GraphQL BatchでクライアントN+1を無理矢理倒す (事例紹介:株式会社ハウテレビジョン様)
株式会社ハウテレビジョン様で、 質問箱サービスMondのパフォーマンス分析と改善を行いました。
内容としてはLCPの内訳の計測、その解決方法の提案、そして一番大きな問題だった GraphQL リクエストの最適化という話になります。
現時点で全ての問題の修正には至っていませんが、開発的には全ての問題の内訳が認識可能になっていて、検証が終われば段階的にリリースできる、という状態です。
以下、敬称略
相談内容
mond.how のLighthouseスコアを改善してほしい
主要な技術構成
- Next.js - Page Router
- Hasura CE - GraphQL Server Hasura のセルフホスティング版
計測と問題
最近は Chrome が出してくれる Lighthouse スコアの推移が見れるダッシュボードがある。
ここで Mond の直近のスコアをみる。
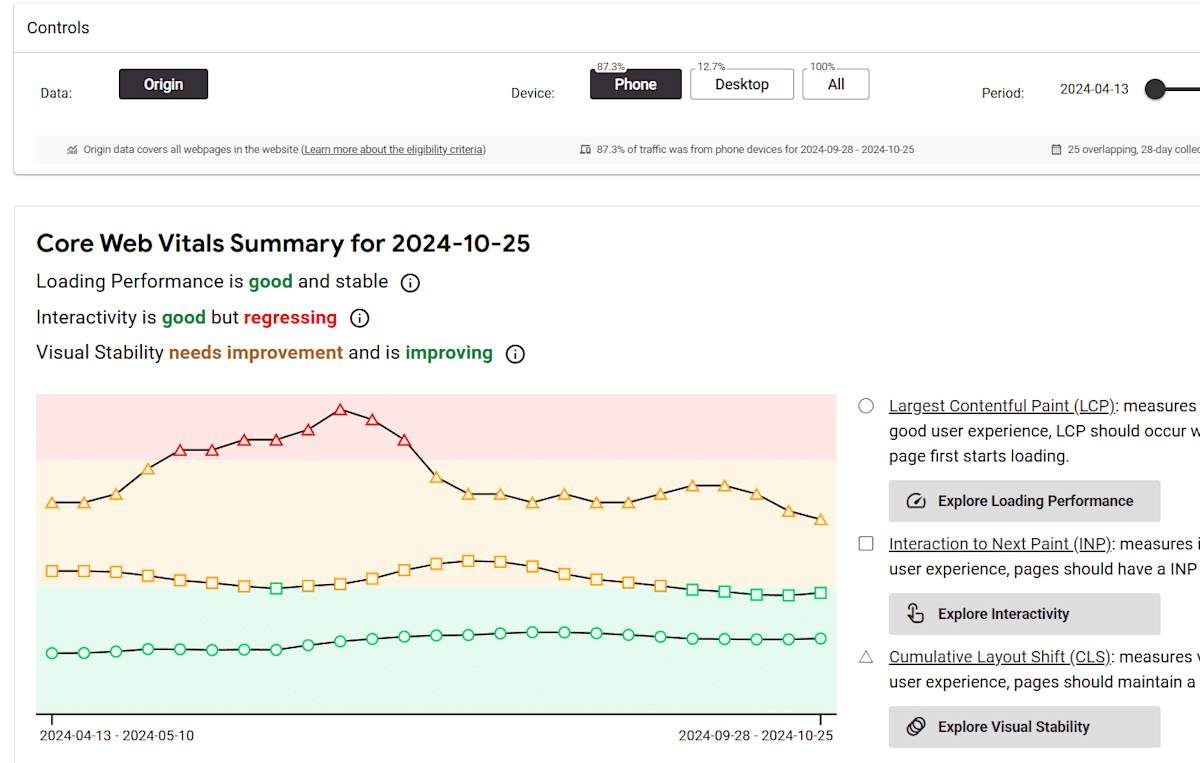
代表例として https://mond.how/kumagi を見ていた。回答数が多い。
cruxvis ではこのようなグラフだったが、どうも今回はサーバー負荷が主要因なようで、計測する時間帯でスコアが大幅に変動した。
手元で計測する限り、昼に60点、夜に30点程度のスコアを出している。夜のほうが高負荷なのかレスポンスが遅め。
ここから DevTools で内訳をみていく。
TBT、つまり JS 評価によるブロッキングタイムが長い。単にビルドサイズが大きい問題がある。ここは時間問わずフロントエンド的に発生する問題。
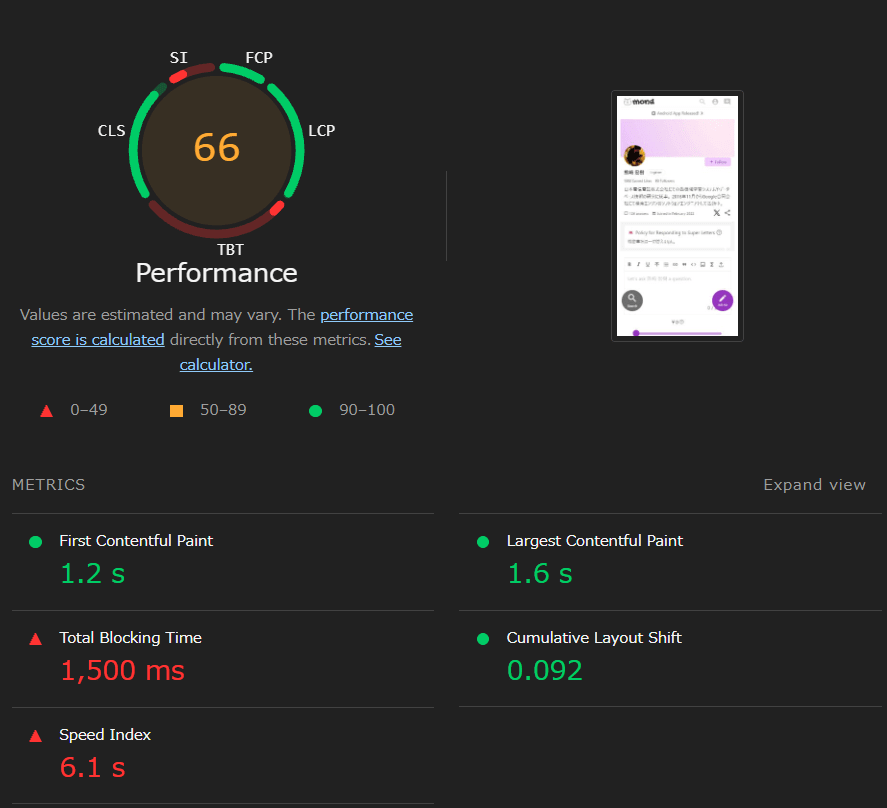
そして GraphQL Request が多すぎる。
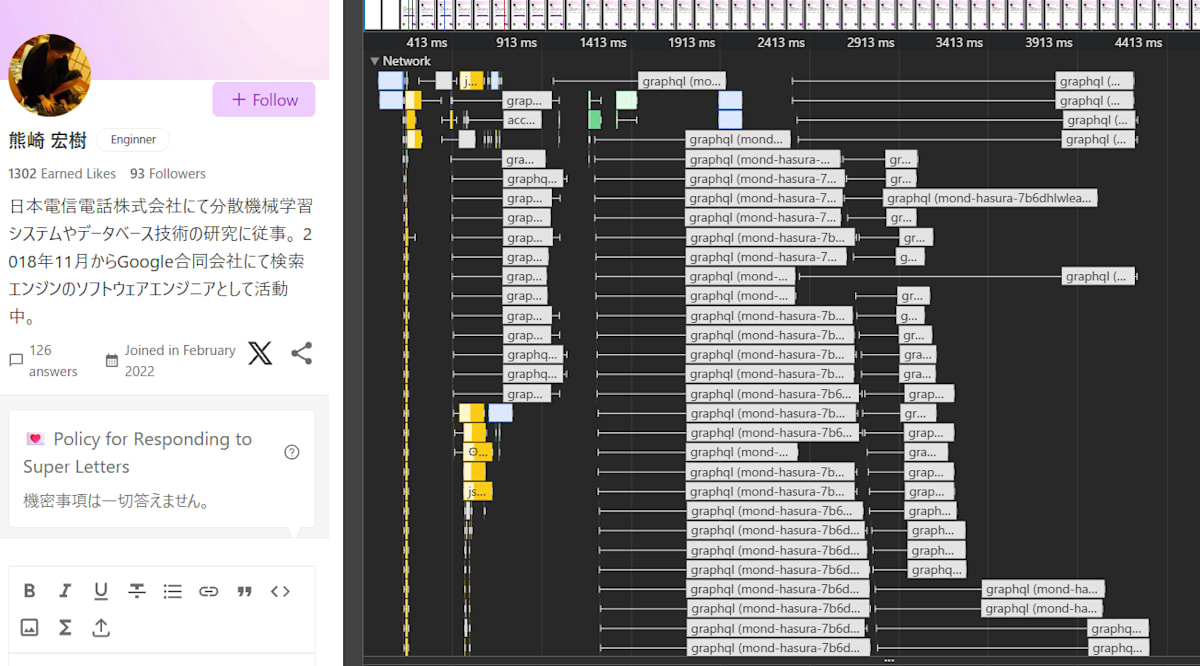
とにかく多すぎる。リクエストキューが捌けるまでだいぶ待たされていて、実質的なウォーターフォールになっている。
モックで理想状態を作ってみる
ソースコードから手元でビルドして本番につなぎつつ、重いデータを洗い出した。
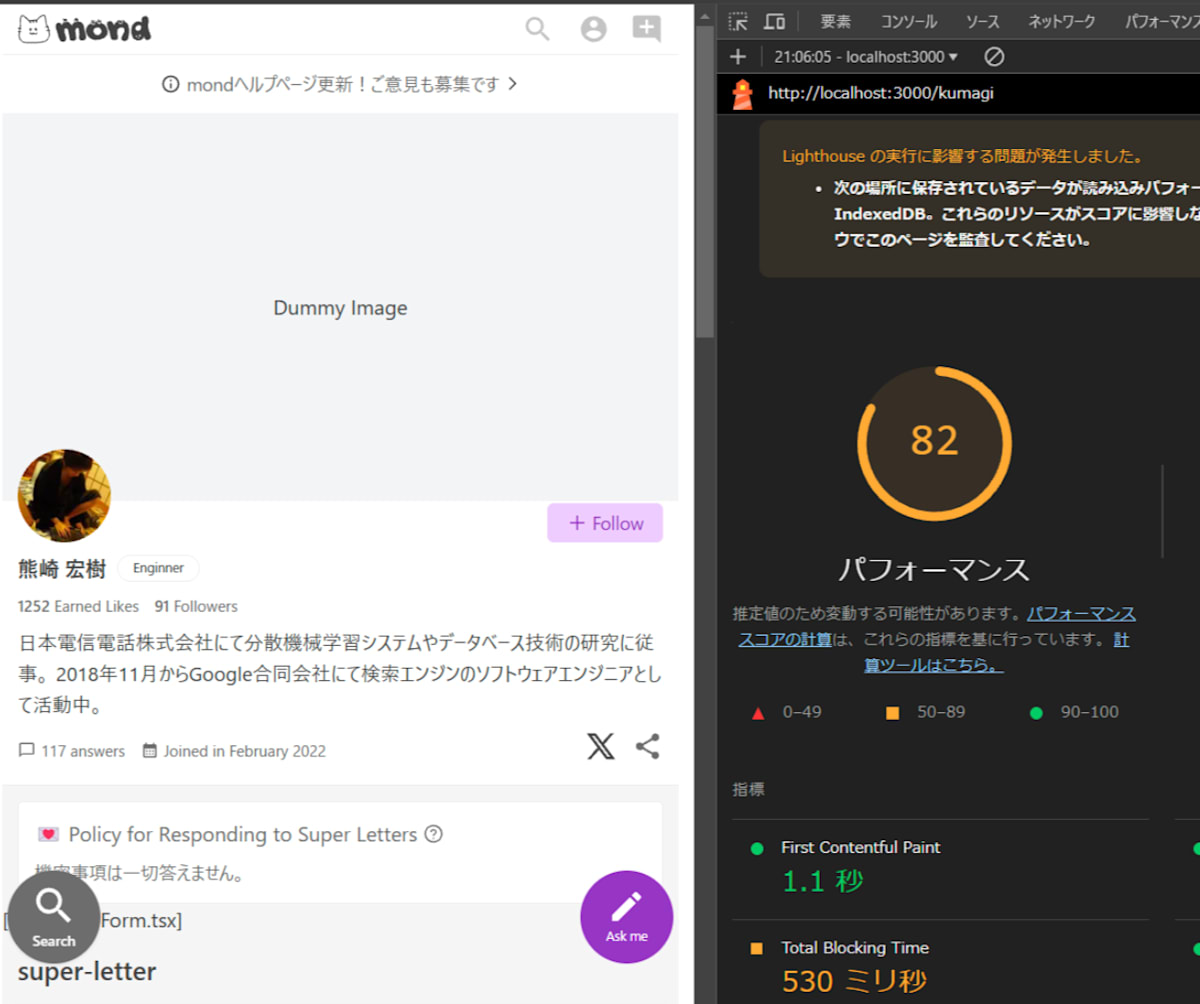
- ユーザーごとのカバーイメージをモック
- コメントフォームを無効化
- LCP以外のコメントの読み込みを止める
この状態でTBT以外ほぼ満点で、82点。
この状態でまだ悪いのは、JSのバンドルサイズと評価時間。なので先にバンドルサイズをみる。
バンドルサイズの分析
とりあえず @next/bundle-analyzer で分析に掛ける。
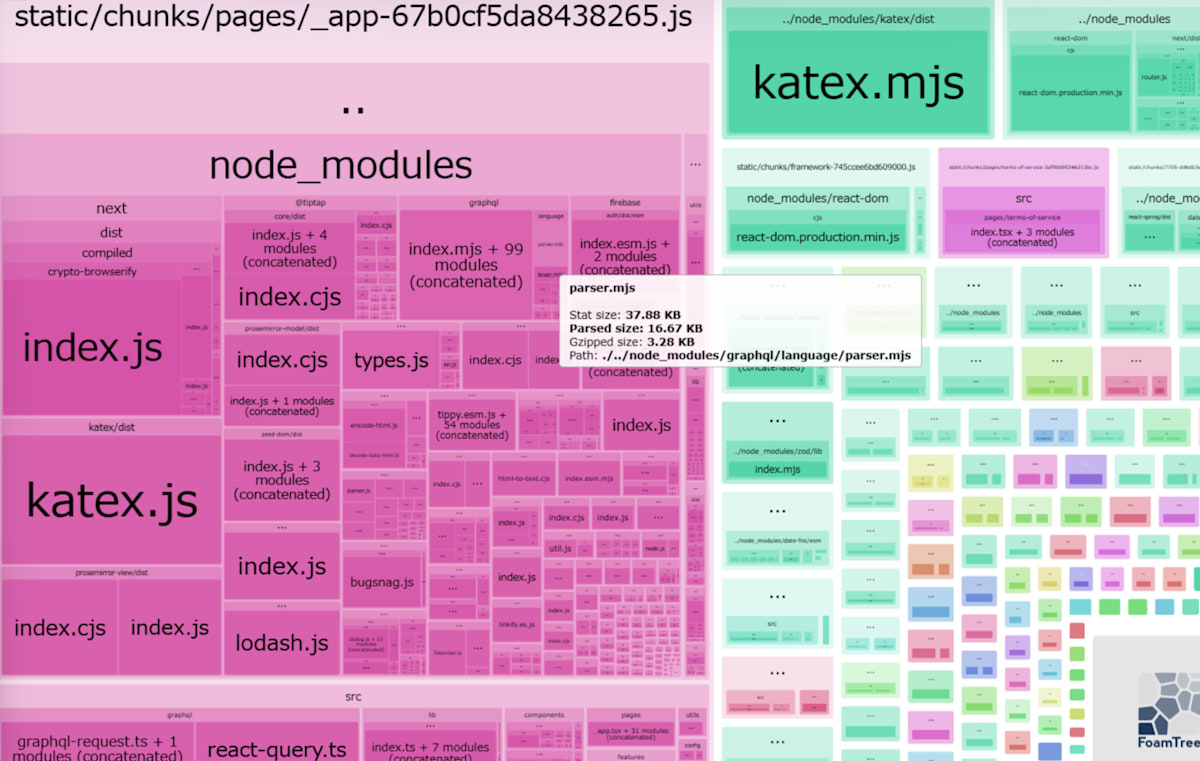
Next Page Router なので、 _app が主要なエントリポイントになる。
まず katex(数式レンダラ)が重複してるのがわかるとして、問題は tiptap と prosemirror のエディタに関するビルドサイズの割合が高い。
UI 的にはこの質問エディタに相当。
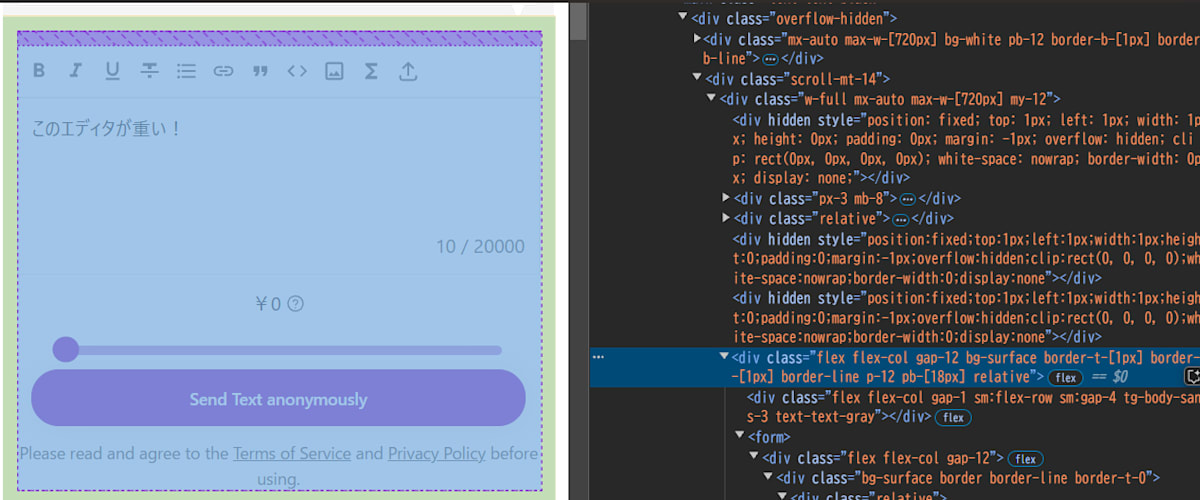
この周辺には問題が2つある。
- このUIだと常にエディタをロードすることが必須になる
- エディタを読み込まない画面でも、エディタのアセットが常に読み込まれている
前者は仕様的な決めが必要で、何らかの形で読み込みを遅延する形が必要ではあることを伝えた。例えば「質問するボタンを押したら初めてエディタが表示される」「エディタのモックを表示しておいて、ホバーやクリックでロードするスケルトンで代替」等を提案。
後者に関しては純粋に技術的な問題で、エディタを Dynamic Import 等で Lazy に隔離することで問題が発生しづらくなるのを確認した。
ただ、いろんな編集以外でも部分の表示にコンパイルしたデータではなく、tiptap を通す前の生データを引き回して、その表示に tiptap を使ってしまっていた。ここも修正しないと tiptap の巨大バンドルは解決しない。
フロントエンド的な修正は確認作業が多すぎるのでIssueに起こしてMondの開発側で解决する問題として、自分は主に GraphQL の問題に取り組むことにした。
GraphQL Request が多すぎる問題
リクエスト数が多すぎる。こっちが本題。
Mondの実装では GraphQL Codegen で react-query のコードを生成して、これをクライアントコードから使っている。
const query = useUserDetailsQuery(...)
const key = useUserDetailsQuery.getKey({ id: theUsersId })
ユーザーの質問への回答は無限スクロールのリストビューになっており、それらの各リストアイテムが自身の詳細解決に5~10件ほど追加でリクエストを発行している。なるほど、これは重い。
リスト取得とアイテム詳細がN+1になっているのだが、これは無限スクロールなので設計的にバッチ化するのがちょっと難しいのはわかる。
詳細の取得を最適化する余地はあるとはいえ、とにかくまばらにリクエストが飛び、かつリクエスト件数が多すぎるのでリクエストキューの待機数が多い。
GraphQL Client Batch の試験導入
設計的にクライアントでまばらにデータを解決してるのが問題で、あらゆる場所でデータ解決粒度を上げる必要があるのだが、そんなの中の人達は外野に言われなくてもわかっている。が、定量化はしていなかった、やっぱ重いね、みたいな肌感を共有した。
ところで、そもそも GraphQL はそもそもクライアントN+1を解決するための技術のはずであり、クライアントのリクエストを合成できるはずである。
Mond は graphql-client を使っているので、これに GraphQL のリクエストバッチがあるか調べたところ、あった。
これは次のようにGraphQLクエリをまとめて投げることができる。
await batchRequests('https://foo.bar/graphql', [
{
query: `
{
query {
users
}
}`
},
{
query: `
{
query {
users
}
}`
}])
ただ、これを使うにはGraphQLのエンドポイント側が対応してないといけない。
(GraphQL自体の動作検証で GitHub GraphQL Endpoint を叩いたら未対応だった)
Hasura が対応してるかどうかを調べたところ、該当するIssueがあり、対応済みとのこと。
これを手元で試したい。 graphql-request の最新版は graffle と名前を変えて再設計とリブランディングしようとしており、ここで batch request の対応が(現状)落ちていた。
なので Mond が作っていた 少し古い graphql-request をベースに、バッチ化クライアントを手作業でつくることにした。
次の実装は graphql-codegen が生成するコードに手を入れ、 500ms 以内に発生したリクエストを、全部同じリクエストに詰め直して送る実装。
// src/graphql/react-query.ts
// オリジナル実装
function fetcher<TData, TVariables extends { [key: string]: any }>(
client: GraphQLClient, query: string, variables?: TVariables, requestHeaders?: RequestInit['headers']
): () => Promise<TData> {
return async (): Promise<TData> => client.request({
document: query,
variables,
requestHeaders
});
}
// バッチ化実装
function fetcher<TData, TVariables extends { [key: string]: any }>(
client: GraphQLClient, query: string, variables?: TVariables, requestHeaders?: RequestInit['headers']
): () => Promise<TData> {
return batchedFetcher(client, query, variables, requestHeaders);
};
let _queue: Array<{
query: string;
variables?: any;
requestHeaders?: RequestInit['headers'];
resolve: (value: any) => void;
reject: (reason?: any) => void;
}> = [];
let _isFetching = false;
let _timeoutId: NodeJS.Timeout | null = null;
const DEBOUNCE_TIME = 500; // ms
function batchedFetcher<TData, TVariables extends { [key: string]: any }>(
client: GraphQLClient,
query: string,
variables?: TVariables,
requestHeaders?: RequestInit['headers'],
) {
return (): Promise<TData> => {
return new Promise((resolve, reject) => {
_queue.push({ query, variables, requestHeaders, resolve, reject });
if (_timeoutId) clearTimeout(_timeoutId);
_timeoutId = setTimeout(() => {
if (!_isFetching) _processBatch(client);
}, DEBOUNCE_TIME);
});
};
}
async function _processBatch(client: GraphQLClient) {
const batch = _queue.slice();
_queue = [];
const batchSize = batch.length;
return client
.batchRequests({
documents: batch.map(({ query, variables }) => ({
document: query,
variables,
})),
requestHeaders: batch[batch.length - 1].requestHeaders
})
.then((res) => {
batch.forEach(({ resolve }, index) => {
resolve(res[index].data);
});
})
.catch((error_) => {
const response = error_.response;
if (response) {
for (let i = 0; i < batchSize; i++) {
const res = response[i];
if (res.data) {
batch[i].resolve(res.data);
} else {
batch[i].reject(res);
}
}
}
})
.finally(() => {
_isFetching = false;
if (_queue.length > 0) {
batch.length = 0;
_processBatch(client);
}
});
}
(これは検証用のコードで、本当は許可リストを作って一部のクエリだけ分岐したり色々している)
バッチ化クライアントを試しに mond で動かしてみると、質的な速度改善が確認できた。具体的に150 Request 発生していた個所が 18 Request になったりした。ただ、その分一つのリクエスト自体は重い。全部合成されているので当然ではあるが。
バッチ化はアプリケーション特性の負荷特性、パフォーマンス特性が変わってしまうような過激な変更で、真面目に動作検証しつつ導入する必要があった。例えば最後のリクエストの認証情報を引っこ抜いて使うので、リクエスト間でセッション情報を動的に書き換えている場所があったら、これでは対応できない。(多分ないと思うが…)
1ヶ月の仕事としてはこれを graphql-codegen としてクライアントコードを生成する PR を作ってそこで終わりになった。
傭兵仕事の結果
JSのTBT、リクエスト依存のLCP/CLS という重い場所の特定とLighthouse上の点数の内訳を洗い出し、それぞれの改善PoCまでは作ることができた。
が、動作確認の保証まではできないのでその先はお願いする、という形になった。スポットで入ってパフォーマンス改善するという立場だと、ドメインの深い部分までは立ち入るのが難しい。
ただ、逆にドメイン知識がないからこそ冷静にDevToolsのメトリクスと向き合えてる気はする。コードを読んでしまうと思い込みで重くない数字を見に行って失敗することがある。自分の中でも計測手法が整理できてきたので、この辺をいつか整理したい
まとめ
- 主要なワークロードに重量級アセットが入ってこないようにバンドルサイズを監視する
- クライアントN+1を起こさないように、設計段階でコロケーションを意識しておきたい
- GraphQL のバッチリクエストは止血的に導入したが、結果として質的な改善にもなりそう
Discussion