Playwrightを参考にブラウザ内テキスト検索を高速化する (事例紹介:サードパーティスクリプト提供会社)
ブラウザ内テキスト探索の高速化というテーマで改善を行いました。公開許可は頂いていますが、先方の希望で社名は伏せさせていただきます。
技術的には「再現性がある木構造のノード探索の条件の生成、その実行の高速化」という少しR&Dっぽいタスクでした。Playwright のコードを参考にしつつ、個別により速いパーツで置き換えていく、というもので非常に興味深いものでした。こういう仕事は楽しいので、いくらでも歓迎です。
今回は最初はドメイン理解に時間をあてて、その後十分にドメイン理解が進んだら計測しつつ改善する、という流れです。
以下、敬称略。
相談内容
ブラウザを自動操作する技術を開発している。技術的には一種のE2Eテストの応用技術で、サーバーに要素の探索条件と、その操作を登録する。
今回の相談では、その要素探索が重くなってしまうケースがあり、これを改善してほしい、という依頼。とくにテキストを条件に使った際のマッチが遅い。
技術的なドメインの理解
Playwrightのコードリーディング、それを組み込んだ実装の調査、という流れで進めていく。
Playwright
Playwright の Chrome エクステンションからコードを移植している。
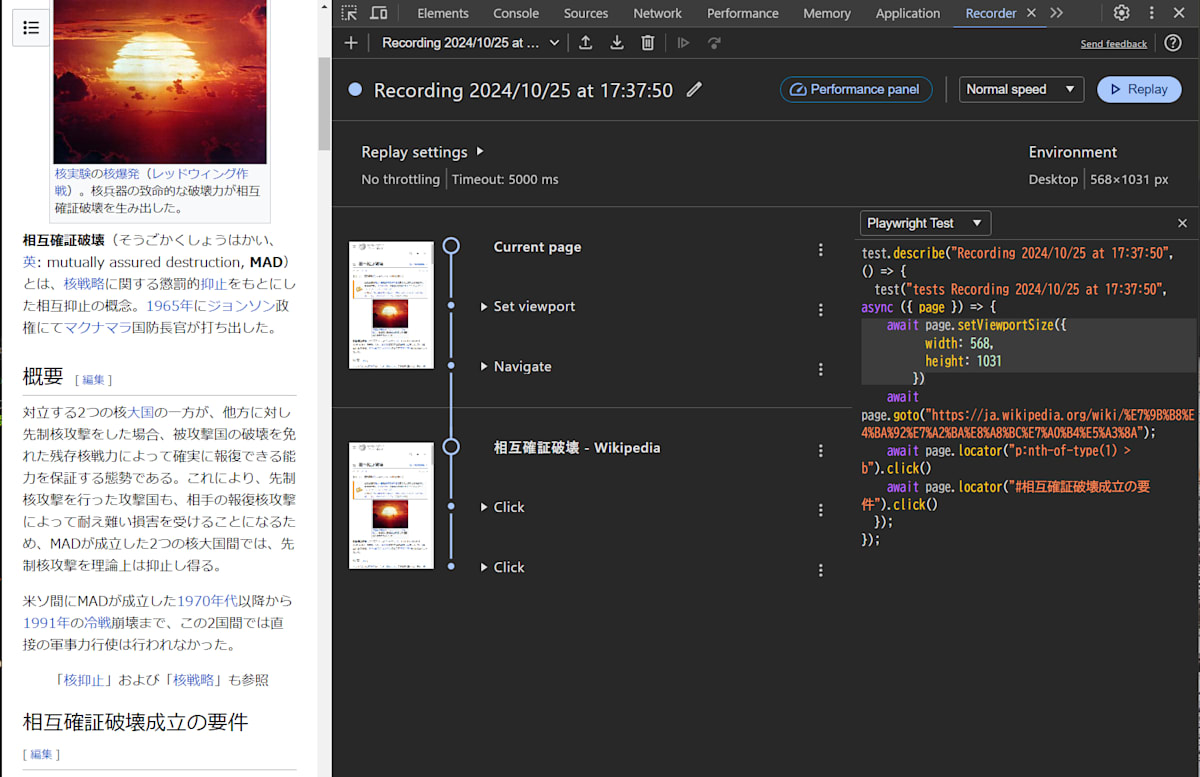
これによって、ブラウザ操作からE2EシナリオのPlaywrightのテストコードを自動生成することができる。便利。
TODO: 勉強のため、ここだけ取り出した npm の module を作ったのを公開する。
セレクタ生成に Chrome拡張からクライアントの払い出して注入するコードを使っている。以下、これを InjectedScript と呼ぶ。
これは手元で動かせるようにリファクタしたサンプルコード。
import { InjectedScript } from "./playwright-injected/injectedScript";
import { generateSelector } from "./playwright-injected/selectorGenerator";
const injector = new InjectedScript(
window,
false,
"javascript",
"text/javascript",
0,
"Chrome",
[]
);
// 試しに全要素のセレクタを生成してみる
for (const el of document.querySelectorAll("*")) {
console.log(
generateSelector(injector, el as HTMLElement, {
testIdAttributeName: "data-testid",
}).selector
);
}
/*
html
head
script >> nth=0
meta >> nth=0
meta[name="viewport"]
title
script >> nth=1
internal:text="clickme span list item 1 list item"i
#foo
internal:role=button[name="clickme"i]
div >> internal:has-text="span"i
internal:text="span"i
internal:text="list item 1 list item"i
internal:text="list item 1"i
internal:text="list item 2"i
*/
注目する点は、internal:has-text="span"i のような表現で、普通のCSSセレクタではテキストに対する探索が表現できない表現を含んでいる。
前提知識として、今のブラウザの仕様だと CSSクエリによるテキスト条件は許されていない。次のようなセレクタはない
button[textContent="click-me"]
Playwright拡張では、この拡張セレクタを入力として Playwright の locator 命令に変換する
import { asLocator } from "./playwright-injected/server-iso-utils/locatorGenerators";
//...
for (const el of document.querySelectorAll("*")) {
const gen = generateSelector(injector, el as HTMLElement, {
testIdAttributeName: "data-testid",
});
const locator = asLocator("javascript", gen.selector);
console.log(locator);
}
/*
locator('html')
locator('head')
locator('script').first()
locator('meta').first()
locator('meta[name="viewport"]')
locator('title')
locator('script').nth(1)
getByText('clickme span list item 1 list item')
locator('#foo')
getByRole('button', { name: 'clickme' })
locator('div').filter({ hasText: 'span' })
getByText('span')
getByText('list item 1 list item')
getByText('list item 1')
getByText('list item 2')
*/
元のセレクタのデータをすべて保持しているわけではなく、各セレクタルールに対してヒューリスティックなスコアがついており、「より有意なセレクタ」を優先する計算が内部で行われている。
// selectorGenerator
function penalizeScoreForLength(groups: SelectorToken[][]) {
for (const group of groups) {
for (const token of group) {
if (
token.score > kBeginPenalizedScore &&
token.score < kEndPenalizedScore
)
token.score += Math.min(
kTextScoreRange,
(token.selector.length / 10) | 0
);
}
}
}
Playwright 拡張のテキスト探索の実装
今回は Chrome 拡張の権限(=ユーザーとほぼ同じ立場)なので WebDriver でしか実行できない locator 変換を通していない。つまり最初のセレクタ表現をそのまま保持している。
これによって要素探索の再現性は非常に高いのだが、本来locatorを作るための中間データなので、Playwright 自体は実行時のパフォーマンス面をあまり考慮していない気配があった。
そういう前提で、 Playwrightテキスト条件検索をどう実装しているのだろうか。InjectedScript の実装を読むと、DOMを全探索して自前のテキストインデックスを作っていた。
// https://github.com/microsoft/playwright/blob/ff5f1628dc8dbbb0217554adc3105bff4e0a504c/packages/playwright-core/src/server/injected/selectorUtils.ts#L63
export function elementText(cache: Map<Element | ShadowRoot, ElementText>, root: Element | ShadowRoot): ElementText {
let value = cache.get(root);
if (value === undefined) {
value = { full: '', normalized: '', immediate: [] };
if (!shouldSkipForTextMatching(root)) {
let currentImmediate = '';
if ((root instanceof HTMLInputElement) && (root.type === 'submit' || root.type === 'button')) {
value = { full: root.value, normalized: normalizeWhiteSpace(root.value), immediate: [root.value] };
} else {
for (let child = root.firstChild; child; child = child.nextSibling) {
if (child.nodeType === Node.TEXT_NODE) {
value.full += child.nodeValue || '';
currentImmediate += child.nodeValue || '';
} else {
if (currentImmediate)
value.immediate.push(currentImmediate);
currentImmediate = '';
if (child.nodeType === Node.ELEMENT_NODE)
value.full += elementText(cache, child as Element).full;
}
}
if (currentImmediate)
value.immediate.push(currentImmediate);
if ((root as Element).shadowRoot)
value.full += elementText(cache, (root as Element).shadowRoot!).full;
if (value.full)
value.normalized = normalizeWhiteSpace(value.full);
}
}
cache.set(root, value);
}
return value;
}
これは与えられたノード以下を再帰的に全探索して、そのテキストをかき集める。
検索時は、このかき集めたテキストに対してテキスト条件を判定する。
組込み時の拡張: MutationObserverの変更監視
現代のウェブサイトは動的に書き換わるので、一度探索して終わりではない。
つまり、DOMを監視して変更があるたびにキャッシュを破棄してテキストインデックスを再構築しないといけない。
const observer = new MutationObserver((records) => {
//再インデックス
});
observer.observe({
childList: true,
subtree: true,
attributes: true,
characterData: true,
})
セレクタ生成側だけではなく、セレクタの利用側もテキストインデックスを作っているので、場合によって毎フレーム発火していくらで重くなる。Playwright InjectedScript は locator を作って捨てていたので、問題になっていない。
(後述する計測処理でも実際に重く計上されていた)
ここまでである程度ドメイン知識が溜まったので、実際に組み込まれた環境で実行コストを調査していくことにした。
組込み実装の調査: 計測しつつ改善
このWikipediaのページで実験していた。特に意味はない。
基本的に、ブラウザをブロッキングしないために、実行フレームで 16ms を超えた部分を適当にピックして内訳を見ていった。
DevTools の Performance タブで、JSタスク単位の BottomUp で見ている
計測上、実際に問題になった点
- lodash.isElement のCPU消費量が多い 約9ms
- テキストインデックス(elementText)が重い 約13ms
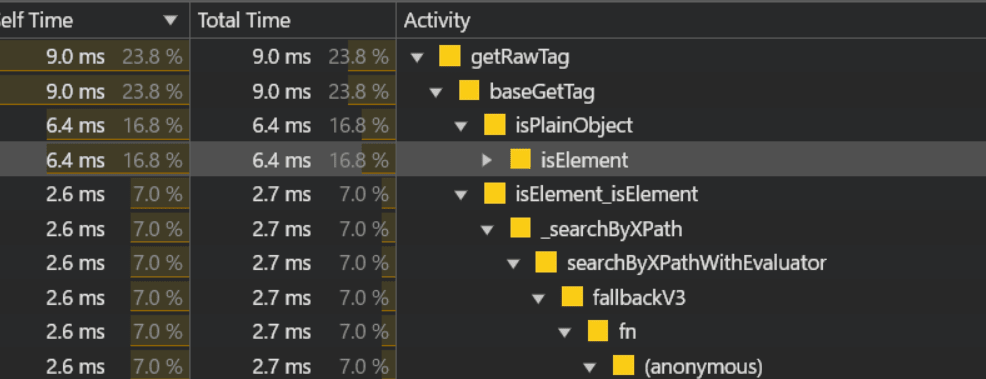
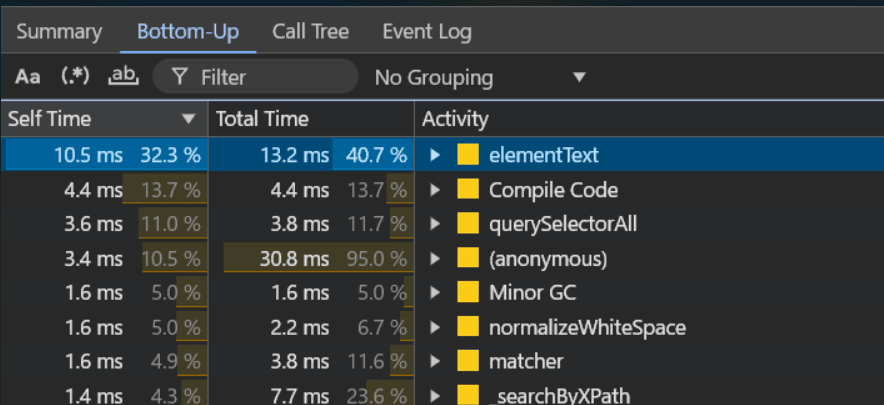
これが 22ms(>16ms) でブラウザのフレーム更新を阻害している。これはMutationObserver単位で発火する可能性があり、そうなるとユーザーとしては辛い状況になるだろう。
可能な限りJITが効かない初回のベンチマークを見ている。
lodash.isElement の問題
まず簡単に倒せそうなものから。
isElementがやけに多く実行サマリに計上されている。
直感的には el instanceof Element しているだけでは?と思ったら、要素判定で lodash.iselement を呼んでいる個所があった。これは探索したものをHTMLElement(Textでないぐらいの意味)でfilterして絞り込むのに使われていた。
import { isElement } from "lodash.iselement"
[...document.querySelectorAll('*')].filter(isElement)
これがなぜ重くなるのか。 lodash の実装をみる。
// https://github.com/lodash/lodash/blob/4.17.15/lodash.js#L11442
function isElement(value) {
return isObjectLike(value) && value.nodeType === 1 && !isPlainObject(value);
}
isPlainObject! これは確か、オブジェクトの中身を全探索してしまう
// https://github.com/lodash/lodash/blob/4.17.15/lodash.js#L11442
function isPlainObject(value) {
if (!isObjectLike(value) || baseGetTag(value) != objectTag) {
return false;
}
var proto = getPrototype(value);
if (proto === null) {
return true;
}
var Ctor = hasOwnProperty.call(proto, 'constructor') && proto.constructor;
return typeof Ctor == 'function' && Ctor instanceof Ctor &&
funcToString.call(Ctor) == objectCtorString;
}
というわけで、理由も納得いったので修正する。
ややファジーだが、これに差し替えることでゼロになった。
function isElement(el: any): any is HTMLElement {
// これだと shadowRoot や iframe 下で false になってしまう
// return el instanceof HTMLElement
return el?.nodeType === Node.ELEMENT_NODE
}
結論というかやっぱりというかの気持ちなのだが、lodash はIE時代の名残りで、ビルトインオブジェクトを信頼しない傾向が強い。自前で低水準のものを多く実装しているので、現代だと余分なオーバーヘッドとして現れることがある。
高速なテキスト検索を考える
今回の依頼の本題の、テキスト検索をインデックスして検索している部分。
これをみる途中で気付いたのだが、 Self Time と Total Time がブレているのは、おそらくDOMのネイティブアクセスの部分が計上されていない。JSのVMとしては10msだが、APIのユーザー的には13ms。
そもそもなぜ重いかと言えば、Playwright拡張がページ内のテキストを全探索するからで、それは拡張内でlocatorをつくるための一時オブジェクトで済まされていたものが、そのまま使われているからだった。
全テキストのスキャン、どうするべきか…
この解決のために色々としらべていたところ、document.createTreeWalker についての興味深いベンチマークを発見した。
Traverse function 1006591.0 Ops/sec
NodeIterator with filter function 105642.7 Ops/sec
NodeIterator with filter param 1689043.0 Ops/sec
TreeWalker with filter function 241954.5 Ops/sec
TreeWalker with filter param 1488959.0 Ops/sec
つまり、DOM API でトラバースするより、この createTreeWalker という DOM APIの方が 10倍以上早い。(存在を知らなかった)
// 遅い実装。DOM APIアクセスが多い。Playwrightの実装はこれベース
function traverse(root: Element, cb: (element: Node) => void) {
for (let child = root.firstChild; child; child = child.nextSibling) {
if (child.nodeType === Node.ELEMENT_NODE) {
traverse(child as Element, cb)
}
}
}
// 速い
function walk(root: Element, cb: (element: Node) => void) {
const treeWalker = document.createTreeWalker(root,NodeFilter.SHOW_ELEMENT);
while (treeWalker.nextNode()) {
cb(treeWalker.currentNode as Node)
}
}
これをベースに改善することにする。
ドメイン特化したテキスト探索の実装
テキストをスキャンすること自体はおそらく避けられないので、MutationObserver単位で createTreeWalker で最低一回はフルスキャンすることは許容することとする。
その上で、今回はDOM内のテキストを全部インデックスする必要がない。事前に検索クエリが判明しているので、これに該当するものだけスキャン時に集める。
createTreeWalkerはさらにテキストノードだけに絞って探索することが出来るので、これで検索ワードに完全一致するテキスト要素を集めればいい。
というわけで、簡単なテキスト検索の実装をしてみた。
function normalize(t) {
return t.replace(/\s+/g, ' ').trim();
}
function search(root, searchQuery) {
const treeWalker = document.createTreeWalker(root, NodeFilter.SHOW_TEXT);
const candidates = new Set();
let text;
while (text = treeWalker.nextNode()) {
const normalized = normalize(text.nodeValue);
if (normalized === searchQuery) {
candidates.add(text);
}
}
return candidates;
}
// https://ja.wikipedia.org/wiki/%E7%9B%B8%E4%BA%92%E7%A2%BA%E8%A8%BC%E7%A0%B4%E5%A3%8A
// 1195ノード
console.time('search')
console.log(search(document.body, '相互確証破壊'));
// Set(3) {text, text, text}
console.timeEnd('search')
// search: 0.60400390625 ms
playwright の elementText でインデックスに 12ms, 実際の検索に 6ms 掛かっていたのが、0.6ms になった。
これは一番簡単な実装で、実際には実装したのは要素を跨いだ検索に対応したり、候補となりうるテキスト断片をキャッシュして二度目以降を更に速くしたりというものなのだが、基本的にはこの応用なので割愛する。それらを入れても、最終的にはインデックス処理に 2ms, 探索 0.1ms ぐらいになった。
まとめ
DevTools Performance の Bottom-Up でSelf Time ~ TotalTime を見てJSタスクの専有時間を計測しよう!

とくにロングタスク(赤い帯がついてる部分の)のサマリから絞り込んでいくといい。
結果として今回わかったこと
- 木構造のトラバースは遅い
- 要素全スキャンに document.createTreeWalker が速い
- ライブラリ実装は過度に汎用化されて遅いことがあり、適切な制約を持ち込めばだいたいのものは高速化する
あとペアプロやコードレビューしていて感じたのが、仮想DOMが普及した現代では、自分が当然だと思っていた木構造のフルスキャンのコスト感や、アニメーションフレームの同期フレームを間引く感覚が現代のフロントエンドエンジニアから失われていそうだった。
Discussion