Kaggleでpytorch-tabnetの学習済みモデルを読み込む方法を力技で見つけた
背景
Kaggleにてpytorch-tabnetを利用したとき、kaggle notebookでのGPU利用時間の節約のために、学習済みモデルの保存をしてました。
しかし、別のnotebookにモデルをアップロードして読み込もうとしたところ、エラーが発生して上手く読み込めませんでした。これはKaggleの仕様が原因で、対処に少し苦労をしました。備忘録として、その解決方法を記事にしました。
コードだけ欲しい方は、notebookを公開してるので、こちらからコピーしたりして使ってください。
何をしたか?
-
io.BytesIO()とzipfileを使って解凍されたモデルを再びzipファイル化 - zipファイルにしたbyte objectを
clf.load_model()で読み込む
詳しく解説
まず、pytorch-tabnetのモデル出力に関する説明をしてから、Kaggleの仕様によってモデル読み込みが上手く行かなくなることを説明します。その後、コードに関する解説を行います。
モデルの出力
pytorch-tabnetのREADMEの方法でモデルの保存を行うと、ハイパーパラメータとモデルの重みがzipファイルとして出力されます。
モデルの読み込みを行う場合は、保存したzipファイルのファイル名を指定(.zipは書かない!)することで学習済みモデルの読み込みができます。以下、コードを引用します。
# save tabnet model
saving_path_name = "./tabnet_model_test_1"
saved_filepath = clf.save_model(saving_path_name)
# define new model with basic parameters and load state dict weights
loaded_clf = TabNetClassifier()
loaded_clf.load_model(saved_filepath)
Kaggleの仕様
Kaggleでは、使用したいファイルをinputフォルダにアップロードします。
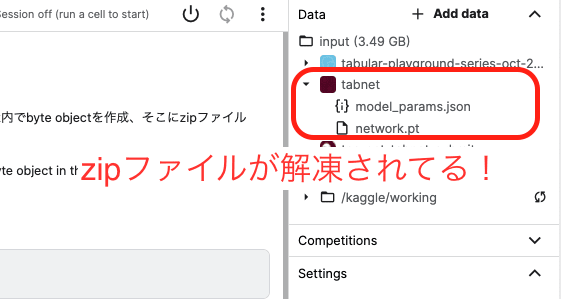
ここで、学習済みモデルのzipファイルをアップロードすると、自動でファイルが解凍されてしまいます
以下、Kaggle Staffのコメントを引用します
ZIP archives are automatically accessible in Kaggle Kernels so you can just access your files as if they were already unzipped.
どうやら、Kaggleの仕様で、zipファイルをアップロードすると勝手に解凍されてしまうようです。
データセットの場合は便利ですが、今回のようにzipファイルじゃないと読み込んでくれない、といったケースでは困りものです。
更に、inputフォルダはread-onlyのため、解凍されたフォルダを再びzip圧縮することも出来ません。
解決方法
フォルダに書き込めない、となったため、ファイルに書き出さずにzip圧縮を行う方法を採用しました。全体は公開してるnotebookをみてください。ここでは要点だけ書きます。
tabnet_zip = io.BytesIO()
with zipfile.ZipFile(tabnet_zip, 'w') as z:
z.write('../input/tabnet/model_params.json', arcname='model_params.json')
z.write('../input/tabnet/network.pt', arcname='network.pt')
ポイントとしては、ioストリームを利用して、byte objectにzip圧縮したファイルを出力します。
これにより、read-onlyの制約を回避しつつ、zipファイルの作成が行なえます。引数arcnameは指定した名前でzipファイルに書き込みを行います。省略すると、第一引数と同じ名前になるのですが、そうするとpytorch-tabnetが想定するフォルダ構成と変わってしまうため、モデル読み込み時にエラーがでます。必ずファイル名のみに変更してください。
作成したストリームを、以下のようにして読み込みます
clf = TabNetClassifier()
clf.load_model(tabnet_zip)
終わりに
今回は、Kaggle notebookの仕様もあり、かなり力づくで解決をしました。今回のケース以外でも、Zipファイルである必要が出てきた場合には、ぜひ活用してみてください。
Discussion