最強の言語モデルLUKEを固有表現抽出(NER)用にファインチューニングして公開してみた
こんにちにゃんです。
水色桜(みずいろさくら)です。
今回はLUKEをファインチューニングして、固有表現抽出タスク(Named Entity Recognition, NER)を解くモデルを作成していきたいと思います。
作成したモデルはこちらのサイトで公開していますので、もしよろしければ使ってみてください。
今回も初心者でもたった2ステップ(ステップ1:必要なライブラリのダウンロード、ステップ2:コードのコピペ)で簡単に使えるようにしてあります。
環境
torch 1.12.1
transformers 4.24.0
Python 3.9.13
sentencepiece 0.1.97
transformersのバージョンが古いとMLukeTokenizer, LukeForQuestionAnsweringが含まれていないので注意してください。(上記のバージョンまでアップデートしてください)
LUKE

2020年4月当時、5つのタスク(Open Entity, TACRED, CoNLL2003, ReCoRD, SQuAD 1.1)で世界最高精度を達成した新しい言語モデル。
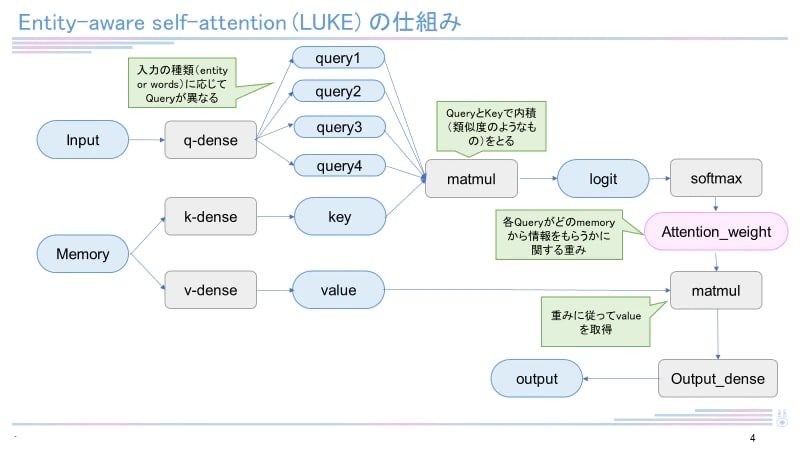
日本語バージョンのLUKEは執筆現在(2023年1月)も4つのタスク(MARC-ja, JSTS, JNLI, JCommonsenseQA)で最高スコアを有しています。RoBERTaを元として構成され、entity-aware self-attentionという独自のメカニズムを用いています。LUKEに関して詳しくは下記記事をご覧ください。
データセット
ストックマーク社が提供しているWikipediaを用いた日本語の固有表現抽出データセットを用いてファインチューニングを行いました。
このデータセットは日本語版Wikipediaから抜き出した文に対して、固有表現のタグ付けを行なったもので、全体で約4千件ほどとなっています。
学習
下記のコードを用いて学習を行いました。
学習には時間がかなりかかるため、読者の皆さんはすでに作成しておいたこちらのモデルを利用することを強くお勧めします。
もし自分でファインチューニングをしてみたいという方は下記のコードを参考にしてみてください。
import json
file_path = "ner.json"
with open(file_path,encoding='utf-8') as f:
list_data = json.load(f)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"studio-ousia/luke-japanese-base",
)
list_text = [data["text"] for data in list_data]
list_tokens = [tokenizer.tokenize(text) for text in list_text]
list_entities = [data["entities"] for data in list_data]
# 学習時のGPUメモリ消費を抑えるため256としている
n_token = 256
# encode後のトークンは、特殊トークン({CLS], {SEP]など)や特殊文字(##)が挿入されることに注意
# spanで表されているラベルと文字数ベースで位置ずれを起こすため、BIO形式に変換する際に補正する必要がある
list_text_id = [tokenizer.encode(text, truncation=True, padding='max_length', max_length=n_token) for text in list_text]
list_tokens = [tokenizer.convert_ids_to_tokens(encode) for encode in list_text_id]
def is_in_span(idx, span):
return span[0] <= idx and idx < span[1]
from collections import defaultdict
list_bio =[]
label2id = defaultdict(lambda :len(label2id))
_ = label2id["O"]
for text, tokens, entities in zip(list_text, list_tokens, list_entities):
bio = ["O"] * len(tokens)
for entity in entities:
cnt = 0
begin_flg = True
label = entity["type"]
for i, tok in enumerate(tokens):
if tok == "<s>" or tok == "</s>" or tok == "[PAD]":
continue
elif is_in_span(cnt, entity["span"]):
if begin_flg:
bio[i] = f"B-{label}"
begin_flg = False
_ = label2id[f"B-{label}"]
_ = label2id[f"I-{label}"]
else:
bio[i] = f"I-{label}"
cnt += len(tok.replace("</s>", "").replace("<s>","").replace('#',''))
list_bio.append(bio)
id2label = {v:k for k,v in label2id.items()}
list_bio_id = [[label2id[label] for label in bio] for bio in list_bio]
print(len(list_bio))
import torch
from torch.utils.data import Dataset, DataLoader
class NERDataset(Dataset):
def __init__(self, texts_id, bios_id, is_test=False):
self.texts_id = texts_id
self.bios_id = bios_id
self.is_test = is_test
def __getitem__(self, idx):
data = {'input_ids': torch.tensor(self.texts_id[idx])}
if not self.is_test:
data['label'] = torch.tensor(self.bios_id[idx])
return data
def __len__(self):
return len(self.bios_id)
from sklearn.model_selection import train_test_split
n_test, n_valid = int(len(list_bio) * 0.2), int(len(list_bio) * 0.1)
list_text_id_train, list_text_id_test, list_bio_id_train, list_bio_id_test = \
train_test_split(list_text_id, list_bio_id, test_size=n_test, random_state=0)
list_text_id_train, list_text_id_valid, list_bio_id_train, list_bio_id_valid = \
train_test_split(list_text_id_train, list_bio_id_train, test_size=n_valid, random_state=0)
ds_train = NERDataset(list_text_id_train, list_bio_id_train)
ds_valid = NERDataset(list_text_id_valid, list_bio_id_valid)
ds_test = NERDataset(list_text_id_test, list_bio_id_test, is_test=True)
print(len(ds_train), len(ds_valid), len(ds_test))
def padding_fn(batch):
x = torch.nn.utils.rnn.pad_sequence(batch, batch_first=True)
return x
from transformers import LukeForTokenClassification
model = LukeForTokenClassification.from_pretrained(
'studio-ousia/luke-japanese-base',
id2label=id2label,
label2id=label2id
)
from transformers import Trainer, TrainingArguments
training_config = TrainingArguments(
output_dir = './luke_ner_n',
num_train_epochs = 10,
per_device_train_batch_size = 8,
per_device_eval_batch_size = 8,
warmup_steps = 460,
weight_decay = 0.1,
save_steps = 460,
do_eval = True,
eval_steps = 460
)
trainer = Trainer(
model = model,
args = training_config,
tokenizer = tokenizer,
train_dataset = ds_train,
eval_dataset = ds_valid
)
trainer.train()
# モデルを保存する。
torch.save(model.state_dict(), "C:\\Users\\tomot\\desktop\\Python\\luke_ner_n\\My_luke_model_ner.pth")
print('saved')
result = trainer.predict(ds_test)
import numpy as np
trues = np.vectorize(lambda x:id2label[x])(ds_test.bios_id).tolist()
preds_id = np.argmax(result.predictions, axis=2)
preds = np.vectorize(lambda x:id2label[x])(preds_id).tolist()
from seqeval.metrics import classification_report
from seqeval.metrics import f1_score
print(f1_score(trues, preds))
print(classification_report(trues, preds))
print('finished')
学習結果
0.8430690349752793

全体の正答率は約0.843でした。スコアは非常に高く、正確に固有表現抽出を行えていることがわかります。特に人名・法人名に関しては非常に高い精度となっています。
モデルの利用方法
以下のコードを実行することで固有表現抽出を行うことができます。
from transformers import MLukeTokenizer,pipeline, LukeForTokenClassification
tokenizer = MLukeTokenizer.from_pretrained('Mizuiro-sakura/luke-japanese-base-finetuned-ner')
model=LukeForTokenClassification.from_pretrained('Mizuiro-sakura/luke-japanese-base-finetuned-ner') # 学習済みモデルの読み込み
text=('太郎は東京で買い物をした')
ner=pipeline('ner', model=model, tokenizer=tokenizer)
result=ner(text)
print(result)
終わりに
今回はLUKEを用いて固有表現抽出を行う方法について書いてきました。
固有表現抽出はLUKEが最も得意とするタスクであり、実際非常に高い精度を達成できています。
ぜひ皆さんもこのモデルを利用してみてください。
素晴らしい技術なので、LUKEがより一層普及することを切に願っています。
では、ばいにゃん~。
参考・謝辞
著者である山田先生およびStudio ousiaさんには感謝いたします
学習を行う際に用いたコードは以下の書籍を参考にさせていただきました
(とても分かりやすい良書なのでぜひ読んでみてください)
Discussion