Azure FunctionsのPythonプログラミングモデルと関数構造の比較
ネット上でのAzure FunctionsへのPythonでのコーディング方法は新旧の情報が入り乱れていてわかりづらいので整理してみました。
Azure Functionsの構造
まず、この後の説明のためにAzure Functionsの一般的な構成を概説します。これは利用する言語やフレームワークに依存しません。

Azure Functionsの構成概要
| 要素 | 概要 | 要素に属する設定等 |
|---|---|---|
| App Service Plan | ・関数アプリが実行される基盤(コンピューティングリソース) ・従量課金の場合は自動的に割り当てられスケール指定は不可。プレミアムプランや専用プランではスケール指定が可能 ・プレミアムプラン/専用プランではこのPlanの種類と稼働時間、インスタンス数が料金を決定する |
・AppServicePlanのプラン(インスタンスサイズ) ・リージョン・所属VNet ・(プランの)スケーリングルールや上限 |
| 関数アプリ (Function App) |
・Azure上で「リソース」として扱われる「複数の関数をまとめて管理・デプロイするためのコンテナ単位」 ・内部的にはプロセス・従量課金ではこの関数アプリの実行数 x 実行時間が料金を決定する(関数の実行時間ではない点に注意) ・URLを持ち、外部から見ると「Webサーバ」に対応 |
・デフォルトドメイン、カスタムドメイン ・ランタイム言語バージョン ・アプリキー ・マネージドID ・ストレージアカウント(コードを保存) ・常時利用可能インスタンス数(プレミアム/専用のみ) ・ (アプリの)スケールアウト上限 ・Application Insightsや診断設定などのログ設定 |
| 関数(Function) | ・特定のイベントに応じて実行される単一の処理単位 ・REST APIの場合は特定ホスト上の各APIに対応 (例: GET /api /usersや POST /api/users) |
・トリガー ・入出力バインディング ・関数キー |
Pythonのプログラミングモデルって?
Azure Functionsでは関数が呼び出される契機であるトリガーや関数の返り値の出力先を定義する必要があり、これらの設定によってAzure基盤とユーザーの作った関数を連携させることができます。
Pythonにおいてはこの定義スタイルが二種類あり、
プログラミングモデルv1
- トリガーや出力をfunctions.jsonという別ファイルで定義
- 各関数をモジュール(個別のディレクトリ内の__init__.py)として定義
プログラミングモデルv2
- トリガーや出力をPythonコード内のメソッドやデコレータで設定
- すべての関数をfunction_app.py内で定義(Blueprintによるファイル分割は可能)
という違いがあります。
それぞれのプログラミングモデルでのファイル構造とFunctions要素の対応は下図のようになります。
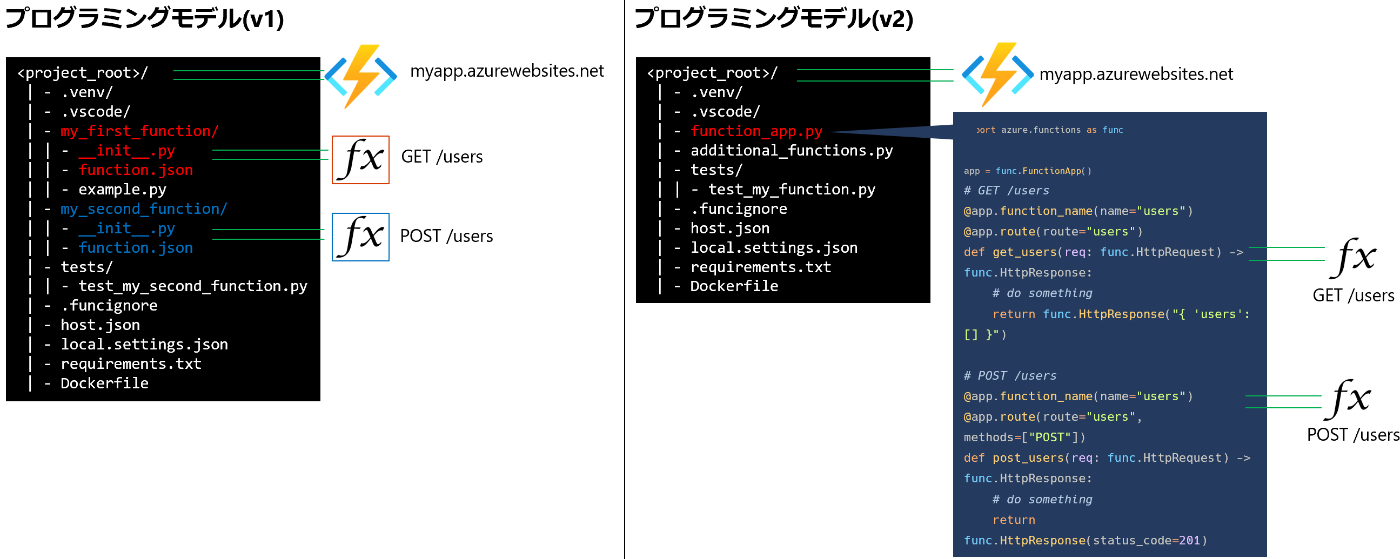
Azure Functionsの構成要素とプログラミングモデル毎のファイルの対応
プログラミングモデルv1では関数ごとにディレクトリを分割するのが必須、プログラミングモデルv2ではfunction_app.pyにまとまっているのが特徴となります。
プログラミングモデルv2で関数をファイル分割したい場合にはこちらのBlueprint記法を参照してください。
また、v1/v2のコード/設定ファイルの内容は以下のように異なります。

Pythonプログラミングモデルv1とv2のコード比較
具体的な動かし方
Pythonを使ったAzure Functionsの具体的な利用方法については以前の記事をご参照ください。
まとめと参考
ネット上にはAzure Functionsの開発に関するドキュメントがたくさんありますが、Pythonの場合には記載されているプログラミングモデルがどちらを前提としているか(自分の選択したモデルと合っているか)をきちんと識別できないと混乱しがちです。参考になれば幸いです。
v1/v2の詳細は下記ページを参照してください。
プログラミングモデルv1:
プログラミングモデルv2:
Discussion