世界最高精度を達成した言語モデルLUKEの論文を徹底解説(試しに使えるソースコードも記載)

こんにちにゃんです。
水色桜(みずいろさくら)です。
今回は2020年4月当時、5つのタスクで世界最高精度を達成した新しい言語モデルLUKEの論文について、新規性は何なのかなどについて書いていきたいと思います。
日本語バージョンのLUKEは執筆現在(2022年11月)も4つのタスクで最高スコアを有しています。
もし記事中で何かご不明な点、間違いなどがありましたら、教えていただけると嬉しいです。
2022年12月27日追記:LUKEをファインチューニングして感情分析に用いれるモデルを作成してみました。下記の記事に載せたリンクからモデルをダウンロードできます。LUKEを試してみたいという方はぜひ使ってみてください。
LUKEの特徴・新規性まとめ(お忙しい方向け)
- RoBERTaをベースに構成されたよ。
- 日本人を中心としたチームが開発したモデルがTransformersに採用されたのはLUKEが初めてだよ。
- Wikipediaから取得した固有表現注訳付きコーパスを用いて、ランダムにマスクされた単語を予測するタスクで事前学習を行ったよ。
- entity-aware self-attentionという新しいメカニズムを提案して、attention_scoreを計算する際、単語のタイプ(固有表現か否か)を考慮できるようにしたよ。
- 5つのタスク(Open Entity, TACRED, CoNLL2003, ReCoRD, SQuAD 1.1)で世界最高スコアを達成したよ。
LUKEへの導入、Attentionとは
Attentionは「深層学習モデルに入力されたデータのどの部分に注目するのかを学習し、利用する仕組み」のことです。Seq2Seqなどの従来手法では文全体を最終的に1つの固定長ベクトルに詰め込んで表現するため、文が長くなると意味を伝えるのが難しくなるという問題がありました。それに対して、Attentionはデコーダーにおいて、入力系列の情報を直接参照できるようにすることで、文が長くなっても適切に意味を伝えることができるようにしました。文全体の意味に加えて、単語を1語1語出力する際に毎回、対応する入力系列の単語を逐次的に考慮しながら翻訳します。また、注目度も含めて深層学習の誤差逆伝播によって学習できます。
RNNと比較した際のAttentionの利点(こちらを参考にしました)
- 高い性能が期待できる(現在の世界最高精度クラスのモデルの多くはAttentionを用いている)
- 高速に学習できる(RNN は時刻tの計算が終わるまで時刻t+1の計算をできず、GPU をフルに使えません。Transformer は推論時の Decoder を除いて、すべての時刻の計算を同時に行えるため GPU をフルに使いやすいです。)
- 構造が単純
Attentionの構造(こちらを参考にしました)

Attentionの基本はqueryとmemory(key, value) です。Attentionとはqueryを用いてmemoryから必要な情報を選択的に抽出する仕組みです。memoryから情報を抽出する際、queryはkeyによって取得するmemoryを決定し、対応するvalueを取得します。

例えば、食べ物というQueryに対して、「『いちご』が80%、『が』が5%、『好き』が15%くらい」という風に、Keyはどこにどれくらい注目するのかを決定します。
具体的な計算はQueryとKeyの行列積をとります。
行列積をとった後、softmax関数にかけることでAttention_weightが得られます。
Attention_weightはvalueから情報を取得する際に、どこにどれだけ注目するのかを示しています。
Attention_weightとvalueの行列積を計算することで、Inputのどこにどれだけ注目すればいいかという情報を持ったoutputを得ることができます。
LUKE
RoBERTaを元として構成された新しい言語モデル(entityも独立したtokenとして扱う)。entity-aware self-attentionという独自のメカニズムを用いています。開発当時(2020年4月当時)、5つのタスク(Open Entity, TACRED, CoNLL2003, ReCoRD, SQuAD 1.1)で世界最高スコアを達成しました。(画像はLUKEの論文より引用)



entity-aware self-attentionとは
結論から言うと、entity-aware self-attentionでは、単語間の関係を表すattention_scoreを計算する際に、ペアとなる単語の組み合わせ(単語×単語、単語×固有表現、固有表現×単語、固有表現×固有表現)によって用いられるQueryが異なるように設計されています。通常のself-attentionでは下のような計算式で出力が計算されます。(数式はLUKEの論文より引用)
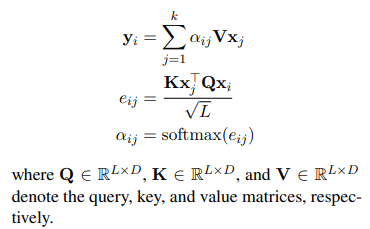
それに対して、LUKEでは下の数式のように、ペアとなる単語の組み合わせによってQueryが異なります。これらのQueryは元々のQueryを元にして、downstream dataset(Wikipediaから取得した固有表現注訳付きコーパス)を用いて、ランダムにマスク(全体の15%)された単語を予測するタスクで事前学習し、取得します。

これを踏まえると、entity-aware self-attentionは下のような構造であると考えられます。Queryがペアとなる単語の種類に応じて異なるため、より詳細に単語と単語の関係を把握することが可能になっています。

LUKEを用いたプログラム
このプログラムはLUKEが最も得意とする単語間の関係を把握するプログラムです。初回にデータがダウンロードされるのでデータ量に注意してください(Wi-fi環境下をお勧めします)。
from transformers import LukeForEntityPairClassification, LukeTokenizer
model = LukeForEntityPairClassification.from_pretrained('studio-ousia/luke-large-finetuned-tacred') # モデルの設定
tokenizer = LukeTokenizer.from_pretrained('studio-ousia/luke-large-finetuned-tacred') # トーケナイザ(形態素解析を行うもの)の設定
entity_spans = [(0, 3), (15, 29)] # どの単語とどの単語の関係を調べるか入力する
text = 'Taro belong to Keio university' # 解析したい文章
inputs=tokenizer(text, entity_spans=entity_spans, return_tensors="pt") # テキストを形態素解析する
outputs = model(**inputs) # モデルにかける
logits = outputs.logits # logits(確率をマッピングした配列)を抽出
predicted_class_idx = int(logits[0].argmax()) # 最も確率の高いインデックスを取得
print("Predicted class:", model.config.id2label[predicted_class_idx]) # インデックスが表す関係性を表示
実行すると、
Predicted class: org:parents
となります。日本語で「母体」という意味で、所属を表す関係性であることが判別できています。
終わりに
今回は新しい言語モデルであるLUKEについて解説をしてみました。
日本人を中心としたチームが開発したモデルがTransformersに採用されたのはLUKEが初めてであり、個人的にとても期待しています。
まだ解説記事も少ないですが、一人でも多くの方にLUKEの素晴らしさが伝わればいいなと思っています。
では、ばいにゃん~。
参考
LUKEの論文(著者である山田先生には感謝いたします)
attentionに関する説明を参考にさせていただきました
Discussion