はじめに
サロンスタッフ予約サービス「minimo」でバックエンドエンジニアをしている肉です。
minimoはユーザーにぴったりな美容師やネイリスト、アイデザイナー(以下、掲載者様)などを検索・予約できるサービスです。
サロンに予約するのではなく掲載者様個人に直接予約することができ、来店前にメッセージでやり取りできるのが特徴です。
minimoを説明するページがありますので気になった方や使ってみたい方はぜひ御覧ください。
前回は minimoの検索システム用に機械学習モデルを作る という記事にて
モデルを作る背景やその作り方について記事にしました。
今回は機械学習モデルを既存システムに導入した方法について紹介します。
全体アーキテクチャ概要
以下の図を用いて説明します。
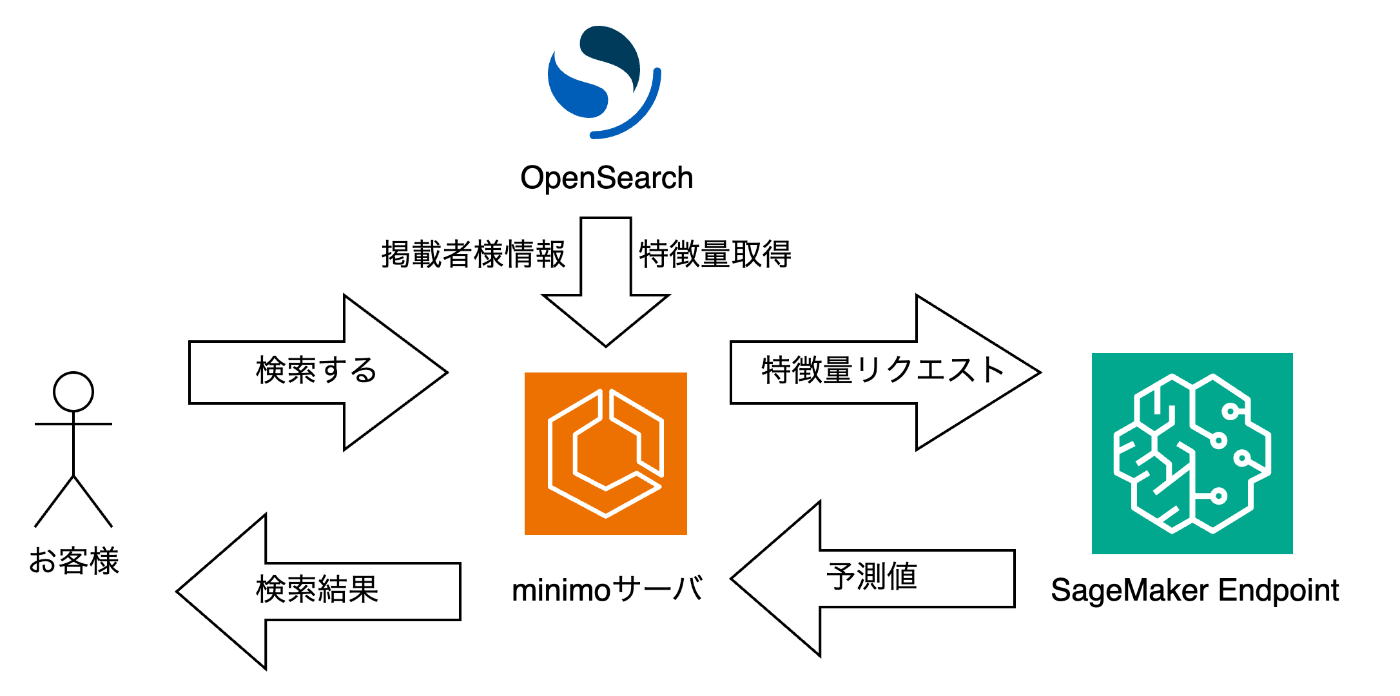
minimoではAWSを使ってインフラを構築しております。
既存システムではお客様の検索条件にヒットした掲載者様をminimo独自のアルゴリズムで並び替えを行い、検索結果をお客様に返しています。
一方、今回のシステムでは機械学習を使った推論モデルによって並び替えを行うようにしています。
これを実現するために、AWSが提供しているOpenSearchとSageMakerを使用しています。
OpenSearchは全文検索や分析を目的としたオープンソースの検索エンジンです。
minimoでは既にOpenSearchを使っておりまして、主に検索にあたってOpenSearchとRDSを併用し、掲載者様情報の取得を行っております。
今回は新たに特徴量の保存、取得のために使用しました。
OpenSearchは機械学習で使われるベクトル検索やベクトル特徴量もサポートしているので、機械学習的にうれしい検索エンジンだったりします。
SageMakerではモデルやサーバ側のコードをデプロイし、推論結果を返す用途で使用しています。
SageMaker Endpointに対して特徴量を含むリクエストを投げることで推論結果を返しています。
図の流れで行くと
- お客様が検索をする
- OpenSearchとRDSを使い検索条件に合った掲載者様情報の一覧を取得する
- 既存のシステムではこの一覧を検索結果として返していました
- 掲載者様情報を使い掲載者様の特徴量を取得する
- 取得した特徴量を使ってSageMaker Endpointに対してリクエストを投げる
- 予測値(推論結果)を受け取る
- 受け取った予測値を元に並び替えを行い後処理をし、検索結果として返す
ような流れになります。
機械学習モデルのデプロイ
minimoのインフラはAWS CDKを使い、コードで管理しています。
それに乗っかり、SageMakerへのデプロイはCIからリソースを更新することで実現しています。
minimoにおけるコンテナでの運用やCDKでの管理について詳しく知りたい方はこちらのスライドを参照してください。
SageMakerへのデプロイのイメージは下図のようになります。

これによりGitHub上からSageMakerへのデプロイを実現しています。
また、用意するインスタンスタイプについて、
Locustを用いて、ピークタイムを再現するような負荷をかけ、問題ないようなインスタンスタイプを選ぶようにしています。
どこからOpenSearchの特徴量を取得するか
OpenSearchはお客様・掲載者様の特徴量をインデックスに格納し、リクエストを作る際にOpenSearchから特徴量を取得しています。
この特徴量の取得はminimoのアプリケーションサーバが行っており、お客様の検索に対してヒットした掲載者様の特徴量をOpenSearchから取得しています。
この連携をアプリケーションサーバではなくSageMaker側でやるという方法もありましたが、特徴量の一部を後処理で使っていることもあり、取得回数を減らすという意味でこのような実装にしました。
また、ドメイン固有の実装を分散させたくない意図もありました。
大きく仕様が変わったときに該当箇所が分散していると辛いですよね。
システム連携の実装のポイント
おかげさまでminimoは月間200万人以上のお客様に使われており、日々多くの検索リクエストがあります。
そこへ新たに推論モデルを導入するとなると一定レイテンシが大きくなることが予想されます。
その一方で、検索なのでリアルタイムでお客様へ検索結果を返す必要があります。
そこでレイテンシを抑えるアイデアとして新たに推論結果のキャッシュを用意しました。
推論結果のキャッシュは、あるお客様の検索クエリに対してヒットした掲載者様の推論スコアをキャッシュするというものです。
お客様が新しい検索結果を見る際、その検索結果内に既に推論済みの掲載者様がいる場合、再度推論サーバにリクエストを送らないようにするために用意しています。
このような実装の背景に、お客様は検索結果をスクロールする毎に次の検索結果を表示して掲載者様を探す、というminimoの仕様があります。
従来であればスクロールする毎にページャをインクリメントするようなリクエストを投げていました。
しかし推論モデルの場合、検索時に条件に合う掲載者様をすべて取得後、並び替え、というのをスクロールする毎に行うのはシステムに対する負荷が大きいです。
そこでキャッシュを使うことで、SageMaker上で同じ掲載者様の推論スコアを何度も計算する必要がなくなり、レイテンシが大きくならないようにしています。
特にお客様は、自分が行きたいエリア内から検索条件を追加して絞り込むため、このキャッシュにより検索条件が被っている掲載者様の推論スコアを再計算する必要がなくなります。
結果として、従来のレイテンシに大きな影響を与えずに実装することが出来ました。
また、SageMaker側から500等が返ってきて推論できない、あるいは、事前に決めた時間以内にレスポンスが返ってこなかった場合の保険として、上記ケースが発生した場合は既存のアルゴリズムによる検索結果を返す実装を入れました。
ダウンタイムは作りたくないですよね。
運用フェーズでのモニタリング
リリース後はモデルによる推論結果のチェックや各種リソースをモニタリングしていきます。
検索はコア機能ですので、リリース時はABテストを行い様子を見ていきました。
ABテスト中は、予約率と予約された掲載者様の平均順位を中心に見ていきました。
また、OpenSearchやSageMakerへの負荷、特にピークタイムにおけるレイテンシを見ていきました。
結果としてリリース当初、予約率に有意な差が見られ、また予約された掲載者様の平均順位が上がっていることが確認できました。
特に平均順位が上がったことにより従来よりも予約される掲載者様を上に並べ替えることが出来ていることが確認できました。
しかしながら長く数字を見ることで予約率において有意な差がなくなってきたことも確認できたのですが、それは別途記事にしたいと思います。
負荷に関しましては事前の負荷試験による見積もりが効いており、ピーク時においても問題ありませんでした。
まとめ
「minimoの検索システム用に機械学習モデルを作る」 にて作った推論モデルを実際にサービスに入れ、お客様に利用していただき、効果測定を行うまでの流れについて概要を説明しました。
機械学習の実サービスへの導入を検討していたり進めている方がいらっしゃれば、是非コメントいただけると助かります!
また、コメントだけでなく一緒に手を動かしていただける仲間も募集しております!
特に機械学習を用いてプロダクトの課題を共に改善してくれる仲間を探しています!
フルリモート勤務も可能ですので、詳しくは下記採用ページをご確認ください。

Discussion