こんにちは。
ご機嫌いかがでしょうか。
自称 ”Well-Archおじさん” の 吉井 亮です。
アメリカ時間の2025年4月15日に Well-Architected Framework の Generative AI Lens が発表されました。
自分の勉強がてら要約します。要約は LLM 無し、人間の力です。
Generative AI Lens のスコープ
Well-Architected の柱に沿った主要な領域をカバーします。
- オペレーショナルエクセレンス
- 一貫したモデル出力品質
- トレーサビリティの維持
- ライフサイクル自動化
- モデルのカスタマイズ
- セキュリティ
- Gen AI エンドポイント保護
- 有害な出力を抑制
- イベント監視と監査
- プロンプト保護
- モデル汚染のリスクを低減
- 信頼性
- スループット要件のクリア
- 信頼性の高い通信の維持
- 成果物のバージョン管理
- 分散計算タスク
- パフォーマンス効率
- パフォーマンスをキャプチャし改善
- リソース最適化
- コスト最適化
- モデルの選択
- 推論のコストとパフォーマンスのバランス
- プロンプトのコスト
- ベクトルストアとワークフローの最適化
- 持続可能性
- 計算リソースの最小化
設計原則
AWS で作成された生成 AI ワークロードには、次の設計原則が適用されます。
制御された自律性のための設計
運用要件、セキュリティ管理、想定された障害ケースを確立することで、AI システムを維持します。
包括的な可観測性
セキュリティ、パフォーマンス、コスト、持続可能性の観点から、生成 AI ワークロードを可視化します。
あらゆるレイヤーからメトリクスを収集し運用を維持します。
リソース効率の最適化
AI コンポーネントの選択は経験的な要件に基づいて行われます。モデルの適正化、データの最適化、動的スケーリングにより効率的なリソース運用を実現します。
分散型レジリエンスの確立
コンポーネントまたは地域的な障害が発生しても運用を継続できるシステムを設計します。
リソース管理の標準化
構造化された管理システムを導入することで、セキュリティ、バージョン管理、運用管理などを実現します。
セキュアなインタラクション境界
最小権限アクセス、セキュアな通信、入出力のサニタイズ、包括的な監視を実装します。
責任あるAI
メリットを最大化し、リスクを最小化することを目指してAIテクノロジーを設計、開発、活用することを「責任あるAI」と呼びます。
公平性、出力の説明可能性、プライバシー、セキュリティ、安全性、コントロール、正確性と堅牢性、ガバナンス、透明性を考慮します。
生成AIライフサイクル
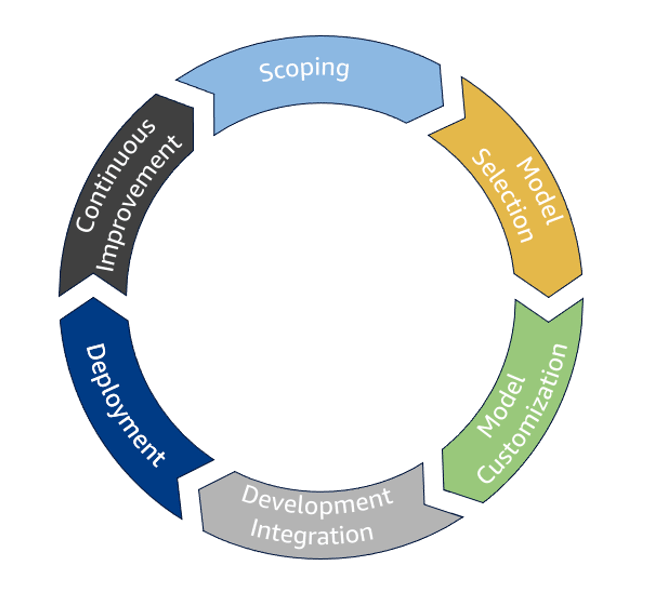
Scoping では、プロジェクトの目標、要件、潜在的なユースケースを定義します。
Model selection では、モデルの選定と導入優先順位付けをします。具体的な要件とユースケースに基づいて、様々なモデルを評価します。
Model Customization は、事前トレーニング済みのモデルを、プロンプトエンジニアリング、RAG、エージェント、微調整、継続的な事前トレーニング、モデル蒸留、人間によるフィードバック調整などの手法を用いて、特定のユースケースに合わせてカスタマイズするプロセスです。
Development Integration では、開発されたモデルを既存のアプリケーションに統合し、完全に機能する状態にして本番環境での使用準備を整えます。
このプロセスには、推論のためのモデルの最適化、エージェントワークフローのオーケストレーション、RAGワークフローの強化、ユーザーインターフェースの構築が含まれます。
Deployment では、モデルを本番環境にデプロイし、ユーザーが利用できるようにします。
Continuous Improvement では、継続的な改善が行われます。導入されたモデルのパフォーマンスを監視し、ユーザーからのフィードバックを収集し、モデルに反復的な調整を加えることで、精度、品質を高めるという継続的なプロセスを指します。
データアーキテクチャ
生成 AI におけるデータの3つの主要なユースケース、事前学習、ファインチューニング、RAG に焦点を当てます。
膨大かつ多様なデータセットの管理と処理を行うために、主に非構造化データのデータ品質管理、大規模データセットの効率的な保存と取得、処理に必要な計算リソースの管理などが必要です。
ファインチューニングは、事前学習済みモデルを特定のタスクやドメインに適応させることに重点を置いており、より小規模で焦点を絞ったデータセットを使用します。
ファインチューニングのためのデータアーキテクチャは、迅速な反復処理、効率的なデータ前処理、データセットとモデルパフォーマンスの関係性を追跡するためのバージョン管理をサポートする必要があります。
RAG データアーキテクチャは、大規模な知識ベースの効率的なインデックス作成、リアルタイムのデータ検索、最新情報の維持といった要件に対応する必要があります。
オペレーショナルエクセレンス
オペレーショナルエクセレンスの柱 を一読することをおすすめします。
定期的にモデルパフォーマンスを評価します。
モデル出力を Ground Truth Data と比較するテストを実施し、モデルの潜在的なドラフトや劣化を測定します。
ユーザーからのフィードバックを評価に使います。「いいね」のようなシンプルなもので構いません。フィードバックはアプリケーションでキャプチャしデータベースへ保管します。
定期的なレビュープロセスを確立し継続的な改善を行います。
すべてのレイヤーでメトリクスとログを収集します。一般的なアプリケーションと同じです。
モデルの継続的な監視とアラートが必須です。データドリフト、モデルの劣化、セキュリティ上の脅威といった問題に対処します。
AI アプリケーションの安定性とパフォーマンスを確保するために、レート制限とスロットリングを実装します。過負荷を防ぎ、DoS 攻撃の緩和に役立ちます。
バージョン管理されたプロンプトテンプレート管理システムを実装、チームがプロンプトを体系的にバージョン管理、テスト、最適化できるように支援します。
変更のトレーサビリティが強化され、迅速なロールバックが可能になります。
AI エージェントと RAG ワークフローにトレースを実装し、モデルの挙動を可視化します。非効率な入出力の特定、ボトルネックの特定、効率的なデバッグが可能になります。
IaC を実装します。CI/CD パイプラインを通じてインフラ管理を自動化します。
GenAIOps を導入します。これはモデルの開発、展開、管理を自動化するベストプラクティスです。(企業・組織レベルの大きな話ですが、全体的な推進をしている立場の方は参考になると思います。)
モデルのカスタマイズよりも、プロンプトエンジニアリングとRAGを優先します。モデルのカスタマイズに伴う時間、コスト、複雑さを軽減可能です。
特定のユースケースやドメイン固有の知識、トレーニング用の大量データを有しているなどの事情があればモデルカスタマイズを検討します。
セキュリティ
セキュリティの柱 は全員必読ですね。
Gen AI でも最小権限の原則は忘れてはいけません。
Bedrork、SageMaker AI 等の API エンドポイントへのアクセスは IAM ロールに限定します。この IAM ロールは最小権限です。
基盤モデルとアプリケーション間はプライベートネットワーク通信を実装します。
データアクセスに最小権限を適用します。RAG は安全な VPC 内に配置します。
学習に使用するデータは難読化と匿名化を行い、意図しない漏洩を防止します。
ガードレールを実装して望ましくないモデル出力の識別と修復を自動化します。ガードレールを用いることによってコンテンツ、トピック、機密情報に基づいて応答をフィルターします。
ユーザーからの入力をサニタイズします。インジェクションや不適切なコンテンツが生成されるリスクを抑制します。
プロンプトカタログを保護します。職務に合わせた最小権限の IAM ロールを作成し、カタログへのアクセスを制御します。
事前トレーニングおよび進行中のトレーニング段階において、トレーニングジョブにデータを導入する前に、データを検査し汚染されていないことを確認します。
信頼性
信頼性の柱 がベースです。
AWS の他サービスと同じく AI サービスにもクォータがあります。クォータをコントロールし、必要に応じて緩和申請を行います。
Quotas for Amazon Bedrock
ワークフローに回復ロジックを実装します。条件分岐、ループなどを駆使して、再試行、エラー処理、適切な失敗を実装します。
長時間の処理、無限ループはリソースを消費します。エージェントの信頼性を高めるため、ワークフローにタイムアウト管理を実装します。
エラーメッセージングは機密性の高い内部情報の漏洩を防止しつつ、ユーザーに代替パスを提供します。ユーザーエクスペリエンスに重点を置くエラーメッセージングを実装します。
プロンプトカタログは信頼性にも寄与します。いつでもデプロイ、および、ロールバックできるプロンプトカタログを実装します。
モデルのハイパーパラメータはプロンプトカタログとペアで検証する必要があります。
Gen AI でも信頼性への考慮は忘れてはいけません。
アプリケーションのコンポーネント間にネットワーク接続の冗長性を確保します。
複数の AZ 間でモデルリクエストや RAG を負荷分散し、耐障害性を高めます。
データを保護するために利用可能なリージョンにデータレプリケーションします。
また、エージェントの機能が利用するリージョンで利用可能であることを事前に確認しておきます。
モデルの事前学習、微調整、蒸留を行う場合はフォールトトレランスなインフラストラクチャを用意します。これらのタスクは長時間のコストと時間がかかります。確実にタスクを実行できるインフラストラクチャにしておきます。
パフォーマンス効率
パフォーマンス効率の柱 がベースとなりつつ、Gen AI でのパフォーマンス効率についての言及です。
Groud Truth Data を用意します。これは、プロンプトとその望ましい応答の組み合わせで、真であると分類されたデータです。
テストケースに応じて変更・拡張する必要がある生きたデータです。
Gen AI において、モデルのパフォーマンスを測定し、評価することが重要です。Gen AI を含めたアプリケーション全体のパフォーマンスを分析します。
負荷テストを行いパフォーマンスベースラインを特定し、継続的な運用に役立てます。
モデルのパフォーマンスはハイパーパラメータに影響する場合があります。ハイパーパラメータを最適化することでパフォーマンスを改善します。
各パラメータの最大値と最小値をテストし、結果を Groud Truth Data と比較すると良いでしょう。ほとんどの場合、大規模なテストは必要ありません。数回の反復で十分です。
ユースケースに適したモデルを選択します。Groud Truth Data によるテストに加え、難解なプロンプト、意図的なプロンプトを試します。一連のテストに加えて公開ベンチマークを参考にすることも選択肢です。
テストで決定的な結果が得られないときはモデルルーターを検討します。モデルルーターは、プロンプトに基づいて最適なモデルにルーティングします。
プロンプトや RAG で不十分な場合はモデルカスタマイズを行います。カスタマイズは大量のリソースを消費することになり、パフォーマンス的な考慮事項です。
ベクトルストアを最適化すると関連性の高いデータを取得可能です。
チャンキングとエンベッティング、アルゴリズム、インデックス、クエリの最適化にチャンレンジし、パフォーマンスを継続的に監視し評価します。
コスト最適化
コスト最適化の柱 と基本的な考え方は同じです。
過剰なプロビジョニングを避け、最適なモデルの選択、コストに影響を与えるパラメータを調整します。コストを監視し予測することも忘れずに。
モデルを選択する場合、コストを考慮します。Amazon Bedrock の料金
まずは小規模なモデルからテストを始めて、徐々にモデルのサイズと機能を増やしていくことで、費用対効果が高いモデルを選択できるようになります。
モデルはマネージド型、セルフホスト型があり、それぞれのコストとパフォーマンスを考慮して決定します。
入出力のトークン数を抑えることがコスト削減には重要です。
プロンプトを短くすることで推論コストを抑制します。具体的には、不要な単語を削除します。テストを継続して最適なアプローチを見つけます。場合によってはモデルを変更します。
モデルからの応答の長さによってコストが変わります。応答はできるだけ簡潔にするよう工夫します。モデルのパラメータで出力トークン長を抑制したり、プロンプトに簡潔さを促す指示をします。
ベクトルストアに埋め込む際のチャンクデータ長を短くします。ただ、これはパフォーマンスを低下させる可能性があるのでトレードオフを考慮して行いましょう。
エージェントが長時間実行されるとコストに影響します。ワークフローにタイムアウトやループ上限を設け、無用な長時間実行を防止します。
持続可能性
管理しているワークロードに適したリソースを選択・使用することが環境への配慮になります。
AutoScaling を備えたサーバーレスアーキテクチャを採用するとリソース効率が改善します。
より効率よく Gen AI モデルを利用するには、量子化とプルーニングが有効です。
量子化とは、モデルの重みと活性化を表すために使用される数値の精度を下げることです。
プルーニングとは、モデルから冗長または不要なパラメータを削除することです。
大規模な汎用モデルに頼るのではなく、特定のユースケースに合わせて調整された小規模なモデルを微調整することで、少ない計算リソースで同等の結果が得られることがあります。
おまけ
トップページ がすでに要約だったという・・・

Discussion