相変わらず,WaveNetとは異なるニューラルボコーダーを調査していたところ,ソースフィルタモデルのニューラルボコーダーを発見.面白いアイデアが使われていたのでネットワークと誤差関数の解説を行う.
論文リンク
ネットワーク構造
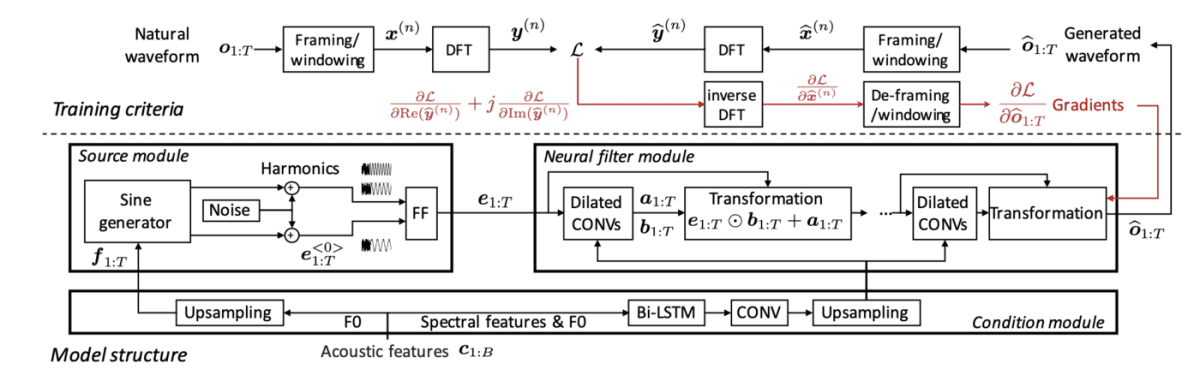
X.Wang et al.2019
上図はネットワーク構造である.NSFは
- Condition module
- Source module
- Neural filter module
の3つのmoduleで構成されている.以下に1つずつ説明していく
Condition module
音響特徴量のF0とSpectral features(論文ではMel-generarized cepstral coefficients)を,Source moduleとNeural filter moduleへと渡す前処理を行う.それぞれの前処理は以下のようになる.
F0→Source module
長さ_B_の基本周波数F0を音声波形長_T_にUpsampleしてSource moduleへと渡す.図のf _{1:T}がそれに該当する.
Spectral features & F0 → Neural filter module
Bidirectional-LSTMとConv Blockを通してから音声波形長TにUpsampleしてNeural filter moduleへ渡す.
Source module
このmoduleでは
- sin波の生成
- 訓練時の位相マッチ
- 生成信号への情報付与
の3つの処理を行う.sin波の生成はこのモデルにおける重要なポイントであり,品質に大きな影響を与えている.それ以外の処理は,本論文では品質の向上に有意な差がなかったため,簡単に説明する.
sin波生成
Condition moduleから得たf _{1:T}を元にsin波を生成する.WaveNetは過去の出力,その他のニューラルボコーダはガウス雑音を入力としているが,sin波を生成してそれを入力とするのがこの論文の面白い点である.
考察
他のニューラルボコーダは,音声波形の確率分布を求めているのに対して,NSFは基本周波数に対してどのような調波構造を付与するか,といった決定論的な考え方に基づいているのではないかと考えている.
訓練時の位相マッチ
訓練時は,生成するsin波の位相を教師信号と相関が最大になるものを用いる.生成時はランダムに位相を決定する.
生成信号への情報付与
各時刻tに対して以下の式を生成sin波に適用する.
\begin{align}
e^{<0>}_t =
\begin{cases}
\alpha sin(\sum^{t}_{k=1}2\pi \frac{f_k}{N_s} + \phi) + n_t & (f_t > 0) \\
\frac{1}{3\sigma}n_t & (f_t = 0)
\end{cases}
\end{align}
有音区間では倍音+ガウス雑音,無音区間ではガウス雑音のみを付与する
Neural filter moduleへ
上の処理で得た信号e^{<0>} _{1:T}は,FeedForward layerを通してNeural filter moduleの入力e _{1:T}として用いる.
Neural filter module
Source moduleの生成信号e _{1:T}を入力,条件付きベクトルとして[Condition moduleで前処理した特徴量](### Spectral features & F0 → Neural filter module)を用いて,以下のDilated CONVsとTransformationを複数回適用することで音声波形\widehat{o} _{1:T}を生成する.
Dilated CONVs
入力e _{1:T}をDilated CONVsに通して,出力a _{1:T},b _{1:T}を得る.Dilated CONVsはParallel WaveNetと同様に複数のDilated convolutionとCondition moduleの特徴量を用いたgated activation functionsで構成されている.また,b _{1:T}を正の値にするためにb _{1:T} = e^{b _{1:T}}とする.
そして,Transformation blockで,
e _{1:T} \odot b _{1:T} + a _{1:T}
を計算する,
e _{1:T} \odot b _{1:T}は要素積である.
bの役割
b _{1:T}は正の値であること,Dilated CONVsの入力e _{1:T}と要素積を行っていることから,e _{1:T}の情報をどの程度次のFeedForwardで利用するかといった係数の役割を果たしていると考えられる.また論文では,b _{1:T}=1(skip connection)や,b _{1:T}=0(skip connectionなし)と値を固定して比較実験を行った所,b _{1:T}=1のときにMOS値が最も良くなっていた.そのため,下手にb _{1:T}をネットワーク内で計算するより,素直にskip connectionしたほうが品質に良い影響を与えている.
誤差関数
WaveNetと異なり,波形領域では損失関数の計算を行わず,DFTを用いて周波数領域で計算を行う.そしてiDFTを用いて波形領域に戻すことで勾配を求める.この方法により,勾配の計算を効率よく行う事ができる.この損失関数より,このモデルは確率的勾配降下法で学習を行う.
音声波形→スペクトル
生成音声\widehat{o} _{1:T}を,
\widehat{x}^{(n)}=\left[\widehat{x}^{(n)} _1,\dots,\widehat{x}^{(n)} _M\right]^T
とNフレームに分割し,ハニング窓を掛ける.そして,\widehat{x}^{(n)}を\widehat{y}^{(n)}=\left[\widehat{y}^{(n)} _1,\dots,\widehat{y}^{(n)} _K\right]^Tと周波数ビンKでDFTを行う.自然音声も同様の処理でスペクトルを算出する.
スペクトル振幅距離
生成音声と自然音声の双方を離散フーリエ変換を行い,周波数領域で誤差をとる.教師の音声波形のスペクトルをy^{(n)},生成音声のスペクトルを\widehat{y}^{(n)}とすると式は以下の様になる.
\mathcal{L}_s=\frac{1}{2}\sum^{N}_{n=1}\sum^{K}_{k=1}\left [log\frac{Re\left(y^{(n)}_{k}\right)^2 + Im\left(y^{(n)}_k\right)^2}{Re\left(\widehat{y}^{(n)}_{k}\right)^2 + Im\left(\widehat{y}^{(n)}_k\right)^2} \right ]^2
Re(\cdot),Im(\cdot)はそれぞれスペクトルの実部(振幅スペクトル)と虚部(位相)である.
Parallel WaveGAN等,周波数領域での損失を計算する手法はあるが,この手法の面白いところは,位相の情報も利用していることである.後に逆離散フーリエ変換を行うためと考えれば当たり前だが,位相情報を利用して損失の計算を行っている手法は初めて見た.
勘違いしてました、単純に複素数の絶対値の2乗をとってるだけなので、対数振幅スペクトルの計算を行ってるだけです。
また,Parallel WaveGANと同様に,複数の周波数ビンで離散フーリエ変換を行い,それぞれの誤差を加算することで,より音声の品質が向上する.窓長が1種類のみだと,pulse-train noiseが発生するとのこと.これが音声としてどのように現れるのかは不明である.
勾配の計算
確率的勾配降下法で学習するために\frac{\partial \mathcal{L}_{s}}{\partial \widehat{o} _{1:T}}を計算する必要がある.この勾配を求めるためには,{\bf g}^{(n)} =\frac{\partial\mathcal{L} _s}{\partial Re\left(\widehat{y}^{(n)}\right)}+j\frac{\partial\mathcal{L} _s}{\partial Im\left(\widehat{y}^{(n)}\right)}の計算を行えば良い.
なぜか
{\bf g}^{(n)}はエルミート対称性であることから{\bf g}^{(n)} =\frac{\partial \mathcal{L} _{s}}{\partial \widehat{x}^{(n)}}が成り立つ.
また\widehat{x}^{(n)}は生成波形をフレーム処理と窓関数の適用をしただけなので,
\widehat{o} _tと\widehat{x}^{(n)} _mの対応関係はすぐに求めることができる.
このあたり,数学の知識不足でイマイチ理解できていないため,今後理解を深める.
位相距離
スペクトルの位相を用いて以下のように求める.
\begin{aligned}
\mathcal{L}_p &= \frac{1}{2}\sum^N_{n=1}\sum^K_{k=1}\left|1-exp\left(j(\widehat{\theta}^{(n)}_k-\theta^{(n)}_k)\right)\right|^2 \\
&=\sum^N_{n=1}\sum^K_{k=1}\left[1- \frac{Re\left(\widehat{y}^{(n)}_{k}\right)Re\left({y}^{(n)}_{k}+\right)+Im\left(\widehat{y}^{(n)}_{k}\right)Im\left({y}^{(n)}_{k}\right)}{\left|\widehat{y}^{(n)}_{k}\right|\left|{y}^{(n)}_{k}\right|}\right]
\end{aligned}
ただし,本論文では位相距離を損失関数に加えても,品質に良い影響が出ていないため,詳しい説明は省略する.
サンプル音声
著者の上げているサンプル音声.本論文のNSFはb-NSFと表記されているものである.サンプル音声には,音響特徴量としてメルスペクトログラムを用いて学習されているものもあり,さらに発展手法のサンプルも聞くことができる.
感じたこと
- 学習の工夫として,位相情報を用いたものはあまり品質に影響しておらず,位相情報を扱うのは難しい
- 音声の品質に関して,サンプルを聞く限りWaveNetに引けをとらない品質で驚いた.これで自己回帰も知識蒸溜も必要ないのは素晴らしい
まとめ
Neural Source Filterは発展手法や,TTSに適用したもの等,関連論文全てを見るのは大変である.しかし,品質を考えると今後着目していきたいニューラルボコーダであると感じている.また,論文ではDFTやiDFTの実装に関する記述がしっかりなされているため,興味があれば論文を読むことをおすすめする.
Discussion