小さな分析チームで始めるマイクロデータメッシュ
一つのデータパイプラインの中で、やりたいこと毎に小さいパイプラインを作る
データ変換処理のパイプラインと言うのは、放置しているとどんどん複雑になる傾向にあります。
そこで、ある程度統制するため、層に分けるアプローチがよくとられています。

しかし、この層に分けると言うのは案外難しく、データ更新の頻度や鮮度の管理に課題があります。
今回はやりたい事ごとに都度パイプラインを作り、その中で他にも使えるテーブルを再利用してテーブルの乱立を防ぐ、方法を考えました。

このアプローチの実現にはいくつか制約があります。この記事では、直面している課題、アプローチの利点、そしてdbtを用いた実装方針について記載していきます。
この手法が着目している課題
データメッシュと言うと、大企業におけるデータマネジメントに近い印象を持つと思います。
上記の記事では、大企業における部署のような単位をドメインとしているので、組織体制まで踏み込んで装着していく必要があり、なかなか大変です。
しかし、パイプラインの複雑さは、組織の規模によらず、データが複雑であれば少人数でも管理できない状態に陥ると考えています。
そこで今回は、5~10人程度の1チーム内において発生するパイプラインの管理の課題に着目し、data mesh の考え方を小さなデータパイプラインマネジメントに取り入れることで、解決しようと試みています。
層に分けるというアプローチの限界
ELTのTransfer層は、いくつかの層に分けるアイデアが一般的です
例えば dbt では以下のようなパイプラインを紹介しています
How we structure our dbt projects
gitlab 社も層を定義しています
この層を分けるアイデアは SSoT を起点としていて、複数の用途に利用するための (dbtのケースで言う) mart 層の存在が共通点だと思います。
しかし、このmart 層に以下の課題があります。
- mart 層が保守されない
- データの鮮度・頻度は汎化できない
1.は、一度汎用的なものとして作ったテーブルも、いずれ古くなると言うのが課題です。
汎用性を維持するには、ビジネス背景やデータ生成元のシステムの拡張に応じて、この汎用テーブルも拡張していく必要があるのですが、大抵の場合はデリバリーの都合やスキルの問題で、下流の層で増築されてしまいます。
下流の層で増築されたのち、定期的に汎用テーブルを改修する、といったリファクタリングの文化を作って解決する必要があります。しかし、リファクタリングの重要性が理解され推進される環境はそう多くないのが現実かと思います。

2.は mart 層のテーブルの生成タイミングによるものです。ECサイトの例を用いて紹介します。
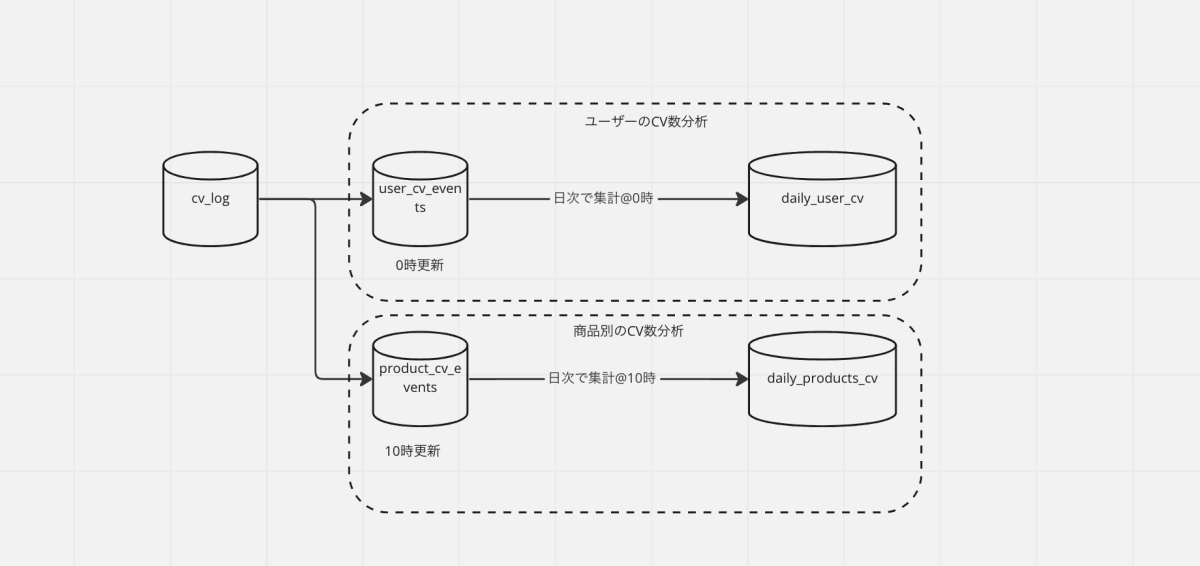
mart 層に、ユーザーのCVを記録した cv_events テーブルがあり、これを日次で集計した daily_user_cv テーブル が reporting 層にあります。
ユーザーのCV数は翌朝に前日までのデータをモニタリングするため、 cv_events テーブルと daily_cv は0時にバッチで更新されています。

ここで新たに、商品毎の CV 数を分析することにします。cv_events を商品毎に集計し、 daily_products_cv というテーブルを作ることにしました。
しかし、ユーザーのCV数の分析と違い、更新タイミングが0時ではなく、10時でした。新商品がサイトに反映されるのは毎朝10時だったためです。そこで、商品が切り替わる前のデータで分析できるよう、 cv_events と daily_cv_products は 10 時にバッチで更新することにしました。

この時、 cv_events は毎日 0 時と 10 時に更新される状態となり、どうも歪です。
10時に更新された cv_events は、0時~10時のデータが混ざっているため、前日までのデータをみたい daily_user_cv テーブルの参照元として使えなくなっています。cv_events は 汎化テーブルですが、0時に更新する場合と、10時に更新した場合とで、使える用途が異なっているわけです。
また、0時の実行タイミングでは cv_events の商品情報は下流で利用されず、 10 時の実行タイミングではユーザー情報が下流で使われません。使われないデータを生成するのも無駄に思います。
日に2回程度であればあまり問題ないですが、いずれ毎・毎分で分析したくなることもあります。そのためだけに、大福帳になりやすいCVテーブルの更新頻度を上げていくのはあまりSDG's とは言えないでしょう。
汎用テーブルではなく、個々のドメインで閉じたパイプラインを作る
①mart 層が保守されないこと、②データの鮮度・頻度は汎化できないことより、「なんでも使えるmart」と言うのは現実的ではなくなってきます。
そこで、層の分解を諦めてみようと思います。
さっきの例では、cv_events テーブルを個々の用途に分けて、例えば user_cv_events と product_cv_events に分けます。以下、この 「個々の用途」を、data mesh の呼び方に合わせて「ドメイン」と呼ぼうと思います。
これなら②の問題は起きず、個々の用途に合わせて更新頻度を上げれば良くなります。user_cv_events と product_cv_events は似ていますが、更新鮮度が違うので別物なのです。
しかし、この場合も問題は起きます。
例えば新たに、月次のユーザー毎のCV数を分析したいとします。分析は前月のものを翌月1日見るものとします。
user_cv_events_for_monthly と monthly_user_cv を作り、バッチの更新時刻は毎月1日の0時にしました。

さて、これは明らかに user_cv_events と user_cv_events_for_monthly が同じです。
user_cv_events から monthly_user_cv を作れるはずですし、更新タイミングも既存のもので良さそうです。これを許してしまうと、テーブルの乱立は避けられません。
そこで、「各自好きなようにパイプラインを作って良いが、他の人が作ってるテーブルで使えそうなものはなるべく再利用して良い」と言うルールにします。
こうすれば以下のように、テーブルの乱立を抑えた形になります。

しかし、そんな都合のいい設計が簡単にできれば苦労しません。
このやり方は、①テーブルが増えてくると既存のテーブルで使えそうなものを見つけられない、②見つかったとしてもあずかり知らぬところでテーブルの仕様が代わり、ある日突然動かなくなる と言うことが起きます。
ドメイン内部の汎用的なテーブルを外部公開する
先程の課題を、「外部に公開するテーブルを明確にする」と言うアプローチで解決します。
具体的には、各ドメインのパイプラインのうち、これはシンプルでいろんなものにも使えそうだ、と思ったものだけを、更新頻度・鮮度・スキーマ情報などのメタ情報をつけて、外部に公開します。
一度公開した外部テーブルは、原則変更しません。どうしても変更する場合は、リネームやシャーディング等を用いてバージョンを管理しつつ、ユーザーへの告知を行います。

外部に公開したテーブルは、情報を標準化して、検索できるようにします。
マニュアルでやるならそれらのテーブルをスプレッドシートで管理したり、カタログのように横断で探せるようなメタ情報検索プラットフォームがあると良さそうです。
外部公開テーブルを運用していくための制約
外部に公開するテーブルを管理しつつ、ドメイン毎にパイプラインを分解していくには、以下の制約が伴います
- 外部公開したテーブルを、ドメイン側の開発者が、責任をもってメンテナンスし、変更する場合は事前告知を行なった上でバージョン管理すること
- 外部公開されたテーブルを、利用者側が効率よく検索でき、利用是非を判断できる仕組みがあること
- 外部公開されたテーブルに不具合がある場合、利用者側のバッチで検知でき、下流のテーブルへの影響を把握できる仕組みがあること
ここまで読んでお気づきの方も多いと思いますが、 data mesh の principles によく似ています。
この規約を、部署も考え方も全く違う組織で運用するのは当然難しいですが、数名のチームであれば、 contributing のルールとして制定して実現できるレベルだと考えています。
この外部公開テーブルは、ソフトウェア開発におけるどのクラスからも利用できるパブリッククラスのような位置付けと考えています。
dbt の exposure を使ったマイクロデータメッシュの装着
このアイデアを具体的に運用するための手段の例を最後に紹介します。
dbt を使うと上記の制約を管理することができます。
exposure
dbt の exposure を使えば、外部公開しているテーブルを定義できます。exposure に記載するメタ情報は、dbt 側で一定のルールがあるため、既に標準化されている状態です。
本来はBIツールのようなものに展開するためのものと思いますが、同じ dbt project の別のパイプラインで参照する際に見るべき情報としても使えます。
各種の分析用途で作ったパイプラインのうち、これは汎用性が高いと思えるテーブルを、開発者が都度 exposure として定義していきます。
その後、他の分析をしたい場合は、開発をする前に exposure を探り、再利用できるものがないかをチェックしていきます。
yaml selector
dbt の yaml selector を使えば、用途毎に合わせて更新するテーブルをある程度機械的に指定できます。
exposure に指定されている別ドメインのテーブルは更新しないが、自分のドメイン内部のテーブルを更新する、といった更新パイプラインを作るのに適しています。
分析用途ごとに yaml selector を使って dbt run を実行し、更新するテーブルをドメイン内部で閉じるようにします。
tests, freshness
別ドメインのデータを使う場合は、そのデータがメタ情報に記載された通り更新されているかを確認した上でパイプラインを実行する必要があります。model に対しては dbt の tests でデータをテストでき、外部の dbt project については source に対する freshness を定義してデータをテストすることができます。
exposure を使って見つけたテーブルを参照する際は、必ずそのテーブルの鮮度を dbt test 等を用いてチェックし、エラーがあった場合は検知するようにします。
まとめ
data mesh で提唱されている、ドメイン側がデータを管理して提供する、と言う考え方を、数人の分析チームにおける、案件毎のデータパイプラインとして導入するアイデアを紹介しました。
人数が少なくても、扱うデータの種類が多かったり、分析する内容が複雑であれば、パイプラインは複雑になっていくと思います。
そこで、案件ごとにパイプラインを自由に作れるようにしてアジリティを維持しつつ、案件ごとに使えそうなテーブルは外部に公開し標準化するという仕組みを提案しました。
データ変換パイプラインの保守や、dbtのモデル構成に悩んでいる人がいたら、ぜひ参考にしてみてください。
Discussion