株式会社松尾研究所で働いている栗原です。本記事は、松尾研究所 Advent Calendar 2025の記事です。
はじめに
日本語音声合成は、ディープラーニングを用いた音声合成手法が登場して以降、大きく品質を上げました。当初は、フィードフォワード型などの単純な手法で実現してきましたが、様々なディープラーニングの手法を取り込み、急激に品質を上げていき、あっという間に日常的に使用する技術になった感があります。
日本語音声合成の一研究者として、この分野の発展を願い日本語音声合成全般について語っていきたいと思います。
技術の全てを網羅すると書籍レベルの情報量になってしまうので、今回は「日本語」にフォーカスして書きたいと思います。
音声合成の概念
まず始めに、人間が音声を発話する時のプロセスを考えてみます。

人間が音声を発話する時のプロセスのイメージ. 一部画像を生成AIで作成
まず、何を話したいかを頭で考えますよね。この時、(ほぼ無意識に)「どのように読むか」を頭で考えて、それを人間の器官である声帯・声道で物理的な音波として音を作る事で実現できると考えられます。
このプロセスをシステムに置き換える事で任意の音声を生成するシステムとして考案されたのが、パイプライン式音声合成[1]です。イメージとしては、「アクセント・読み」の部分を言語処理部が推定し、その情報を元に「声道・声帯」に当たる部分を音響特徴量推定部・ボコーダにおいて音声を生成するイメージです。

頭で考え、それを声帯・声道などの器官で音声化します. 一部画像を生成AIで作成
この音響特徴量推定部とボコーダについては、世界中の人類共通の器官として言語によらず同じモデルとして扱える(人類みんなが同じ声帯・声道の機能を持っている)ので、世界共通の研究課題として急速に高品質化が進みました。
音響特徴量推定部としては、初めてディープラーニングを用いた音声合成を開発したZenらが開発したフィードフォワード型音声合成[1:1]が有名です。この手法では、HMM (Hidden Markov Model)を用いた音声合成[2]のHMMの部分をフィードフォワードに置き換えたもののため、HMM音声合成の時に用いてたフルコンテキストラベルという複雑なラベルファイルを用いていました。その後、2017年にSequence to sequence with attention方式 (Seq2seq)の音声合成[3]が登場します。フィードフォワード型音声合成と比べ何が良かったかというと、特殊なラベルファイル(例:これで1文)を使わずに「文字列」を直接的に入力する事ができる点でした。これにより、ぐっと音声合成のラベルファイルが取り扱いやすくなりました。文字列だと、自然言語処理でも扱えるので機械学習的にも大きなメリットです。下記にフォーマット例を記載しました。長いので折りたたんでいます。
従来法・提案法のラベルフォーマット例を見たい方はこちらをクリック
例文:水をマレーシアから買わなくてはならないのです。
従来法ラベル (長いから頭の6行だけ表示。これで「ミズヲ」まで)
0 3000000 xx^xx-sil+m=i/A:xx+xx+xx/B:xx-xx_xx/C:xx_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:xx_xx#xx_xx@xx_xx|xx_xx/G:3_3%0_xx_0/H:xx_xx/I:xx-xx@xx+xx&xx-xx|xx+xx/J:4_23/K:1+4-23
3000000 3400000 xx^sil-m+i=z/A:-2+1+3/B:xx-xx_xx/C:xx_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:3_3#0_xx@1_4|1_23/G:7_2%0_xx_0/H:xx_xx/I:4-23@1+1&1-4|1+23/J:xx_xx/K:1+4-23
3400000 4200000 sil^m-i+z=u/A:-2+1+3/B:xx-xx_xx/C:xx_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:3_3#0_xx@1_4|1_23/G:7_2%0_xx_0/H:xx_xx/I:4-23@1+1&1-4|1+23/J:xx_xx/K:1+4-23
4200000 5100000 m^i-z+u=o/A:-1+2+2/B:xx-xx_xx/C:xx_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:3_3#0_xx@1_4|1_23/G:7_2%0_xx_0/H:xx_xx/I:4-23@1+1&1-4|1+23/J:xx_xx/K:1+4-23
5100000 5400000 i^z-u+o=m/A:-1+2+2/B:xx-xx_xx/C:xx_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:3_3#0_xx@1_4|1_23/G:7_2%0_xx_0/H:xx_xx/I:4-23@1+1&1-4|1+23/J:xx_xx/K:1+4-23
5400000 6400000 z^u-o+m=a/A:0+3+1/B:xx-xx_xx/C:xx_xx+xx/D:xx+xx_xx/E:xx_xx!xx_xx-xx/F:3_3#0_xx@1_4|1_23/G:7_2%0_xx_0/H:xx_xx/I:4-23@1+1&1-4|1+23/J:xx_xx/K:1+4-23
提案法ラベル(1文で表示)
^ミ[ズヲ#マ[レ]ーシアカラ#カ[ワナ]クテワ#ナ[ラ]ナイノデス$
英語では、単語を数字に置換したり、発音記号に変換する事[4]で容易に音声合成を構築できるようになりました。これは日本語にも応用できるかもしれない、と日本語音声合成の研究者も、文字列として日本語をそのまま入力してみたのですが、上手くいきませんでした。この辺り、日本語の難しさと直結していると感じますが、どう日本語を入力できるようにしていったかを説明していきたいと思います。
日本語音声合成の課題
従来法を[1:2]とし、提案法を[5][6][7]とした時の図を以下に示します。
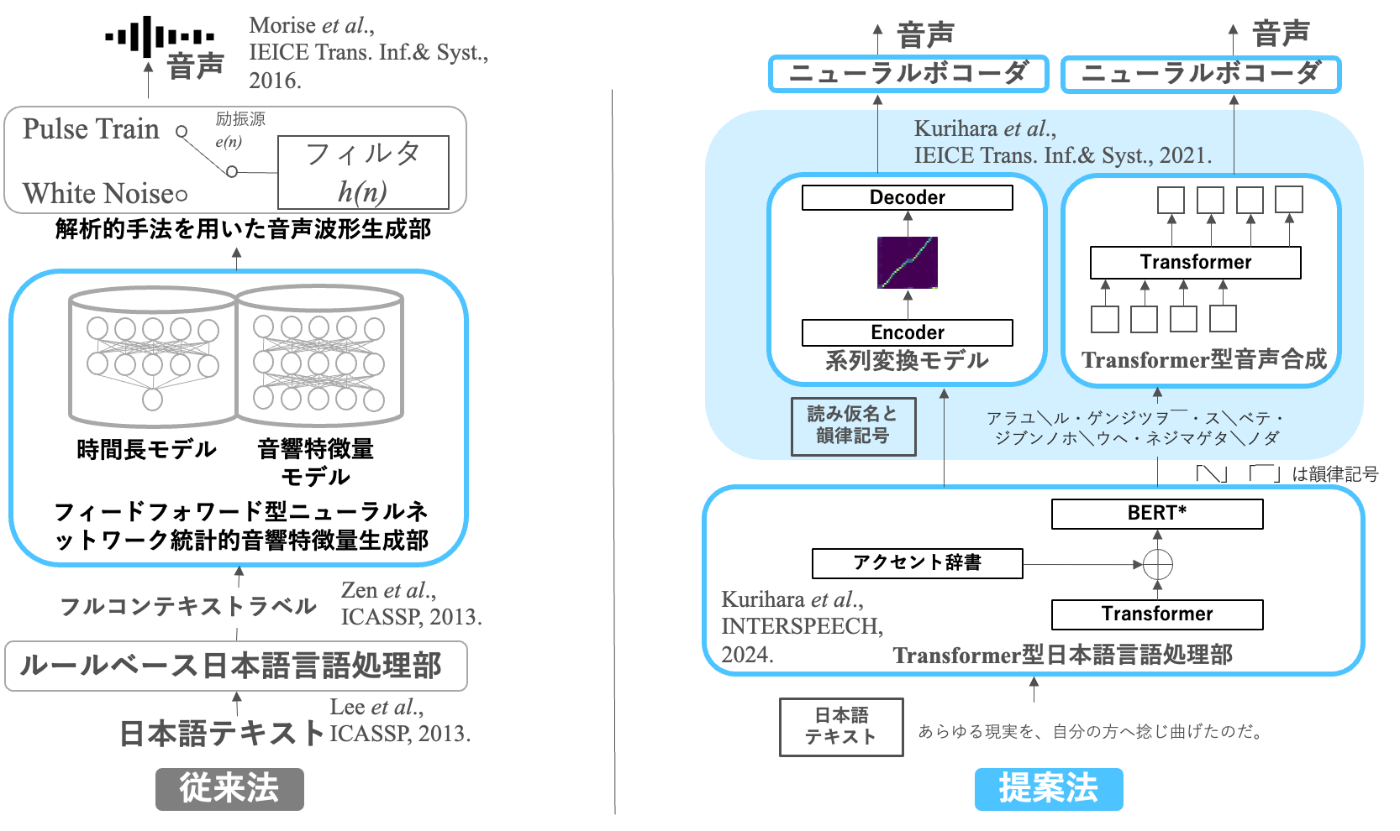
従来法と私の提案法
Seq2seq音声合成で日本語を生成できない理由は、日本語の漢字が複数の読み方を持ってしまう事にあります。Seq2seq音声合成は、教師あり学習でラベルが必要なため、Seq2seq音声合成は音声ファイルとラベル(文字列)の特徴を関連付けて学習させようとします。その文字列すなわち漢字が複数の読み方を持ってしまう場合、音声波形とラベルの相関が取れなくなってしまいます。そうすると、Seq2seqの学習ができないのは、なんとなくイメージは湧くと思います。
そうです。それなら、片仮名なら読みが特定出来るから大丈夫じゃないか、と思いますよね。半分正解です!片仮名を用いて学習させる事で、読み間違いは無くなります。ただ、問題なのはアクセントが再現できない事です。これ、思ったよりも違和感があります。
どうすれば、アクセントが再現できるのか、という事で考案したのが、Seq2seq音声合成の日本語化手法です[5:1][6:1]。手法は違いますが、同時期に現名古屋大学の安田先生が違うアプローチでこれを解決する手法を提案されていました[8]。

ようは、ココに日本語で受ける余地を作る、というのが私が提案した日本語化手法です。ココに、何を入れれば日本語を読めるのか、というのが課題で、これを解くことができれば世界的に流行していた(結果的にもデファクト化した)音声合成手法の日本語化が実現できるという事です。
アクセントが再現できないのであれば、再現できる手法が必要だという事で、アクセントを埋め込む手法を作ってみました[5:2][6:2]。
この辺りの手法について解説していきます。
まず、みなさん下記の言葉を口に出してみてください。

どう発音しましたか?「カキ」は「牡蠣」でしたか?「柿」でしたか?
これ、アクセントによって意味が変わってきてしまう言葉の例なんです。
この「カキ」が「カ\キ(牡蠣)」なのか「カキ ̄(柿)」なのかを判断するのが、日本語言語処理部[7:1]で、このアクセントを音声として再現できるものが日本語Seq2seq音声合成[5:3][6:3]という事になります。
という事で、日本語Seq2seq音声合成はアクセントを認識して、声の高さを変える事ができないといけない、という事になります。そうであれば、「アクセントの情報とそれに対応する音声」を一緒に学習させれば良い、と考えられます。
以上より、普通の日本語ではダメなのではと仮説を立てました。
日本語の表記として我々が普段から使用している「漢字仮名交じり文」「片仮名」を用いる事を諦めます...!
(注釈:最新の手法では、直接日本語を入力できる手法も登場しています)
日本語音声合成の実現方法
アクセントを明示できる表現方法を探すと、いくつか候補が出てきます。国立国語研究所の窪薗先生[9]、元東大藤崎先生[10]、NHK放送文化研究所など、この辺りのアクセント及びその表記法を研究されている先行研究はありますし、かなり昔ですが2002年頃にJEITAが音声合成のアクセントの表記法を提案しています。
これらの先行研究を参考に、Seq2seq音声合成への入力表記法を作れば音声合成側でも日本語アクセントの制御ができるのではないかと考えました。その結果、書いた論文がこちら[5:4]です。簡単に概念図を示します。Seq2seq音声合成の入力として、上記の先行研究の知見をもって、片仮名(音素記号)に日本語のアクセントを埋め込んで表現した表記方法を学習データとして用いる事にしました。これをSeq2seq音声合成の概念図と合わせると、下記のような形になります。

簡単な概念図
この手法が正しく動作するのかについて、主観評価実験の結果を下記に示します。この実験では、実際に主観評価実験として音声を聞いてもらい実験を行いました。ボコーダ(メルスペクトログラムから音声波形への変換)にはGriffin-Limボコーダという解析的手法での音声波形生成手法を用いました。

主観評価実験のMOS(5段階評価値) (Copyright (C) 2021 IEICE, [5] Fig. 8)
Original: 録音された人間の肉声(Ground Truth)
ReGL (Resynthesis with Griffin-Lim): 録音された人間の肉声からメルスペクトログラムを計算しGriffin-Limアルゴリズムを用いて再合成した音声(性能限界)
T2KH: Tacotron 2に漢字・平仮名を入力したモデル(従来法)
T2KT: Tacotron 2にアクセント情報のない片仮名を入力したモデル(従来法)
T2PP (Prop.): Tacotron 2に提案手法の韻律記号付き音素系列を入力したモデル(提案法)
DV3KH: Deep Voice 3に漢字・平仮名を入力したモデル(従来法)
DV3KT: Deep Voice 3にアクセント情報のない片仮名を入力したモデル(従来法)
DV3PP (Prop.): Deep Voice 3に提案手法の韻律記号付き音素系列を入力したモデル(提案法)
TRKH: Transformerに漢字・平仮名を入力したモデル(従来法)
TRKT: Transformerにアクセント情報のない片仮名を入力したモデル(従来法)
TRPP (Prop.): Transformerに提案手法の韻律記号付き音素系列を入力したモデル(提案法)
上記より、Tacotron 2[11], Deep Voice 3[12], Transformer-based TTS[13] の3つのSeq2seq音声合成の手法において、アクセントを付加した記号(T2PP, DV3PP, TRPP)の評価値がそれぞれ良い値(一番自然な音だった)となっている事が分かります。今回はアクセント記号を入れるか、入れないかで実験を行っていたので、アクセント記号を入れると、アクセントも含めて自然な音声になったと言える実験結果を得られました。実験結果も重要だったのですが、このアイデアがESPNetに実装されて「使えるもの」として認知されていったのはありがたい事でした。
この手法については、論文[5:5]が公開されているのと書籍「Pythonで学ぶ音声合成 機械学習実践シリーズ」や「進化するヒトと機械の音声コミュニケーション Vol.2」に解説があります。
実装は上記の「Pythonで〜」の著者 山本龍一さんが公開されているttslearnやESPNetにサードパーティー実装が公開されていますので気になる方はご覧いただければと思います。
このブログは音声を貼れないようなので、気になる方は論文のSupplementaryより音声を聞いてみてください。
リンク先のMultimedia file Download (ZIP)をダウンロードすると聞けます。
「一聞は一見にしかり」です。
その次の問題:日本語言語処理部
という事で、「日本語入力ができるseq2seq音声合成」ができました!
これで、正しい日本語アクセントの音声を出力する事ができます。
が、この記号付きの文字列を我々が普段使用している「漢字仮名交じり文」の文字列から、どう推定すれば良いのだ、、、という問題が出てきます。
音声合成を行うのに、「ホンジツ\ノ・カ\イギハ・コチラデ\ス」などと文章を打つわけにはいかないですよね。音声化するテキストは、日本語でコピペしたい!という当たり前の要求が出てきます。
日本語アクセントがどこにあるか、記号を振れる人って日本人でもあまりいないと思われます。
この変換タスクは、音声合成の中でも言語処理部と言われ、日本語以外でもGrapheme to Phoneme (G2P)と呼ばれており、音声合成の発音を良くするための改善が行われている分野です。この「アクセントと読み」の推定が難しいのです。固有名詞の読みをどう特定すれば良いのか、私自身も正しい解がありません。日本人の名前を100%正しく読むのって無理ゲーな気がしていますが、日本語言語処理部はそのような問題をクリアーしていかなければなりません。
次回以降は、この日本語言語処理部・日本語G2Pを対象に解説していきたいと思います。このあたりの問題設定が、日本語の難しさと直結してきますので、次回書く時はこの辺りを重点的に書きたいと思います。
This article is based on “Prosodic Features Control by Symbols as Input of Sequence-to-Sequence Acoustic Modeling for Neural TTS” [5], by the same author, which appeared in the Proceedings of “Prosodic Features Control by Symbols as Input of Sequence-to-Sequence Acoustic Modeling for Neural TTS,” Copyright (C) 2021 IEICE. The material in this article was presented in part at the proceedings of “Prosodic Features Control by Symbols as Input of Sequence-to-Sequence Acoustic Modeling for Neural TTS,” [5] and all the figures of this paper are reused from [5] under the permission of the IEICE.
-
Zen et al., Deep mixture density networks for acoustic modeling in statistical parametric speech synthesis, ICASSP, pp. 3844-3848, 2014. ↩︎ ↩︎ ↩︎
-
Tokuda et al., Speech parameter generation from HMM using dynamic features, ICASSP, pp. 660–663, 1995. ↩︎
-
Sotelo et al., Char2Wav: End-to-end speech synthesis, ICLR, 2017. ↩︎
-
Keith Ito, An implementation of Tacotron speech synthesis in TensorFlow, https://github.com/keithito/tacotron. ↩︎
-
Kurihara et al., Prosodic features control by symbols as input of sequence-to-sequence acoustic modeling for neural TTS, IEICE Trans. Inf. & Syst., E104-D, vol. 2, pp. 302-311, 2021. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
栗原ら, 読み仮名と韻律記号を入力とする日本語end-to-end音声合成の音質評価, 信学技報, SP2018-49, pp. 89-94, 2018. ↩︎ ↩︎ ↩︎ ↩︎
-
Kurihara et al., Enhancing Japanese text-to-speech accuracy with a novel combination transformer-BERT-based G2P: Integrating pronunciation dictionaries and accent sandhi, INTERSPEECH, pp. 2790-2794, 2024. ↩︎ ↩︎
-
Yasuda et al., Investigation of enhanced Tacotron text-to-speech synthesis systems with self-attention for pitch accent language, ICASSP, pp. 6905-6909, 2019. ↩︎
-
Kubozono, Japanese Dialects and General Linguistics, Journal of the Linguistic Society of Japan, vol. 148, pp. 1–31, 2015. ↩︎
-
藤崎ら, 日本語単語アクセントの基本周波数パタンとその生成機構のモデル, 日本音響学会誌, 27巻, 9号, pp. 445-452, 1971. ↩︎
-
Shen et al., Natural TTS synthesis by conditioning WaveNet on mel spectrogram predictions, ICASSP, pp. 4779-4783, 2018. ↩︎
-
Ping et al., Deep voice 3: Scaling text-to-speech with convolutional sequence learning, ICLR, 2018. ↩︎
-
Li et al., Close to human quality TTS with transformer, arXiv:1809.08895, 2018. ↩︎

Discussion