定が実際に成立するかを実験的に検証しました。
実験内容と結果
Llama-2-7BモデルをMetaMathQAデータセットでファインチューニングする過程で、アダプター行列
実験の結果、初期段階では行列
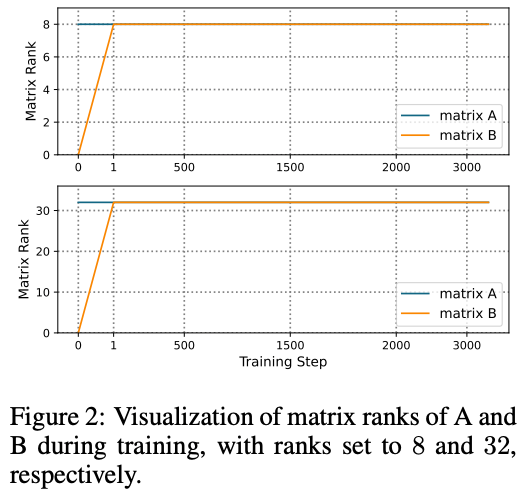
この実験結果より、LoRA-Proの理論の前提となる仮定は問題なく成立すると結論づけられています。
フルランクとは
「フルランク」であるとは、その行列のすべての行ベクトルが線形独立であり、かつすべての列ベクトルも線形独立である状態を指します。
具体例
-
フルランクの行列の例(情報の重複がない、最大限の情報を保持)
A = \begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix}
この行列の行ベクトルは(1, 0) (0, 1) (1, 0) (0, 1)
同様に、列ベクトルも(1, 0) (0, 1) この行列Aは、行の数(2つ)と同じ数の線形独立な行ベクトルを持ち、列の数(2つ)と同じ数の線形独立な列ベクトルを持っています。このような状態を「フルランク」と言います。この行列は、2次元空間の情報を最大限に、かつ重複なく表現しています。
-
フルランクではない行列の例(情報が重複している、一部の情報が失われている可能性)
B = \begin{pmatrix} 1 & 2 \\ 2 & 4 \end{pmatrix}
この行列の行ベクトルは(1, 2) (2, 4) (2, 4) (1, 2) 2 \times (1, 2) = (2, 4)
同様に、列ベクトルも(1, 2) (2, 4) この行列Bは、行の数(2つ)に対して線形独立な行ベクトルが1つしかありません(例えば
(1, 2)
-
アプローチ: LoRAの勾配が、フルファインチューニングの真の勾配により近づくように最適化し、性能を向上
- フルファインチューニングの真の勾配
g = \frac{\partial L}{\partial W} \tilde{g} = sBg^A + sg^B A - この最適化問題には閉形式解が存在することを理論的に証明。この解は、フルファインチューニングの勾配を明示的に計算することなく、標準LoRAの勾配(
g_{lora}^A g_{lora}^B g^A g^B - これにより、LoRA-Proは学習過程を通じてフルファインチューニングの勾配方向を継続的に追跡し、修正することが可能になる
- 追加の計算は低ランク行列
r \times r
- フルファインチューニングの真の勾配
LoRA-Proにおける行列A, Bの最適化ステップ
1. 順伝播と標準勾配の計算
通常のLoRAと同様に、事前学習済み重み
2. 「等価勾配」の定義
LoRA-Proは、LoRAアダプターの更新が、フルファインチューニングにおける「仮想的な低ランク勾配」
3. 最適化問題の定式化
LoRA-Proの目的は、この「等価勾配」
ここで、
4. 最適な勾配の導出
上記の最適化問題には、フルファインチューニングの勾配
5. 任意行列 X
ステップ4で得られた勾配
6. アダプター行列の更新
最後に、ステップ4と5で得られた調整後の最適な勾配
この一連のプロセスにより、LoRA-Proは損失を着実に減少させながら、フルファインチューニングの勾配方向をより正確に追従し、高い性能を達成します。
精度比較
論文の実験結果は、LoRA-ProがLoRA、LoRA-GA、DoRAなどの他のLoRA派生手法を上回り、特にGLUEベンチマークではフルファインチューニングも上回る性能を示しています。これは、フルファインチューニングが訓練データセットが小さい場合に過学習しやすいのに対し、LoRA-Proがより汎化性能の高い解に収束できるためだと考えられます。

課題と今後の期待
しかし、LoRA-Proの実用化には課題も残されています。理由としては、最適化の過程で勾配を複数ステップに分けて算出する必要があり、Optimizerの処理が複雑になるためです。その結果、公式で提供されているコードは、DeepSpeedの独自実装にとどまっており、広く普及しているPEFTライブラリ(Hugging Faceなど)に直接統合されていないため、気軽に試すことが難しい現状です。
DeepSpeed実装部
今後、LoRA-Proの優れたアプローチが、PEFTなど多くの開発者に利用される形で実装されることを期待したいです。(AI codingでこの辺りのハードルは低いかもしれない)

Discussion