こちらは、MIXI DEVELOPERS Advent Calendar 2025の4日目の記事になります
家族アルバム みてね(以下、みてね)でSREをしているyktakaha4と申します🐧
本記事では、みてねのEKSアップグレード運用について、今までの経緯も踏まえつつ最近の状況をお伝えします
参考になる部分があれば幸いです!
過去の取り組み
みてねでは、2021年よりAmazon EKSを利用しており、以降EKSクラスタの定期的なアップグレードに取り組んできました
障害発生時のユーザー影響を最小化するため、Blue/Green方式により半年ごとに2バージョンずつのアップグレードを基本方針としつつ、運用系機能を別クラスタに分離したり、TerraformやHelm Chart構成の最適化をおこなって、作業時間の短縮を進めてきました
地道な効率化の結果、昨年のMIXI DEVELOPERS Advent Calendar 2024にて弊チームのkohbisが執筆したEKSアップグレードRTAの時点では、1週間程度の工数でアップグレード対応を完了できるようになっていました
Karpenter導入による恩恵
一定の改善が達成できたため、その後EKSバージョンアップに関する優先度は相対的に下がっていましたが、今年になってコスト最適化の文脈からコンピューティングリソースのオートスケーラーであるKarpenterの導入を実施しました
元々みてねで利用していたCluster Autoscalerはコントロールプレーンと同一バージョンで利用することが原則推奨されているのに対して、KarpenterはKubernetesクラスタとの互換性が明示されており、Driftなどの機能を活用することでワーカーノードを安全に置換することができます
そうした背景を踏まえ、EKSクラスタアップグレードの効率化について再度検討することとなりました
EKS Auto Modeについて(未導入)
Amazon EKSにおいてクラスタを構成する際の選択肢のひとつとしてEKS Auto Modeがあります
EKS Auto Modeを有効化すると、従来ユーザーによる管理が必要だったEC2インスタンスやロードバランサーなどの各種リソースやEKSアドオンのバージョン指定がAWSによって管理されるため、運用コストの低減やアップデート頻度の増加によるセキュリティの向上が期待できます
KarpenterはEKS Auto Modeの一部としても提供されておりNodePool構成などは引き継いで利用できるため、既にKarpenterを導入している場合は移行コストという点でも一定のメリットがあります

https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/automode.html より引用
しかし、今回の検討ではEKS Auto Modeの採用は見送ることとしました
理由のひとつに、みてねでは過去のTerraformやHelm Chartの最適化によってリポジトリ内の一部設定ファイルを書き換えるだけでバージョンアップ可能になっていたため、EKS Auto Modeを導入した際の運用コスト削減は限定的になりそうでした
また、EKS Auto Modeでは管理対象となっているEC2インスタンスに対して追加の時間課金が発生します。他社様の事例でも数%のコスト増が見込まれるという試算もありました
Karpenterが未導入だった場合、スケーリングの挙動が最適化されることで前述したコスト増を上回る削減効果が得られる可能性もありますが、みてねでは既にKarpenterを単体で導入しており、そうした期待も難しい状況でした
今後のアップデートを注視しつつ、改めて検討できるとよいものと思います
2025年の取り組み
今年、EKSアップグレードに関連して改善できた部分をご紹介します
従来、Blue/Green方式でEKSアップグレードをおこなう際は、概ね以下の手順を踏んでいました
- 新バージョンとの互換性を確認する
- 新しいEKSクラスタを起動する
- 運用系クラスタに新しいEKSクラスタの接続設定を追加
- 運用系クラスタからArgo CD Applicationを適用
- 新しいEKSクラスタに切り替える
- 関係各所への周知
- ALBの加重ルーティングによりWebトラフィックを移行
- 新旧クラスタでワーカーを並行稼働し非同期処理を移行
- 後片付け
- 旧クラスタの削除
手順の詳細についてはアップグレードガイドを整備し、各フェーズで作成すべきPRや実行コマンドのサンプルを提供することで属人化の低減と作業効率の向上に努めていましたが、各作業には依存関係が存在するため、アップグレード対象のクラスタごとに複数のPRを作成し、順番に適用していく作業が必要です
PRの差分はいずれも設定値変更のような軽微な内容になっているものの、これ以上の作業時間短縮は難しい状況になっていました
そうした背景を踏まえ、今後はin-place方式をデフォルトの手順とするようにアップグレードポリシーを変更しました
AWSのベストプラクティスにおいても、まずはin-place方式でのアップグレードを検討し、必要に応じてBlue/Green方式を選択することが推奨されています
Karpenterの設計を鑑みても、一般的なユースケースではin-place方式を前提とすることでDriftなどの機能を最大限活用することができそうです
また、過去のアップグレード作業を振り返ってみると、EKS Cluster Insightsによって示される指摘事項の解消や、Changelogの確認、開発環境での動作検証といった複数のプロセスによって問題のほとんどは洗い出せているという実績もあったため、明確な理由がない限りはin-place方式を選択することとしました
in-place方式の場合の作業手順は以下になります
EKSクラスタの作成・削除が不要になったことで、必要なステップを大幅に削減することができました
- 新バージョンとの互換性を確認する
- EKSクラスタをアップグレードする
- EKSクラスタバージョンおよびアドオンバージョンの変更
- AMIの更新
アップグレード方式の変更にあたって留意すべき内容についても抜粋して紹介します
Kubernetesは公式でバージョンスキューが定められており、in-place方式でのアップグレードにおいてもクラスタ内のコンポーネントのバージョンが混在しても正常な動作を維持できます
Karpenterはコントロールプレーンと互換性のあるもののうち最新バージョンのワーカーノードを選択して起動する仕様になっています
前述したバージョンスキューに違反しない限り既存のノードは維持されますが、スケールアウトやスポットインスタンスの中断によって新規のノードが起動するタイミングでノードのバージョンが更新されていきます
みてねでは、アップグレードのタイミングでamiSelectorTermsを利用してその時利用できる最新のAMIバージョンを指定することでDriftを発生させ、一部のステートフルなノードを除いて即時でワーカーノードのアップグレードを実施しています
KarpenterはGracefulな中断についてはPodDisruptionBudgetを尊重してDriftを実施するため、ノードが一度に中断されてワークロードが過負荷にならないよう設定状態を見直しましょう
非同期系の処理については、ワークロードが安全に終了できるように karpenter.sh/do-not-disrupt アノテーションを付与したり、TerminationGracePeriodや expireAfter に長めの値を設定するのがお勧めです
更に細かなノードの中断制御が必要な場合は、NodePool Disruption Budgetsも活用できます
みてねでは開発者向けにSandbox環境という個人用の開発環境をDeploymentを使って提供しているのですが、これらが稼働するノードを日中帯にアップグレードするとダウンタイムが発生してしまい、運用上好ましくありません
NodePoolの spec.disruption を活用すると、業務時間帯にDriftが発生する変更を適用した後、利用者が少なくなった夜間にノードのアップグレードを発生させるといった挙動も実現可能です
設定イメージを以下に示します
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: sandbox
spec:
disruption:
budgets:
# Disruptionをおこなう場合、1台ずつ実施する
- nodes: "1"
# 平日9時~21時(JST)はEmpty以外を起因とするDisruptionを抑止する
- duration: 12h
nodes: "0"
reasons:
- Underutilized
- Drifted
schedule: 0 0 * * mon-fri
consolidationPolicy: WhenEmpty
EKSアップグレードとは別の文脈ですが、弊社ojima-hよっておこなわれたデプロイフローの見直しによって、検証環境への変更適用が効率化されたのも大きな改善となりました
PRに deploy/dev や deploy/stg などのラベルを適用するだけで検証環境に任意の差分を適用できるようになったため、従来環境ごとにPRを分けていたものをひとつにまとめることができるようになり、実装の見通しも良くなりました

https://team-blog.mitene.us/cd27948e2480 より引用
具体的な実現方法については以下の記事で詳しく紹介されています
得られた効果
アップグレードポリシーの変更とデプロイフローの見直しによる作業量の変化について図示します(かなり大雑把な説明のため、実際の作業内容はもう少し複雑です)
当初のBlue/Green方式においては、Terraform構成を管理しているリポジトリで、EKSクラスタの作成やトラフィックの切り替えといった作業内容にあわせてクラスタ種別・環境ごとにPRを作成し、実施のタイミングで都度マージしていました

Blue/Green方式のイメージ
in-place方式に変更したことで作業の手数が削減され関連PRも減少しましたが、クラスタ種別・環境ごとにPR作成するのは引き続き必要でした

in-place方式(デプロイフロー見直し前)のイメージ
アップグレード方式変更と並行して実施されたデプロイフローの見直しによって、環境ごとにPRを作成する必要がなくなり、クラスタ種別ごとに数種類のPRを作成するだけで済むようになりました
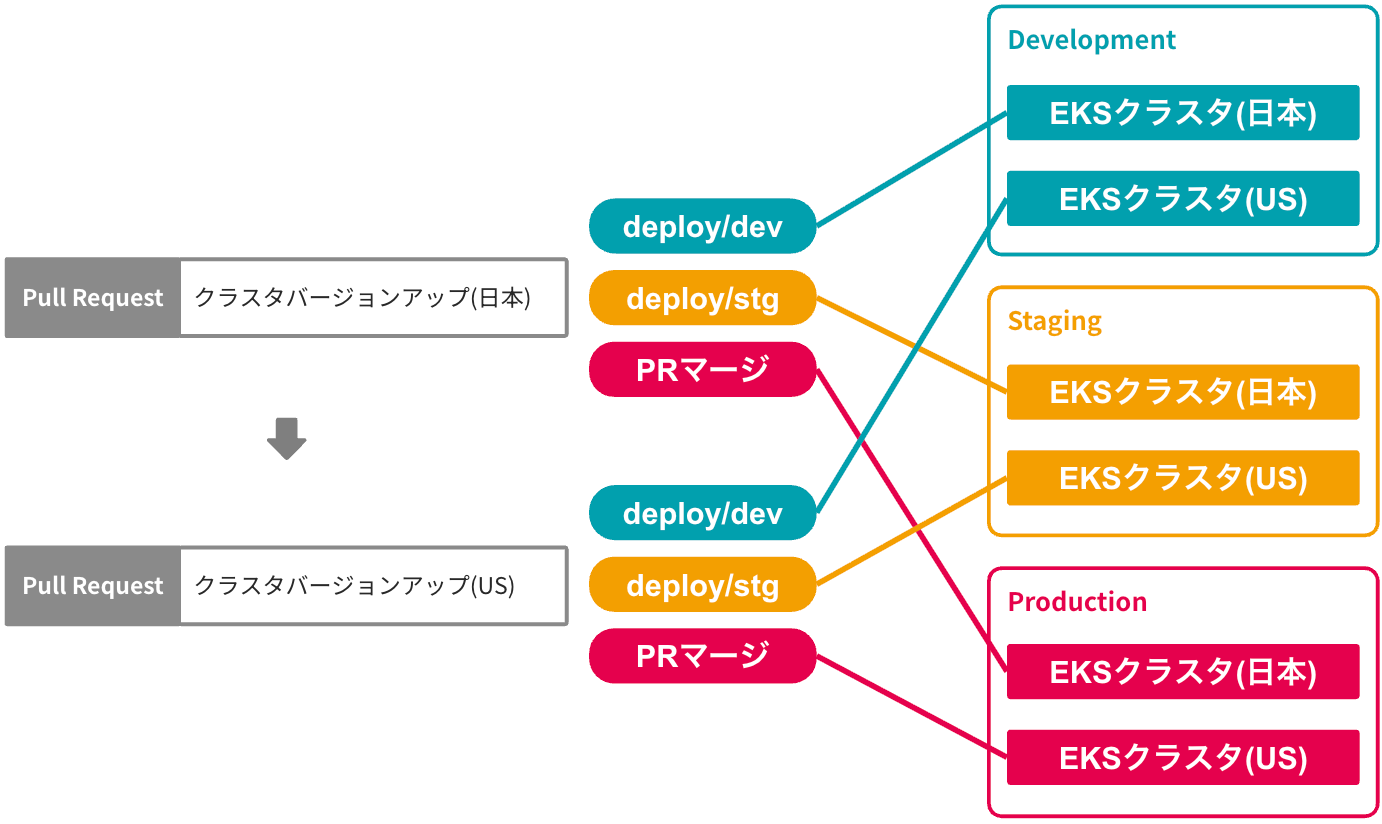
in-place方式(デプロイフロー見直し後)のイメージ
結果、現在は 個人のサイドタスクとして数日で対応できる程度の作業量 まで工数を圧縮することができています
環境適用後の動作確認などは引き続き必要になるものの、昨年末よりは改善の進んだ状態になったものと思います
また、in-place方式でのアップグレードへの最適化をおこなった副次的効果として、AMIなどのセキュリティアップデートの変更のハードルも下がりました
先月公開されたCVE-2025-31133, CVE-2025-52565, CVE-2025-52881についても、前述した amiSelectorTerms を最新化する数行の変更をマージするだけで、ワークロードへの影響を抑えつつ対応をおこなうことができました
来年末にはアップグレードのコストを無にできているといいですね ☺️
おわりに
MIXI DEVELOPERS Advent Calendar 2025では、MIXI GROUP の各社に所属するエンジニアが多様なアウトプットをおこなっています
他の記事もぜひご覧ください!

Discussion