【AIセキュリティクラス】セキュリティ・キャンプ全国大会2022に参加しました
1. はじめに
2022年8月8日から5日間、セキュリティ・キャンプ全国大会2022に参加してきました。私が選択したのはDクラス(AIセキュリティクラス)で、文字通りAIに対する攻撃と防御の手法をハンズオン形式で学びました。ここでは、講義内容の整理とAIセキュリティの情報発信を兼ねて、学んだことをまとめていきたいと思います。
2. 選考課題
選考課題は技術的な問題が1問、フェイクニュースとAIに関する意見を記述する問題が3問ありました。セキュキャンホームページで公開されている情報によると、Dクラスでは以下の点を評価するとのことだったので、技術的な問題に一番時間をかけて進めました。
AIや機械学習の知識、理解力。モデル化の考え方に親しんでいるかどうか。未解決のサイバーセキュリティの課題に関心があるか。
解答する上で気を付けたことは、参考文献を明記することです。参考文献を書くことで、説得力が増しますし、自分が述べた意見がデタラメに考えたものではないという証明にもなります。
3. 講義一覧
講義一覧は以下の通りです。
| 講義番号 | 講師 | 講義タイトル |
|---|---|---|
| D1,D4,D5,D6 | 伊東 道明 高江洲 勲 |
実践 AIシステム Attack&Defense |
| D2 | 村山 太一 | 機械学習による検知など近年のフェイクニュースに対する取り組み |
| D3 | 小澤 健祐 | AI技術最前線 |
| D7 | 北條 孝佳 高江洲 勲 伊東 道明 園田 道夫 |
これからのAIにとってのセキュリティを考える |
以下、各講義の内容についてまとめていきます。
3-1. 講義「実践 AIシステム Attack&Defense」
この講義では、AIへの攻撃手法と防御手法をハンズオン形式で学びました。
以下にその内容をまとめます。
AIへの攻撃手法は、主に以下の5種類に大別されます。
- 学習データ汚染
- 事前学習モデル汚染
- 機能の悪用
- 敵対的サンプル
- モデル/データ抽出
この講義では「敵対的サンプル」のみを扱ったので、それ以外の手法の詳細は省きます。
3-1-1. 敵対的サンプルの仕組み
敵対的サンプル攻撃とは、入力データに微小なノイズ(摂動)を入れて、意図的に誤分類を引き起こす攻撃のことです。この時、ノイズを入れた入力のことを敵対的サンプルと言います。
簡単に説明すると、以下のような決定境界をもつAIに対して、決定境界を越えるようなノイズを生成させると、誤分類を引き起こすことができます。
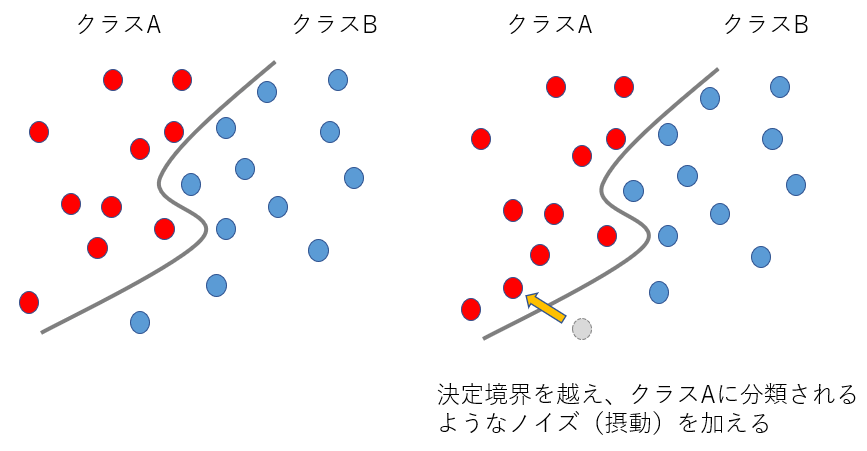
図1. 敵対的サンプル攻撃の簡単なイメージ
もう少し詳しく見ていきましょう。
通常、学習の際は、損失が小さくなるように重み
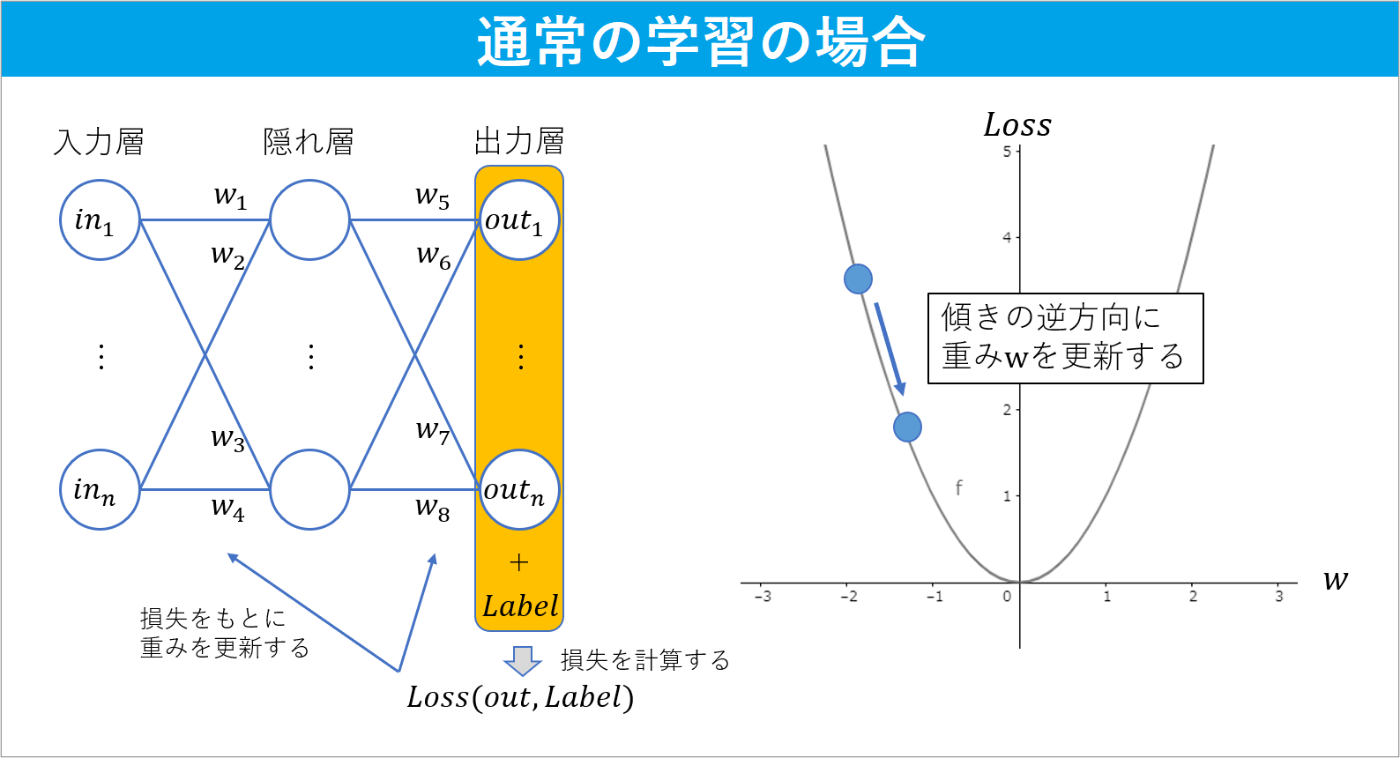
図2. 通常の学習の仕組み
敵対的サンプルの場合はどうでしょうか。
敵対的サンプルの場合は、重みは変化させず、損失が大きくなるように入力を変化させます(図3)。ここで注目すべき点は入力を変化させていることです。前述したように、通常の学習は損失をもとに重みを更新しますが、今回は誤分類を引き起こす入力を得ることが目的なので、損失をもとに入力を更新していきます。また、勾配降下法の一部を以下のように修正し、損失が大きくなるように変更します。
- 損失
Loss in - 勾配(傾き)と同じ方向に重みを更新する

図3. 敵対的サンプル生成の仕組み
また、この手法はFGSM(Fast Gradient Sign Method)と呼ばれています。
3-1-2. 敵対的サンプルの作成
それでは、実際に敵対的サンプルを作っていきましょう。
ソースコードは、以下のサイトを参考にしています。
手順1)ARTのインストール
まずはART(Adversarial Robustness Toolbox)をインストールします。ARTは、AIへの様々な攻撃や防御のツールを提供するPythonライブラリです。
$ pip3 install adversarial-robustness-toolbox
手順2)必要なライブラリのインポート
次に、必要なライブラリをインポートします。
# tensorflow
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
# ART
import art
from art.attacks.evasion import FastGradientMethod
from art.estimators.classification import KerasClassifier
# other
import numpy as np
※tf.compat.v1.disable_eager_execution()は、tensorflow2系の挙動を無効化させる処理です。
手順3)標的モデルをロードする
次に、標的モデルをロードします。
# 標的モデルをロード
model = tf.keras.models.load_model('target_model.h5')
手順4)標的モデルをKerasClassifierでラップする
ARTで敵対的サンプルを作成するためには、標的モデルをARTのラッパークラスでラップしなければなりません。ラッパークラスはTensorflow、Keras、Scikit-learn、PyTorchなど、それぞれのライブラリに対応したクラスが用意されています。
今回はKerasを用いたので、art.estimators.classification.KerasClassifier()でラップします。
# 標的モデルをラップする
classifier = KerasClassifier(model=model, clip_values=(0.0, 1.0), use_logits=False)
各引数の詳細は以下のようになっています。
| 引数名 | 詳細 |
|---|---|
| model | 標的モデルを設定する |
| clip_values | 特徴量がとりうる最大値と最小値を設定する |
| use_logits | モデルの出力がLogitsの場合はTrue、確率またはその他の場合はFalseを設定する |
modelはロードしたモデルを設定し、clip_valuesは画素値を255で割って正規化しているため、0.0~1.0の範囲を割り当てています。use_logitsは標的モデルの出力が確率なので、Falseを設定します。
手順5)FGSMインスタンスを作成し、敵対的サンプルを生成する
FastGradientMethod()を用いてFGSMインスタンスを作成します。
# FGSMインスタンスを作成する
attack = FastGradientMethod(estimator=classifier, eps=0.05)
クラス名が FastGradientMethod(FGM) となっていますが、これはFGSMをより一般的に利用できるように改良したためです。
引数の詳細は以下の通りです。
| 引数名 | 詳細 |
|---|---|
| estimator | ラップされたモデルを設定する |
| eps | ノイズの度合いを設定する |
epsの値が大きいほどノイズが増えて誤分類される確率も増えますが、ノイズが多すぎると攻撃を隠すことができなくなるため、低い値を設定しています。
続いて、FGSMインスタンス内のメソッドとして定義されているgenerate()を使って敵対的サンプルを生成していきます。
# 敵対的サンプルを生成する
X_test_adv = attack.generate(x=X_test)
引数xには、ノイズを加える前の元画像を設定します。今回は、標的モデルを構築するときに用意したテスト画像を使用します。
以下は、元画像と実際に生成された敵対的サンプルの一部です。
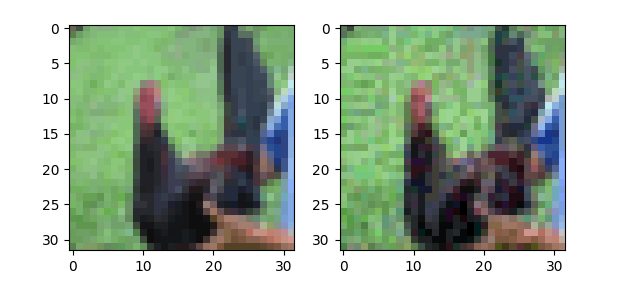
図5. 元画像と敵対的サンプルの比較(左:元画像、右:敵対的サンプル)
敵対的サンプルにノイズが混じっていることが分かります。少しノイズが目立ちますが、何も知らない人からすると画質の悪い鶏の画像くらいにしか思わないはずです。
手順6)誤分類の確認と精度検証
最後に、本当に誤分類されるのかと、精度の検証を行いたいと思います。
下図は、通常の画像と敵対的サンプルを入力として渡した時の予測結果です。
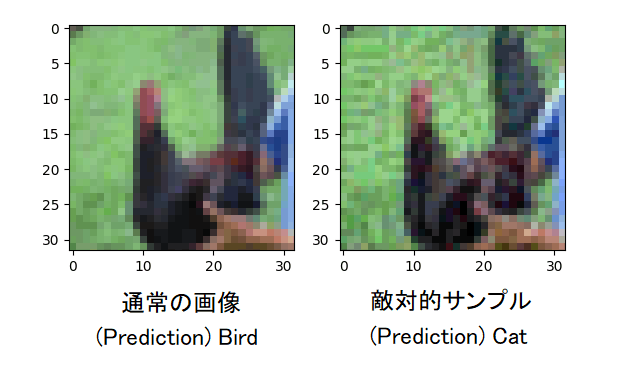
図6. 通常画像と敵対的サンプルの予測結果の比較
通常の画像は"Bird"と判別できているのに対して、敵対的サンプルは"Cat"と誤分類していることが分かります。
次に、予測精度を検証します。以下、検証時のコードと出力です。
# 通常の入力に対する予測精度
predictions = model.predict(X_test)
print("Normal accuracy => " + str((np.sum(np.argmax(predictions, axis=1) == np.argmax(y_test, axis=1)) / len(y_test)) * 100))
# 敵対的サンプルに対する予測精度
adv_predictions = model.predict(X_test_adv)
print("Adversarial accuracy => " + str((np.sum(np.argmax(all_preds, axis=1) == np.argmax(y_test, axis=1)) / len(y_test)) * 100))
Normal accuracy => 83.19%
Adversarial accuracy => 12.479999999999999%
かなり精度が落ちていることが分かります。
CIFAR10はクラスが10クラスあるので、約12%の精度は 「100(%) / 10(クラス) = 10(%/クラス)」 により、ほぼ当てずっぽうの予測をしていると言えます。
3-1-3. 敵対的サンプル攻撃を防ぐには
今までは攻撃手法を見てきましたが、ここからはそれに対する防御手法を簡単にまとめていきます。
敵対的サンプルの防御手法は主に6つです。
- データ拡張
- フィルタ処理
- 敵対的学習
- ネットワークの蒸留
- アンサンブルメソッド
- AI(Autoencoderなど)による検出
全部やるときりがないので、今回はその中でも実装が比較的簡単かつ防御率の高い「敵対的学習」を実装したいと思います。
敵対的学習とは、敵対的サンプルを学習データに入れることで、敵対的サンプルに対する耐性を高める防御手法のことです。
それでは、さっそく実装していきましょう。
ソースコードは、ARTのGitHub上に公開されているexamplesを参考にしています。
手順1)必要なライブラリをインポートする
まずは必要なライブラリをインポートします。
from __future__ import absolute_import, division, print_function, unicode_literals
# tensorflow
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPooling2D, Activation, Dropout
tf.compat.v1.disable_eager_execution()
# ART
from art.attacks.evasion import FastGradientMethod
from art.estimators.classification import KerasClassifier
from art.utils import load_dataset
# other
import numpy as np
1行目の__future__モジュールのインポートは、python3系の機能を2系で使えるようにするための処理です。
手順2)標準モデルの構築
何も防御対策を施していないモデルを構築します。
# CIFAR10のロード
(x_train, y_train), (x_test, y_test), min_, max_ = load_dataset(str("cifar10"))
x_train, y_train = x_train[:5000], y_train[:5000]
x_test, y_test = x_test[:500], y_test[:500]
im_shape = x_train[0].shape
# 通常モデルの設計とコンパイル
model = Sequential()
model.add(Conv2D(32, (3, 3), padding="same", input_shape=x_train.shape[1:]))
model.add(Activation("relu"))
model.add(Conv2D(32, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation("softmax"))
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
# 学習
model.fit(x_train, y_train, epochs=30, batch_size=128)
手順3)敵対的サンプルを生成
精度検証用と学習用の敵対的サンプルを生成します。
先ほど作成したモデルをKerasClassifierでラップし、FGSMインスタンスを作成して、敵対的サンプルを生成します。ここら辺は、前節の敵対的サンプル生成と同じ流れです。
# KerasClassifierでラップする
classifier = KerasClassifier(model=model, clip_values=(min_, max_))
# FGSMインスタンスを作成する
attack = FastGradientMethod(estimator=classifier, eps=0.05)
# 敵対的サンプルを生成する
x_train_adv = attack.generate(x_train)
x_test_adv = attack.generate(x_test)
手順4)標準モデルの推論精度を検証
標準モデルの推論精度を検証します。
# 標準モデルの推論精度を検証
predictions = np.argmax(classifier.predict(x_test), axis=1)
accuracy = (np.sum(predictions == np.argmax(y_test, axis=1)) / len(y_test)) * 100
print("(input) Normal, (model) Normal => " + str(accuracy) + "%")
predictions = np.argmax(classifier.predict(x_test_adv), axis=1)
accuracy = (np.sum(predictions == np.argmax(y_test, axis=1)) / len(y_test)) * 100
print("(input) Adversarial Example, (model) Normal => " + str(accuracy) + "%")
(input) Normal, (model) Normal => 59.199999999999996%
(input) Adversarial Example, (model) Normal => 19.400000000000002%
結果は、通常の入力時の精度が約59.2%、敵対的サンプル入力時の精度が約19.4%となりました。
通常の入力時の精度がかなり悪いですが、今回は検証用の簡易的なモデルとなるため、気にしないことにします。
手順5)学習データに敵対的サンプルを追加して再学習させる
敵対的学習をするために、通常の入力と敵対的サンプルを組み合わせた学習データを作ります。
# 学習データに敵対的サンプルを追加する
x_train = np.append(x_train, x_train_adv, axis=0)
y_train = np.append(y_train, y_train, axis=0)
その後、この学習データをもとに敵対的学習を始めます。
# 敵対的サンプルが組み込まれた学習データで再学習
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
robust_classifier = KerasClassifier(model=model, clip_values=(min_, max_))
robust_classifier.fit(x_train, y_train, nb_epochs=30, batch_size=128)
手順6)敵対的学習済みモデルの推論精度を検証
最後に敵対的学習済みモデルの精度を検証します。
# 敵対的学習済みモデルの推論制度を検証
predictions = np.argmax(robust_classifier.predict(x_test), axis=1)
accuracy = (np.sum(predictions == np.argmax(y_test, axis=1)) / len(y_test)) * 100
print("(input) Normal, (model) Adversarial Training => " + str(accuracy) + "%")
predictions = np.argmax(robust_classifier.predict(x_test_adv), axis=1)
accuracy = (np.sum(predictions == np.argmax(y_test, axis=1)) / len(y_test)) * 100
print("(input) Adversarial Example, (model) Adversarial Training => " + str(accuracy) + "%")
(input) Normal, (model) Adversarial Training => 50.8%
(input) Adversarial Example, (model) Adversarial Training => 46.0%
敵対的サンプルに対しても、ほとんど精度を落とさずに推論できていることが分かります。
ただ、普通の入力に対しての精度が少し落ちているため、精度を落としたくない環境では、敵対的学習は少し使いづらいかもしれません。
3-1-4. 競技形式で実践!(Attack & Defense)
この講義の最後に、受講メンバー同士で敵対的サンプルを送り合ったり、その攻撃に耐えられる頑健なAIを作成する競技形式のコンテスト?がありました。
ルールは簡単で、各受講者にAIが割り当てられ、互いのAIに対して攻撃や防御を繰り返し、得られたスコアを競い合います。スコアは攻撃用と防御用の2種類があり、攻撃用はどれだけ相手のAIを誤分類できたかで決まり、防御用は自分のAIがどれだけ正しく分類できたかで決まります。攻撃は30分に1回しかできないため、短時間で何度も攻撃をしてスコアを伸ばすことはできません。また、敵対的サンプルのeps(ノイズの量を決めるパラメータ)には上限が設けられているので、epsを異常に高くして誤分類を多く引き起こすこともできません。
競技初日は、とりあえずepsを少し低めにして攻撃を繰り返し、AIの頑健性をどうやったら高められるかを考えていました。敵対的学習により、ある程度誤分類を減らすことはできたのですが、他の人も同じことをしていると思ったので、別の手法も考えました。事前に講義で、複数の防御手法を組み合わせることで頑健性を上げられると聞いていたので、データ拡張とフィルタ処理と敵対的学習を組み合わせて実装しました。しかし、このモデルに差し替えたとたん防御スコアが落ちたので、もとのモデルに戻して一日目が終わりました。当日は時間が無くて、とりあえず動くことを目標に進めていたので、実装を間違えて頑健性ダウンにつながったのだと思います。
二日目は、防御はいったん置いて、敵対的サンプルの作成に注力しました。まずはepsの値がどこまで通るのかを調べて、ぎりぎりまでepsを高めて敵対的サンプルを作成しました(攻撃が30分に1回しかできないので、eps制限の境目を調べるのにかなり時間がかかりました、、)。また、バッチ正規化を削除することで、敵対的学習が促進されるという論文を共有してくれた方がおり、論文を読みながら試行錯誤を繰り返していました。
( 論文:https://proceedings.mlr.press/v162/wang22ap/wang22ap.pdf )
なんやかんやで二日目も終わり、無事コンテストが終了しました。一日目は防御がうまくいかずスコアが伸び悩んでいましたが、二日目は攻撃と防御を工夫したことにより、スコア順位を4位まで上げることができました!それでも、トップ3との差が広かったのには驚きです。

図7. 最終日のスコアグラフ(自分は黄緑色のグラフです)
以上、講義「実践 AIシステム Attack&Defense」のまとめでした。
3-2. 講義「近年のフェイクニュースに対する取り組み」
講義「機械学習による検知など近年のフェイクニュースに対する取り組み」は、近年流行しているフェイクニュースの検知に関する講義でした。フェイクニュース検知の仕組み、限界、進展について、この分野の最前線で活躍されている村山太一さんからお話を聞くことができました。下記リンクに公式の講義スライドが公開されているので、詳しく知りたい人は一読することをお勧めします。
以下、講義内容をまとめます。
3-2-1. 特徴量
フェイクニュース検知によく用いられる特徴量は、以下の6つです。
- テキスト特徴量
- ユーザ特徴量
- 情報伝播パターン
- 時間パターン
- 画像情報
- ネットワーク情報
「テキスト特徴量」は、文字通りテキストを特徴量にしますが、文字の並びや語の重要度など、様々なテキストの表現方法が存在します。頻繁に用いられている表現方法としては「Bag of words」や「N-grams」や「TF-IDF」などがあります。また、構文木を活用して文法を表現したり、単語の意味は周囲の単語によって形成されるという仮説に基づいて、語をベクトル表現で表す方法もあります。
「ユーザ特徴量」は、フェイクニュースを拡散するBotやユーザの特徴を表したものです。具体的にはフォロワー数、投稿数、プロフィール写真、確認済みのユーザかなどを特徴量としています。
「情報伝播パターン」は、通常のニュースとフェイクニュースの伝播パターンの違いを利用した特徴量です。図8のように伝播グラフを作成したとき、いくつかの点を中心に広がっている情報は通常の情報で、複数の小さな発信源で構成されている場合はフェイクの可能性があるということが分かっています。

図8. 情報伝播パターンの例(左:フェイクニュース、右:通常のニュース)[1]
「時間パターン」は、時間変化に応じてニュースへの関心が変わることを表した特徴量です。図9のように、通常のニュースは一度流行があった後は比較的緩やかに収まる傾向がありますが、フェイクニュースは何度も大きな流行を繰り返していることが分かります。
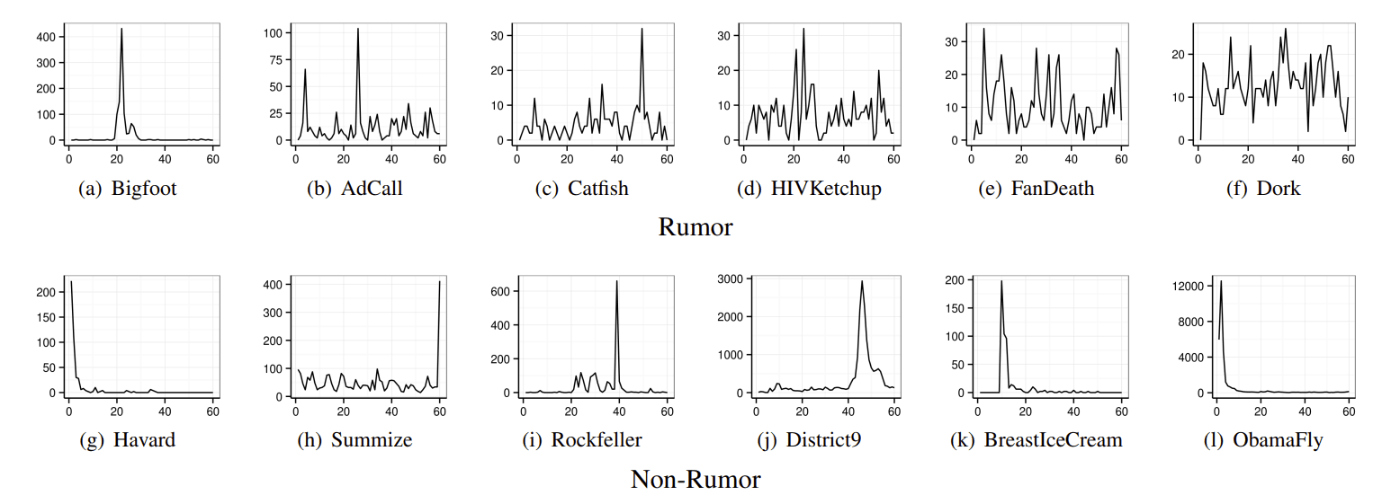
図9. 時間パターンの例(上:フェイクニュース、下:通常のニュース)[2]
「画像情報」は、画像の分布、画像ペアの平均類似度、画像類似度の分布ヒストグラム、画像クラスタ数を用いた特徴量です。
「ネットワーク情報」は、ユーザのフォロー関係や記事のもととなる情報の関係などをネットワークとして表現した特徴量です。
3-2-2. 検知モデル
フェイクニュース検知モデルに使われている主な深層学習モデルは、以下の4つです。
- RNN
- CNN
- GNN
- Transformer-based Neural Network
RNNには、時系列の流れ(以前の入力が今後の値に影響を与える)を考慮できるという特徴があります。単語を文脈に当てはめて学習できるため、テキストベースの検知モデルに用いられています。
CNNは、画像系の処理で有名ですが自然言語処理も行えるため、テキスト特徴量も扱うことができます。また、時間パターンを用いた検知にも適用可能です。
GNNは、グラフ構造を取り入れたニューラルネットワークで、何らかの関係性を加味した学習が可能になります。具体的には、ユーザ間の関係性の学習などに利用されています。
Transformer-based Neural Networkは、最近、自然言語処理や画像処理において主流となっているアーキテクチャで、入力を並列的に扱うことができるため、RNNやCNNの課題を補うことができます。
3-2-2. 日本語のデータセットが少ない
機械学習をするうえでデータセットは必要不可欠な存在ですが、フェイクニュース検知における日本語のデータセットはあまり存在しません。コンペ用のデータセットも一部ありますが、全て実際のフェイクニュースで構成されているわけではなく、GPT-1で生成されたテキストが含まれています。他には、FIJが検証したフェイクニュース307件を含んだデータセットとして"Japanese Fake News Dataset"があります。こちらは、zenodoで公開されています。
3-2-4. フェイクニュース検知の問題点
フェイクニュース検知も完全ではないため、いくつか問題点が指摘されています。
一つ目は、今のデータセットをもとに作った検知モデルが、将来のフェイクニュース検知に対応できるかです。例えば、米大統領選におけるフェイクニュースを検知するモデルがあったとします。モデルを作った年度の選挙はこのまま対応できますが、次回の選挙はモデルに学習させた人とは別の立候補者が出る可能性があります。もしそうなった場合、前立候補者のデータセットで学習したモデルでは対応できなくなることが考えられます。
二つ目は、フェイクニュースではない記事を誤ってフェイクニュースとして検知することです。検知手法に機械学習を用いている以上、このようなことは起こり得ます。誤ってフェイクニュースだと判定されると、著者が不利益を被るなど危険な状態へ発展しかねないため、この問題はフェイクニュース検知の実用化を進めるうえで、解決必須の課題だと言えるでしょう。
三つめは、フェイクニュースと判断するまでのプロセスがブラックボックス化されているという点です。なぜフェイクニュースと判定されたのか、明確な理由が無いと検知結果を信用することができません。しかし、検知モデルの構造上、判定結果に至るまでの処理が複雑過ぎて、理解することができないのです。
3-3. 講義「AI技術最前線 」
この講義では、AIの基本的な知識や設計上の注意点などのお話を聞くことができました。
最近、業務やサービスなどにAIを導入する事例が増えていますが、実際にはAIをうまく活用できていないことが多いようです。実際に起こりうる例として、AIを使うまでもない作業にAIを使ったり、AIを使う目的が曖昧なことなどが挙げられます。そこで、設計する際は以下の10点を考えて設計すると、全体像が明確になり失敗することが少ないようです。
- 誰が喜ぶか
- なぜ喜ぶか
- なぜAIを使うのか
- どんなAIか
- データの収集方法
- 分析に活用できるデータ
- 精度向上のために必要なデータ
- 導入にかかるコスト
- AIの効果の検証方法
- 既存AIとの違い
この講義内容の一部は以下にて公開されていました。
3-4. 講義「これからのAIにとってのセキュリティを考える」
この講義では、三つの議題をもとにグループ議論を行いました。
テーマ1:データセットとプライバシー
一つ目は、データセットにプライバシーに関わる情報を含むべきかという議論です。
様々な分野で活躍しているAIですが、そのデータセットには購買履歴や移動情報、個人情報などが含まれていることがあります。ここで、万が一情報の漏洩が起きると、ユーザのプライバシーが危険にさらされることが考えられます。
このテーマについて、私のグループでいろいろ議論し合った結果、データを暗号化すればプライバシーが危険にさらされることは無いという結論に至りました。暗号化すれば漏洩後の危険性が低いことと、暗号済みのデータを計算する手法を用いれば、途中のデータ処理においてもプライバシー情報を理解できないことがその結論の根拠です。
しかし、そもそも個人の記録(購買履歴など)を取得すること自体がプライバシー侵害に当たるのではないかという疑問がありますが、その点については議論できませんでした。
テーマ2:AIの品質保証
二つ目のテーマは、AIの品質をどのように保証するかについてです。
AIの品質とは、顧客の要求したパフォーマンスを発揮できているかや、顧客の期待通りのAIとなっているかを表す指標のことです。
AIの品質を保証できないと何が問題なのかというと、顧客と共通認識を持つことができないことです。AIはその性質上、従来の品質保証方法を適用することができません。そのため、顧客と共通認識を持つことができず、顧客のAIに対する過度な期待へとつながります。過度な期待は品質のハードルを高めるため、開発者の負担も増大します。
また、これはビジネスの話だけではなく、私たち一般人にも同じことが言えます。例えば、自動運転車の事故です。2016年に起きたテスラ車の事故は、部分自動運転モードを信じきった結果、システム側の識別不良にドライバーが対応できず起きたものです。このように、AIへの過度な期待(信頼)を与えないためにも品質保証は重要な課題となるわけです。
前置きが長くなりましたが、以上のテーマのもとグループで議論を行いました。しかし、残念ながら結論は出ませんでした。(AIの品質について理解するのと、議論の導入に時間をかけすぎてしまいました、、)
個人的には、自動運転のレベル分け(レベル1:運転支援、レベル5:完全自動運転)のように、第三者機関が厳密な点検項目を設けてAIをレベル分けすると良いと思いました。
テーマ3:AIの責任
三つ目のテーマは、AIに関する責任は誰が背負うべきかについてです。
時に、AIの判断がトラブルを引き起こすことがあります。例えば、先ほどのテスラの事故では、AIの自動運転機能が対応できなかったことも原因の一つでした。このように、AIが原因に関わっているとき、責任を負うのは誰でしょうか。
私たちのグループでは、場合によるという結論が出ました。
例えば、苦手な問題をレコメンドする学習支援AIがあったとします。ある日、とある生徒から成績が上がらないとクレームがあった場合、責任の所在は誰にあるのでしょうか。
もし、レコメンドの精度が悪いことが原因であれば、AIの開発者(またはAIを誇大広告していたのであれば営業)にその責任があります。しかし、逆に生徒が勉強しないでクレームを言っていたのであれば、生徒側に責任があります。
このように状況に応じて責任が変わるため、一概に誰に責任があるとは言えないです。(当たり前なことを言っている気がする、、)
4. 終わり
セキュリティキャンプ無事修了しました!長いようで短かった一週間でした。
講義が始まるまではついていけるか不安でしたが、講義内容やサポートがかなり充実していて、無事スムーズに進めることができました。本当に満足です。
また、個人的にセキュリティキャンプはがっつりセキュリティをやるイメージだったのですが(もちろんやりますが)、実際には電子工作をメインでやっている人や、全レイヤーを網羅するため「走るルーター」を作る人や、生物学とバイナリを組み合わせたバイ(オ)ナリアンがいたりと、セキュリティ問わずかなり自由で面白そうな講義が多かったです。みんな自分の好きな分野を楽しみながら極めている感じがして、本当に刺激的な空間でした。
他にも、セキュリティ会社に就職してセキュリティ知識ゼロからペンテスターになった人や、まったく別の業界からセキュリティ業界に入った人など、多様な職歴を持った方のお話も面白かったです。
セキュリティキャンプ終了後の今のレベルは、AIセキュリティの先っぽを少しかじった程度だと感じています。講義では、ある程度ソースコードが用意された環境だったので、次は自分でゼロから実装していきたいです。また、ARTのソースコードを読んで理解を深めたり、そのほかの攻撃手法も試していく予定です。暇なときにこのブログに投稿していくので、ぜひ見てみてください。
以上、セキュリティキャンプ全国大会2022参加記録でした!
5. おまけ。個人的に面白かった話。
-
説明可能なAI
Grad-CAMなどの説明モデルを、意図した出力へだます攻撃手法があるようです。出力のヒートマップが意図的に変更されていることが分かります。
https://www.kdnuggets.com/2021/02/adversarial-attacks-explainable-ai.html -
普通のアプリに偽装して標的型攻撃を行う攻撃手法:DeepLocker
普段は普通のアプリとして振る舞いながら、標的を見つけたらマルウェアを実行する攻撃手法です。標的かどうかを判断するのにDeep-Learningを用いています。
https://www.mbsd.jp/research/20190311/deeplocker/ -
論文の読み方
チャットで盛り上がっていた論文の読み方です。卒研するときに知りたかった、、
https://www.slideshare.net/Ochyai/1-ftma15
こちらも面白いです。
https://ainow.ai/2019/11/28/180522/
-
Diffusion network examples, Sejeong Kwon, "Prominent Features of Rumor Propagation in Online Social Media", 2013 IEEE 13th international conference on data mining. IEEE, 2013. ↩︎
-
Examples of extracted time series, Sejeong Kwon, "Prominent Features of Rumor Propagation in Online Social Media", 2013 IEEE 13th international conference on data mining. IEEE, 2013. ↩︎
Discussion