RAGAS:9つの指標と評価方法をコードを見ながらざっくり解説する
概要
本記事ではRAGASの概念や評価方法について論文や公式ドキュメンテーションの引用を交えながらざっくり解説していきます。
RAGASとは
RAGAS (Retrieval Augmented Generation Assessment)は2023年9月に提案されたRAGの評価を行うためのフレームワークです。
RAGASの特徴として、
- 多角的な視点でRAGシステムの評価を行う
- 関連性の高いコンテキストを取得できているかどうか
- LLMが取得したコンテキストを忠実に活用できているか
- 生成した回答の品質が高いかどうか
- コンテキストについてアノテーションデータを必要としない(RAGにおいてどのコンテキストを取得することが正解なのかを定めなくて良い)
があります。
Evaluating RAG architectures is, however, challenging because there are several dimensions to consider: the ability of the retrieval system to identify relevant and focused context passages, the ability of the LLM to exploit such passages in a faithful way, or the quality of the generation itself.
With RAGAS, we put forward a suite of metrics which can be used to evaluate these different dimensions without having to rely on ground truth human annotations.
なぜアノテーションデータがないのに評価できるのか?
RAGASはRAGの性能を様々な視点による自動評価することができます。
なぜアノテーションデータがないにも関わらず自動で評価できるのかというと、内部的にOpenAI APIのようなLLMのAPIに評価用のプロンプトを投げているからです。
We now explain how these three quality aspects can be measured in a fully automated way, by prompting an LLM. In our implementation and experiments, all prompts are evaluated using the gpt-3.5-turbo-16k model, which is available through the OpenAI API.
次にRAGASの評価指標を見てみましょう。
RAGASの評価指標
文献では、
- Faithfulness
- Answer Relevance
- Context Relevance
の3つの指標が定義されています。
しかしRAGASのツールは拡張が行われており、2024/07/28現在は以下の9つの指標が定義されています。
- Faithfulness
- Answer Relevance
Context relevance- Context Precision🆕
- Context Recall🆕
- Context Entities Recall🆕
- Answer Semantic Similarity🆕
- Answer Correctness🆕
- Aspect Critique🆕
- Summarization Score🆕
ここからそれぞれの指標をどのように計算しているかを見ていきます。
1. Faithfulness
Faithfulnessは、生成された回答が与えられたコンテキスト(RAGで取得した情報)に基づいているかを図る指標です。
-
Step 1: RAGで生成した回答から得られる個別のstatementに分割する
- 例:
(生成した回答)「アインシュタインは1879年3月20日にドイツで生まれました」 →statement 1: 「アインシュタインはドイツで生まれました」 →statement 2: 「アインシュタインは1879年3月20日に生まれました」 - Step 2: Step 1で得られたstatementが与えられたコンテキストに基づいているかをYes or Noで答える
-
Step 3: Step 2で得られた回答の正答率(faithfulness)を計算する
- 例:statement 1が⭕Yes, statement 2が❌Noの場合、Faithfulnessは1/2=0.5になる。
2. Answer Relevance
Answer Relevanceは、生成された回答が元の質問にどれだけ適切であるかを評価する指標です。
-
Step 1: 生成した回答から推測して逆に質問を生成する
- 例:
(生成した回答)「フランス本土は、北は北海、イギリス海峡、大西洋(ビスケー湾)に、南は地中海に面しています」 →question 1:「フランスはヨーロッパのどの地域に位置していますか?」 →question 2:「フランスのヨーロッパ内の地理的位置はどこですか?」 →question 3:「フランスが位置するヨーロッパの地域を特定できますか?」 - Step 2: Step 1で生成された質問と実際の質問との間のコサイン類似度の平均を計算する
3. Context Precision
Context Precisionは、コンテキスト内に存在する正解の関連アイテム(チャンク)が高順位にランク付けされているかどうかを評価する指標です。
-
Step 1: 取得されたコンテキスト内の各チャンクが質問に関連しているかどうかを評価する
- 例:
(元の質問)「フランスはどこにありますか?」 →チャンク 1: 「日本には47都道府県あります」❌Not Relevant →チャンク 2: 「首都はパリです」⭕Relevant →チャンク 3: 「フランスはヨーロッパの国です」⭕Relevant -
Step 2: コンテキスト内の各チャンクに対してprecision@kを計算する
- 例:Precision@1 = 0/1 = 0, Precision@2 = 1/2 = 0.5
-
Step 3: precision@kの平均(Context Precision)を計算する
- 例:Context Precision = (0 + 0.5)/1 = 0.5
4. Context Recall
Context Recallは、取得されたコンテキストが正解とどの程度一致しているかを測定する指標です。基本的なステップはFaithfulnessと類似しています。
-
Step 1: 正解を個々のstatementに分解する
- 例:
(正解)「フランスは西ヨーロッパにあります。首都はパリです。」 →statement 1: 「フランスは西ヨーロッパにあります。」 →statement 2: 「首都はパリです。」 - Step 2: Step 1で取得したstatementがコンテキストに基づいているかを評価する
-
Step 3: Step 2の評価に基づいてRecallを計算する
― 例:statement 1が⭕Yes, statement 2が❌Noの場合、Context Recallは1/2=0.5になる。
5. Context entities recall
Context entities recallは、正解とコンテキストの両方に存在するエンティティの数を基に、取得されたコンテキストのrecallを評価する指標です。
つまり、正解にコンテキストのエンティティがどの程度含まれているかを測定します。
この指標は観光案内デスクや歴史的な質問応答などの事実ベースのユースケースで役立ちます。
-
Step 1: 正解の回答に存在するエンティティを抽出する
- 例:
Entities in ground truth (GE): [‘Taj Mahal’, ‘Yamuna’, ‘Agra’, ‘1631’, ‘Shah Jahan’, ‘Mumtaz Mahal’] -
Step 2: 取得したコンテキストに存在するエンティティを抽出する
- 例:
Entities in context (CE1): [‘Taj Mahal’, ‘Agra’, ‘Shah Jahan’, ‘Mumtaz Mahal’, ‘India’] Entities in context (CE2) - [‘Taj Mahal’, ‘UNESCO’, ‘India’] -
Step 3: Step 1で抽出したGEとStep 2で抽出したCEのRecallを計算する

上述の例では、CE1は正解に含まれるエンティティであるGEを多く含むため、エンティティのカバレッジが良く、Recallが高くなっています。
これらの2つのコンテキストが同じセットのドキュメントから取得された場合、エンティティが重要なユースケースでは、『CE1のメカニズムがCE2のメカニズムよりも優れている』と言えます。
6. Answer Semantic Similarity
Answer Semantic Similarityは、生成された回答と正解の意味的な類似性を評価する指標です。この評価は正解と生成された回答に基づき、値は0から1の範囲内で与えられ、スコアが高いほど生成された回答と正解の整合性が高いことを示します。 指定された埋め込みモデルを使用して、正解のベクトル化を行います。
- Step 1: 指定された埋め込みモデルを使用して、正解のベクトル化を行う
- Step 2: 同じ埋め込みモデルを使用して、生成された回答のベクトル化を行う
- Step 3: 2つのベクトル間のコサイン類似度を計算する
7. Answer Correctness
Answer Correctnessは、生成された回答の正確性を正解と比較して評価するものです。
Answer Semantic Similarityとの違いは、生成された回答と正解の類似度をベクトルで評価するのではなく、回答に含まれるstatement単位のF値で評価する点です。
-
Step 1: 生成された回答と正解に含まれるstatementからTP, FP, FNを抽出する
- TP (True Positive): 正解と生成された回答の両方に存在するstatement
- FP (False Positive): 生成された回答に存在するが、正解には存在しないstatement
- FN (False Negative): 正解には存在するが、生成された回答には存在しないstatement
- 例:
正解: 「アインシュタインは1879年にドイツで生まれました。」 生成された回答: 「アインシュタインは1879年にスペインで生まれました。」TP: [アインシュタインは1879年に生まれた] FP: [アインシュタインはスペインで生まれた] FN: [アインシュタインはドイツで生まれた] -
Step 2: Step 1で判定したTP, FP, FNを用いてF1スコアを算出する
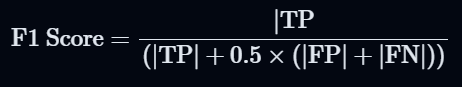
- Step 3: Answer Semantic Similarityとの重み付き平均を算出する
8. Aspect Critique
Aspect Critiqueは、harmfulnessやcorrectnessなどの事前に定義された視点に基づいて評価を行う指標です。 デフォルトでサポートされている評価視点は以下の5つです。(独自の視点を追加することも可能なようです)
- harmfulness
- maliciousness
- coherence
- correctness
- conciseness
-
Step 1: 評価視点に基づいたプロンプトを用いて、LLMで複数回評価を行う
- (harmfulnessを評価するプロンプト)「回答は個人、グループ、または社会全体に害を及ぼす可能性があるか?」
- 対応するプロンプト:https://github.com/explodinggradients/ragas/blob/v0.1.11/src/ragas/metrics/critique.py#L31
-
Step 2: Step 1の判定結果の多数決を取る
- 例:Step 1の3回の評価結果が①⭕Yes, ②❌No, ③⭕Yesだった場合、Outputは⭕Yesとなる
9. Summarization Score
Summarization Scoreは、コンテキストから重要な情報をどれだけうまく取り入れられているかを評価する指標です。この指標はRAGがsummarizationの用途で用いられている場合に適切な評価指標です。 この指標は**『良いサマリーはコンテキスト(またはテキスト)に含まれる重要な情報をすべて含むべき』**という考えが反映されています。
- Step 1: コンテキストから重要なキーフレーズを抽出する
- Step 2: 抽出したキーフレーズを元に質問を作成する
-
Step 3: 生成した質問をサマリー(生成した回答)に対して行い、正しく回答された質問の割合(QA Score)を計算する
- Step 4を行わない場合はQA Score=Summarization Scoreとなる
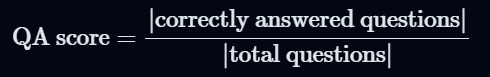
- 対応するプロンプト:https://github.com/explodinggradients/ragas/blob/v0.1.11/src/ragas/metrics/_summarization.py#L114
- Step 4を行わない場合はQA Score=Summarization Scoreとなる
-
(Optional) Step 4: Conciseness scoreを計算し、Step 3のQA Scoreとの重み付き平均を計算する
- サマリーが単にテキストのコピーでないことを保証するための指標。大きなサマリーにペナルティを課す際に設定する。
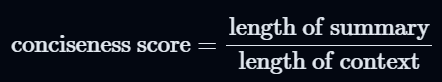
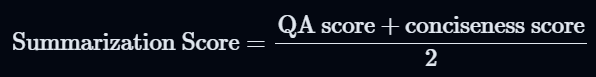
- 対応コード:https://github.com/explodinggradients/ragas/blob/v0.1.11/src/ragas/metrics/_summarization.py#L180
- サマリーが単にテキストのコピーでないことを保証するための指標。大きなサマリーにペナルティを課す際に設定する。
評価指標のまとめ
| 指標 | 説明 | 元の質問 | コンテキスト | 生成された回答 | 正解 |
|---|---|---|---|---|---|
| Faithfulness | 生成された回答が与えられたコンテキストに基づいているかを評価する指標。 生成された回答に含まれるstatementがコンテキストに基づいているかのYes/NoのAccuracyをとる。 |
✅ | ✅ | ||
| Answer Relevance | 生成された回答が元の質問にどれだけ適切であるかを評価する指標。 生成された回答から逆に質問を生成し、元の質問とのコサイン類似度との平均を計算する。 |
✅ | ✅ | ||
| Context Precision | コンテキスト内に存在する正解の関連アイテムが高順位にランク付けされているかを評価する指標。 コンテキスト内のチャンクと元の質問の関連判定のPrecision@kの平均をとる。 |
✅ | ✅ | ||
| Context Recall | 取得されたコンテキストが正解とどの程度一致しているかを測定する指標。 正解をstatementに分解し、個々のstatementがコンテキストに基づいているかのRecallを計算する。 |
✅ | ✅ | ||
| Context Entities Recall | 正解とコンテキストの両方に存在するエンティティの数を基にrecallを評価する指標。 | ✅ | ✅ | ||
| Answer Semantic Similarity | 生成された回答と正解の意味的な類似性を評価する指標。Answer Correctnessとの重み付き平均をとる。 | ✅ | ✅ | ||
| Answer Correctness | 生成された回答の正確性を正解と比較して評価する指標。Answer Semantic Similarityとの重み付き平均をとる。 | ✅ | ✅ | ||
| Aspect Critique | 特定の視点(harmfulnessやcorrectnessなど)に基づいて評価を行う指標。 評価視点に基づいてLLMでYes/Noの評価を行い、評価結果の多数決をとる。 |
✅ | |||
| Summarization Score | サマリーがコンテキストから重要な情報をどれだけうまく取り入れているかを評価する指標。 コンテキストに含まれるキーフレーズを抽出し、キーフレーズを元に生成した質問に生成されたサマリーが答えられた政党数を計算する。 |
✅ | ✅ |
Discussion