BigQueryで列の中央値/n%tile値を出す
BigQueryには、「列を指定するだけで」中央値を返してくれる集計関数 median(col) や、「列とパーセンテージを指定するだけで」n%tile値を返してくれる集計関数 percentile(col, percentage) はありません。
その代わり、n分位近似境界を返すAPPROX_QUANTILES()が実装されており、これを使えば、 インターフェースがぱっと見わかりにくい ですが近似中央値/n%tile値を一応得ることができます。
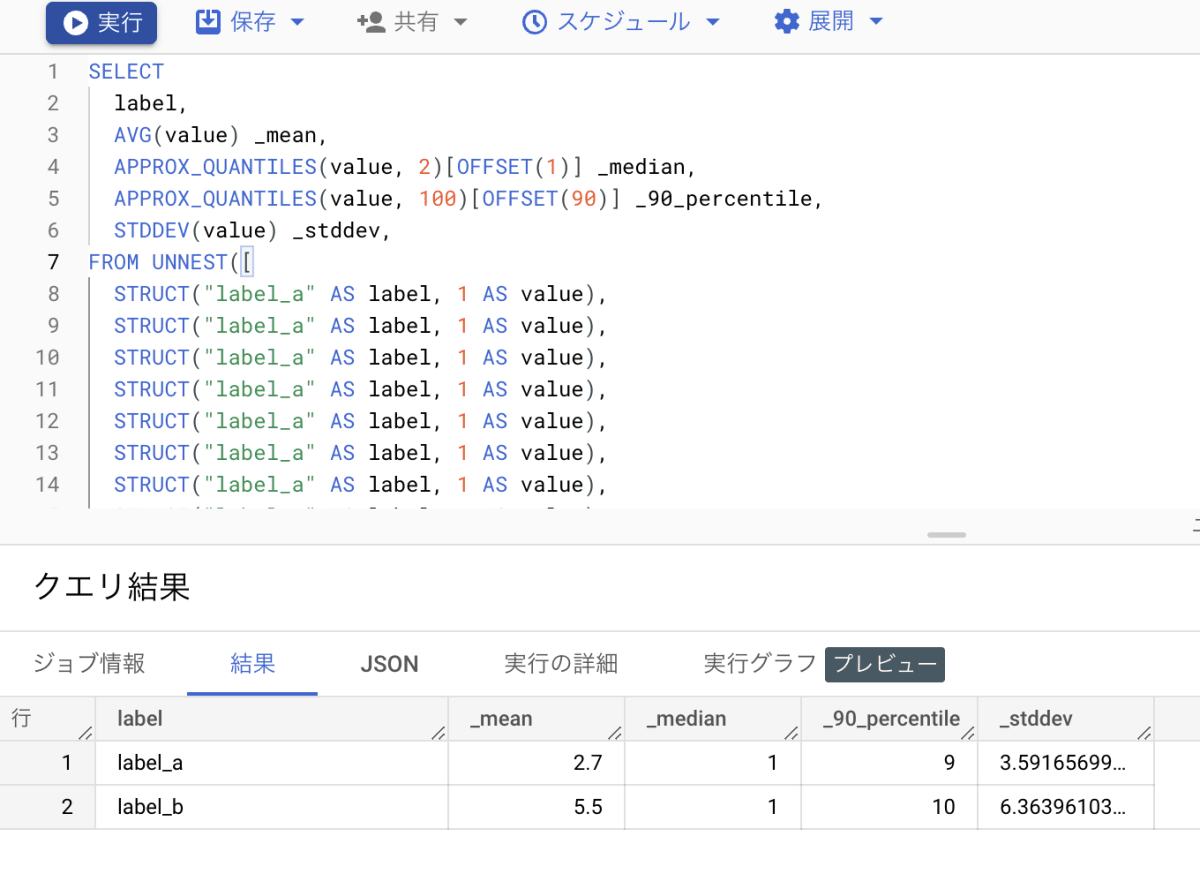
SELECT
label,
AVG(value) _mean,
APPROX_QUANTILES(value, 2)[OFFSET(1)] _median,
APPROX_QUANTILES(value, 100)[OFFSET(90)] _90_percentile,
STDDEV(value) _stddev,
FROM UNNEST([
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 9 AS value),
STRUCT("label_a" AS label, 10 AS value),
STRUCT("label_b" AS label, 1 AS value),
STRUCT("label_b" AS label, 10 AS value)
])
group by 1
-
APPROX_QUANTILES(col, n)は、 列colの要素を小さい順にn個のバケットに振り分け、[最小値, バケット1と2の境界値, バケット2と3の境界値, ..., バケットn-1とnの境界値, 最大値]のn+1の長さの配列を返します。 - 例:
APPROX_QUANTILES(x, 2)で [最小値, 中央値, 最大値] のようなARRAYが返ってくるので、[OFFSET(1)]をすることで中央値を得ることができる。 - 例:
APPROX_QUANTILES(x, 100)で [最小値, 1%tile, 2%tile,... 99%tile, 最大値] のようなARRAYが返ってくるので、[OFFSET(90)]をすることで90%tileを得ることができる。
APPROX_QUANTILES() は近似集計関数なので、正確さをそこまで求めないときはこれが使えそうです。
- 具体的には、要素の個数が偶数のときに中央値を求める場合、正しくは要素を正順に並べたときにちょうど中央に出現する 2つの要素の重み付け平均 を中央値とすべきですが(線形補間)、この関数では中央となる値の候補のうち より小さい数 がそのまま中央値になるようです。(多分)
- 例:
[1, 10]の中央値は、これらの算術平均 5.5 になるべきだが、APPROX_QUANTILES(value, 2)[OFFSET(1)]は小さい方の値 1 を返す。 - ドキュメントにはどのような近似計算がされるのか詳しく説明されていない
BigQueryのUDFを使って、列の中央値/n%tile値を正確に出す
正確な中央値
中央値/n%tileを正確に計算したい場合は、UDFで集計関数を作って使う方法があります。
中央値については https://github.com/GoogleCloudPlatform/bigquery-utils/tree/master/udfs/community#medianarr-any-type によって bqutil.fn.median() がすでに定義されており、これを真似すれば median() 集計関数が作成できます。
CREATE OR REPLACE FUNCTION [project_id].[database_name].median(arr ANY TYPE) AS ((
SELECT IF (
MOD(ARRAY_LENGTH(arr), 2) = 0,
(arr[OFFSET(DIV(ARRAY_LENGTH(arr), 2) - 1)] + arr[OFFSET(DIV(ARRAY_LENGTH(arr), 2))]) / 2,
arr[OFFSET(DIV(ARRAY_LENGTH(arr), 2))]
)
FROM (SELECT ARRAY_AGG(x ORDER BY x) AS arr FROM UNNEST(arr) AS x)
));
のように定義すると、
SELECT
label,
[project_id].[database_name].median(value)
FROM ~~
GROUP BY 1
のように median() 関数が使えるようになります。
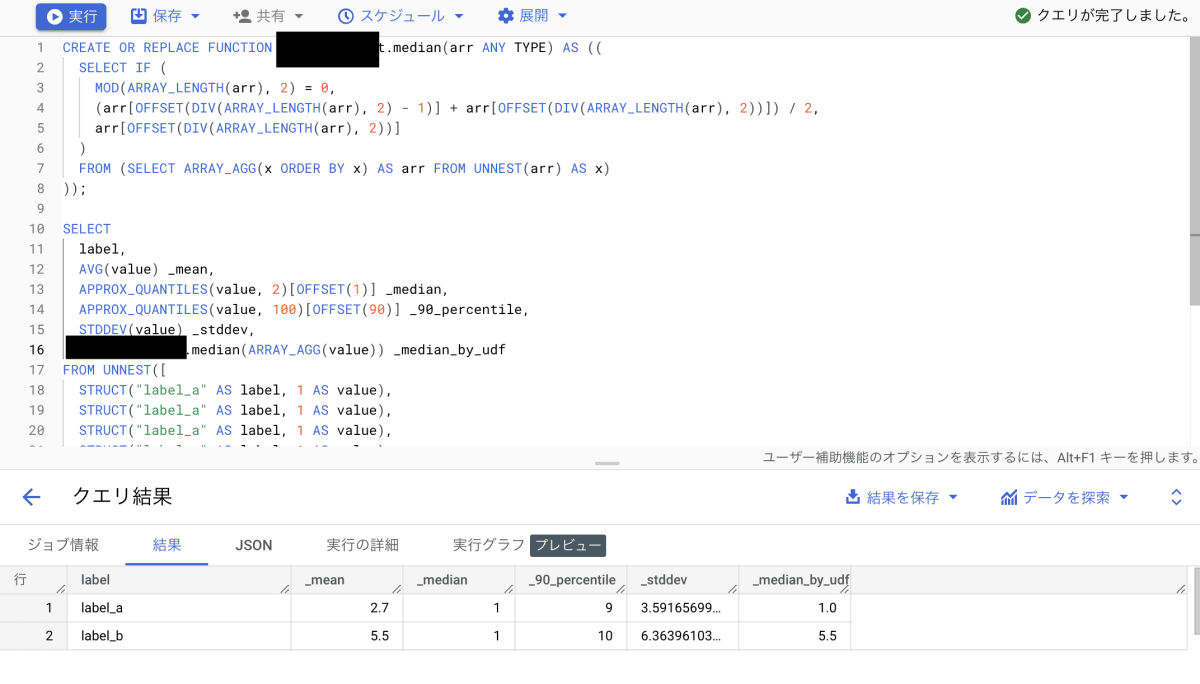
↑のクエリ
CREATE OR REPLACE FUNCTION [project_id].[database_name].median(arr ANY TYPE) AS ((
SELECT IF (
MOD(ARRAY_LENGTH(arr), 2) = 0,
(arr[OFFSET(DIV(ARRAY_LENGTH(arr), 2) - 1)] + arr[OFFSET(DIV(ARRAY_LENGTH(arr), 2))]) / 2,
arr[OFFSET(DIV(ARRAY_LENGTH(arr), 2))]
)
FROM (SELECT ARRAY_AGG(x ORDER BY x) AS arr FROM UNNEST(arr) AS x)
));
SELECT
label,
AVG(value) _mean,
APPROX_QUANTILES(value, 2)[OFFSET(1)] _median,
APPROX_QUANTILES(value, 100)[OFFSET(90)] _90_percentile,
STDDEV(value) _stddev,
[project_id].[database_name].median(ARRAY_AGG(value)) _median_by_udf
FROM UNNEST([
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 9 AS value),
STRUCT("label_a" AS label, 10 AS value),
STRUCT("label_b" AS label, 1 AS value),
STRUCT("label_b" AS label, 10 AS value)
])
group by 1
なお、bqutil.fn.median() を直接使って
SELECT
label,
bqutil.fn.median(ARRAY_AGG(value))
FROM ~
group by 1
と書けるのではと思う方もいるかもしれませんが、
BigQueryのUDFはリージョンごとに定義されており、 bqutil.fn.median() はUSに定義されているため、 asia-northeast1 にあるデータセットに対してクエリを投げる場合は自分で asia-northeast1 リージョンにUDFを定義して使う必要があります。
正確なn%tile値
中央値と同じように、UDFを使うことで正確なn%tile値も出せそうな気がしたので&ネットの海を探しても見つけられなかったので[1][2]、n%tileを計算するUDFを自分で書いてみます。
CREATE OR REPLACE FUNCTION [project_id].[dataset_name].percentile_agg(arr ANY TYPE, percentile NUMERIC) AS ((
WITH const AS (
SELECT
percentile*(ARRAY_LENGTH(arr) - 1) idx_numeric,
CAST(FLOOR(percentile*(ARRAY_LENGTH(arr) - 1)) AS INT64) idx_floored,
CAST(CEIL(percentile*(ARRAY_LENGTH(arr) - 1)) AS INT64) idx_ceiled,
)
SELECT IF (
MOD(idx_numeric, 1) = 0,
-- ちょうど percentile*ARRAY_LENGTH(arr) 番目の要素があるときはその値を返す
arr[OFFSET(idx_floored)],
-- ちょうど percentile*ARRAY_LENGTH(arr) 番目の要素がないときは、線形補間 ( https://ja.wikipedia.org/wiki/分位数 )でpercentile値を求める
ABS(idx_numeric - idx_ceiled) * arr[OFFSET(idx_floored)]
+ ABS(idx_numeric - idx_floored) * arr[OFFSET(idx_ceiled)]
)
FROM (SELECT ARRAY_AGG(x ORDER BY x) AS arr FROM UNNEST(arr) AS x)
CROSS JOIN const
));
呼び出す際は、正確な小数計算を行うため (丸め誤差が発生しないようにするため)
SELECT
label,
[project_id].[database_name].percentile_agg(ARRAY_AGG(value), NUMERIC '0.9') _90_percentile
FROM ~~
GROUP BY 1
のように NUMERICリテラルを使用してパーセンテージを指定する必要があります。
使ってみた様子:
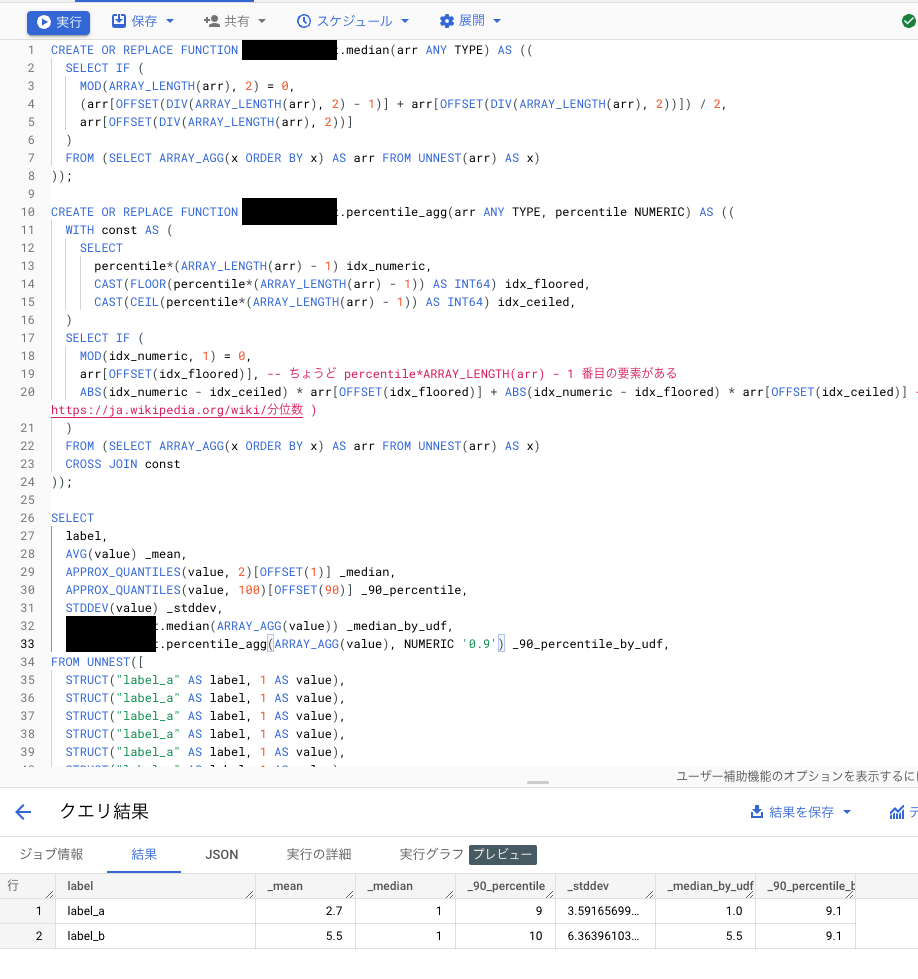
↑のクエリ
CREATE OR REPLACE FUNCTION [project_id].[database_name].median(arr ANY TYPE) AS ((
SELECT IF (
MOD(ARRAY_LENGTH(arr), 2) = 0,
(arr[OFFSET(DIV(ARRAY_LENGTH(arr), 2) - 1)] + arr[OFFSET(DIV(ARRAY_LENGTH(arr), 2))]) / 2,
arr[OFFSET(DIV(ARRAY_LENGTH(arr), 2))]
)
FROM (SELECT ARRAY_AGG(x ORDER BY x) AS arr FROM UNNEST(arr) AS x)
));
CREATE OR REPLACE FUNCTION [project_id].[database_name].percentile_agg(arr ANY TYPE, percentile NUMERIC) AS ((
WITH const AS (
SELECT
percentile*(ARRAY_LENGTH(arr) - 1) idx_numeric,
CAST(FLOOR(percentile*(ARRAY_LENGTH(arr) - 1)) AS INT64) idx_floored,
CAST(CEIL(percentile*(ARRAY_LENGTH(arr) - 1)) AS INT64) idx_ceiled,
)
SELECT IF (
MOD(idx_numeric, 1) = 0,
arr[OFFSET(idx_floored)], -- ちょうど percentile*ARRAY_LENGTH(arr) - 1 番目の要素がある
ABS(idx_numeric - idx_ceiled) * arr[OFFSET(idx_floored)] + ABS(idx_numeric - idx_floored) * arr[OFFSET(idx_ceiled)] -- 線形補間 ( https://ja.wikipedia.org/wiki/分位数 )
)
FROM (SELECT ARRAY_AGG(x ORDER BY x) AS arr FROM UNNEST(arr) AS x)
CROSS JOIN const
));
SELECT
label,
AVG(value) _mean,
APPROX_QUANTILES(value, 2)[OFFSET(1)] _median,
APPROX_QUANTILES(value, 100)[OFFSET(90)] _90_percentile,
STDDEV(value) _stddev,
[project_id].[database_name].median(ARRAY_AGG(value)) _median_by_udf,
[project_id].[database_name].percentile_agg(ARRAY_AGG(value), NU
MERIC '0.9') _90_percentile_by_udf,
FROM UNNEST([
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 9 AS value),
STRUCT("label_a" AS label, 10 AS value),
STRUCT("label_b" AS label, 1 AS value),
STRUCT("label_b" AS label, 10 AS value)
])
group by 1
これで、たしかに正確なn%tileを算出できました。
- ウィンドウ関数の
PERCENTILE_CONT()(後述)と違い、このpercentile_agg()はGROUP BYによるデータ集計時に1度だけ処理されるので、計算資源を節約できるはず。
付録: PERCENTILE_CONT() 関数について
BigQueryには、n%tile値を出せそうなPERCENTILE_CONT()という関数もあるのですが、これはウィンドウ関数で、集計関数として使うことが出来ません。
例えば、以下のように GROUP BY を使用したクエリで、グループ化していないカラムの集計に使うことはできません。
SELECT
label,
PERCENTILE_CONT(value, 0.5) OVER() AS median, -- ← error
PERCENTILE_CONT(value, 0.9) OVER() AS percentile90, -- ← error
FROM UNNEST([
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 9 AS value),
STRUCT("label_a" AS label, 10 AS value),
STRUCT("label_b" AS label, 1 AS value),
STRUCT("label_b" AS label, 10 AS value)
])
group by 1
PERCENTILE_CONT() で同じことをやりたい場合、
-
OVER(PARTITION BY label)でグループ内でのウィンドウ演算をする - DISTINCT をつける
で一応できますが、集計前のレコード数分だけ PERCENTILE_CONT() の演算が走ってしまうので、計算資源が無駄に使われてしまいます。
SELECT DISTINCT
label,
PERCENTILE_CONT(value, 0.5) OVER(PARTITION BY label) AS median,
PERCENTILE_CONT(value, 0.9) OVER(PARTITION BY label) AS percentile90,
FROM UNNEST([
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 1 AS value),
STRUCT("label_a" AS label, 9 AS value),
STRUCT("label_a" AS label, 10 AS value),
STRUCT("label_b" AS label, 1 AS value),
STRUCT("label_b" AS label, 10 AS value)
])
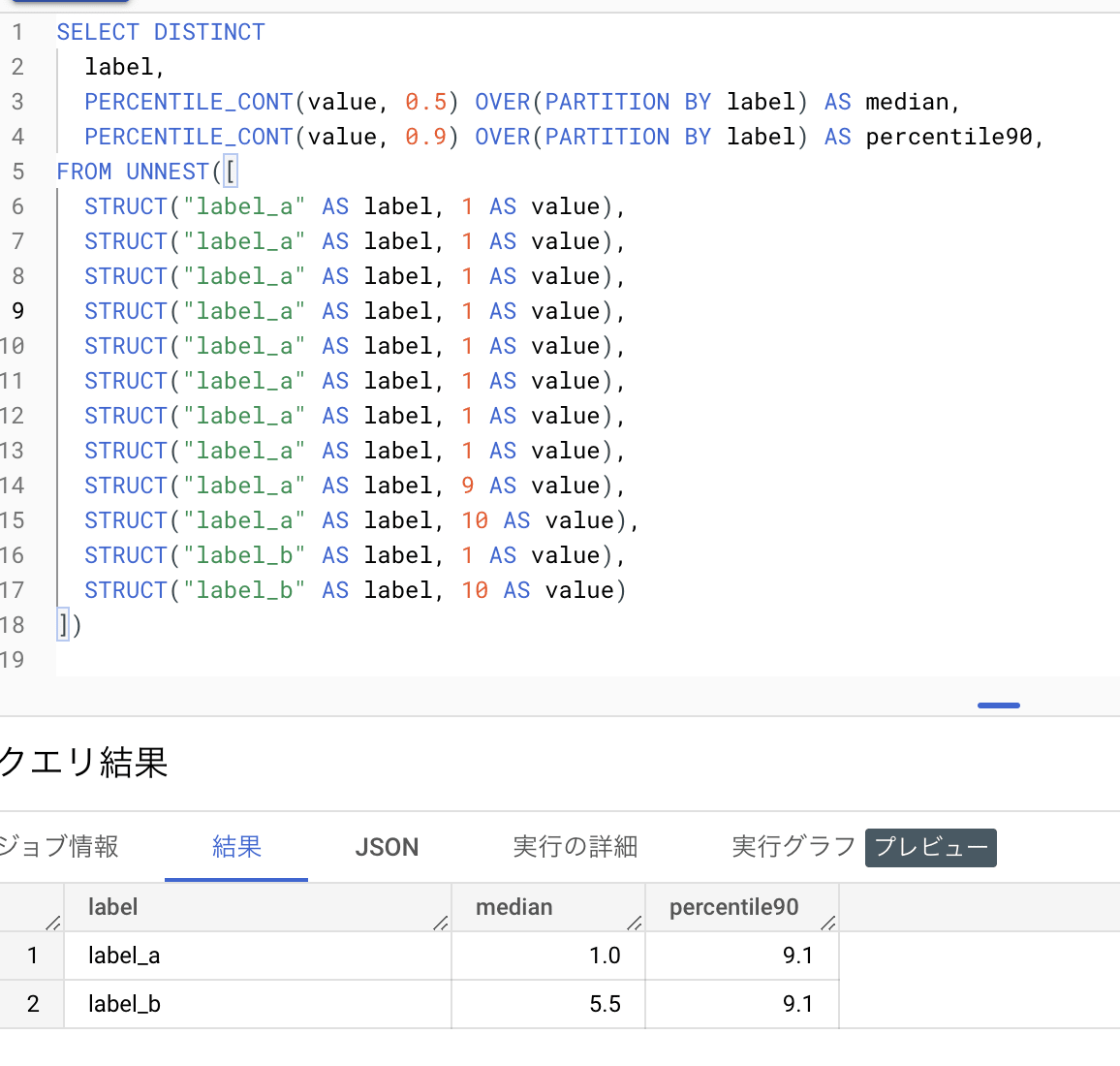
- 計算資源をたくさん使う代わりに、正確な中央値/n%tile値が計算されている。
また、 PERCENTILE_CONT() を使うと、平均値( AVG() )等の他の集計関数が同時に使えず、平均値と%tile値を同時に1つのクエリ結果に出せないのが地味につらいです。
付録: Redshiftで列の中央値/n%tile値を出す
BigQuery では集計関数で中央値/n%tile値を出すのは大変でしたが、 Redshiftでは、中央値の算出は MEDIAN() 集計関数が、
n%tile値の算出はPERCENTILE_CONT()集計関数がそれぞれ定義済みなので便利です。
BigQueryにも欲しい…
SELECT
AVG(x) _mean,
MEDIAN(x) _median,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY x) _median2,
PERCENTILE_CONT(0.9) WITHIN GROUP (ORDER BY x) _90_percentile,
STDDEV(x) _stddev
FROM _table
-
https://github.com/GoogleCloudPlatform/bigquery-utils/tree/master/udfs/community#medianarr-any-type には、%tileを計算できるUDFの定義は含まれていない。 ↩︎
-
線形補間していない例はいくつか見つかる ( https://qiita.com/dr666m1/items/74a921cf6493169e466c など) ↩︎

Discussion