BitNetから始める量子化入門
はじめに
BitNet、最近話題になっていますね。
そもそも量子化って何?という方もいると思うので、この記事は DeepLearning の量子化から入り、その上で BitNet の触りについて見ていこうと思います。色々とわかってないことがあり、誤読してそうなところはそう書いてるのでご了承ください。
図を作るのは面倒だったので、様々な偉大な先人様方の図やスライドを引用させていただきます。
量子化
DeepLearning における量子化
DeepLearning の学習・推論は基本 float32 で行います。これを int8 や Nbit に離散化することを量子化といいます。
計算に使う値は、モデルの重み、アクティベーション(ReLUとか通した後)、重みの勾配等があります。
学習時については一旦置いておいて、この記事では推論における量子化について焦点をあてます。推論時に量子化の対象となるのは重みとアクティベーションの値です。


バイナリニューラルネットとハードウェアの関係[4] p11,12 より引用
量子化のメリットとデメリット
DeepLearning の計算量の殆どが行列の積和演算が占めています。この計算に使われている float32 の値を in8 や Nbit に量子化すると、データを表現するのに必要な情報量が減ります。これによりメモリ消費量が少なくなるので以下のようなメリットがあります。
- メモリの削減
- 通信量の削減
- 消費電力減
- 推論速度の向上
注意しなければならないのが4つ目の推論速度の向上です。
そのまま動かしても基本的にはレイテンシは変わりません(※)。メモリ消費量が少なくなることによりバッチサイズが増えて スループットは向上 しますが、レイテンシは変わりません。
(※ と書いたのですが、CPU, GPUでも最適化処理を入れるとレイテンシは減りそうです。BitNet b1.58 では FasterTransformer というライブラリを用いて GPU 上でレイテンシを低減させています。すげ〜。)
レイテンシについては FPGA や ASIC で専用回路を作ると早くなる可能性があります。これについては後述します。
デメリットは、精度低下です。
基本的には量子化を行うと精度が下がります。数値をめちゃくちゃ近似して丸めてるのでそれはそうという感じです。(後述しますが)特に重みとアクティベーション両方を1bitと極端な量子化を行うと結構な精度低下を引き起こします。タスクにもよりますが int4, int8 なら結構精度を保てる印象があります。
量子化をどこで行うか
量子化はどこをどうどのように量子化するかでパターンが分けられます。
- 何を量子化するか
- 重み
- アクティベーション
- いつ量子化するか
- 学習後(PTQ: Post Training Quantization)
- 学習時(QAT: Quantization-Aware Training)
まず何を量子化するかです。重みだけ量子化したり、重みとアクティベーション両方を量子化したりします。さらに重みを何ビットにするか、アクティベーションを何ビットにするかでもバリエーションがあります。ちなみに BitNet b158 は重みは -1, 0, 1 の3値で、アクティベーションは 8bit です。
いつ量子化するかですが、これは2種類あります。
学習後に量子化する PTQ(Post Training Quantization)ですが、これは普通に学習したモデルを推論時に量子化する手法です。一応これでも一定程度(int8とか)なら精度出たりします(もちろんタスクによる)。
単に量子化するよりも学習時に量子化を意識した学習のほうが性能があがるよね、というのがQAT(Quantization-Aware Training)です。
QAT においては学習時にアクティベーションの段階で下図の Quantizer にかけてアクティベーションを量子化します。しかしこの Quantizer は微分不可能なので Backpropagation をするときに微分値に1を用いる STE(Straight Through Estimator)という手法を用います。
STE でやっていることは、Backpropagation するときに Quantizer を直線近似して、その微分が1なのでそれを利用していることになります。この近似の仕方でも様々なパターンがあります。

Ghoul et al. 2022 [6] Figure5
FPGA や ASIC についての高速化について
量子化の最終目標はここだと思います。
重み、アクティベーションを1bitまで極端な量子化をすると行列積が XNOR + bitcount で表され計算回路がとてもシンプルになります。

バイナリニューラルネットとハードウェアの関係[4] p49 より引用
これを用いて専用回路を組めば回路素子数・サイズがかなり小さくなり、計算が超効率化するので、推論速度も早くなり、消費電力量がかなり減ります。
ただし話はそう単純なものではありません。
- 精度について
- 精度は下がります。重みもアクティベーションも1bitにした XNOR-NET(一部スケーリング係数を扱っていますが)では AlexNet に比べ ImageNet の Top-5 認識精度が 80.2% -> 69.2% と下がっています。ただしこれはかなり古い情報なので最新の研究ではどうなってるか知りませんが、難しいタスクであることには変わりないと思います。
- モデル構造に制約がかかります。行列積以外の ASIC で処理できない処理が入ると CPU に計算をオフロードしないといけません。これが発生すると速度低下を引き起こしてしまいます。できれば計算を end2end に ASIC 上で行いたいですが、モデル構造がシンプルである必要があります。
- ASIC について
- 作るのにアホみたいにお金がかかります。しかもめちゃくちゃチップをすらないとペイしない。
- 上述したようにモデル構造に制約がかかります。
- FPGA について
- ここについてはあまり詳しくないのですが、本格運用に耐えられる FPGA ってそんなにあるのかな、というイメージがあります。ASIC の前の段階という印象があり、最終的には ASIC を目指すのかなという所感です。違ってたらすみません。
多分ハードウェアやコンパイラの人からすると他にも課題がたくさんあるかもしれません。でも、夢がある領域だとも思います。
BitNet, BitNet b1.58 について
それでは量子化の基礎知識について学んだ上で BitNet についての解説に入ります。
BitNet には重みを1bitにした BitNet[6]と、その後続で重みを3値(-1, 0, 1)にした BitNet b1.58 [8] があります。b1.58 は log 3_2 = 1.58 (ternary値のビット数)から来てるらしいです。へぇ。
BitNet
昨今の LLM には Transformer という機構が入っており、ここの計算量がモデルの計算量の大部分を占めます。この Transformer の中の Linear レイヤーを BitLiniar というものに差し替えたものが BitNet になります。
Transformer については調べればわかりやすい記事がいっぱいでてきますが、動画で解説されてるアリシア先生の Transformer 解説 [7] がわかりやすかったです。
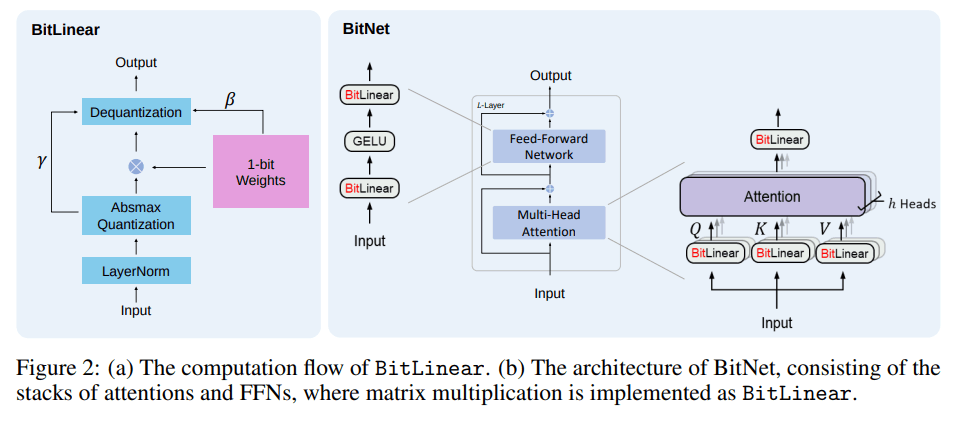
Wang et al. 2023 [6], Fig2
BitLinear では 重みは 1bit にアクティベーションは 8bit に量子化 (※) されています。
※ と思ったんですがここわかってないです。実装をみるとアクティベーションに関しては round 処理入ってないので、レンジは int8 ですが小数点以下が入っているので精度は float32 です。また、論文の式にも round 処理は書かれていません。
BitNet b158 では明確に論文に round 処理が書かれており、実装も round されています。BitNet ではアクティベーションに明確に量子化処理はいれてないのでしょうか。
アクティベーションを高精度(ex. 8bit)にしている理由は論文では以下のように書かれています。
- (量子化されていない)skip connection と layer normalization のコストはモデル全体に比べると小さい
- QKV の計算コストはモデルが大きくなるにつれて割合が小さくなる
- LLM ではサンプリングのため高制度出現確率を保持する必要がある。
ここもあまり理解できていません。2つめのQKVについて、Transformerの数が増えてモデルサイズが大きくなればQKVの計算も増えるよな、と思ったり3つめについてはLLMについて明るくないので知らないのですが、とりあえず今回はアクティベーションは高精度(ex. 8bit ?)でやっています。
ここらへん大事なところなのに誤読してるかもしれないのです。すみません。
BitLinear
BitLinear について見ていきます。
LayerNorm
fp32 の計算では重みの初期化(ex. Kaiming initialization, Xavier initialization)により出力の分散が1になり学習が安定します。
量子化でint8にするとこれが使えないので、アクティベーション前に LayerNorm を施します。重みと入力が互いに独立という条件下だと出力の分散が1に近似できます。
該当箇所を Readable (https://readable.jp/translate) で訳したものを参考に貼ります。

Absmax Quantization

活性化関数 ReLU の変わりに、最小値を引いて [
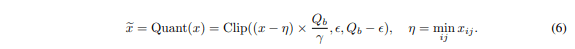
Dequantization
量子化をすると、値をスケールして離散化しているので分布が大きく変わってしまいます。
これだと元の学習されたモデルの分布から大きく変わってしまうので dequantize をして元の分布に戻してあげます。
この BitLinear の処理をまとめると以下のようになります。
他にも、並列化をするためにデバイス間で行列を分解したりしています。(詳細は論文読んでね!)
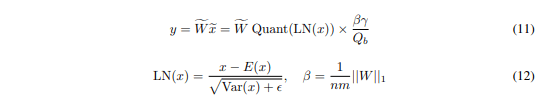
学習について
学習は QAT に該当し、STE を用いて量子化を考慮した学習を行っています。
学習時の勾配は高精度で行っており、1bitの重みの学習では学習率を大きくしたほうが良かったことが述べられています。
実験結果
色々実験してるのですが、おもしろかったものをピックアップします(実験設定の詳細は論文を参照ください)。
重み1bit の BitNet が Scaling Law に従っている
論文では重み1bitのBitNet と fp16 の BitNet (なんでfp32じゃないんだ)の比較が載せられており、重みを1bitにした BitNet が Scaling Low(モデルのサイズ、データセットサイズ、計算量、に従い loss がべき乗則に従って減少する)に従うと述べています(右図)。
これに関しては期待できる情報で、LLM で重み 1bit で Scaling Law を満たしている実験結果はインパクトあるのではないでしょうか(自分が知らないだけだったらすみません)
モデルサイズが大きくなるほど fp16 のモデルとの loss の差が小さくなっています。
更に論文では、BitNet は計算効率が良いので、モデルサイズで比較するのではなく消費電力量によるスケーリング効率を考えると fp16 よりも効率的であると述べています。
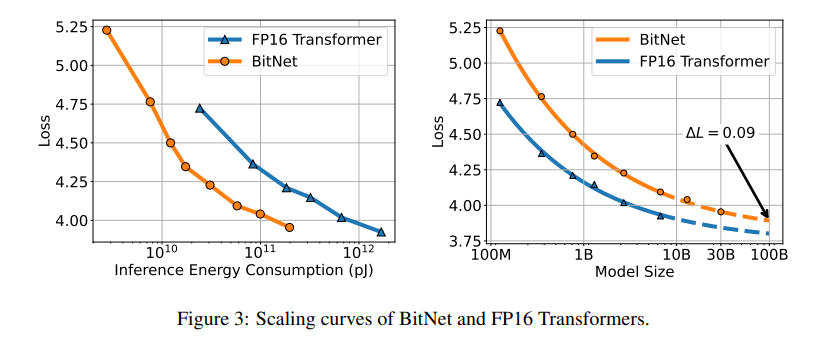
一応注意しないと行けないのが、論文中で消費電力について話されていますが、ここでの消費電力はあくまで計算で求めた理論値であり、実測値ではないです。現状そのまま動かしてもfloat16の場合と消費電力は(ほぼ?)変わらないと思います。こういうところは注意ね。
学習の安定さ
こっちも結構面白いと思います。fp16 のモデルに比べ、learning rate を大きくとっても学習が安定するという結果です。同じ設定で左図では fp16 のモデルは発散している一方 BitNet は収束しています。また、右図では learning rate を大きくとっても収束している上、learning rate が大きいほうが性能が高くなっています。
重み1bitの学習というと収束しなさそうで学習が難しそうという印象がありますが、逆に安定するのは結構うれしいことだと思います。ここらへんは LLM くらいデカイモデルだと量子化が正則化として効いてるとかあるのかな?知らんけど。

BitNet b1.58
(自分の認識では)日本で騒ぎのきっかけとなった論文です。
解説は様々な方が既に書かれてるのでここでは省きます。ありがたいね。
BitNet との違いは重みを1bitではなく3値(-1, 0, 1)でとっています。
(あとちゃんと論文中の式でも実装でも round をとっており INT8 にしていることが確認できます)

実験結果
こちらもおもしろかったものをピックアップします(実験設定の詳細は論文を参照ください)。
モデルサイズが大きくなると高精度のモデルに匹敵
Table2 でモデルサイズが3Bに達すると、fp16 の LLAMA に匹敵、ところどころ性能が超えているところがあります。ここらへんは前回の論文と同じ内容ですね。

Ma, Shuming, et al [2024], Table1, 2
レイテンシ、メモリ消費量、スループットの改善
個人的には前の論文と違って、ちゃんと実測値を測っていることが偉いと思いました。
私はレイテンシは基本的には早くならないと思っていたのですが、FasterTransformerというライブラリを用いることでレイテンシも1.5~4倍程度改善しています。
モデルサイズ、メモリ消費量、スループットは改善しそうですがレイテンシも改善するんですね。

Ma, Shuming, et al [2024], Fig2, 3
感想
BitNet がでたことで世界がすぐ変わるか、というとそうではないかもしれませんが、LLM で Scaling Law が効きそう、1bit-weight, 8bit-activation で十分性能がでる、モデルサイズを大きくすると高精度モデルに匹敵する性能がでる、学習がかなり安定している、あたりのことは結構嬉しいことだと思いました。今後もどんどん研究が進んでいくことに期待します。全部1bitでできるようになって爆速で動くASICとか出たら、なにか変わるかも。僕はNVIDIA株を持ってないので大いに歓迎です。
参考記事
量子化入門についてはここらへんの記事・解説動画がとても参考になります。ありがたさしかないです。
[1] Deep Learning研修(発展)】推論最適化のためのコンパクト化技術 第3回5「基礎:量子化」
[2] 深層モデルの高速化
[3] ニューラルネットワークの量子化についての最近の研究の進展と、その重要性
[4]
バイナリニューラルネットとハードウェアの関係
[5] ニューラルネットワークの量子化手法の紹介
[7] 【深層学習】Transformer - Multi-Head Attentionを理解してやろうじゃないの【ディープラーニングの世界vol.28】
[9] 【論文丁寧解説】BitNet b1.58とは一体何者なのか
参考文献
[6] Wang, Hongyu, et al. "Bitnet: Scaling 1-bit transformers for large language models." arXiv preprint arXiv:2310.11453 (2023).
[8] Ma, Shuming, et al. "The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits." arXiv preprint arXiv:2402.17764 (2024).
Discussion