dbt を使ったデータマネジメントと adhoc クエリの共存
概要
BI用のデータパイプラインを運用していると、デリバリーを重視した分析を実施したくなることがあります。例えば広告運用や販促活動のように毎日コストがかかるものを運用している場合は、分析に数日かけて結果を待つということはなかなかできません。
一方で、スピードを重視して分析を行うと、集計ミスも発生しやすく、誤った事業判断を行ってしまうこともあります。分析用に作ったデータマートも乱立してしまい、結果的にスピードも落ちてしまうことも起こります。
この記事では、デリバリーと品質のバランスを取るために、dbt を使った ad-hoc クエリの運用事例をまとめています。
背景
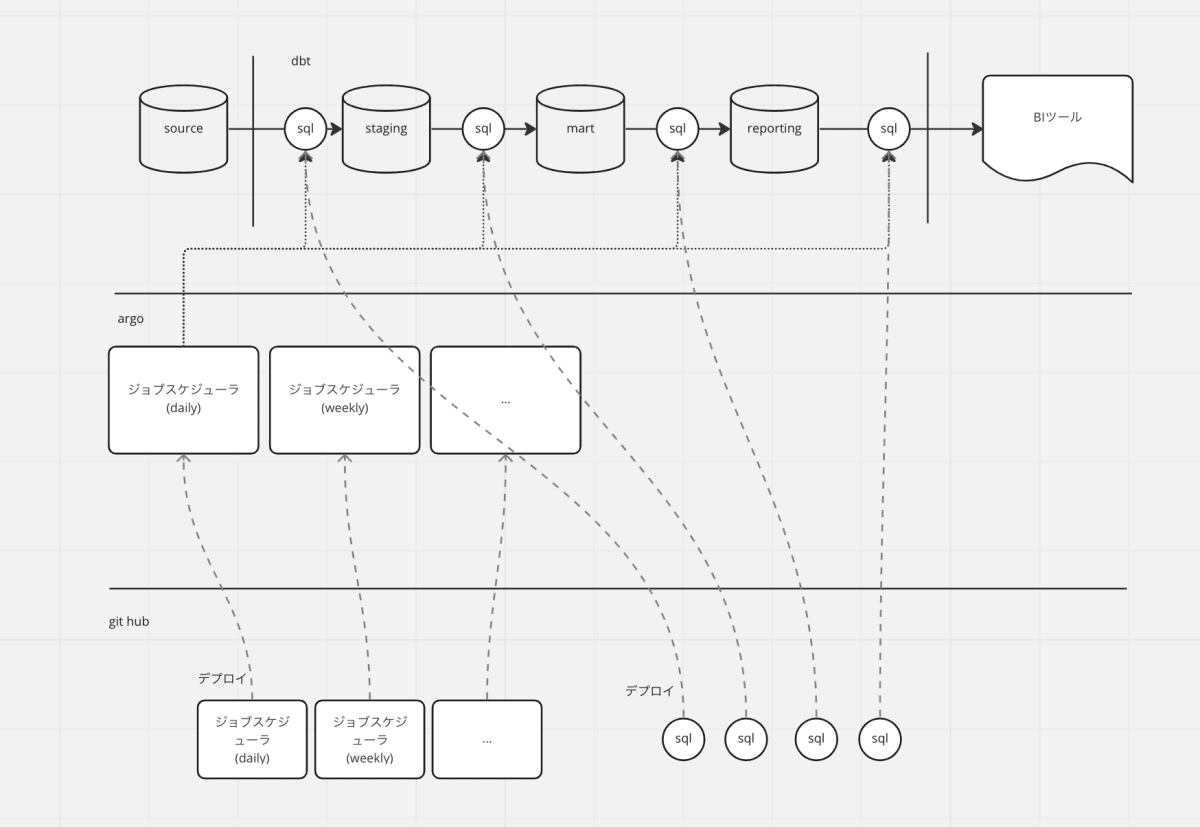
多くの dbt プロジェクトは、 ①データを加工・抽出するクエリ と ②クエリを定期実行してテーブルを日々更新するためのジョブスケジューラ の2つの要素で成り立っていると思います。
- ジョブスケジューラに argo を選定。dbt Core を argo から実行。
- staging / mart / reporting の3層構成とし、mart 層のデータはディメンショナルモデリングを実施
- git hub actions を用いたデプロイフロー
一方で、事業を行っていると、スピード感の強い課題も発生します。
- ABテストを実施しているが、有意差がみられていない。ABテストの期間内に、別の観点でも比較して、本当に有意差がないのか急いで確認したい。
- 新作商品の売り上げが落ち込んでいる。急ぎ原因を判断し、カスタマーが飽きない内に打ち手を実行したい。
上記のようなケースに対応できる分析用マートが事前に存在すれば良いのですが、新規のABテストや新作商品の場合は新しいデータを参照する必要も多く、クエリを書く必要も多いです。
このようなケースはデータパイプラインを使わず、BigQuery のコンソールからデータを毎日手動で抜き出したり、スプレッドシートやTableau, access などのツールを使ってデータを取得していました。最初はそれでも問題無いのですが、これが長期で運用され、気がつけばこのスプレッドシートが重要なKPIダッシュボードとなってしまう、ということになりがちです。
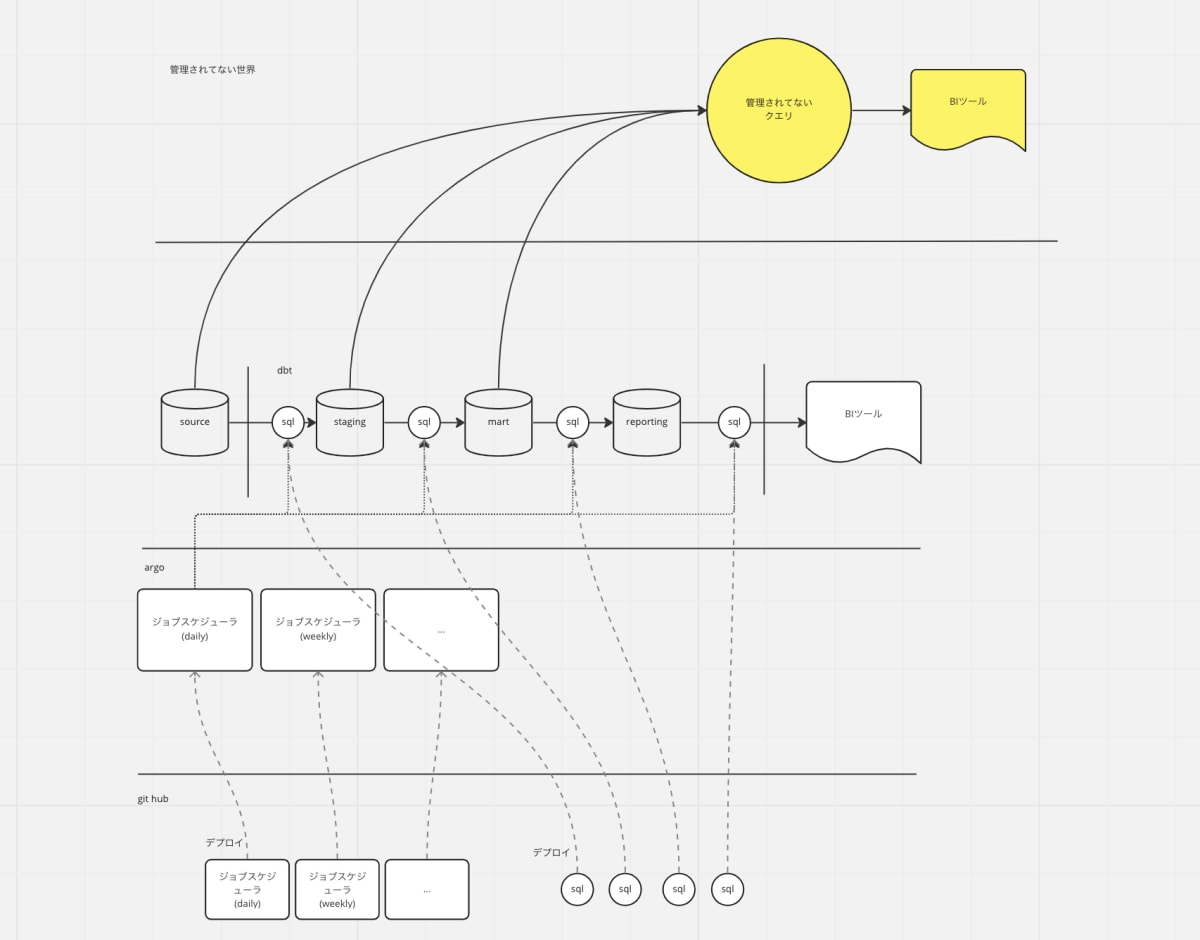
そこで、スピードを損なわず dbt で分析できる状況を実現するための運用事例を考えました。
考えたこと
想定するユースケース
品質とデリバリーはどうしてもトレードオフが発生してします。そこで、ユースケースを限定し、多少の品質を落としても良い前提条件を作ります。
- 分析した結果が内部でのみ利用される
- 新規事業やF/Sで始めたABテストの初速結果を振り返るなど、正確さよりもスピードが求められる状況
- 分析結果だけを完全に信じるわけではなく、あくまでも参考値として扱い、他の定性分析等を組み合わせて事業判断がなされる
実施したこと
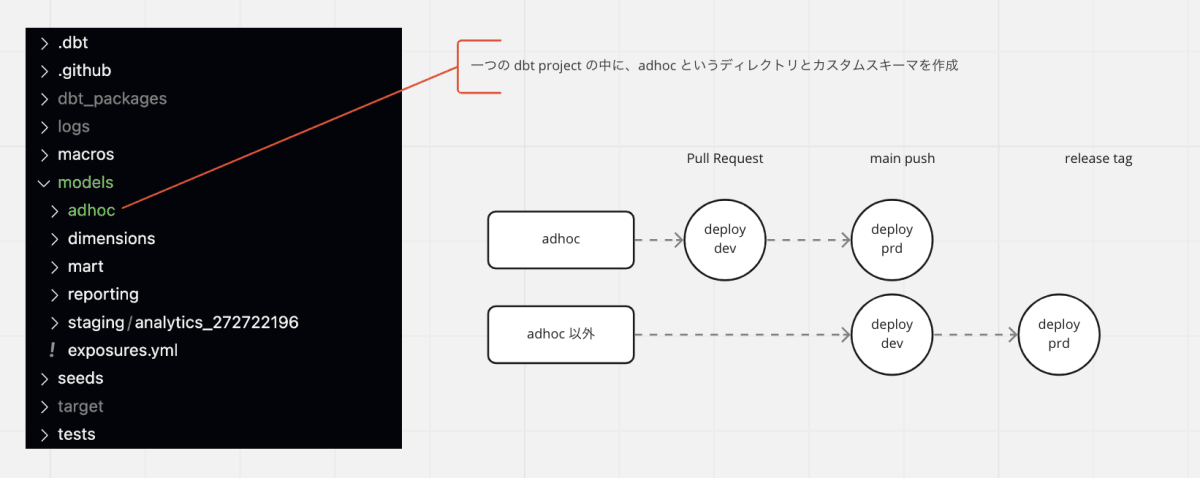
モノリポ、モノプロジェクト
dbt のリネージをたどれる状態とするため + コードの置き場所を一つにしました。
デプロイフローの切り出しとCI時間の削減
他の案件で main ブランチに不具合を起こしてしまうなど、リリースできないタイミングが生まれがちです。このような状況を可能な限り減らし、他の案件によって干渉されないようにしました。
通常は main push で dev 環境へのデプロイ、release tag で prd 環境へのデプロイとするところ、adhoc クエリのみ main push で prd 環境へのデプロイとしました。
dev 環境へのデプロイ省略に加え、tag を打たないため差分のみがデプロイされるため、CI時間を大きく削減しています。
また、 差分デプロイとなるため、仮に main ブランチにバグがある状態でも資材をリリースできます。
スケジューラの撤廃と ad-hoc view の運用
dbt のジョブスケジューラは、混雑する時間帯を避けたり、更新タイミングを合わせたりするため、tag や selector を使って実行タイミングを分けるなど、意外と運用が複雑になり、調整・検討することが多く実装のボトルネックになります。
ジョブスケジューラの検討をせずに、クエリがかける人なら本番環境に最新のデータを持ったマートを作れる状態を目指しました。
そこで、作られるモデルは view に限定しました。ただしいくつかの運用制約をつけました。
- 抽出
viewは性能面ではデメリットになります。BIの機能を使って、ローカル抽出することで解決を図りました。
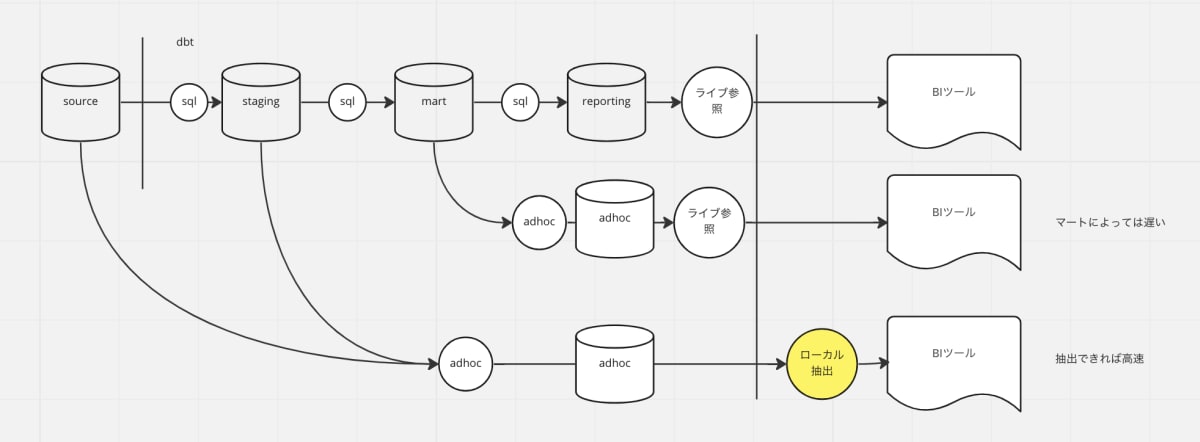
- 指向
品質の位置付けを分けるために、adhoc の view とそうでないテーブルは一方通行としました。
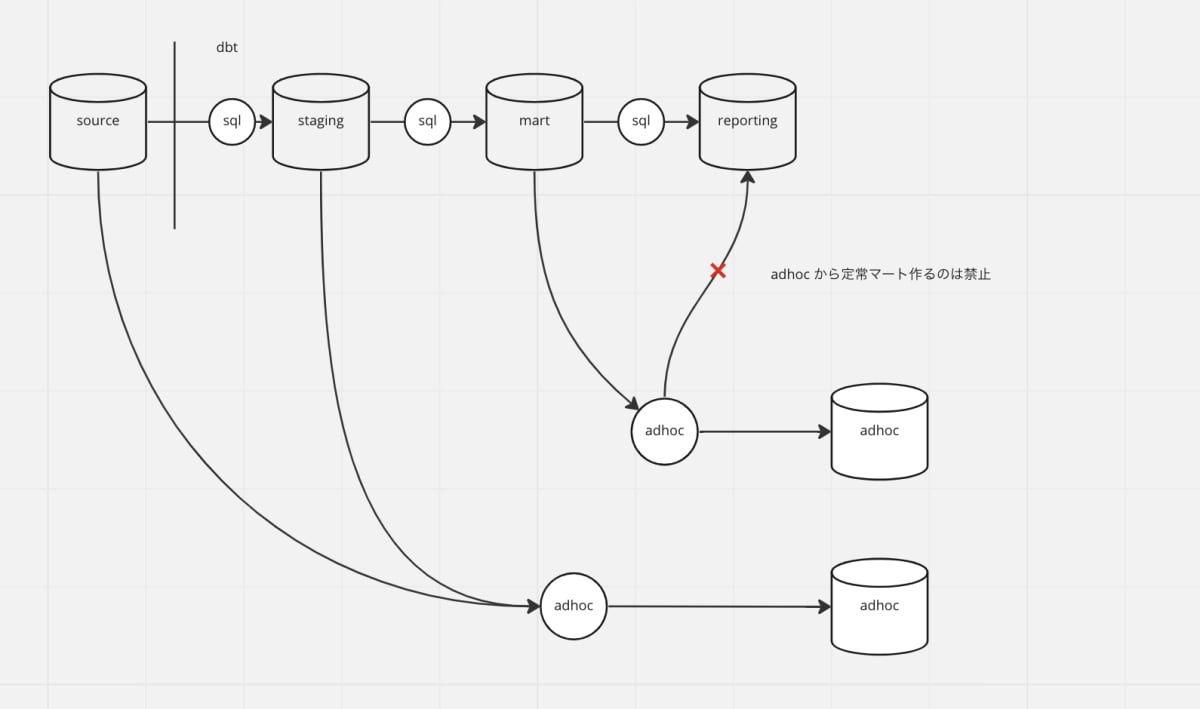
補足:adhoc のモデルを job から参照すると、リリースタイミングの違いによって、job の実行で view の中身が更新されてしまう。なので adhoc で書いたクエリは adhoc に閉じるよう制約を与えた。下流のテーブルは全て adhoc になる。
テスト
最低限、ソースの変更などによってレコード重複が起きるケースを検知するため、モデルごとに primary key test は必須とした。
※ assert_value や reference など追加のテストは大歓迎
この仕組みの効果
データマネジメント
間違っていた時にフォローできる状態にはなりました。
-
最低一人の approve があるクエリである
明らかにおかしなクエリや、全くテストのないクエリがリリースされるのを防止しました。 -
リポジトリにクエリがコミットされ、ソース管理ができている
不具合時、gitのコミットログから発生時期を調べることができ、バージョンの管理ができるようになりました。 -
リネージがたどれる
ソースデータの欠損など、障害時の影響調査を効率よく行えるようになりました。
クエリのライフサイクル
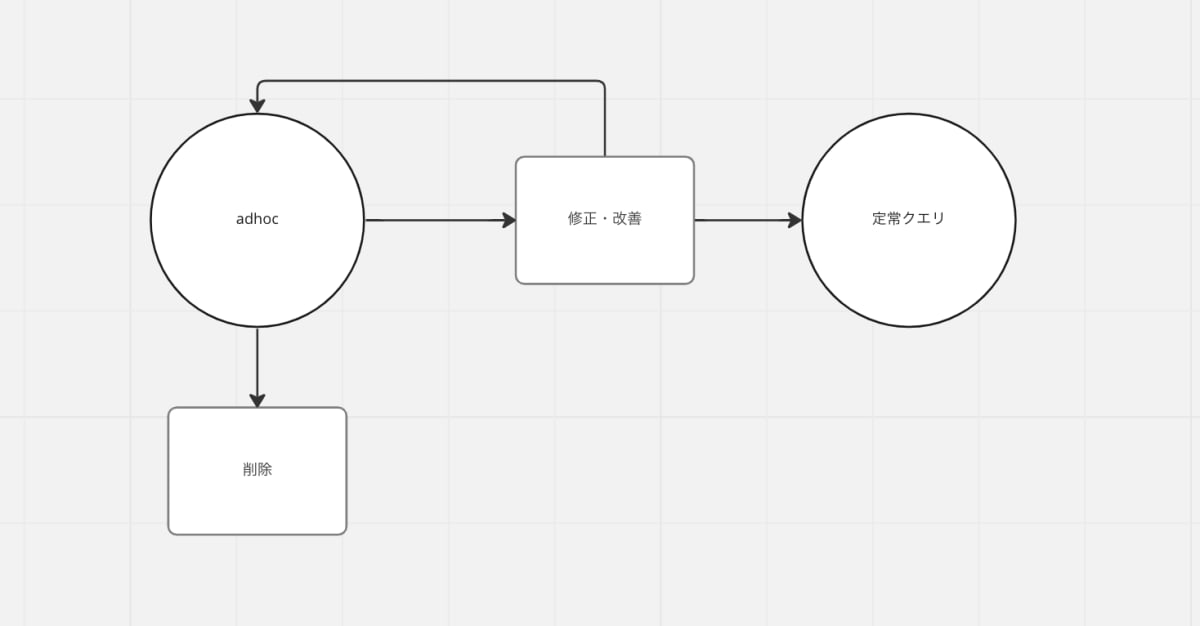
小さい検証をいっぱいできる環境として良く機能しました。分析は仮説検証の繰り返しでもあるので、なんとなく思いついたことを adhoc として作成しておいて、うまくいったらちゃんとモデリングし、そうでないものはそのまま削除する、といったサイクルは相性が良さそうでした。
job のことを考えなくていい効能
jobを作成するスキルを問わず、人気の環境でした。
job の処理をカプセル化するというのは、 adhoc 以外にも適用余地がありそうでした。例えばワークフローエンジンの運用だけ別チームに切り出し、分析チームはクエリの作成に集中する、というような分担も良さそうでした。
オンボーディングとしての adhoc
新規参画したメンバーのオンボーディングタスクに良かったです。dbt を初めて触るという人にとって、まずは dbt 記法で書いて本番環境にテーブルを作ることができる体験はスムーズな導入になりました。
課題
adhoc ではない adhoc クエリ
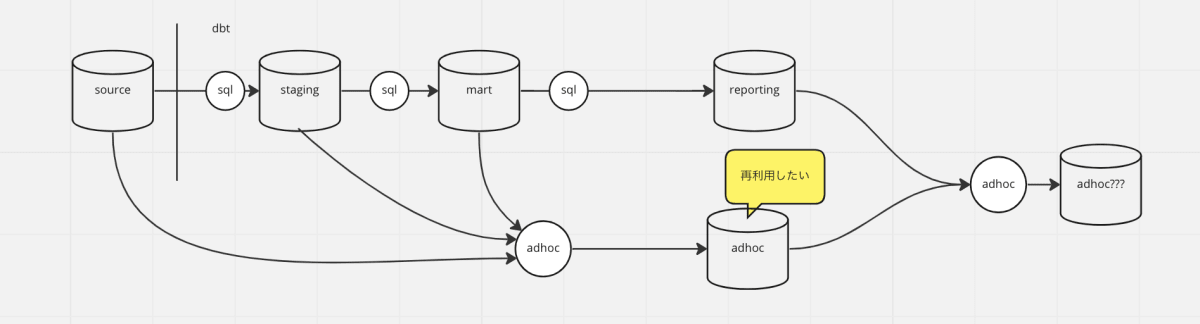
adhoc view を adhoc から参照させることを許容しました。
しかし、これは失敗だったかもしれません。元々単発の分析用途で提供していたが、 adhoc クエリで作った view を SSoT 的に再利用し始めるケースを止められませんでした。
結果、アドホックな要件でないものも、adhoc の view を使いたいがために、adhoc として作成する、という状況に陥りました。
adhoc view を再利用するようになったら、強制的にadhocから退場させるようなリファクタリングの仕組み、ルールを作る必要がありそうです。
リファクタリングの難しさ
アドホッククエリのリファクタリングはあまり進まなかった。①そもそもアドホックで書いたクエリの50%くらいしか長期で使われていかない or みてる人が数人のニッチなテーブルになっていた。②一度アドホックで出すと、次も近いデリバリー感の要件が飛んできてしまい、リファクタリングの時間が取れなくなってしまった。※クオリティを重視するフェーズにないチームなのか、単に看過してるだけなのかは見定め中。
<補足>リファクタリングはどんな時に行おうとしているのか
性能劣化、リソース超過、保守性の限界を迎えるとき。tobe 象というよりは、基本は課題ベースで修正を行なっていくのが良さそうです
- 性能劣化:view ではなく table や incremental を使いたくなるようなデータ量になったときに検討する
- リソース超過:BigQuery の場合、クエリが長大になると complex エラーが出てくる。このタイミングで検討する。
- 保守性の限界:求められるD要求に対して、実装工数が追いつかなくなったり、求められる品質に対して、集計ミスが多くなりすぎたときに検討する。
Discussion