WaveGlowの要点整理とメモ
昔からWaveGlowの論文は目を通していたが,最近になりようやく理解が追いついてきたので要点整理とメモを行う.
参考リンク
- 論文
- [DL論読会]Glow: Generative Flow with Invertible 1×1 Convolutions
- [DL輪読会]Flow-based Deep Generative Models
- NVIDIA公式の実装
WaveGlowのここが凄い
- 自己回帰しないので推論が速い(最近だとデフォルトだが)
- 直接尤度の最大化で最適化できる
Flow-based generative modelの復習
まずはFlow-basedの生成モデルの簡単な復習から行う.こちらの記事が分かりやすいので,詳しく知りたい方はこちらを参照
簡単に言うと
サンプリングや尤度を求めるのが簡単な潜在変数から,簡単かつ逆変換可能な関数を複数回適用することでデータの分布を求める生成モデル.学習時はデータに逆変換した関数を適用して潜在変数を求めて,その尤度を最大化する.多くは,オーバーフローを起こさないように負の対数尤度を最小化する.
WaveGlowの場合
球面ガウスに従う潜在変数
この関数
ただし,
である.また,
ただし, サイズが
のJacobianの行列式の計算には D×D の計算量が必要なので, O(D^3) が大きくなるとlog-detが計算時間のボトルネックになります. 実際, Glowで生成しているCelebAの画像は D =256×256×3≃200,000次元です. したがって, 現実的にはJacobian行列式を高速に計算するための工夫が必要になります. 詳しくは後で述べますが, Jacobianが三角行列になるような工夫をしたり, log-det自体をtraceによって近似したりといったアプローチがあります. D
ゆえに,ネットワーク構造の箇所で,ヤコビアンの計算が簡単になる点についても触れていきたい.
ネットワーク構造
ネットワーク構造は以下のようになる.
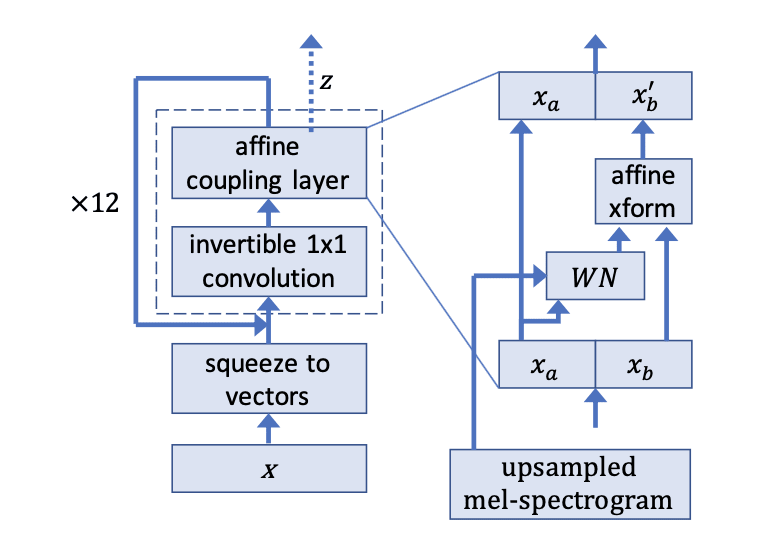
R.Prenger et al.2018
基本的には,Glowのアーキテクチャを,音声波形の生成ができるように置き換えたと考えて良い.以下にネットワークの詳細を記す.
squeeze to vector
入力の音声を8サンプルごとにベクトルとしてグループ化する.実験では,音声データを16000サンプルに区切って学習を行っているため,データサイズを8×2000に変換している.
なぜ行うか
Real NVPとは違い,所謂step of flowのたびに行っているわけではない.これは,音声波形の時間方向をそのまま扱うのは冗長で,8サンプルでグルーピングしたほうが学習の効率が良いからなのでは,と考えている.正直なところあまり言及されていないのでここはもう少し理解を深めたいところである.
invertible 1×1 convolution
Glowで用いられている手法である.後述のaffine coupling layerで,
となる.
Glowでのinvertible 1×1 convolutionとの違い
Glowでは,このconvolutionの重みをLU分解を行うことで対角行列にして,行列式の計算を簡単にしている.一方,WaveGlowではこのconvolutionの重みを正規直交で初期化することで逆行列が存在することを担保している.直交行列の性質より,
であることから
と対数尤度が0になる.このため,WaveGlowではLU分解を行わずに直接
affine coupling layer
基本的な構造はGlowと同じであるが,WNはWaveNetに似たDilated Convolutionsとskip connectionsで構成されている.違いとしては,causal convolutionではなく,未来方向の情報も畳み込んでいることである.
計算
まず,入力をチャンネル方向に半分にする.
そして,
affine xformで,
ただし,
affine coupling layerの対数尤度
論文では省略されているが,affine coupling layerのヤコビアンは以下のようになる.
affine xformのおかげで,ヤコビアンが三角行列になる.ゆえに,
とaffine coupling layerのヤコビアンは簡単に求めることができる.
WaveGlowの対数尤度
以上より,WaveGlowの対数尤度は以下の式で表せる.
最初の項は,球面ガウスの対数尤度である.
Early outputs
ネットワークの図には記されていないが,学習時は4つのcoupling layerごとに出力から2チャンネルのデータを損失関数に加えている.実験ではinvertible 1×1 convolution,affine coupling layerそれぞれ12層で構成されているため,4層目と8層目のときにEarly outputsを行っている.こうすることにより,浅い層の学習の効率が良くなるとのこと.発想としてはReal NVPのmulti-scale architectureに似ている.
推論
推論時は,ガウス分布からサンプリングした潜在変数
推論時,invertible 1×1 convolutionは重みの逆行列を求める.一方,affine coupling layerでは,
という計算によって逆変換を行う.これは学習時の
評価
サンプル音声.聞いた印象だと
- WaveNetよりも,「スーッ」といった少しノイジーな音声の再現度がより自然に聞こえる.(サンプル音声の上から3番目は分かりやすいかと)
- ただし,Tacotron2+WaveGlowだと,少し機械音のようになってる箇所がある.これがTacotron2のメルスペクトログラムの精度によるものなのかは判断が難しい
感じたこと
- 他のFlow-basedのモデルにも通ずることだが,教師データとの差分を取って誤差を最小化するのではなく,尤度を直接最大化する考え方は面白いなと
- ただ,1つ1つの重みの表現力が制限されることで,結果としてかなり深いネットワークになることが考えられる.GPUメモリの効率としてはどうなのだろうと疑問
- VAEやGANと比べて,最適化の難易度が気になる.
まとめ
Flow-basedな生成モデルを用いたニューラルボコーダであるWaveGlowの要点整理を行った.かなり数学的なモデルになっていて,尤度を直接最大化するというのは非常にかっこいい.しかし,いかんせん数学の知識がまだまだ及ばないため,これら周辺技術の調査をしつつ,わからない知識は適宜勉強し直して行きたいところである.また,過去に実装を動かしたことがあるがソースコードの理解ができていなかったため,ソースコードの理解にも努めていきたい.
Discussion