【AWS認定(SAP-C02)ノート】信頼性、耐障害性、事業継続性
はじめに
本記事は、AWS Certified Solutions Architect - Professional の下記の分野とタスクステートメントに関連するAWSサービスの特徴やポイントのまとめです
- 第 1 分野: 複雑な組織に対応するソリューションの設計
- タスクステートメント 3: 信頼性と耐障害性に優れたアーキテクチャを設計する。
- 第 2 分野: 新しいソリューションのための設計
- タスクステートメント 2: 事業継続性を確保するソリューションを設計する。
対象知識
- 目標復旧時間 (RTO) と目標復旧時点 (RPO)
- 災害対策戦略 (AWS Elastic Disaster Recovery [CloudEndure Disaster Recovery]、
パイロットライト、ウォームスタンバイ、マルチサイトの使用など) - データのバックアップと復元
- AWS のグローバルインフラストラクチャ
- AWS ネットワークの概念 (Route 53、ルーティングメソッドなど)
災害対策
RDS Proxy:データベースへのリクエスト改善
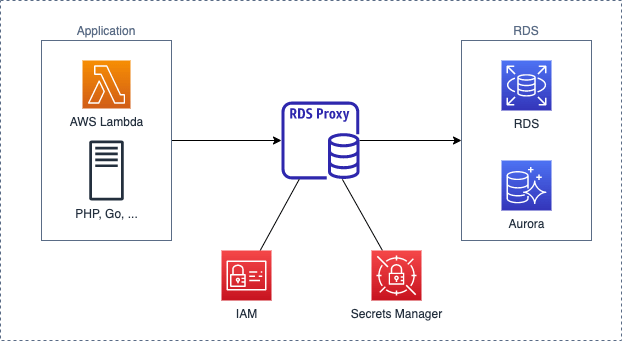
データベース接続プールを確立し、このプール内の接続を再利用する
この方法により、毎回新しいデータベース接続を開くことによるメモリと CPU のオーバーヘッドを回避する
RDS Proxyの作成
- Aurora、RDS(MySQL、PostgreSQL)データベースに関連付ける
- RDS Proxyのエンドポイントが生成される
- アプリケーションからRDS Proxyのエンドポイントにリクエストを実行
セキュリティ
- Secrets Managerが必要
- データベースのユーザー名、パスワード用
- セキュリティグループ
- アプリケーションからリクエスト送信を許可
- DB本体のSG:RDS Proxyからリクエスト送信を許可
Aurora Data API
- Aurora サーバレスはRDS Proxyをサポートしていないので、Data APIを使用
- 必要とするIAMポリシー
- Secrets Managerからシークレットの取得
-
rds-data:ExecuteStatementなど、RDSDataServiceのAPIアクションへの権限
ARN によって識別される DB クラスターの Data API にアクセスするためにユーザーが最低限必要なアクセス許可の例
このポリシーには、Secrets Manager にアクセスし、ユーザーの DB インスタンスの承認を取得するために必要なアクセス許可が含まれている
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SecretsManagerDbCredentialsAccess",
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": "arn:aws:secretsmanager:*:*:secret:rds-db-credentials/*"
},
{
"Sid": "RDSDataServiceAccess",
"Effect": "Allow",
"Action": [
"rds-data:BatchExecuteStatement",
"rds-data:BeginTransaction",
"rds-data:CommitTransaction",
"rds-data:ExecuteStatement",
"rds-data:RollbackTransaction"
],
"Resource": "arn:aws:rds:us-east-2:111122223333:cluster:prod"
}
]
}
EC2 Auto Scaling
アプリケーションの負荷を処理するために適切な数の Amazon EC2 インスタンスを利用できるようにEC2インスタンスを自動で増減する
スケーリングポリシー
スケジュールに基づくスケーリング
希望する最小の容量、最大の容量の指定を、特定時間に変更できる
- 時間設定
- 1回限り
- 繰り返し
- Cron
- 有効なケース
- 需要の幅が時間帯によって変化する場合
- あらかじめ予測できるインスタンス数を指定する場合
シンプル (簡易) スケーリングポリシー
CloudWatchアラームを指定して、追加、削除するポリシー
- クールダウン:スケールアウト/スケールインの後、クールダウンに指定した秒数が経過するまでは、次のスケールアクションは行われない
ステップスケーリングポリシー
1つのCloudWatchアラームをトリガーにして、段階的にスケールアウト/スケールインを設定できる
- ウォームアップ
- 無駄なインスタンスが起動することを防ぐ
- 前回のスケールアウトから指定の秒数が経過していなくても必要なインスタンスが起動する
ターゲット追跡スケーリングポリシー
ターゲット値を決めるだけで、スケーリングに必要なCloudWatchアラームはAWSが自動作成する
- スケールアウト:短い時間で起動するようにアラームがトリガーされる
- スケールイン:ゆっくり時間をかけて行われる
予測スケーリングポリシー
過去のメトリクス履歴を元に機械学習を使って予測し、必要な時間になる前にはAuto Scaling グループ内のEC2インスタンスの数を増やす
- 履歴データ
- 最低24時間分のデータが必要
- 新たな履歴に対して24時間ごとに再評価が実行され、次の48時間の予測が作成される
SQSに基づくスケーリング
Amazon SQSキュー内のシステムロードの変化に応じて Auto Scaling グループをスケーリングする
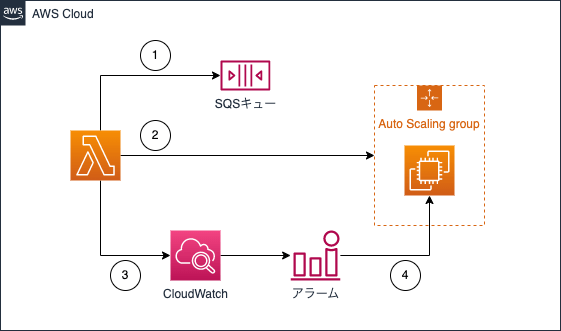
処理
- キューで待機しているメッセージ数を取得する(
ApproximateNumberOfMessages) - Auto Scalingグループから
InService状態のインスタンス数を取得する - CloudWatch の
PutMetricData APIで送信する - Auto Scalingグループのスケーリングポリシーによって、
PutMetricDataされたメトリクスのしきい値アラームに応じたスケールアウト/スケールインアクションが実行される
ファンアウト (fanout):扇形に広がる

- エンドユーザーのリクエストはアプリケーション (ALB + EC2) からSNSトピックへパブリッシュされる
- メッセージは複数のSQSキューへサブスクライブされる
- 各SQSキューをポーリングしているEC2インスタンスがメッセージを受信し、それぞれ並列で処理する
ライフサイクルフック
- スケールアウト時:ソフトウェアのデプロイを完全に完了したことを確認してから
InServiceになる - スケールイン時:必要なデータのコピーを完了してから
Terminatingになる -
Pending:Wait:スケールアウトではInServiceになる前、スケールインではTerminatingになる前に待機状態にする- ハートビートタイムアウト:
Pending:Wait待機状態の最大秒数- この秒数が経過すると、デフォルトの結果に基づいて処理される
-
ABANDON:インスタンスがターミネートされる -
CONTINUE:スケールアウトではインスタンスがInServiceになり、スケールインではインスタンスがターミネートされる
- ハートビートタイムアウト:
Amazon Route53
パブリックまたはプライベートなホストゾーンやリゾルバーを提供するDNSサービス
- ドメインの購入、管理可能
- エッジロケーションを利用して展開
Route53 ヘルスチェック
IPアドレスかドメインとポートを指定して、接続テストを実行
フェイルオーバールーティングポリシー

プライマリリージョンのヘルスチェックが失敗した場合、セカンダリリージョンへフェイルオーバーされる
位置情報ルーティングポリシー
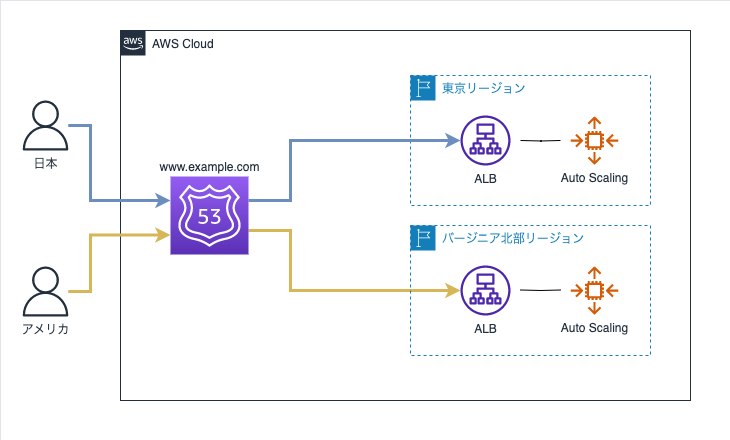
ユーザーの地理的場所、つまり DNS クエリの送信元の場所に基づいて、トラフィックを処理するリソースを選択できる
例えば、日本からのすべてのクエリを東京の ELB ロードバランサーにルーティングしなければならない場合に使用
- レコードの決定条件:Route53にあらかじめ用意されている大陸、国、アメリカの州から選択
レイテンシールーティングポリシー

複数のリージョンでアプリケーションがホストされている場合、どちらにアクセスしてもいいかネットワークレイテンシーが最も低いリージョンのレコードを返すことでネットワークパフォーマンスを向上させたい場合に使用
AWS Service Quotas
- 調整可能な制限値と使用量が、現在のAWSアカウントでどうなっているかを確認できる
- クォータの引き上げリクエストが実行できる
クォータモニタ (AWS Limit Monitor)
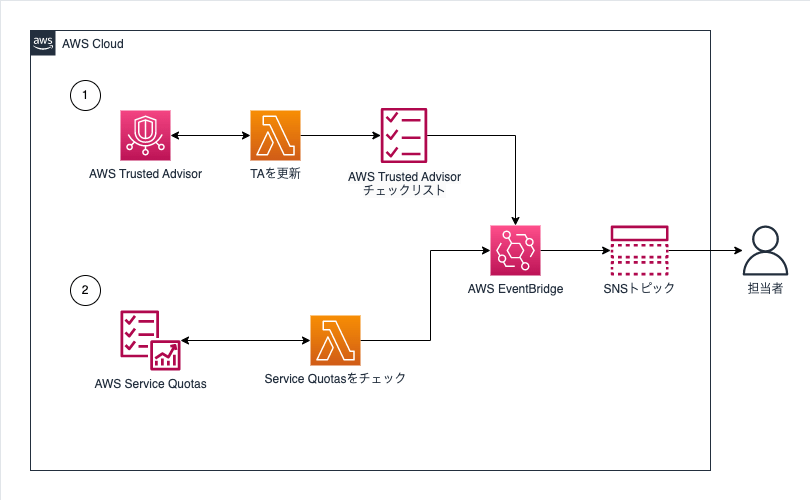
- サービス使用量が制限に近づいているかのモニタリングを自動化するソリューション実装
- CloudFormationテンプレートが用意されているので、素早く構築して運用できる
1. Trusted Advisor がチェックする制限値
Trusted Advisorチェックリストを更新するLambda関数と、チェックリスト更新を検知するEventBridgeルールによってSNSトピックから担当者へ通知
2. Trusted Advisor がチェックしない制限値
Service QuotasをチェックするLambda関数を用意して情報を取集し、制限値に近づいている場合は、EventBridgeイベントバスへ送信し、SNSトピックから担当者へ通知
Discussion