プログレッシブJPEG
デコード方法が仕様書に書いていないプログレッシブJPEG
いくつかの省略
ここではBaseline JPEGで出てくる情報は省略している。そもそもBaseline JPEGの資料はその辺に転がっているので省略。
取りあえずDC成分とAC成分の説明を。JPEGは8x8のブロック単位で処理をし、離散コサイン変換と言う処理を行い、色情報をDC成分とAC成分に分離する。DC成分は、そのブロックの代表である。わかり安く言うとDC成分は平均。AC成分は変化である。言い替えるとエジソンとテスラである。このデジタル離散変換は、AC成分は上の方に低周波成分が、下の方に高周波成分が集まる性質がある。と書くと何も分かっていない人がコピペした様にしかみえない。
要するに分かりやすい変化が上の方に集まり、分からないだろうと言う情報が下に集まるのである。この見ても分からないだろうと言う情報を切り捨て(これを高尚な言葉で量子化と言う)、データを0だらけにすることで圧縮率を高めるのである。この切り捨てた情報は戻ってこないので非可逆圧縮と言われている訳である。
なおJPEGにおいて、DCTをかけた8x8のブロック(高尚な言葉では行列と言う)の64のうち最初の一つ[0,0]をZZ(0)と書くことが多い。これがDC成分で、残りは全てAC成分である。要するに最初の一つがエジソンで残りはテスラである。
スキャンヘッダについて
プログレッシブJpegにおいて鍵になるのはスキャンヘッダである。スキャンヘッダはSOSマーカーの後に出てくる定義で、使用するハフマンコードとイメージに格納されているコンポーネントについて定義しているヘッダである。イメージデータは必ずこのヘッダの後にくる。
このヘッダで定義されているのは以下の通り
- Ns 成分数 SOSマーカーの後に続くイメージデータに格納されている成分数。次のSOSマーカーまで有効。Nsの数だけCs/Td/Taが定義されている。カラーイメージの場合は、Ns=3になるのだが、プログレッシブJpegの場合、3の場合と1の場合がある。
- Cs 成分ID イメージデータに格納されている成分ID カラーイメージの場合、成分ID 1 = Y(輝度)、 2 Cb(青成分) 3 Cr(赤成分)になる(これはJpeg本体では定義されていない)
- Td DC成分ハフマンテーブル このイメージデータが使うDC成分のハフマンテーブルの番号
- Ta AC成分ハフマンテーブル このイメージデータが使うAC成分のハフマンテーブルの番号
- Ss 量子化係数開始番号 デコードするブロックの最初の番号で、最少は0 ZZ(Ss)などとかく。
- Se 量子化係数終了番号 デコードするブロックの最後の番号で、最大は63。またSeはSsと同じか大きい必要がある。 ZZ(Se)などとかく。
- Ah 前回のスキャンのシフト量 後述するsuccessive approximationで利用する。必ずAhは0もしくはAl+1になる。
- Al シフト量 プログレッシブJpegとロスレスで利用する。Alは13を越えてはいけない。単純に書くと ZZ(k) = Z << Al になる。これはデジタル離散変換の特性を活かして、最初は大まかな数字をあたえてデコードし、後から数字精度を上げて解像度をあげる手法をとるためである。
プログレッシブJPEGのエンコード方法
プログレッシブJPEGのエンコード方法についてはISO/IEC 10918-1のAnnex Gに書かれている。だがデコード方法は書くのが面倒だから(高尚な言い方では煩雑になるから)エンコードを逆順にやれとだけかかれている。しかし、プログレッシブのエンコードの説明自体があちこちに飛びまくっているのでデコード方法を逆算するのも面倒なのだ。
JPEGのエンコードは8x8のブロックに分割し、離散コサイン変換で、高周波成分(変化の大きい部分)を上の方に固め、各ブロックを量子化(割り算)、たくさん0を生成し、ハフマンもしくは算術符号で圧縮すると仕組みである。この処理はシーケンシャルで行われる。つまり上から順番に処理する。
それでは、プログレッシブJPEGはどのようなものかと言うと、大雑把な全体のデータを最初に表示し、徐々に細かくしていくのである。DC成分だけでも8x8のモザイク状の画像で、サムネイルには十分使える。そのためつまり8x8のデータの上の方だけをエンコードし、次に中の方、最後に後ろの方をエンコードするわけである。
その時、デコードされていないデータは0で埋められる。下のデータはイメージである。ちなみに格納するときはジグザグにスキャンされ、{100,20,10,2,3,4,0,....,0}と展開される。仕様書では最初をZZ[0]、最後をZZ[63]と定義している。
| 100 | 20 | 4 | 0 | 0 | 0 | 0 | 0 |
| 10 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
なお仕様書にスキャンを何回に分割するべきか、一度のスキャンで読み取る数は全く指定されていないので全てエンコーダの方が決定する。たとえば、最初のスキャン → 100(DC成分のみ) 2番目のスキャン 20,10,4,3,2 3番目のスキャン 残りの0 全部と言う感じにする。これをスキャンヘッダに書き込むとき、最初のスキャン Ss=0,Se=0,2番目のスキャンSs=1,Se=6,3番目のスキャンSs=7,Se=63と表記する。
ただし、リファレンス実装がDC成分とAC成分を必ず分けて実装しているのでDC成分とAC成分が同時にでてくるプログレッシブJPEGは恐らく存在しない。
この情報は、SOS (0xffda)ヘッダーのSs及びSeに書かれている。そのため、SOS (IMAGEDATA) SOS (IMAGEDATA2) SOS ... EOI と言う構造になっている。ただし、SOSの前にはDHT(ハフマンテーブル定義)を置くことができる(それ以外も置けるらしいが意味があるのだろうか)。これもエンコーダに任されておりスキャンごとにDHTをおいているケースと最初にまとめているケースがある。
baselineではこの数字は通常無視される(仕様的にはSs=0,Se=63にするのがただしい)SSは、ブロックの起点、SEは終点を指しており、上記のケースだと、一度目は 0,0 、二度目は、1,5、三度目は、6,63 になる。これだけなら実装はさほど難しくないのだ。
しかし、プログレッシブJpegにはもう一つ、AhとAlと言う情報を使用して段階的に精度をあげていく仕組みがある。
コンポーネント単位のエンコード
プログレッシブJPEGでは、コンポーネントを別々に計算する場合がある。既存のエンコーダではAC成分を計算する場合はほぼY,Cb,Crの各コンポーネント単体で行われ、DC成分のみを計算するときだけY,Cb,Crをまとめる計算していることが多い。通常(シーケンシャル)のJpegは、Y,Cb,Crを一つのブロックにまとめて計算している。
SOS (0xffda)ヘッダーがNs=3で、Y=4,Cb=1,Cr=1の場合(これはSOFの後にあるフレームヘッダーにC1 H2 V2,C2 H1 V1,C3 H1 V1などと書かれている)、Y成分の2x2のブロックを単位とし、Cb、Crの成分は間引きして一ブロックにする。つまり最少単位は16x16になる。ところが、Ns=1の場合は8x8に変わる。プログレッシブJpegの場合、前に展開した係数を保存して置く必要があるため、毎回、順番が変わる可能性があるわけである。言い替えると実装が面倒くさいのである。
このコンポーネント単位のエンコードをおこなう場合、MCUブロックが変化する。筆写泣かせの仕様であった。初期実装にYUV4:1:1のプログレッシブJpegだけコケるバグがあったのだが原因はループごとに読み出し順が変わるからであった。筆写以外のプログレッシブJpegの実装はこの仕様を華麗にかわしているのだが、筆写は泥臭く回避した。
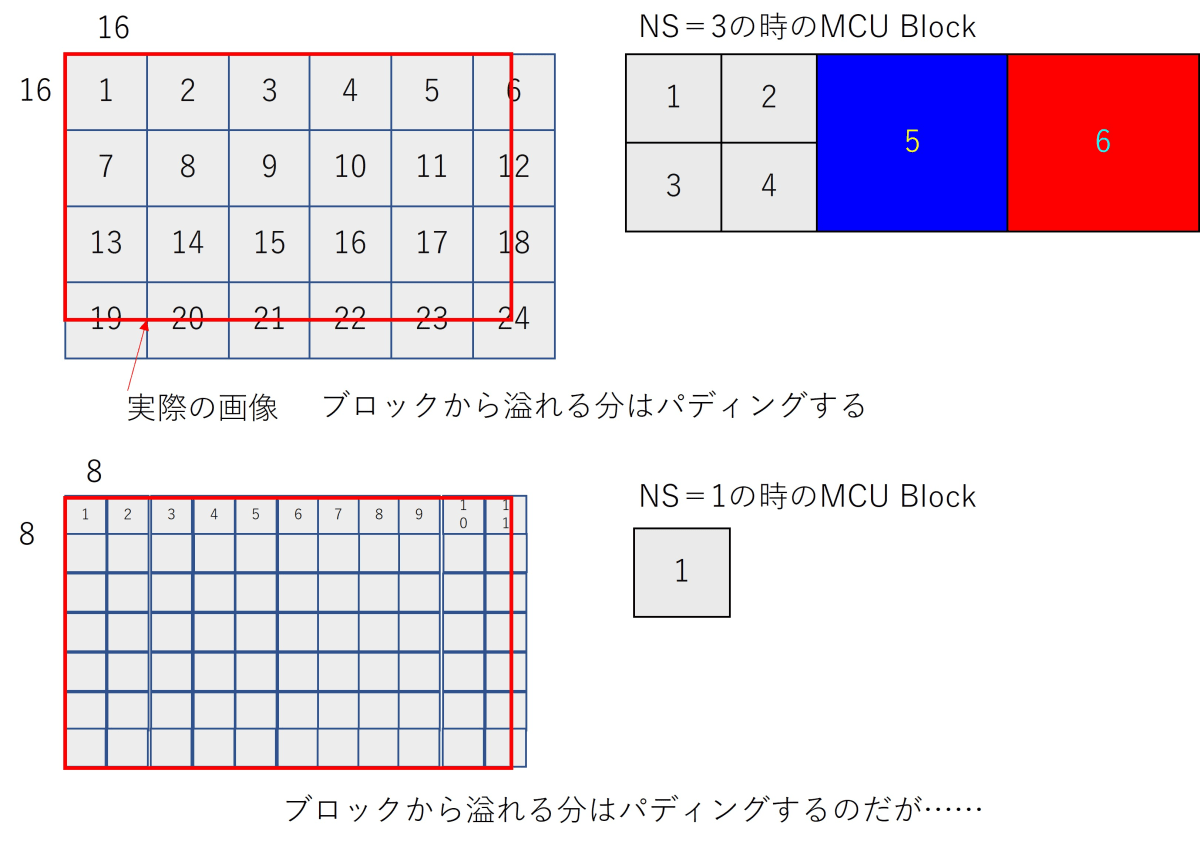
上記の例だとNs=3の時の輝度成分(Y)のブロックサイズは96 pixel x 64 pixel で、Ns=1の時は88 pixel x 56 pixel に変わる。つまり96x64で読み出すとデータが不足してエラーになる。スキャン順も変わるため、意識しないと画像が化ける。
ハフマン符号化
ハフマン符号化は、ベースラインJPEGとは異なりEOB1-14が実装されている(0x01-0x0e。EOBnは、どれだけブロックをスキップするかを書いている。
- EOB0 1
- EOB1 2,3
- EOB2 4..7
- EOB3 8..15
- EOB4 16..31
- EOB5 32..63
- EOB6 64..127
- EOB7 128..255
- EOB8 256..511
- EOB9 512..1 023
- EOB10 1 024..2 047
- EOB11 2 048..4 095
- EOB12 4 096..8 191
- EOB13 8 192..16 383
- EOB14 16 384..32 767
ベースラインは8x8のブロック単位で行うが、プログレッシブではブロックを飛ばすことが可能である。
これにより圧縮率を高くしている。しかし、次のsuccessive approximationのケースではEOBが出てきても後処理をおこなう必要がある。
AlとAh(successive approximation)
AlとAhのAはsuccessive approximation(逐次近似値)の略で、0-13までの値をとる(Baselineでは常に0)ある。これがまたややこしい。
Alは以下の計算で出てくる
デコードするときは逆になるようである。
とりあえず
successive approximationを使う場合1bitずつ加算しろとある(G.1.1.1.2)。そのbitは算術符号の部分をよめと。(Figure G.11)。意味不明なのでdpjpeg.cのコードから読み解くと、eob==0の場合、ハフマンテーブルかAC成分を読み出す(ここは通常と同じ)。ただし値は00-1fの間しか取らない。0の場合、EOBnを取得する。1の場合は1bitを読み出し、それから下位ビット分(0-15)だけ、successive approximationを行い、最後に値を挿入する。この値は、読み出した値が、0の場合は、-valを挿入し、1の場合は、valを挿入する。EOBの場合は、Seまで、successive approximationをおこなう。successive approximationは、Seになるまで繰り返し、1bit読み出し 1なら ZZ(l)に valを加算(負の場合は減算)をおこない 0ならスキップする。
これをフローチャートに起こしてみたら更に分からなくなったので、恐らくソースコードを読んだほうが早い。
これを先程の表で書いてみると
DCT後のデータ
| 100 | 20 | 4 | 0 | 0 | 0 | 0 | 0 |
| 10 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Ss=0,Se=0,Ah=0,Al=0 {100 実際にはDC成分は、前のブロックとの差分}
| 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Ss=1,Se=5,Ah=0,Al= 4 {1,0...}
| 100 | 16 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Ss=1,Se=5,Ah=4,Al=3 {0,1,0...}
| 100 | 16 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Ss=1,Se=5,Ah=3,Al=2 {1,0,0,0,1,0...}
| 100 | 20 | 4 | 0 | 0 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Ss=1,Se=5,Ah=2,Al=1 {0,1,1,0,1,1}
| 100 | 20 | 4 | 0 | 0 | 0 | 0 | 0 |
| 10 | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Ss=1,Se=5,Ah=1,Al=0 {0,0,0,0,1,0}
| 100 | 20 | 4 | 0 | 0 | 0 | 0 | 0 |
| 10 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Ss=6,Se=63,...
とデータ格納をすると言うお話らしい。そしてこの仕組みは必ずサポートしないといけない。
ちなみ、こういうインプリが存在する。
- Ss,Se,Ah,Al 0,0,0,1 Y,Cr,Cb DC成分のみ
- Ss,Se,Ah,Al 1,5,0,2 Cb
- Ss,Se,Ah,Al 1,5,0,2 Cr
- Ss,Se,Ah,Al 1,5,0,2 Y
- Ss,Se,Ah,Al 1,63,2,1 Cb successive approximation
- Ss,Se,Ah,Al 1,63,2,1 Cr successive approximation
- Ss,Se,Ah,Al 1,63,2,1 Y successive approximation
- Ss,Se,Ah,Al 0,0,1,0 Y,Cr,Cb DC成分のみ
- Ss,Se,Ah,Al 1,63,1,0 Cb successive approximation
- Ss,Se,Ah,Al 1,63,1,0 Cr successive approximation
- Ss,Se,Ah,Al 1,63,1,0 Y successive approximation
プログレッシブのメリットとデメリット
メリットは、重い画像を表示させるとき、大まかなイメージから表示出来る事。ブロックをまたいで0を格納できるEOBnと言う仕組みが存在することにより理論的な圧縮率がベースラインJPEGより高くなる点。
デメリットは、デコードのコストが重い(大まかなイメージを表示するためにはスキャンごとにIDCTをする必要がありその分時間がかかる)、それ以上のデメリットはメモリを食う点である。前のスキャンの情報をIDCTをかける前の状態で持つ必要がある。つまりMCU Unit Size x MCU_MAX_X x MCU_MAX_Y x 2byteの作業用メモリが最低必要。これをザックリ計算すると表示する画像の2倍から4倍のメモリが必要と言う計算になる。そのため16bitのPCではそもそもメモリが足りない。特にi8086系は、64KBのワーキングメモリで、1MBの画像データを展開していたのでプログレッシブにそもそも対応出来なかったのである(無理に対応すると表示に1分以上かかりそう)
ザックリイメージが欲しいだけならサムネイルを格納した方が良い気がする。
Discussion