mints: 5.7kb の TypeScript コンパイラを作った
世の中の TypeScript コンパイラが大きすぎるので作りました。
ここで試せます。 jsx と jsx pragma のサポートもしたので、 preact も動いています。
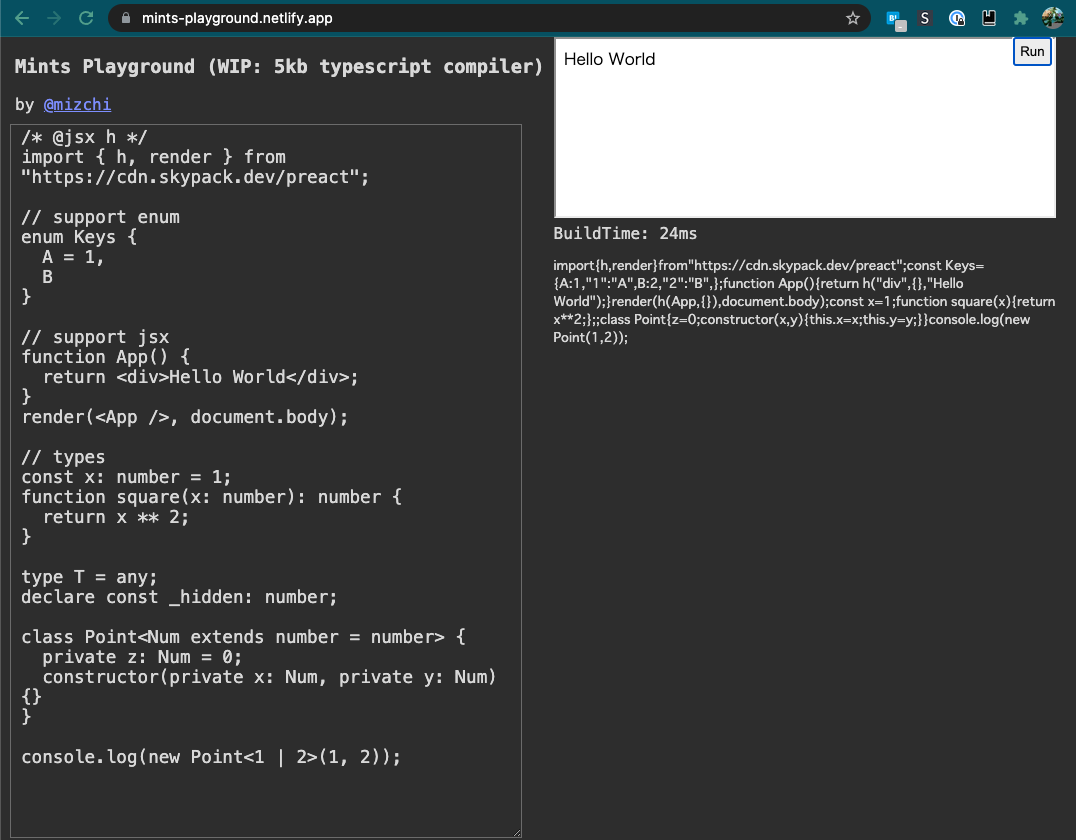
実装方針
- ビルドサイズ第一
- とにかく軽量に
- mints自体が他のコードをビルドするときの速度ではない点に注意
- 現状、まともなエラーレポートが出ない。エラーメッセージをインライン化するとビルドサイズが増えるため。
- 空白行と型情報を落とすだけ
- ES5 への変換や commonjs への変換は実装しない
- enum と constructor と jsx のみ transform する特殊対応をしている
- 真面目な構文解析をしてない
- 例えば 1+1*2 のような binary expression は結合順を解析してない。型を落とすだけなら不要
- prettier でフォーマットされたコードはコンパイルできるのが目標(空白行制御を真面目にやっていない)
-
foo;のような expression statement にはセミコロン必須とした。
なぜ作ったか
Web上で動く TypeScript + React のプレイグラウンドを何度か作ったのですが、この時問題になるのが TypeScript コンパイラのビルドサイズです。ページ中の簡易なTSコードにも巨大なコンパイラが必要になり、気軽にページ内にTSコンパイラを埋めることができません。また、開発環境としても都度 TypeScript の 2.9MB をバンドルするので、体験もよくありません。
これは本家 TypeScript がブラウザで動くには動くがビルドサイズを考慮してないのと、単にコンパイルする以外に様々な静的解析を備えているからですが、TSコードの型を落とすというゴールに対しては過剰です。TS 本体は古の namespace で書かれているので treeshake も効きません。
bundlephobia.com 各種コンパイラのサイズを比較してみました。gzip 前のサイズです。
- TypeScript: 2.9MB
- @babel/core + @babel/preset-typescript: 1.8MB
- sucrase: 176kb
- mints: 15kb
- esbuild-wasm: 8.4MB
- @swc/wasm: 16MB
これだけ小さければ、 プレイグラウンドに限らず、ビルド制限のある Edge Worker の中とか色々使い道がある気がします。
JS で書いた理由
本当は Rust+Wasm の練習として作ろうかと思ったのですが、 Wasm だとコアのランタイムだけで 6kb あり、nom みたいなパーサコンビネータのライブラリを使うと依存の依存でさらに膨らみます。
Geal/nom: Rust parser combinator framework
フルスクラッチで書けばいいとは思うのですが、なれてないのでビルドサイズ制御が難しいと思い、最初は慣れている TypeScript で実装することにしました。
書いてみた感想ですが、正直 JS だと文字列の効率的な扱いが難しいです。内部的に持ってる UInt16Array に対して正規表現を掛けたいことが何度もありましたが、JS だと都度エンコードしないといけません。
javascript - Why is array.prototype.slice() so slow on sub-classed arrays? - Stack Overflow
真面目な Rust 製 TypeScript パーサは Rome に任せとけばいい気もします。
Rome will be written in Rust 🦀
mints
今回実装した TypeScript Compiler です。
import {tranform} from "@mizchi/mints";
const code = `const x: number = 1;`;
transform(code).result; // => const x=1;
使うだけならこれだけです。まだAPI変えるかも。
pargen
既存のライブラリを使わず、専用のパーサコンビネータを作りました。
mints/packages/pargen at main · mizchi/mints
pargen は LL(k) + packrat cache のパーサコンビネータです。pegjs インスパイアです。
mints の 5.7kb のうち、 pargen が 2kb です。というか最初は pargen を作って複雑なのもいけそうな気がして TS パーサを書いてみた、という流れです。
内部的には $seq(), $or(), $repeat(), $not() という基本命令があり、これを組み合わせて構文を定義します。
例えば mints の const x: number = 1, y; の代入文のパースは次のように定義されています。
const assign = $def(() => $seq(["=", $not([">"]), _s, anyExpression]));
const variableStatement = $def(() =>
$seq([
$seq([declareType, __]),
$repeat_seq([
destructive,
_s,
$skip_opt(_typeAnnotation),
$opt($seq([_s, assign])),
_s,
",",
_s,
]),
_s,
destructive,
_s,
$skip_opt(_typeAnnotation),
$opt($seq([_s, assign])),
])
);
$skip(...) という直接 token を読みつつ捨てるという専用の処理があって、これによって TypeScript の型情報をパースしながら捨てています。
$skip_opt() は optional な skip なので、型を書いても書かなくてもいい、ということになります。いずれにせよ処理の上では無視されます。
名前を付けてオブジェクトとしてパースすることができます。例えば enum のパースと変形は次のような実装になります。
const enumStatement = $def(() =>
$seq(
[
K_ENUM,
__,
["enumName", identifier],
_,
K_BLACE_OPEN,
_,
[
"items",
$repeat_seq([
//
["ident", identifier],
["assign", $opt(enumAssign)],
_s,
$skip(","),
_s,
]),
],
[
"last",
$opt(
$seq([
["ident", identifier],
["assign", $opt(enumAssign)],
_s,
$skip_opt(","),
])
),
],
_,
K_BLACE_CLOSE,
],
(input: {
enumName: string;
items: Array<{ ident: string; assign?: string }>;
last?: { ident: string; assign?: string };
}) => {
let baseValue = 0;
let out = `const ${input.enumName}={`;
for (const item of [
...input.items,
...(input.last ? [input.last] : []),
]) {
let nextValue: string | number;
if (item.assign) {
const num = Number(item.assign);
if (isNaN(num)) {
nextValue = item.assign as string;
} else {
// reset base value
nextValue = num;
baseValue = num + 1;
}
} else {
nextValue = baseValue;
baseValue++;
}
const nextValueKey =
typeof nextValue === "number" ? `"${nextValue}"` : nextValue;
out += `${item.ident}:${nextValue},${nextValueKey}:"${item.ident}",`;
}
return out + "};";
}
)
);
課題
TS の JS Superset ではない部分
TS は JS のスーパーセットを謳っていますが、一部コードの変形を伴う実装があります。enum, decorator, constructor, jsx がそうです。
このうち、 decorator と namespace は使用頻度が低い+代替手段があるので未サポートとして、他は実装しました。
with
デコレータ、with 文に対応していません。
jsx の <button disabled></button> のような右辺値省略でtrueになる構文に対応していません。
jsx は作ったばかりでまだちゃんとデバッグしてないので、バグが多そうな気がしています。
マルチバイト文字のカウント
「𠮷」みたいな文字コードが大きい一部の文字列を使うとトークナイズがズレます。
今後やりたいこと
パフォーマンス
現状、ビルド速度は tsc の数倍遅いです。
構文定義を工夫する、オプティマイザを作る、プリプロセスでstatementを分割して並列ビルドする、などの工夫があります。
そもそも tokenize フェーズがなく直接コードを読んでるのをやめるといいかもしれません。
結果として、今こういうプリプロセスが存在してしまっています。
export function preprocess(input: string) {
const { escaped, literals } = escapeLiteral(input);
const out = escaped
// delete inline comments /*...*/
.replace(/\/\*(.*?)\*\//gmu, "")
// delete line comments
.replace(/(.*?)(\/\/.*)/gu, "$1")
// delete redundunt semicollon except for statement
.replace(/(?<!for\s?\()([\n\r\t; ]*;[\n\r\t ;]*)(?!\))/gmu, ";")
// delete redundant whitespaces
.replace(/[ \t]+/gmu, " ")
// delete redundunt whitespaces after control token
.replace(/([\}\{\(\)\n\r,;><])[\n\r\t]+\s*/gmu, (_, $1) => $1);
return restoreEscaped(out, literals);
}
今の所3倍ぐらい遅いです。
compileTsc [0] 75
compileTsc [1] 21
compileMints [0] 65
compileMints [1] 54
compileTsc [0] 34
compileTsc [1] 23
compileMints [0] 100
compileMints [1] 62
compileTsc [0] 36
compileTsc [1] 32
compileMints [0] 106
compileMints [1] 84
compileTsc [0] 132
compileTsc [1] 96
compileMints [0] 775
compileMints [1] 575
compileTsc [0] 92
compileTsc [1] 73
compileMints [0] 286
compileMints [1] 249
test262
JS レベルですべてパースできることを保証するのに、test262 を通すまで頑張る、というのがあります。
tc39/test262: Official ECMAScript Conformance Test Suite
読みやすいエラーメッセージの生成
現状、内部のエラー構造をそのままダンプしてるだけです。これは主に $or が上から順に試した結果でハンドルすることを想定していて、人間が読む用のデータじゃありません。
haskell の parsec は一番深いエラーを報告するという実装みたいで、これを真似るのはそう難しくなさそうです。
構文定義の圧縮
他のパーサジェネレータが大抵は持ってる機能で、pargen で記述している構文定義を JSON or Binary にエンコードしてしまえば、ビルドサイズが減ります。
試作した感じ、 15kb が 8kb ぐらいになり、 pargen の構文ビルダやオプティマイザも最終ビルドから除去でき、またビルダが初期化時に行っていた構文構築部分もなくなってCPUコストも減る、といいことづくめなんですが、代わりにエンコード出来る表現に縛られるので実装の自由度が減ります。
実際自由度が減ることで困ることは少なくて、関数にポインタを割り当てて別途宣言しておく、ぐらいでしょうか。
PR歓迎
コードが汚いのが申し訳ないんですが、5.7kb と他にない特徴があるので、面白いと思います。。
packrat のパーサーは今回始めて実装したこともあり、拙い実装なので、パーサに自信ニキなどにアドバイスいただけると嬉しいです。
単にこのコードのパースが通らない! といった内容でも構いません。
mints の構文定義
pargen の parse 処理本体
よろしくおねがいします。
Discussion