2分で決まる:Serena vs Cipher 思想とアーキテクチャ——CLIオンデマンドか常駐メモリか
はじめに
AIによるコーディング支援が広がる一方で、課題はいつも「文脈」です。
必要なファイルに届かない、会話が切り替わると前提が消える——そんな齟齬をどう埋めるか。
本記事は、そのボトルネックを解く 2 つのOSS、Serena と Cipher を比較します。
- Serena:CLI 実行時に必要な文脈だけを生成。軽く、はやい。
- Cipher:常駐サーバ+メモリで文脈を保持。IDE連携が強く、継続作業に強い。
結論はシンプルです。個人×CLI中心なら Serena、IDE中心/複数人/大規模なら Cipher。
以降は、この判断を迷いなく下せるように、思想・アーキテクチャ・最短導入・運用のコツを実戦目線で整理します。
1. はじめに:AIはプロジェクトの「文脈」をどこまで掴めるか?
AI コーディング支援の弱点は、しばしば文脈不足にあります。
「関係のないファイルに手を入れてしまう」「会話が変わると前提を忘れる」という経験があるはずです。
この壁を崩す鍵が MCP(Model Context Protocol) と、その上で動く OSS ツール群。
本シリーズでは、注目度の高い Serena と Cipher を取り上げ、実務の観点で比較します。
- 前編:思想とアーキテクチャ
- 中編:機能比較・導入手順
- 後編:開発スタイル別の選び方
まずは「なぜ設計が違うのか」「どこが体験の差になるのか」を掴みます。
2. 解決策となる2つのOSS:「Serena」と「Cipher」
-
Serena
CLI を起点に、コマンド実行のたび 必要最小限の文脈 を集めて LLM に渡します。
常駐プロセスは不要。軽く試せて、動きも読みやすい。個人や小さな案件と相性が良い。 -
Cipher
ローカルサーバとして常駐。メモリレイヤーに文脈を蓄え、IDE からいつでも引き出せます。
連携に強く、会話をまたいでも理解が深まる。チーム開発や大規模コードで効きます。
目的は同じでも、**「文脈をいつ作り、どれだけ保持するか」**の考え方が対照的です。
3. 最大の違いはアーキテクチャ:CLIツール vs ローカルサーバ
3.1 概観
-
Serena(CLI型)
- 実行時だけコードをスキャン → 文脈生成 → LLM へ
- 常駐なし。導入が速く、PC負荷も最小。
-
Cipher(常駐サーバ型)
- IDE から常時接続 → メモリレイヤーで文脈を保持・検索・共有 → LLM へ
- 連携が強力。会話を跨いだ再応答が速い。
3.2 要点の早見表
| 観点 | Serena | Cipher |
|---|---|---|
| 形態 | CLIツール | ローカルサーバ |
| 文脈 | 都度生成 | 持続保持(メモリ) |
| 連携 | ターミナル中心 | IDE/ツール横断 |
| 導入 | 非常に手軽 | やや手順あり |
| リソース | 実行時のみ使用 | 常駐で一定使用 |
詳細な機能・導入は中編で扱います。
3.3 図で見る動き
Serena(CLIオンデマンド)
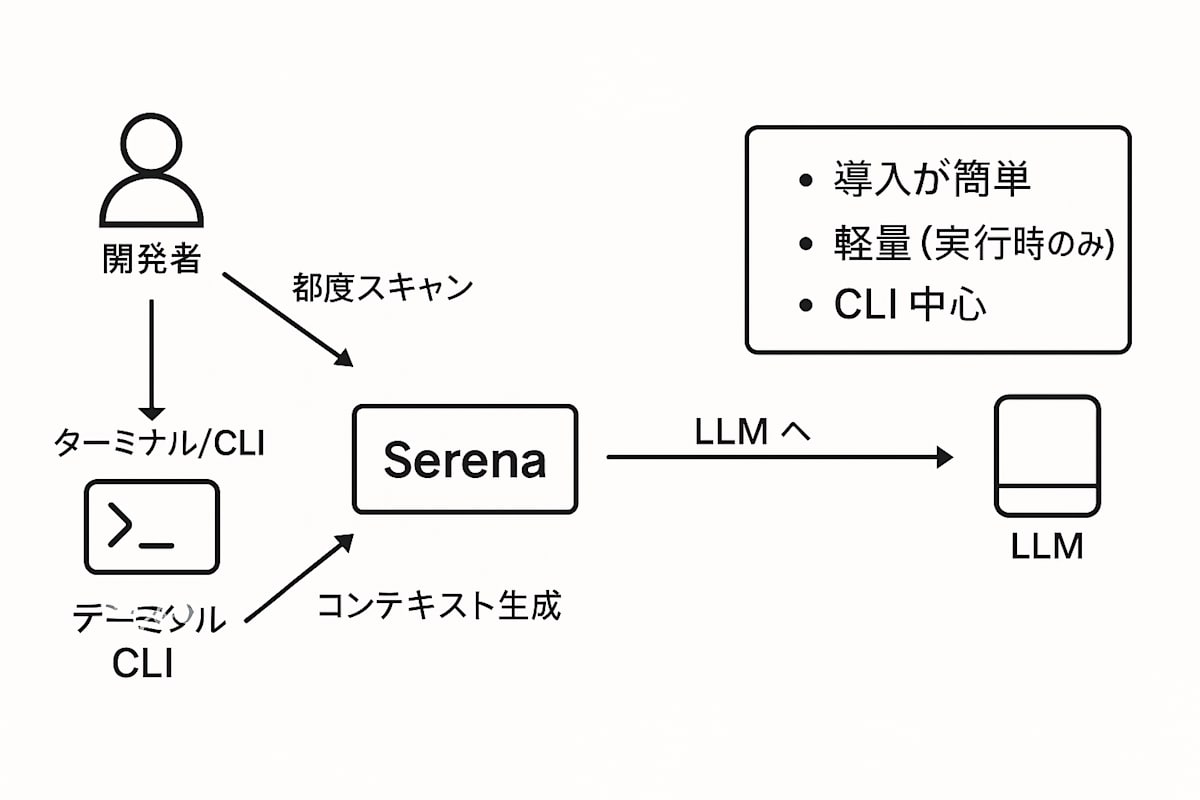
開発者 → ターミナル/CLI → Serena(都度スキャン/コンテキスト生成)→ LLM。要点:導入が簡単/軽量/CLI中心。
Cipher(常駐+メモリレイヤー)
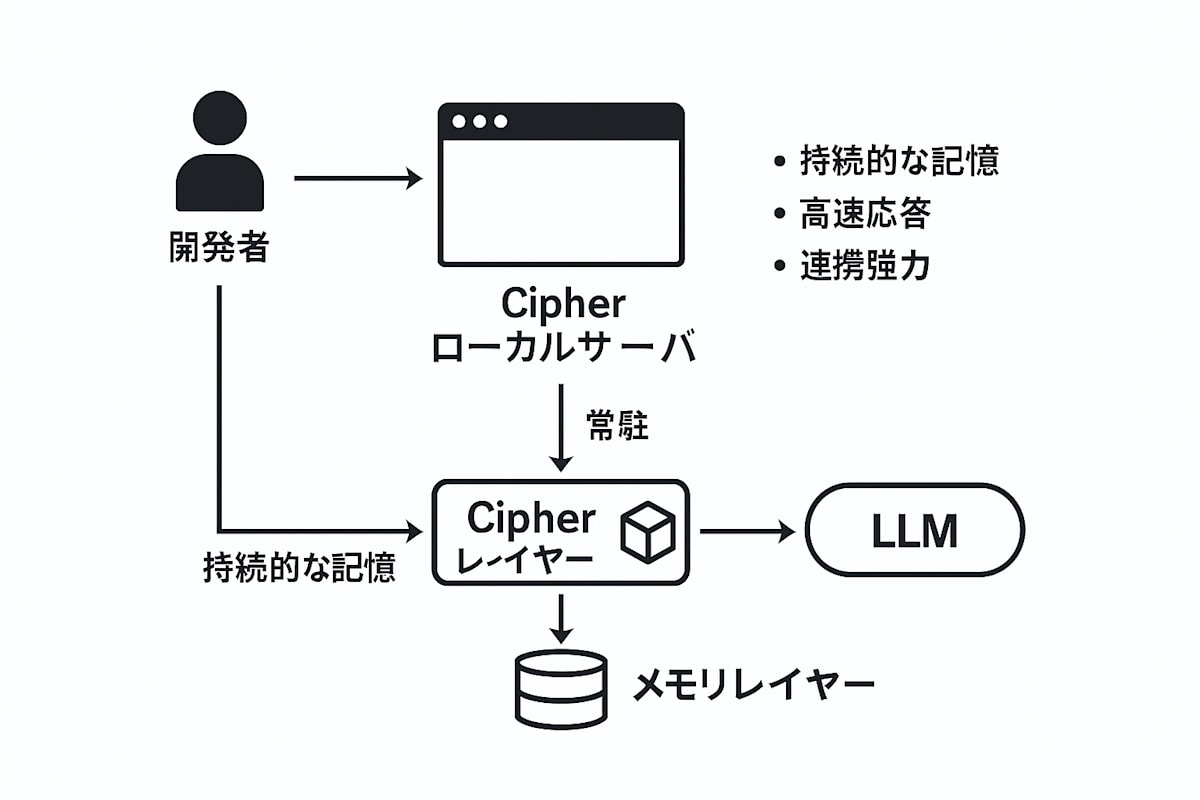
IDE → Cipher ローカルサーバ → メモリレイヤー → LLM。要点:持続的な記憶/高速応答/連携強力。
4. 一目でわかる機能比較表
| 観点 | Serena | Cipher |
|---|---|---|
| 形態 | CLIツール | ローカル常駐サーバ |
| 文脈 | 都度生成(オンデマンド) | 持続保持(メモリレイヤー) |
| 連携 | ターミナル中心 | IDE横断(VS Code/Cursor 等) |
| 導入 | 軽い | やや手順 |
| 応答(2回目以降) | 再生成あり | 速い(保持済み) |
| リソース | 実行時のみ | 常駐で一定使用 |
| チーム共有 | 手動共有中心 | メモリ共有しやすい |
| スケール | 小〜中規模に好相性 | 中〜大規模に強い |
| 典型ユースケース | 個人/短期/CLI派 | IDE派/チーム/長期運用 |
迷ったら:軽く試す:Serena → 継続運用:Cipher。
5. 「Serena」のメリット・デメリット
5.1 メリット
- 導入が速い:依存が少なく、まず触れる。
- 軽量:バックグラウンド常駐なし。負荷が読める。
- 文脈が見えやすい:オンデマンド抽出で挙動が透明。
- CLIワークフローと親和:ターミナル駆動の個人開発に合う。
5.2 デメリット
- 実行オーバーヘッド:大規模リポジトリは待ちが出やすい。
- IDE連携は控えめ:ターミナルからの利用が主。
- 連続作業で再形成:会話が変わると文脈を作り直す場面がある。
5.3 最短導入(例)
実行環境は公式手順に合わせて調整してください。以下は最小の流れ。
# 例:uv を使う場合(公式の案内に準拠)
# ⚠️ セキュリティ注意:実行前にスクリプト内容を確認することを推奨
curl -LsSf https://astral.sh/uv/install.sh | sh
# Serena を取得
git clone https://github.com/oraios/serena.git
cd serena
# 設定テンプレートを準備
cp project.template.yml my-project.yml
# ↳ 言語やプロジェクトルートを指定
cp serena_config.template.yml serena_config.yml
# ↳ 上記 my-project.yml を登録
大規模は初回が重くなりがち。事前に index すると体感が変わります。
uvx --from git+https://github.com/oraios/serena serena project index
MCP クライアント設定(例:Claude Desktop)
{
"mcpServers": {
"serena": {
"command": "uv",
"args": ["run", "--directory", "/path/to/your/serena", "serena-mcp-server"]
}
}
}
※ /path/to/your/serena は実際のクローン先パスに置き換えてください(例:/home/user/tools/serena)。
設定が失敗する場合のトラブルシューティング:
- パスが正しいか確認:
ls -la /home/user/tools/serena - uvコマンドが利用可能か確認:
uv --version - MCPサーバが起動するか確認:
uv run --directory /home/user/tools/serena serena-mcp-server --help
5.4 よくあるつまずき
-
初回解析が長い:大きいリポジトリは待つ。最小ディレクトリから試す。
- 解決策:
uvx --from git+https://github.com/oraios/serena serena project index --directory ./srcのように範囲を限定
- 解決策:
-
言語サーバ依存:対象言語の LSP の導入状況を確認。
- 解決策:言語別にLSPをインストール(例:TypeScript なら
npm install -g typescript-language-server)
- 解決策:言語別にLSPをインストール(例:TypeScript なら
-
無駄トークン:質問を具体化(ファイル/関数名を明示)→無駄を削減。
- 解決策:「
UserService.jsのauthenticateメソッドにログイン履歴機能を追加」のように具体化
- 解決策:「
Serenaのコツ(プロンプト例)
良い例:
`UserService.js` の `authenticate` メソッドに、ログイン失敗3回でアカウントロック機能を追加。
既存のバリデーション処理は保持し、新たに `failureCount` と `lockedUntil` フィールドを使用。
悪い例:
ログイン機能を改善してください。
コツ:
- "1タスク=1プロンプト"。範囲を絞る。
- ファイル/シンボル名を入れる。
- 変更の狙い(目的・制約)を先に言う。
6. 「Cipher」のメリット・デメリット
6.1 メリット
- 持続的な記憶:会話を跨いでも理解が深まる。
- IDE連携が強い:VS Code/Cursor から透過利用。
- 応答が速い:二回目以降の質問で効く。
- チーム運用しやすい:メモリ共有、文脈の再利用。
6.2 デメリット
- 常駐プロセス:メモリ/CPU を常時消費。
- 初期設定:環境変数や埋め込み設定など、最初に少し手数。
- 設計の理解が必要:メモリ設計(保存/検索の粒度)に慣れが要る。
6.3 最短導入(例)
# グローバル導入
npm install -g @byterover/cipher
# 対話/サーバ/MCP の各モード
cipher # 対話
cipher --mode api # APIサーバ
cipher --mode mcp # MCPサーバ
# Cipherの動作確認
cipher --mode api &
# プロセス確認
ps aux | grep cipher
# ヘルスチェック(タイムアウト付き)
curl -m 10 http://localhost:3000/health
6.4 よくあるつまずき
-
.env の鍵漏れ:必ず .env を .gitignore。共有は Vault 系で。
- 解決策:API キーは環境変数で管理(
export OPENAI_API_KEY=your_key)、チーム共有には AWS Secrets Manager や HashiCorp Vault を使用
- 解決策:API キーは環境変数で管理(
-
ポート競合:他常駐ツールと重なる場合はポートを明示。
- 解決策:
cipher --mode api --port 3001のようにポート指定
- 解決策:
-
初回インデックス時間:大規模リポジトリは待つ。最初は小さく。
- 解決策:
cipher --mode index --path ./src/componentsのように範囲を限定
- 解決策:
Cipherのコツ(メモリ活用例)
メモリレイヤーの仕組み:
Cipherは会話の文脈、コード理解、ユーザー設定を永続化したメモリ空間に保存し、
後続の質問で即座に参照できるようにしています。
良いメモリ管理例:
- 記憶化する単位(課題/変更理由/インターフェース)を決める
- "学習ログ"を残すと、後続の応答が安定
- チームでは共有用メモリの命名規約を作る(例:
feature/<ticket>、bug/<id>)
メモリ設定の具体例:
{
"memory": {
"project_context": "Next.js ecommerce app",
"coding_style": "TypeScript strict mode, functional components",
"test_framework": "Jest + React Testing Library"
}
}
付録:導入の順番(最短ルート)
- Serena を個人で試す(CLI/小粒タスク)。
- 継続運用や IDE 中心が見えたら Cipher を導入。
- チーム共有が増えたら、メモリ運用のルール化(命名・保存粒度・削除基準)。
7. どっちを選ぶ?判断チェックリスト
チェック(当てはまる方を選ぶ)
- CLI中心で動くことが多い
- 導入は最短がいい/軽く試したい
- 小〜中規模の個人案件が多い
- 実行時だけ動けばよい(常駐は避けたい)
→ Serena
- IDE(VS Code/Cursor)から離れたくない
- 会話をまたいで文脈を残したい
- 複数人で文脈を共有したい
- 中〜大規模コードで再応答の速さが欲しい
→ Cipher
7.1 早見表(短文のみ)
| 条件 | 推奨 |
|---|---|
| 個人 × CLI中心 | Serena |
| IDE中心 | Cipher |
| 複数人で共同開発 | Cipher |
| 大規模コード | Cipher |
| 常駐を避けたい | Serena |
| まずは軽く試したい | Serena |
7.2 図(選択フローチャート)
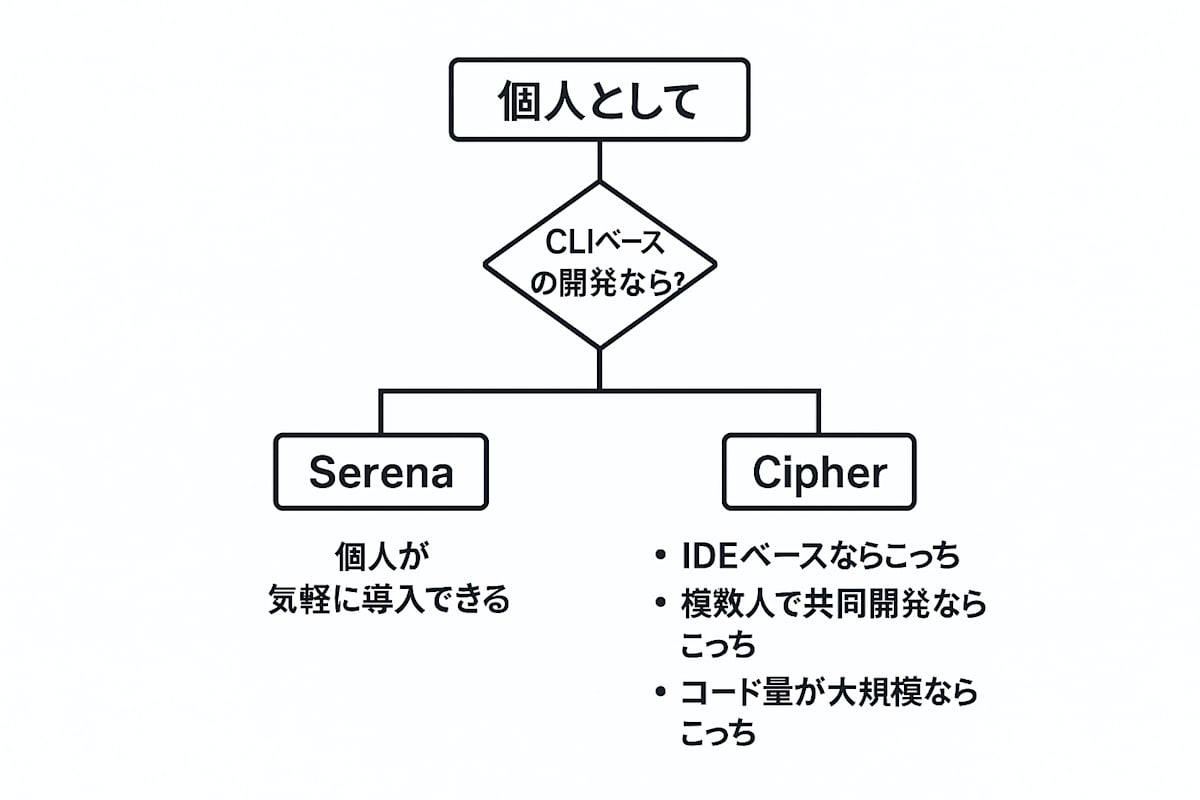
8. 段階導入のすすめ(最小コストで拡張)
Phase 1:個人で試す(Serena)
- 小粒タスクで効果を確認(関数修正、ユニット追加、軽微なリファクタ)。
- プロンプトは具体化(ファイル名/シンボル名/目的)。
- 初回解析が重い場合は対象ディレクトリを絞る。
Phase 2:IDE中心に移行(Cipher)
- IDEから常駐サーバに接続。メモリで再応答を高速化。
- 「何を覚えさせるか」を決める(仕様、意図、制約、IF/型、既知不具合)。
Phase 3:チーム運用に拡張(Cipher)
- 共有メモリの命名規約:
feature/<ticket>、bug/<id>など。 - 保存粒度:1タスク=1メモ。重複は避ける。
- 破棄ポリシー:期限・変更イベントで整理(肥大化防止)。
-
セキュリティ:鍵は Vault / Secrets、
.envは.gitignore。
Phase 4:計測と改善
- 時間:初回/2回目の応答時間、タスク完了リードタイム。
- 品質:差分のレビューヒット率、手戻り件数。
- プロンプト:テンプレの AB テスト(指示の粒度・順序)。
うまくいかないときは 前のフェーズに戻る。
例:Cipher で運用が重い → Serena のスポット活用に寄せる。
9. まとめと次アクション
-
結論の再掲
- 個人×CLI中心 → Serena。軽く、速く、入りやすい。
- IDE中心/複数人/大規模 → Cipher。記憶を活かし、速く回す。
-
次にやること
- 既存タスクの中から 10〜30分の小粒 を選ぶ。
- Serena で試す(オンデマンド文脈の手触りを確認)。
- IDE 中心なら Cipher を導入。チームは命名と粒度を先に決める。
- 応答時間・手戻りを定点観測。テンプレートを更新。
-
公式リソース
- Serena (GitHub) - CLI型AIコーディング支援ツール
- Cipher (GitHub) - 常駐型AIコーディング支援ツール
おわりに
文脈は“その場しのぎ”ではなく“資産”にする。
その設計が、日々の開発体験を左右します。
- まずは小さく:個人タスクで Serena を試す。オンデマンド文脈の手触りを確認。
- 必要に応じて拡張:IDE中心・継続運用・チーム共有が見えたら Cipher へ。
- 運用を回す:何を覚えさせ、いつ破棄するか。命名・粒度・鍵管理をルール化。
- 測って改善:初回/再応答時間、手戻り、レビュー指摘。数字で見ると効きます。
最後にもう一度。個人×CLIは Serena。IDE/複数人/大規模は Cipher。
小さく始めて、必要になったら広げる。これが最速最短の導入ルートです。
Discussion