最強の言語モデル(LUKE)をQAタスク用にファインチューニングして公開してみた
こんにちにゃんです。
水色桜(みずいろさくら)です。
今回は現在(2023年1月)、世界最高精度を有している言語モデルであるLUKEをファインチューニングして、Question-Answeringタスク(SQuAD、狭義の質問応答)を行ってみようと思います。
作成したモデルはこちらのサイトで公開していますので、もしよろしければ使ってみてください。
今回も初心者でもたった2ステップ(ステップ1:必要なライブラリのダウンロード、ステップ2:コードのコピペ)で簡単に使えるようにしてあります。
このモデルを使えばチャットボットなども作成することが可能です。
環境
torch 1.12.1
transformers 4.24.0
Python 3.9.13
sentencepiece 0.1.97
transformersのバージョンが古いとLukeForQuestionAnsweringが含まれていないので注意してください。(上記のバージョンまでアップデートしてください)
LUKE

2020年4月当時、5つのタスク(Open Entity, TACRED, CoNLL2003, ReCoRD, SQuAD 1.1)で世界最高精度を達成した新しい言語モデル。
日本語バージョンのLUKEは執筆現在(2023年1月)も4つのタスク(MARC-ja, JSTS, JNLI, JCommonsenseQA)で最高スコアを有しています。RoBERTaを元として構成され、entity-aware self-attentionという独自のメカニズムを用いています。LUKEに関して詳しくは下記記事をご覧ください。
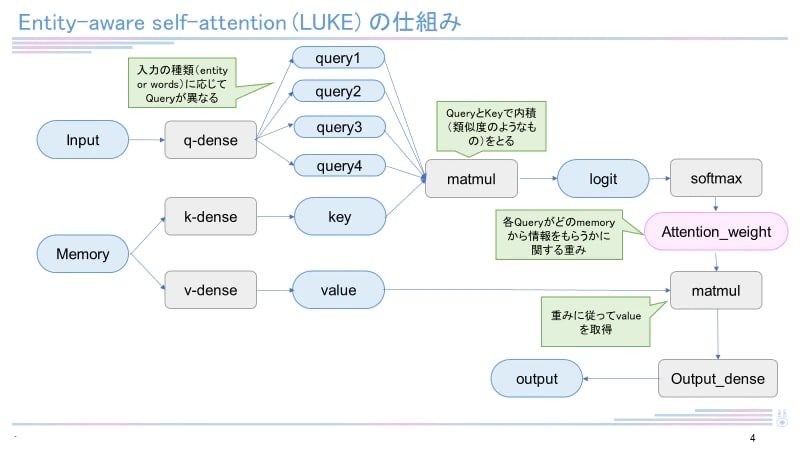
データセット
今回はファインチューニングのためのデータとして運転ドメインQAデータセット(DDQA)を用いました。
このデータセットはウェブ上で公開されている運転ドメインのブログ記事を基に構築されており、述語項構造QAデータセット(PAS-QAデータセット)と文章読解QAデータセット(RC-QAデータセット)から構成されています。その中でも、RC-QAデータセットは文章の中から質問に対する答えを抽出する問題です。今回はSQuAD(質問に対する応答(該当部分の抜き出し))の学習を行いたいので、RC-QAデータセットを用いました。
学習
下記のコードを用いて学習を行いました。
学習には時間がかなりかかるため、読者の皆さんはすでに作成しておいたこちらのモデルを利用することを強くお勧めします。
もし自分でファインチューニングをしてみたいという方は下記のコードを参考にしてみてください。
from transformers import AutoTokenizer, LukeForQuestionAnswering
import torch
import json
MODEL_NAME='studio-ousia/luke-japanese-base-lite'
tokenizer=AutoTokenizer.from_pretrained(MODEL_NAME)
model=LukeForQuestionAnswering.from_pretrained(MODEL_NAME)
import os, json
dataset_dir = "DDQA-1.0/RC-QA"
list_file = ["DDQA-1.0_RC-QA_train.json", "DDQA-1.0_RC-QA_dev.json", "DDQA-1.0_RC-QA_test.json"]
list_dataset = []
for fil in list_file:
with open(os.path.join(dataset_dir, fil),encoding='utf-8') as f:
dataset = json.load(f)
list_dataset.append(dataset['data'][0]['paragraphs'])
print(len(dataset['data'][0]['paragraphs']))
list_train, list_valid, list_test = list_dataset
# cl-tohoku/bert-base-japanese-whole-word-maskingのモデルは最大512トークンまで対応しているが、
# 学習時のGPUメモリ消費を抑えるため256としている
n_token = 251
def is_in_span(idx, span):
return span[0] <= idx and idx < span[1]
from collections import defaultdict
def preprocess(examples, is_test=False):
dataset = defaultdict(list)
all_starts, all_ends = [], []
for example in examples:
for qa in example["qas"]:
context, question, answers = example["context"], qa["question"], qa["answers"]
starts, ends = [], []
for i,answer in enumerate(answers):
encode = tokenizer(question, context)["input_ids"]
tokenized = tokenizer.decode(encode)
decode_str = tokenized.replace(" ", "").replace("<s>", "").replace("[PAD]", "").replace("##", "")
# decode後のコンテクストの開始位置(質問文長)
len_question = decode_str.find('</s></s>')
cnt = 0
start_position = 0
for i_t,e in enumerate(encode):
tok = tokenizer.decode(e).replace(" ", "")
if tok == "</s>" or tok == "<s>" or tok == "[PAD]":
continue
else:
if cnt <= len_question + answer["answer_start"]:
start_position = i_t
if cnt <= len_question + answer["answer_start"] + len(answer["text"]):
end_position = i_t
cnt += len(tok.replace("</s>", "").replace("<s>",""))
starts.append(start_position)
ends.append(end_position)
if (not is_test) or (i == 0):
dataset["contexts"].append(context)
dataset["questions"].append(question)
dataset["input_ids"].append(encode)
dataset["tokenized"].append(tokenized)
dataset["start_positions"].append(start_position)
dataset["end_positions"].append(end_position)
all_starts.append(starts)
all_ends.append(ends)
all_answers = (all_starts, all_ends)
return dataset, all_answers
from torch.utils.data import Dataset, DataLoader
class QADataset(Dataset):
def __init__(self, dataset, is_test=False):
self.dataset = dataset
self.is_test = is_test
def __getitem__(self, idx):
data = {'input_ids': torch.tensor(self.dataset["input_ids"][idx])}
if not self.is_test:
data["start_positions"] = torch.tensor(self.dataset["start_positions"][idx])
data["end_positions"] = torch.tensor(self.dataset["end_positions"][idx])
return data
def __len__(self):
return len(self.dataset["input_ids"])
from torch.utils.data import Dataset, DataLoader
class QADataset(Dataset):
def __init__(self, dataset, is_test=False):
self.dataset = dataset
self.is_test = is_test
def __getitem__(self, idx):
data = {'input_ids': torch.tensor(self.dataset["input_ids"][idx])}
if not self.is_test:
data["start_positions"] = torch.tensor(self.dataset["start_positions"][idx])
data["end_positions"] = torch.tensor(self.dataset["end_positions"][idx])
return data
def __len__(self):
return len(self.dataset["input_ids"])
dataset_train = QADataset(preprocess(list_train)[0])
dataset_valid = QADataset(preprocess(list_valid)[0])
pp_test, test_answers = preprocess(list_test, is_test=True)
dataset_test = QADataset(pp_test, is_test=True)
from transformers import Trainer, TrainingArguments
training_config = TrainingArguments(
output_dir = 'C://Users//desktop//Python//luke_squad',
num_train_epochs = 3,
per_device_train_batch_size = 8,
per_device_eval_batch_size = 8,
warmup_steps = 500,
weight_decay = 0.1,
do_eval = True,
save_steps = 470
)
trainer = Trainer(
model = model,
args = training_config,
tokenizer = tokenizer,
train_dataset = dataset_train,
eval_dataset = dataset_valid
)
trainer.train()
torch.save(model, 'C:\\Users\\desktop\\Python\\luke_squad\\My_luke_model_squad.pth')
result = trainer.predict(dataset_test)
import numpy as np
predictions = (np.argmax(result[0][0], axis=1), np.argmax(result[0][1], axis=1))
# トークン単位でのExact Match(厳密一致)とF1を計算
def evaluate(ground_truth, predictions):
em, f1 = 0., 0.
n_data = len(ground_truth[0])
for answer_starts, answer_ends, pred_start, pred_end in zip(ground_truth[0], ground_truth[1], predictions[0], predictions[1]):
for answer_start, answer_end in zip(answer_starts, answer_ends):
if pred_start == answer_start and pred_end == answer_end:
em += 1
break
f1_candidate = [calc_f1(ps, pe, pred_start, pred_end) for ps, pe in zip(answer_starts, answer_ends)]
f1 += max(f1_candidate)
return {"em": (em / n_data), "f1": (f1 / n_data)}
def calc_f1(gt_start, gt_end, pred_start, pred_end):
tp = max(0, (1 + min(gt_end, pred_end) - max(gt_start, pred_start)))
precision = tp / (1 + pred_end - pred_start) if 1 + pred_end - pred_start > 0 else 0
# 通常、1 + gt_end - gt_start > 0がFalseになることはあり得ないが念のため
recall = tp / (1 + gt_end - gt_start) if 1 + gt_end - gt_start > 0 else 0
if precision * recall > 0:
return 2 * (precision * recall) / (precision + recall)
return 0.
emf1=str(evaluate(test_answers, predictions))
print(emf1)
print('finished')
学習結果
'em': 0.845933014354067, 'f1': 0.9197176274789681
厳密一致(Exact match)は約85%でした。またf1値は0.92でした。厳密一致の割合は非常に高く(BERTでは0.15)、正確に応答できることがわかります。
モデルの利用方法
以下のコードを実行することでQAタスクを解くことができます。
import torch
from transformers import AutoTokenizer, LukeForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained('Mizuiro-sakura/luke-japanese-base-finetuned-QA')
model=LukeForQuestionAnswering.from_pretrained('Mizuiro-sakura/luke-japanese-base-finetuned-QA') # 学習済みモデルの読み込み
text={
'context':'私の名前はEIMIです。好きな食べ物は苺です。 趣味は皆さんと会話することです。',
'question' :'好きな食べ物は何ですか'
}
input_ids=tokenizer.encode(text['question'],text['context']) # tokenizerで形態素解析しつつコードに変換する
output= model(torch.tensor([input_ids])) # 学習済みモデルを用いて解析
prediction = tokenizer.decode(input_ids[torch.argmax(output.start_logits): torch.argmax(output.end_logits)]) # 答えに該当する部分を抜き取る
prediction=prediction.replace('</s>','')
print(prediction)
実行結果
苺
終わりに
今回はQuestion-Answeringタスクに対応したモデルに関して書いてきました。
厳密一致が0.85と非常に高く、さすがLUKEだと感じました。
もしよろしければぜひこのモデルを利用してみてください。
では、ばいにゃん~。
参考・謝辞
著者である山田先生およびStudio ousiaさんには感謝いたします
Discussion