3秒まとめ
- GoのパフォーマンスはNestJS(TypeScript)の2倍以上!?
- GraphQLのエコシステムはGo, TSともに充実
- GitHub Copilotで、GoのAcceptance Rateが40%を超える体験をした
GraphQL全盛の時代に、どの言語を使って開発すべきか
2015年にFacebookにより公開されたGraphQL。日本でもYahooやメルカリなどバックエンドをマイクロサービス化している多くの企業で採用され、近年はフロントエンド開発者にとって魔法の弾丸のように扱われることも多くなりました。
メルカリShopがGraphQL Client Architecture Recommendation社外版を公開していることからもわかる通り、GraphQLの利用に関する知見はかなり蓄積されてきています。
上記Recommendationによれば、BackendはGoでBackendエンジニアが運用することが推奨されています。確かに、メルカリのような大きな組織、大きなシステム、多くのマイクロサービスで構成されている環境では、おそらく推奨の通りにするのが正しいでしょう。
一方で、小さな組織、限られたエンジニアリソースを活かそうとすると、TypeScriptによるBackend開発も選択肢に上がってきます。GraphQLのエコシステムが一定以上整っていて、フロントとある程度リソースを共有できるうえ、エンジニアの採用難易度もGoほど高くはありません。
TypeScriptとGoによるGraphQL Serverを比較する際に、気になるのは2つの速さです。
1つ目は、レスポンスの速さ。2つ目は開発の速さです。
単純に考えればGoはTier2, TypeScriptはTier3の言語ですから、レスポンスの速さはGoに分があると考えられます。競技プログラミングの話はさておき、実務に強く影響が出るほどの差があるかは気になるところです。
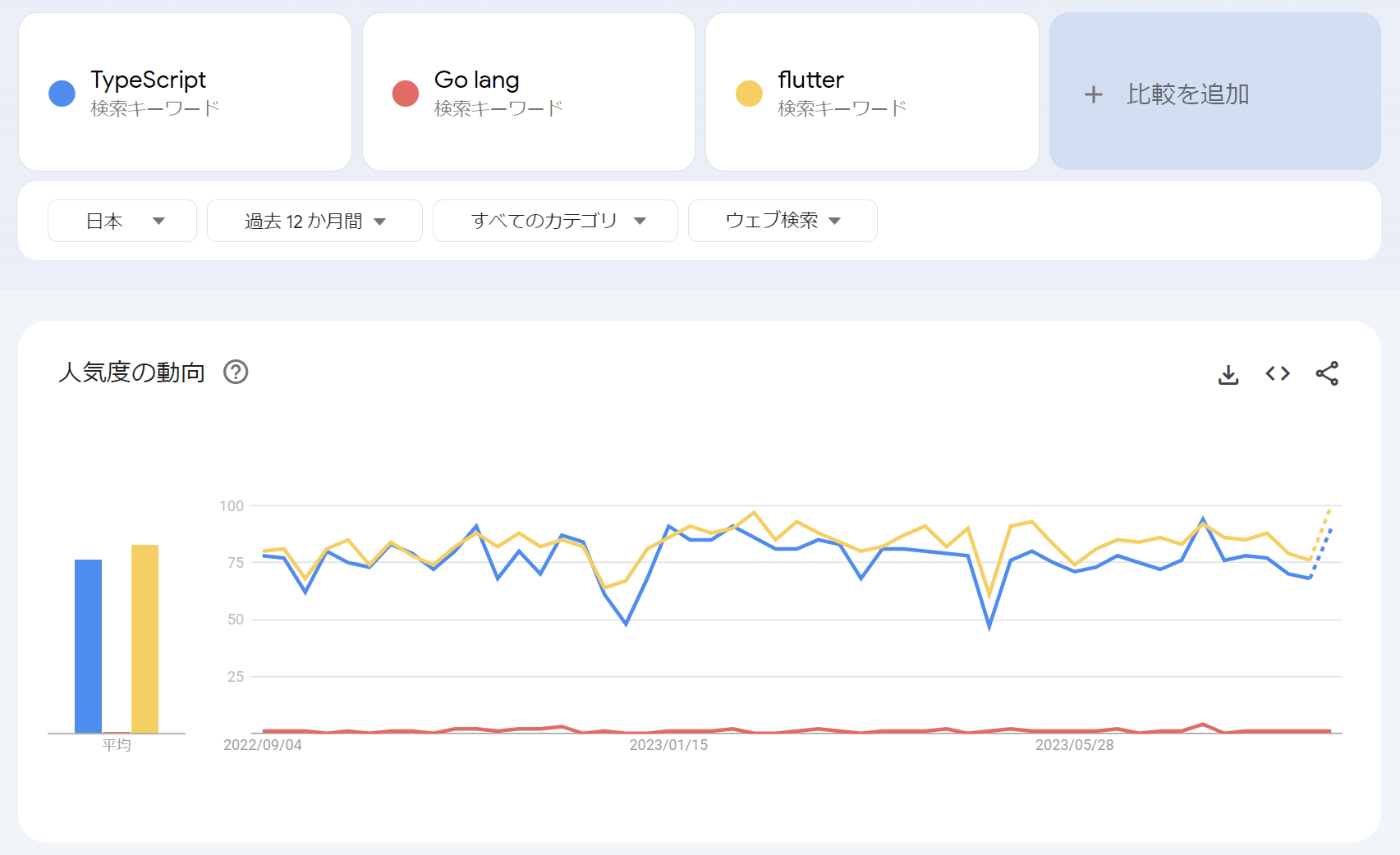
逆に、Google Trendによればポピュラー性についてはTypeScriptに分があります。Goの需要は高く優秀なエンジニアも多いことが予想されますが、コストも含め採用難易度は高いのではないでしょうか。また、今後も残り続け、エンジニアが供給され続ける可能性が高いのはTypeScriptであるといえるでしょう。
エンジニアリソースの大小は、開発速度にも大きく関わります。さらに、GoとTypeScriptでは書くコードの量にも違いがあり、Goに劣るパフォーマンスを、大きなエンジニアリソースで解決する戦略は的外れとは思えません。
レスポンスの速さと開発の速さを同じような条件で比較し、実際にどちらを導入すべきか判断する一つの基準にすることを目指し、この記事を書いていきます。
NestJS(TS), GoでGraphQLサーバーを準備し、それぞれFlutterから用意して速度を計測
今回の検証では、上記のような構成で検証を行っていきます。
私はFlutterのエンジニアなので、Flutterからの呼び出し速度を検証します。
GraphQLサーバーはTypeScript(NestJS) と Goでそれぞれ実装しました。
また、それぞれのサーバーにおいてコード自動生成、Authorizationヘッダーの検証、N+1問題解消のためのdataloaderの実装を行い、それぞれの言語の違いについても検証します。
それぞれの実装は、上記の記事を参考に行いました。
あまり実装に慣れていないチームが新たに実装し始める必要が生じ、これらの実装を標準的なものとして捉え、実装していくシナリオを想定しています。
最後に、DBにはDockerで立てたMySQLを利用します。
データの中身はGraphQLでよく使われるポケモンのデータを入れておきました。
あくまで言語間比較を行うために、すべてローカルネットワーク上で検証を行います。
コード自動生成ライブラリの違い
コードの自動生成については、GoもNestJSも問題なく扱えそうな印象でした。
どちらも1行のコードで意図したとおりに自動生成され、速度もほとんど変わらず。
体感ですが1秒以内に生成されていました。
Schemaについて
Schemaファーストでコードを自動生成します。
Schemaの詳細
type Pokemon{
attack: Int
defense: Int
hp: Int
name: String
jp_name: String
pokedex_num: Int
sp_attack: Int
sp_defense: Int
speed: Int
type1: String
type2: String
generation: Int
is_legendary: Boolean
go : PokemonGo
}
type PokemonGo {
id: Int
name: String
type1: String
type2: String
max_cp: Int
max_hp: Int
image_url: String
}
type Query {
findPokemonByType(type: String!): [Pokemon]! @isAuthenticated
}
Goのコード自動生成にはgqlgenを使う
日本語: https://maku77.github.io/p/v48adgi/
GoでGraphQLサーバーを立てると言ったら、gqlgenというくらい有名なライブラリのようです。
自動生成は go run github.com/99designs/gqlgen generate するだけで簡単です。
NestJSの場合は npm run start:devに統合
こちらもチュートリアルの通りに実装すれば、簡単に自動生成可能です。
使い慣れた npm run start:dev を実行するだけで自動生成されるため、非常に快適でした。
ORMを用意する
実務でもORMを用意してできるだけ手軽かつ安全に書きたくなると思うので、今回はORMを用意します。
GoのORMはsqlboilerを利用
GoのMySQLのORMは思ったより簡潔で、便利な印象でした。
DBとの接続についても非常に簡単に実装できます。
func connectDB() *sql.DB {
jst, err := time.LoadLocation("Asia/Tokyo")
if err != nil {
log.Fatal(err)
}
c := mysql.Config{
DBName: "name",
User: "hoge",
Passwd: "hogehoge",
Addr: "localhost:hoge",
Net: "tcp",
ParseTime: true,
Loc: jst,
}
db, err := sql.Open("mysql", c.FormatDSN())
if err != nil {
log.Fatal(err)
}
// db.SetMaxOpenConns(13) // 必要に応じて設定
// db.SetMaxIdleConns(100)
return db
}
DBのテーブルの型定義ファイルも以下のように1行で自動生成できます。
こっちも非常に簡単ですが、生成用のコードが少しずつ増えていくので、makefileなどを用意してもよいかもしれません。
sqlboiler mysql
しかし、ここで生成される型はあくまでSQLのテーブル構造をもとに生成された型なので、GraphQL Schemaから生成される型とは異なることに注意が必要です。
今回参考にしている Goで学ぶGraphQLサーバーサイド入門を参考にすると、convertXXXを用いて変換しているので、それに倣って以下のように実装しました。
sqlboilerの型定義をgqlgenの型定義に変換する
func convertPokemon(pokemon *db.Pokemon) *model.Pokemon {
legend := pokemon.IsLegendary == 1
attack := int(pokemon.Attack)
defense := int(pokemon.Defense)
hp := int(pokemon.HP)
dex := int(pokemon.PokedexNumber)
spAttack := int(pokemon.SPAttack)
spDefense := int(pokemon.SPDefense)
speed := int(pokemon.Speed)
gen := int(pokemon.Generation)
return &model.Pokemon{
Attack: &attack,
Defense: &defense,
Hp: &hp,
Name: &pokemon.Name,
JpName: &pokemon.JPName,
PokedexNum: &dex,
SpAttack: &spAttack,
SpDefense: &spDefense,
Speed: &speed,
Type1: &pokemon.Type1,
Type2: &pokemon.Type2.String,
Generation: &gen,
IsLegendary: &legend,
}
}
非常に冗長的で面倒です。ただし、冗長なコード故にGitHub Copilotがかなり強く補完してくれるので、利用している方はあまり気にせず書けるかもしれません。
ポケモンのタイプをもとに検索するクエリはこんな感じで実装できます。
func (u *pokemonService) FindPokemonByType(ctx context.Context, typeArg string) ([]*model.Pokemon, error) {
pokemons, err := db.Pokemons(
qm.Where("type1 = ? OR type2 = ?", typeArg, typeArg),
).All(ctx, u.exec)
if err != nil {
return nil, err
}
var result []*model.Pokemon
for _, pokemon := range pokemons {
result = append(result, convertPokemon(pokemon))
}
return result, nil
}
NestJS(TypeScript)はPrismaのおかげでめっちゃ簡単
Prismaの公式チュートリアルに従って進めていくだけです。
DBの接続も非常に簡単で、以下のように schema.prisma に書くだけ。
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "mysql"
url = env("DATABASE_URL")
}
さらに、prisma db pull するだけで、MySQLのテーブルをもとに型定義を自動生成してくれます。クエリも非常に直感的に書けます。さすがprisma。かなり印象よかったです。
async findPokemonByType(type: string): Promise<Pokemon[]> {
const pokemons = await this.prisma.pokemon.findMany({
where: {
OR: [
{
type1: type,
},
{
type2: type,
},
],
},
});
Prismaは型がしっかり決まっているおかげでIDEのオートコンプリートがガンガン効くので、開発体験はかなり良いです。
ORMに関する小まとめ
ORMの良さという意味では、NestJSで使ったPrismaがめちゃくちゃ良いと感じました。
実装にかかる速度という意味でも、NestJSの方がずっと早く、たったの数十分程度で実装できるという結果でした。
Goも特に難しさを感じるようなタイミングはなく、シンプルな記法のおかげでGitHub Copilotの補完も受けられ、体験は悪くないと感じました。
しかしPrismaの強力な型推論と補完の利便性は頭一つ抜けている印象です。
N+1問題対策として使うdataloaderを実装する
あまり詳しくない方のために説明します。
N+1問題とは、発行するSQLが必要以上に増えることでパフォーマンスを低下させてしまう問題のことです。
例えば、親としてpokemon、子としてpokemonGoを持つようなデータがあるとき、なにも考えずに実装すると以下のようなSQLが発行されます。
// +1
SELECT `pokemon`.* FROM `pokemon` WHERE (`pokemon`.`type1` = ?);
// N
SELECT `pokemongo`.* FROM `pokemongo` WHERE (`pokemongo`.`id` = ?) LIMIT 1;
SELECT `pokemongo`.* FROM `pokemongo` WHERE (`pokemongo`.`id` = ?) LIMIT 1;
SELECT `pokemongo`.* FROM `pokemongo` WHERE (`pokemongo`.`id` = ?) LIMIT 1;
SELECT `pokemongo`.* FROM `pokemongo` WHERE (`pokemongo`.`id` = ?) LIMIT 1;
SELECT `pokemongo`.* FROM `pokemongo` WHERE (`pokemongo`.`id` = ?) LIMIT 1;
SELECT `pokemongo`.* FROM `pokemongo` WHERE (`pokemongo`.`id` = ?) LIMIT 1;
- pokemonからTypeが一致するデータを取得(1件)
- それぞれのpokemonに対応するpokemonGoのデータを取得(N件)
あわせてN+1個のクエリが発行されるので、N+1問題と言われます。
SQLを少しかじったことがある方ならお分かりの通り、このケースのN件のSQLは以下のように1つにまとめることができます。
SELECT `pokemongo`.* FROM `pokemongo` WHERE (`pokemongo`.`id`) IN (x, y, z, ...)
上記のようにSQLをまとめる役割を担ってくれる仕組みが、dataloaderです。
Goのdataloaderを実装する
Goのdataloaderの実装
// IN句を使うための関数
func (u *pokemonGoService) FindPokemonGoByIds(ctx context.Context, ids []int) ([]*model.PokemonGo, error) {
int16Ids := make([]int16, len(ids))
for i, id := range ids {
int16Ids[i] = int16(id)
}
pokemonGos, err := db.Pokemongos(db.PokemongoWhere.ID.IN(int16Ids)).All(ctx, u.exec)
if err != nil {
return nil, err
}
return convertPokemonGoSlice(pokemonGos), nil
}
// 内部でdataloaderを使う関数
func (p *pokemonGoBatcher) BatchGetPokemonGo(ctx context.Context, ids []string) []*dataloader.Result[*model.PokemonGo] {
results := make([]*dataloader.Result[*model.PokemonGo], len(ids))
// IN句によるSQLのクエリは、順番を保証しないため、
// 順番を保証するためのマップを作成する
indexes := make(map[string]int, len(ids))
for i, id := range ids {
indexes[id] = i
}
intIds := make([]int, len(ids))
for i, id := range ids {
intIds[i], _ = strconv.Atoi(id)
}
pokemonGos, err := p.Srv.FindPokemonGoByIds(ctx, intIds)
for _, pokemonGo := range pokemonGos {
var rsl *dataloader.Result[*model.PokemonGo]
if err != nil {
rsl = &dataloader.Result[*model.PokemonGo]{
Error: err,
}
} else {
rsl = &dataloader.Result[*model.PokemonGo]{
Data: pokemonGo,
}
}
intId := strconv.Itoa(*pokemonGo.ID)
results[indexes[intId]] = rsl
}
return results
}
// dataloaderを利用するResolver
func (r *pokemonResolver) pokemonResolver(ctx context.Context, obj *model.Pokemon) (*model.PokemonGo, error) {
id := *obj.PokedexNum
thunk := r.Loaders.PokemonGoLoader.Load(ctx, strconv.Itoa(id))
pokemonGo, err := thunk()
if err != nil {
return nil, err
}
NestJSのdataloaderを実装する
NestJSでdataloaderを実装する
// dataloaderの定義
import * as DataLoader from 'dataloader';
export abstract class BaseDataloader<K, V> {
protected readonly dataloader: DataLoader<K, V> = new DataLoader<K, V>(
this.batchLoad.bind(this),
);
public async loadMany(keys: K[]): Promise<(V | Error)[]> {
return keys.length > 0 ? this.dataloader.loadMany(keys) : [];
}
protected abstract batchLoad(keys: K[]): Promise<(V | Error)[]>;
}
// dataloaderの呼び出し
async findPokemonGoByIds(ids: number[]): Promise<PokemonGo[]> {
return await this.loader.loadMany(ids);
}
async findPokemonByType(type: string): Promise<Pokemon[]> {
const pokemons = await this.prisma.pokemon.findMany({
where: {
OR: [
{
type1: type,
},
{
type2: type,
},
],
},
});
const ids = pokemons.map((pokemon) => pokemon.pokedex_number);
const pokemonGoList = await this.findPokemonGoByIds(ids);
const pokemonList = [];
for (const pokemon of pokemons) {
const go = pokemonGoList.find(
(e: PokemonGo) => e.id === pokemon.pokedex_number,
);
pokemonList.push({
...this.convertPokemon(pokemon),
go: go,
});
}
return pokemonList;
}
dataloaderについては、書き方の大きな差は感じられなかった
Goだと明示的にthunkを指定するのに対し、NestJSではその辺を書かなくていいなど小さい違いはありましたが、大きくみるとあまり違いは感じられませんでした。
NestJSのアーキテクチャをそのまま利用してDIしながらオブジェクト指向っぽく実装できるのが良いと感じるかそうでないか?違いはそこに収束するような気がします。
Headerに付与された付加情報を処理する
GraphQLのリクエストの実態はPOSTリクエストですから、Headerにいろいろ仕込みたくなります。認証トークンや、その他識別情報などなど。
おそらく絶対に触ることになる場所なので、GoとNestJSで実装します。
Goでミドルウェアを実装していく
GraphQLサーバーがレスポンスに必要なデータを集めてくる処理は全てリゾルバの中で行っていましたが、リゾルバ関数の中には「HTTP通信」の要素を感じられるような引数は存在しません。
~ 中略 ~
HTTPリクエストの中身を見るような前後処理を挟むためには、通常のHTTPサーバーを作るときと同様の手段でミドルウェアを実装すれば良いのです。
というわけで、単純にミドルウェアを実装すればよさそうです。
type AuthKey struct {
IsAuth bool
Role string
}
func AuthMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, req *http.Request) {
token := req.Header.Get("Authorization")
authKey := AuthKey{
IsAuth: validateToken(token),
Role: checkRole(token),
}
ctx := context.WithValue(req.Context(), "auth", authKey)
w.Header().Set("authenticated", strconv.FormatBool(authKey.IsAuth))
next.ServeHTTP(w, req.WithContext(ctx))
})
}
// server.go
http.Handle("/query", auth.AuthMiddleware(srv))
このミドルウェアはcontextに情報を付加しますが、通信の遮断を行うロジックにはなっていません。すべてのルートに対して機能するからです。
したがって、選択的に遮断機能を使うためにGraphQLの構文の一つであるDirectiveを使います。
GraphQLで書ける @hogeのことです。
(Directive, Decorator, Annotationnなど@まわりがややこしくて非常によくない)
type Query {
findPokemonByType(type: String!): [Pokemon]! @isAuthenticated
}
ここで指定した @isAuthenticated に対して、認証を実装すると以下のようになります。
var Directive DirectiveRoot = DirectiveRoot{
IsAuthenticated: IsAuthenticated,
}
func IsAuthenticated(ctx context.Context, obj interface{}, next graphql.Resolver) (res interface{}, err error) {
v := auth.IsValid(ctx)
if !v.IsAuth {
return nil, errors.New("not authenticated")
}
return next(ctx)
}
あまり難しいことはありません。
QueryやMutationごとに違うロジックで認証を行うことも可能ですし、かなり柔軟に書ける印象です。
NestJSではGuardを使うと非常に簡単に実装可能
Guardはミドルウェアの1つですが、特に権限に合わせたアクセス許可を出すこと専用に作られています。
CanActivateクラスをimplementして、canActivate()を実装し、条件に合わせてbooleanを返すだけ。実装は非常に簡単です。
@Injectable()
export class AuthGuard implements CanActivate {
canActivate(
context: ExecutionContext,
): boolean | Promise<boolean> | Observable<boolean> {
const ctx = GqlExecutionContext.create(context).getContext();
const auth = ctx.req.headers.authorization;
console.dir(auth);
if (auth === 'hoge') {
return true;
} else {
throw new UnauthorizedException();
}
}
}
さらに、リゾルバに以下のように@UseGuards(AuthGuard)デコレータをつけるだけ。
@UseGuards(AuthGuard)
@Query()
async findPokemonByType(@Args('type') type: string) {
return this.service.findPokemonByType(type);
}
これだけで、Authorization Headerを正しく設定していないリクエストをはじくことができます。
付加情報の処理はGoよりNestJSの方が処理しやすい
NestJSの方がGuardを使って、リゾルバに直接デコレータをつけるだけで処理を書けるので、非常にわかりやすいと感じました。
今回は、指定した場所に認証機能をつけましたが、実際の実装では限られたところのみをPublicにして、それ以外すべてに認証が必要にしたいことが多いと思います。その場合もNestJSなら簡単に実装できそうな印象でした。
もちろん、NestJSはフレームワークなので、必要なものがあらかじめ用意されているのは当たり前ですが。
Goについても逆にフレームワークに頼っていないにも関わらず、シンプルに実装できます。どっちのシンタックスが好みかは人によると思うので、お好きな方をお使いください。
FlutterでGraphQLクライアントを作って測定する
Flutterから呼び出すことを想定して、実際にクライアントを作ってみました。
graphql_codegenを使って、バックエンドを作るときに使用したスキーマファイルを利用してコードを自動生成してみました。
さらに、今回はDart製のベンチマークパッケージ「Hakari」を利用していきます。
ポケモン第1世代(151匹)のデータをTypeで検索するリクエストをX回送信した時の処理速度を計測します。
Bench結果
全てローカルネットワークに乗っていて、NestJSとGoはそれぞれそのまま立ち上げています。
また、MySQLサーバーのみDockerで構築されています。
type Query {
findPokemonByType(type: String!): [Pokemon]! @isAuthenticated
}
ポケモンのタイプによりフィルターしたデータを返すクエリを実行しました。
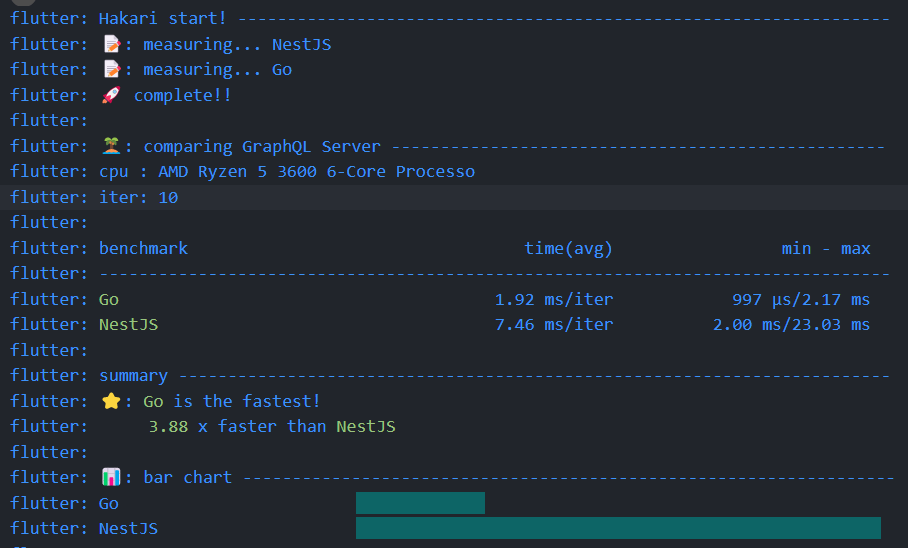
- 10回実行時
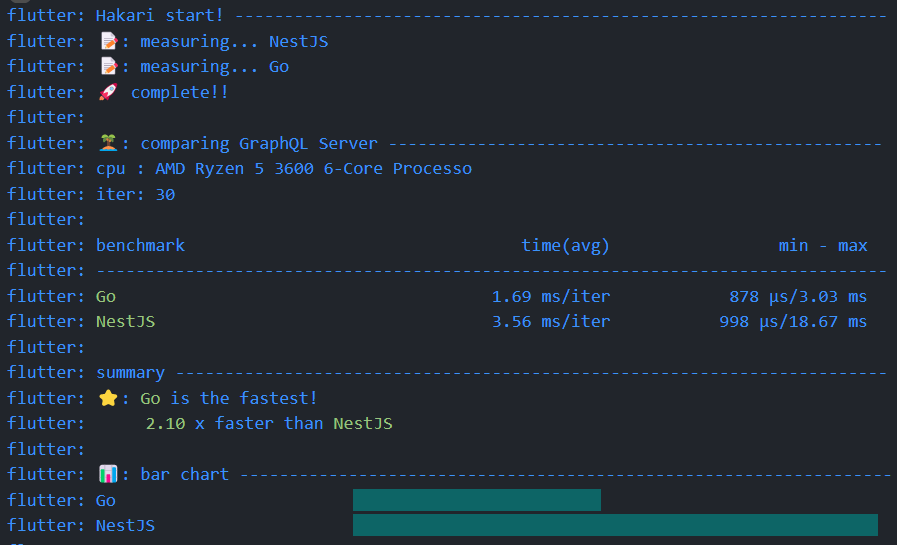
- 30回実行時
- 100回実行時
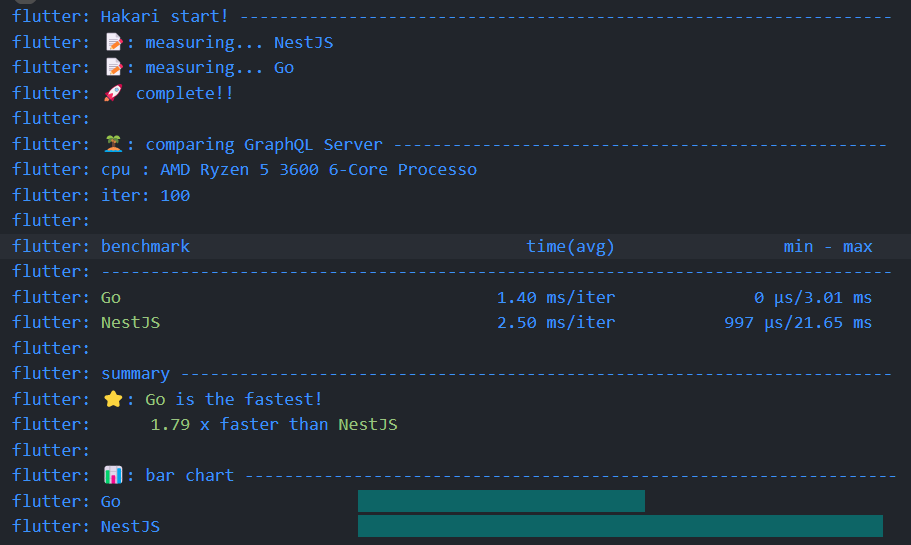
ポケモン(1世代)のタイプは14個しかないので、10回実行時以外は内部実装でキャッシュが利用されている可能性があります。そのためか、100回実行時になると差が縮まってきています。要検証。次の課題です。
また、Hakariの内部実装はmicrosecondsSinceEpochを使っているため、それ以下の計測はできませんでした。
結果としては、想像通り圧倒的にGoが早い結果となりました。
一方で、NestJSは遅いというほどでもなく、TypeScriptなメンバーで多くが構成されるようなチームが採用する技術としては決して間違いではないと思える結果でもあります。
まとめ
今回は、GoとNestJS(TypeScript)におけるGraphQLサーバーを、必ず使う機能について簡単に実装し、Flutterクライアントから呼び出した時の速度を測定してみました。
| Go | NestJS (TypeScript) | |
|---|---|---|
| 実装難易度 | 思ったより高くはない | 簡単 |
| 実装コスト | ||
| (時間・量) | 思ったより早く書ける | 実装にかかる時間は早い。 |
| 自分で書くコード量は少ないが、NestJSのアーキテクチャ上必要になるコードは少なくない。 | ||
| エコシステム | 十分 | 十分 |
| 日本語資料 | 可 | 可 |
| (Goよりずっと多いかと思ったが、想定よりは少ない) | ||
| パフォーマンス | NestJS実装より2倍程度早い | 決して許容できない速度ではない |
| GitHub Copilot | かなり正確に補完される | NestJS + TypeScript + Prismaの構成だと強力に補完される |
どちらの言語(フレームワーク)もかなり簡単に書ける印象でした。しかし、どっちかといえばNestJSの方が簡単で、Goで2~3時間かかる実装が、NestJSでは1時間かからずに書けました。
ただし、私はGoに全く慣れていないので、Goに馴染みのある方であればGoの方が早くなる可能性も高いと思います。
TypeScript人口の方がGo人口よりも圧倒的に多いだろうと予想できますが、エコシステム、日本語資料については、GoとNestJSにおいて大きな差はないように感じました。
パフォーマンスについてはGoが圧倒的でした。GoはNestJSの2倍程度の速さでレスポンスを返せるようです。さすがですね。Goな開発者が多ければメルカリShopの推奨通りGoで書くのが間違いなさそうです。
一方で、NestJSが極端に遅いかというと、そんなことはありません。この感じであれば、本番環境にデプロイしても10~40msくらいでレスポンスを返せるんじゃないでしょうか。要検証ですが、体感レベルでめちゃくちゃ遅いサーバーになることはなさそうです。TypeScriptを扱える人が多い組織では、NestJSなどを使ってGraphQLサーバーを書く選択肢も全然アリですね。
最近全社導入している会社が増えてきたGitHub Copilot。弊社でも全社導入しているため利用しながら実装したのですが、どちらもGitHub Copilotの補完がものすごく強く効きます。 もちろん、今回のような 0 → 1 の実装は非常にマニュアルに近い実装のため、学習量も多く、その結果サジェストが優秀だっただけの可能性もあります。
しかし、上記記事にもある、GoのAcceptance Rateが40%を超えるというデータは私の体感とも一致し、非常に良い開発体験でした。
ChatGPTなども含め、これらのAI技術を活かせることを考えると、パフォーマンスを最優先にGoで組むという選択肢は意外と的外れではないのかもしれません。
最後に、バックエンドをマイクロサービス化していく予定がある場合は、通信プロトコルにgRPCが使いたくなる可能性が高いため、Goが良いでしょう。TypeScriptでgRPCを利用するのはかなりハードル高めです。
さいごに
善行を積むのでLikeください!!
まだまだ暑い...秋はよぅ!
最近は収益化を進めてくるXですが、このアカウントのインプレッションじゃどう考えても黒字にならないことを理解しているので、身の丈に合った課金ゼロスタイルでサーフィンしていく所存。
株式会社マインディアでは、Flutterリードエンジニア、Railsエンジニアを募集しております。
カジュアル面談などの場を用意しておりますので、気軽にDM等でお声がけください。
引き続き、Flutter周りの気になることを調査したり、ジュニアなエンジニアが思うことも記事にしていきますので、良かったらZennやTwitterのフォローをお願いします!

Discussion
良記事ありがとうございます!!
こちらこそ読んでいただきありがとうございます🙇