Open6
スクレイピングのメモ
ヘッドレスでSeleniumを動かすとき何故か、Javascriptを禁止できない。
chromeOptions = webdriver.ChromeOptions()
# headlessが有効だと何故かjavascriptを禁止できない。
# chromeOptions.add_argument("--headless")
chromeOptions.add_argument("--disable-gpu")
chromeOptions.add_argument("--no-sandbox")
chromeOptions.set_capability("goog:loggingPrefs", {"performance": "ALL"})
chromeOptions.add_argument("--disable-javascript")
chromeOptions.add_experimental_option("prefs", {
'profile.managed_default_content_settings.javascript': 2
})
selenium_url = "http://127.0.0.1:4444/wd/hub"
driver = webdriver.Remote(selenium_url, options=chromeOptions)
どぼぢで予期しないタグが勝手に入るのおおおおおお!
ChromeやFirefoxだとHTMLに書いていないタグが勝手に挿入される場合がある。
以下の例ではtable/tr/tdという構造がtable/tbody/tr/tdになっている。
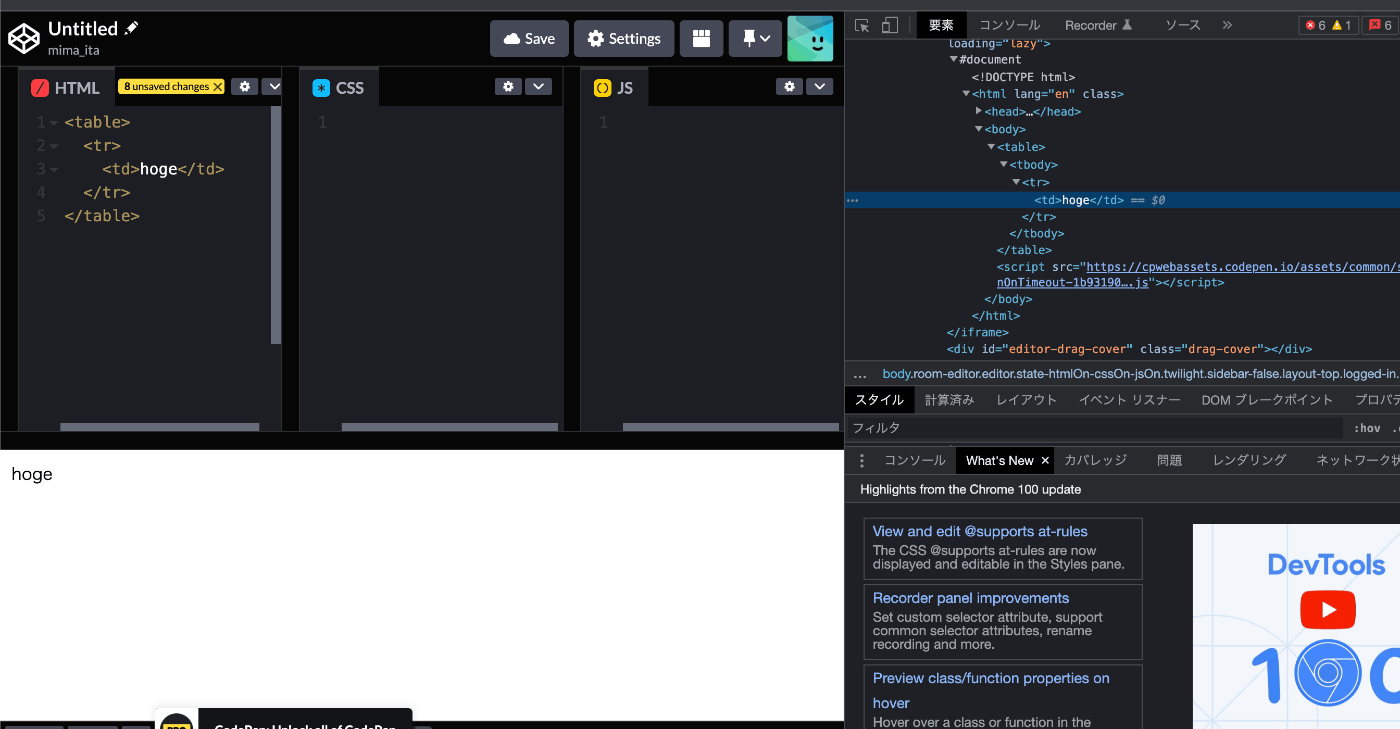
ブラウザ上で操作した時の構造と、bs4などで取得した時の構造が違うケースがあるので注意。
BeautifulSoup4でコメントを除去する方法
# コメントの除去
for comments in soup.findAll(text=lambda text:isinstance(text, Comment)):
comments.extract()
#以降、コメントが消えている
robots.txtのチェックはurllib.robotparserで行える。
sitemapのチェックはultimate-sitemap-parserで行える
sitemapが存在しないページの場合は、tree.all_pages()が何も繰り返さない。
1箇所調べるのに、かなり時間のかかる処理が実行される
サイトの都合で文字化けするケースが存在する。
Firefoxでは表示⇨テキストエンコーディングの修正でエンコードの修正ができる。
昔のChromeにも同じ仕組みがあったが、現在はない。
以下のような拡張機能で対応できる。
仕組みとしてはjavascriptでエンコードを指定してURLを取り直している。
let xmlHttp = new XMLHttpRequest();
xmlHttp.overrideMimeType(`text/plain; charset=cp932`);
xmlHttp.onload = () => {
let res = xmlHttp.responseText
document.open()
document.write(res)
document.close()
};
xmlHttp.open('GET', document.baseURI, true);
xmlHttp.send();
つまり、この仕組みはseleniumでも流用できる。
例えば「�」という文字が一定の割合で存在したら文字化けしているとみなし、修復を行う。