Pythonのオブジェクトはメモリ上でどう表現されているのか? 前編
はじめに
Pythonでの開発中はCやC++と違いメモリの内容を意識することは、ほとんどありません。
本ドキュメントではあえて、intやstrなどのオブジェクトが実際どのようにメモリに格納されているかを実験しつつ確認してみます。
対象のCPythonのバージョン:
オブジェクトのメモリアドレス
組み込み関数のidを使用することでCPython ではオブジェクトのメモリアドレスを取得することが可能です。
では実際にbytes型のメモリをのぞいてみましょう。
まず、bytes型のオブジェクトを作成して、そのオブジェクトのアドレスを表示させます。
import os
print("pid", os.getpid()) # 自分(このプロセス)のPIDを表示
var1 = b"\x01\x0A\x1F\xEF"
addr = id(var1)
print("var1 :", hex(addr))
# キー入力があるまでプロセスを終了しないように待機させる
input("pause")
ここでは次のような結果が出力されます。
pid 18908
var1 : 0x106d61170
pause
今回はキーボードを入力するまで、プロセスが終了されないので、このPythonのプロセスが起動中に、このプロセスIDの該当のメモリを確認します。
macOSの場合、Xcodeをインストールしていればlldbが使用できるので、lldb -p プロセスIDで、プロセスにアタッチしてメモリを確認できます。
上記の例の場合、ターミナルから以下のコマンドを実行します。
lldb -p 18908
この際、管理者権限を求められる可能性があります。
次にmemory read --format hex --size 1 --count 64 *アドレス*コマンドでメモリの内容を読み取ります。
今回の例だと結果は以下のようになります。
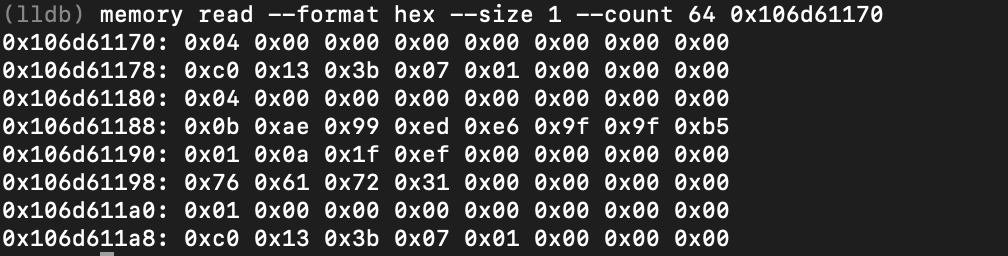
実際、このメモリの内容から、bytes型のサイズと、その中身は確認できます。
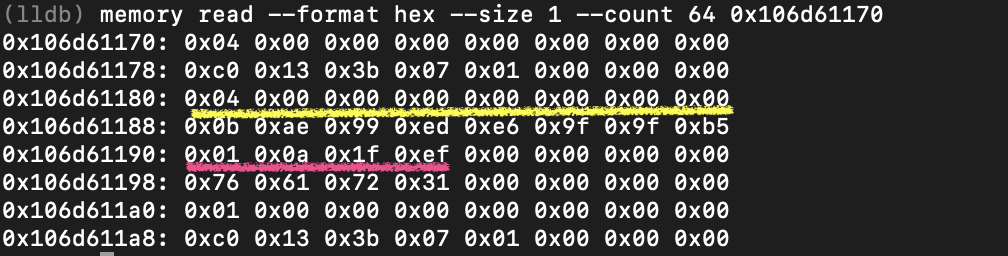
黄色い下線を引いた8バイトがbytes型のサイズで、赤い下線がbytes型の中身になります。
この結論を出すにはPyBytesObject構造体の内容を確認する必要があります。
typedef struct {
PyObject_VAR_HEAD
Py_DEPRECATED(3.11) Py_hash_t ob_shash;
char ob_sval[1];
/* Invariants:
* ob_sval contains space for 'ob_size+1' elements.
* ob_sval[ob_size] == 0.
* ob_shash is the hash of the byte string or -1 if not computed yet.
*/
} PyBytesObject;
ob_svalに格納されているのがbytes型の中身で赤い線の部分になります。
PyObject_VAR_HEADはサイズをもつオブジェクトでは共通して現れるヘッダです。その実際の構造はPyVarObject構造体で表せます。
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
ここのob_sizeがbytesのサイズにあたり、黄色い線で表せます。
PyObjectはすべてのオブジェクトに共通して存在するヘッダでその構造は以下のようになります。
/* Nothing is actually declared to be a PyObject, but every pointer to
* a Python object can be cast to a PyObject*. This is inheritance built
* by hand. Similarly every pointer to a variable-size Python object can,
* in addition, be cast to PyVarObject*.
*/
#ifndef Py_GIL_DISABLED
struct _object {
#if (defined(__GNUC__) || defined(__clang__)) \
&& !(defined __STDC_VERSION__ && __STDC_VERSION__ >= 201112L)
// On C99 and older, anonymous union is a GCC and clang extension
__extension__
#endif
#ifdef _MSC_VER
// Ignore MSC warning C4201: "nonstandard extension used:
// nameless struct/union"
__pragma(warning(push))
__pragma(warning(disable: 4201))
#endif
union {
Py_ssize_t ob_refcnt;
#if SIZEOF_VOID_P > 4
PY_UINT32_T ob_refcnt_split[2];
#endif
};
#ifdef _MSC_VER
__pragma(warning(pop))
#endif
PyTypeObject *ob_type;
};
#else
// Objects that are not owned by any thread use a thread id (tid) of zero.
// This includes both immortal objects and objects whose reference count
// fields have been merged.
#define _Py_UNOWNED_TID 0
// The shared reference count uses the two least-significant bits to store
// flags. The remaining bits are used to store the reference count.
#define _Py_REF_SHARED_SHIFT 2
#define _Py_REF_SHARED_FLAG_MASK 0x3
// The shared flags are initialized to zero.
#define _Py_REF_SHARED_INIT 0x0
#define _Py_REF_MAYBE_WEAKREF 0x1
#define _Py_REF_QUEUED 0x2
#define _Py_REF_MERGED 0x3
// Create a shared field from a refcnt and desired flags
#define _Py_REF_SHARED(refcnt, flags) (((refcnt) << _Py_REF_SHARED_SHIFT) + (flags))
struct _object {
// ob_tid stores the thread id (or zero). It is also used by the GC and the
// trashcan mechanism as a linked list pointer and by the GC to store the
// computed "gc_refs" refcount.
uintptr_t ob_tid;
uint16_t _padding;
PyMutex ob_mutex; // per-object lock
uint8_t ob_gc_bits; // gc-related state
uint32_t ob_ref_local; // local reference count
Py_ssize_t ob_ref_shared; // shared (atomic) reference count
PyTypeObject *ob_type;
};
#endif
非常にながくてややこしいですが、GILを有効(デフォルトの挙動)にしている場合は以下のフィールドが格納されます。
Py_ssize_t ob_refcnt;
PyTypeObject *ob_type;
実験環境でいうと、Py_ssize_tと、PyTypeObject*はともに8バイトになるため、PyObjectのサイズは16バイトとなります。
GILが有効か無効、32ビットか64ビットのプロセスかで構造体の形が変わるケースが多いです。そのため、今回の実験ではGILが有効であることを前提としています。
GILを無効にした場合や32ビットのPythonで動かした場合、今回のサンプルコードは動作しません。
Python上でのオブジェクトのメモリアドレスの探索
前述のように組み込み関数のidを使用することでオブジェクトのアドレスを取得して、デバッガなどを使ってオブジェクトのメモリアドレスを探索することもできますが、試行錯誤に時間がかかります。
そこで、Python上でもctypesライブラリやstructライブラリを使用することで、メモリの探索が容易になります。
PyObjectの探索
前述のとおり、すべてのオブジェクトにはPyObjectの情報が格納されています。
これがメモリ上にどのように入っているかをPython上で確認してみます。
サンプルコードと出力結果
サンプルコード
import ctypes, sys
assert sys.version_info.major == 3
assert sys.version_info.minor == 13
assert sys.implementation.name == 'cpython'
assert sys._is_gil_enabled()
# _object
# 実際には何も PyObject として宣言されていないが、あらゆる Python オブジェクトへのポインタは PyObject* にキャストできる。
# これは手作業で実現した継承に相当する。
# 同様に、可変サイズの Python オブジェクトへのポインタは、さらに PyVarObject* にキャストできる。
# https://github.com/python/cpython/blob/3.13/Include/object.h
# GILが有効であることが前提である
class PyObject(ctypes.Structure):
_fields_ = [
("ob_refcnt", ctypes.c_ssize_t),
("ob_type", ctypes.c_void_p),
]
def inspect_base(addr):
# 指定のポインタをPyObjectの型にキャストする
obj = ctypes.cast(addr, ctypes.POINTER(PyObject)).contents
ob_refcnt = obj.ob_refcnt
ob_type = obj.ob_type
try:
type_obj = ctypes.cast(ob_type, ctypes.py_object).value
except Exception as e:
type_obj = f"<cannot cast to py_object: {e}>"
return {
"addr": hex(addr),
"ob_refcnt": ob_refcnt,
"ob_type": hex(ob_type),
"type_obj": type_obj
}
def print_base(name, addr, indent=0):
res = inspect_base(addr)
print('------------------------')
print(" " * indent, "name:", name)
print(" " * indent, "addr:", res.get('addr'))
print(" " * indent, "ob_refcnt:", res.get('ob_refcnt'))
print(" " * indent, "ob_type:", res.get('ob_type'))
print(" " * indent, "型", res.get('type_obj'))
var1 = b"\x01\x0A\x1F\xEF"
print_base("bytesデータ", id(var1))
var2 = 1.0
print_base("浮動小数", id(var2))
var3 = 1
print_base("整数(小さい)", id(var3))
var4 = 123456789
print_base("整数(大きい)", id(var4))
var5 = "test1"
print_base("文字列", id(var5))
var6 = ("test1", 1)
print_base("タプル", id(var6))
var7 = ["test1", 1]
print_base("リスト", id(var7))
var8 = {"test1": 1, "test2": 1024}
print_base("辞書", id(var8))
backup = var1
print_base("bytesデータ(参照を増やした場合)", id(var1))
出力結果
------------------------
name: bytesデータ
addr: 0x1010024f0
ob_refcnt: 4
ob_type: 0x1016583c0
型 <class 'bytes'>
------------------------
name: 浮動小数
addr: 0x100f21a30
ob_refcnt: 3
ob_type: 0x1016654e0
型 <class 'float'>
------------------------
name: 整数(小さい)
addr: 0x1016904c0
ob_refcnt: 4294967295
ob_type: 0x101667ec0
型 <class 'int'>
------------------------
name: 整数(大きい)
addr: 0x100dbf450
ob_refcnt: 3
ob_type: 0x101667ec0
型 <class 'int'>
------------------------
name: 文字列
addr: 0x1010029a0
ob_refcnt: 5
ob_type: 0x101674c10
型 <class 'str'>
------------------------
name: タプル
addr: 0x100f6a640
ob_refcnt: 3
ob_type: 0x10166fb80
型 <class 'tuple'>
------------------------
name: リスト
addr: 0x100e9f880
ob_refcnt: 1
ob_type: 0x1016674c0
型 <class 'list'>
------------------------
name: 辞書
addr: 0x10100f180
ob_refcnt: 1
ob_type: 0x101669698
型 <class 'dict'>
------------------------
name: bytesデータ(参照を増やした場合)
addr: 0x1010024f0
ob_refcnt: 5
ob_type: 0x1016583c0
型 <class 'bytes'>
このコードと出力結果については次の章で解説します。
オブジェクトのアドレスからPyObjectを表現する
Cで記載されたPyObjectはctypes.Structureを継承したクラスで表現することが可能です。
class PyObject(ctypes.Structure):
_fields_ = [
("ob_refcnt", ctypes.c_ssize_t),
("ob_type", ctypes.c_void_p),
]
idを使用して取得したオブジェクトのアドレスから、ctypes.Structureを継承したクラスにキャストすることが可能です。
# 指定のポインタをPyObjectの型にキャストする
obj = ctypes.cast(addr, ctypes.POINTER(PyObject)).contents
ob_refcnt = obj.ob_refcnt
ob_type = obj.ob_type
ob_refcntの確認
ob_refcntは参照カウンタとなっていて、参照が増えるたびに数値が増えます。
このことは、出力結果の「bytesデータ」と「bytesデータ(参照を増やした場合)」を比較することで確認できます。
------------------------
name: bytesデータ
addr: 0x1010024f0
ob_refcnt: 4
ob_type: 0x1016583c0
型 <class 'bytes'>
... 略
------------------------
name: bytesデータ(参照を増やした場合)
addr: 0x1010024f0
ob_refcnt: 5
ob_type: 0x1016583c0
型 <class 'bytes'>
これはvar1を別の変数に格納して参照を増やした結果、ob_refcntが増加していることが確認できます。
さて、出力結果を確認しているとvar3 = 1の結果のob_refcntが異常に大きな値になっていることがわかります。
...
------------------------
name: 整数(小さい)
addr: 0x1016904c0
ob_refcnt: 4294967295
ob_type: 0x101667ec0
型 <class 'int'>
...
これは小さな整数がImmortal Objectsとして扱われているためです。
通常、オブジェクトは参照カウンタによってオブジェクトを生存を管理します。しかし、Python3.12以降にImmortal Objectsという概念が追加されました。
CPythonでは-5〜256までの小さな整数が初期化時にImmortal Objectsが登録されています。
これらの非常に小さな整数はシングルトンとしてグローバルに共有するためにImmortal Objectsとなっています。
Immortal Objectsについては以下のブログに解説が載っています。
Understanding Immortal Objects in Python 3.12: A Deep Dive into Python Internals
ob_typeの確認
ob_typeはPythonの型を表現するためのPyTypeObjectへのポインタになっています。
ob_typeのアドレスからPythonの型に変更するには以下のようなcastを実施します。
try:
type_obj = ctypes.cast(ob_type, ctypes.py_object).value
except Exception as e:
type_obj = f"<cannot cast to py_object: {e}>"
出力結果を確認すると<class 'int'>などと表示されていることが確認できます。
PyVarObjectの探索
bytes、list、tupleなどのサイズをもつオブジェクトはPyObject_VAR_HEADを持っています。
前述の通り、これはPyVarObject構造体で表せます。
ここではサンプルコードを介してPyVarObjectの内容を確認してみます。
サンプルコードと出力結果
サンプルコード
import ctypes, sys
assert sys.version_info.major == 3
assert sys.version_info.minor == 13
assert sys.implementation.name == 'cpython'
assert sys._is_gil_enabled()
# _object
# 実際には何も PyObject として宣言されていないが、あらゆる Python オブジェクトへのポインタは PyObject* にキャストできる。
# これは手作業で実現した継承に相当する。
# 同様に、可変サイズの Python オブジェクトへのポインタは、さらに PyVarObject* にキャストできる。
# https://github.com/python/cpython/blob/3.13/Include/object.h
# GILが有効であることが前提である
class PyObject(ctypes.Structure):
_fields_ = [
("ob_refcnt", ctypes.c_ssize_t),
("ob_type", ctypes.c_void_p),
]
# PyVarObject
# https://github.com/python/cpython/blob/3.13/Include/object.h#L224
class PyVarObject(ctypes.Structure):
_fields_ = [
("ob_base", PyObject),
("ob_size", ctypes.c_ssize_t),
]
def inspect_base(addr):
# 指定のポインタをPyObjectの型にキャストする
obj = ctypes.cast(addr, ctypes.POINTER(PyObject)).contents
ob_refcnt = obj.ob_refcnt
ob_type = obj.ob_type
try:
type_obj = ctypes.cast(ob_type, ctypes.py_object).value
except Exception as e:
type_obj = f"<cannot cast to py_object: {e}>"
return {
"addr": hex(addr),
"ob_refcnt": ob_refcnt,
"ob_type": hex(ob_type),
"type_obj": type_obj
}
def inspect_py_var(addr):
res = inspect_base(addr)
obj = ctypes.cast(addr, ctypes.POINTER(PyVarObject)).contents
res['ob_size'] = obj.ob_size
return res
def print_py_var(name, addr, indent=0):
res = inspect_py_var(addr)
print('------------------------')
print(" " * indent, "name:", name)
print(" " * indent, "addr:", res.get('addr'))
print(" " * indent, "ob_refcnt:", res.get('ob_refcnt'))
print(" " * indent, "ob_type:", res.get('ob_type'))
print(" " * indent, "型", res.get('type_obj'))
print(" " * indent, "ob_size", res.get('ob_size'))
var1 = b"\x01\x0A\x1F\xEF"
print_py_var("bytesデータ", id(var1))
var2 = ("test1", 1)
print_py_var("タプル", id(var2))
var3 = ["test1", 1, 3]
print_py_var("リスト", id(var3))
var4 = []
print_py_var("リスト(空)", id(var4))
出力結果
------------------------
name: bytesデータ
addr: 0x10cbfec40
ob_refcnt: 4
ob_type: 0x10d24f3c0
型 <class 'bytes'>
ob_size 4
------------------------
name: タプル
addr: 0x10cb66640
ob_refcnt: 3
ob_type: 0x10d266b80
型 <class 'tuple'>
ob_size 2
------------------------
name: リスト
addr: 0x10cc0b1c0
ob_refcnt: 1
ob_type: 0x10d25e4c0
型 <class 'list'>
ob_size 3
------------------------
name: リスト(空)
addr: 0x10cc09e00
ob_refcnt: 1
ob_type: 0x10d25e4c0
型 <class 'list'>
ob_size 0
オブジェクトのアドレスからPyVarObjectを表現する
Cで記載されたPyVarObjectはctypes.Structureを継承したクラスで表現することが可能です。
# PyVarObject
# https://github.com/python/cpython/blob/3.13/Include/object.h#L224
class PyVarObject(ctypes.Structure):
_fields_ = [
("ob_base", PyObject),
("ob_size", ctypes.c_ssize_t),
]
idを使用して取得したオブジェクトのアドレスから、ctypes.Structureを継承したクラスにキャストすることが可能です。
obj = ctypes.cast(addr, ctypes.POINTER(PyVarObject)).contents
res['ob_size'] = obj.ob_size
ob_sizeの確認
出力結果をみるとob_sizeにサイズが格納されていることが確認できます。
| 格納データ | 出力したob_size |
|---|---|
| b"\x01\x0A\x1F\xEF" | 4 |
| ("test1", 1) | 2 |
| ["test1", 1, 3] | 3 |
| [] | 0 |
PyFloatObjectの探索
1.5や8.5e+5といった浮動小数型はPyFloatObjectに格納されます。
サンプルコードと出力結果
サンプルコード
import ctypes, sys
assert sys.version_info.major == 3
assert sys.version_info.minor == 13
assert sys.implementation.name == 'cpython'
assert sys._is_gil_enabled()
# _object
# 実際には何も PyObject として宣言されていないが、あらゆる Python オブジェクトへのポインタは PyObject* にキャストできる。
# これは手作業で実現した継承に相当する。
# 同様に、可変サイズの Python オブジェクトへのポインタは、さらに PyVarObject* にキャストできる。
# https://github.com/python/cpython/blob/3.13/Include/object.h
# GILが有効であることが前提である
class PyObject(ctypes.Structure):
_fields_ = [
("ob_refcnt", ctypes.c_ssize_t),
("ob_type", ctypes.c_void_p),
]
# https://github.com/python/cpython/blob/3.13/Include/cpython/floatobject.h#L5
class PyFloatObject(ctypes.Structure):
_fields_ = [
("head", PyObject),
("ob_fval", ctypes.c_double),
]
def inspect_base(addr):
# 指定のポインタをPyObjectの型にキャストする
obj = ctypes.cast(addr, ctypes.POINTER(PyObject)).contents
ob_refcnt = obj.ob_refcnt
ob_type = obj.ob_type
try:
type_obj = ctypes.cast(ob_type, ctypes.py_object).value
except Exception as e:
type_obj = f"<cannot cast to py_object: {e}>"
return {
"addr": hex(addr),
"ob_refcnt": ob_refcnt,
"ob_type": hex(ob_type),
"type_obj": type_obj
}
def inspect_float(addr):
res = inspect_base(addr)
obj = ctypes.cast(addr, ctypes.POINTER(PyFloatObject)).contents
res['ob_fval'] = obj.ob_fval
return res
def print_float(name, addr, indent=0):
res = inspect_float(addr)
print('------------------------')
print(" " * indent, "name:", name)
print(" " * indent, "addr:", res.get('addr'))
print(" " * indent, "ob_refcnt:", res.get('ob_refcnt'))
print(" " * indent, "ob_type:", res.get('ob_type'))
print(" " * indent, "型", res.get('type_obj'))
print(" " * indent, "ob_fval", res.get('ob_fval'))
var1 = 1.5
print_float("浮動小数: 1.5", id(var1))
var2 = 8.5e+5
print_float("浮動小数: 8.5e+5", id(var2))
*出力
------------------------
name: 浮動小数: 1.5
addr: 0x106815a30
ob_refcnt: 3
ob_type: 0x106f534e0
型 <class 'float'>
ob_fval 1.5
------------------------
name: 浮動小数: 8.5e+5
addr: 0x1066aefb0
ob_refcnt: 3
ob_type: 0x106f534e0
型 <class 'float'>
ob_fval 850000.0
オブジェクトのアドレスからPyFloatObjectを表現する
Cで記載されたPyFloatObjectはctypes.Structureを継承したクラスで表現することが可能です。
# https://github.com/python/cpython/blob/3.13/Include/cpython/floatobject.h#L5
class PyFloatObject(ctypes.Structure):
_fields_ = [
("head", PyObject),
("ob_fval", ctypes.c_double),
]
idを使用して取得したオブジェクトのアドレスから、ctypes.Structureを継承したクラスにキャストすることが可能です。
obj = ctypes.cast(addr, ctypes.POINTER(PyFloatObject)).contents
res['ob_fval'] = obj.ob_fval
ob_fvalはfloat型なので、ここに実際の数値が格納されています。
PyLongObjectの探索
pythonの整数はPyLongObject構造体で表せます。
typedef struct _PyLongValue {
uintptr_t lv_tag; /* Number of digits, sign and flags */
digit ob_digit[1];
} _PyLongValue;
struct _longobject {
PyObject_HEAD
_PyLongValue long_value;
};
pythonの整数の特徴として、無制限の桁を許可しています。
これを実現するためにlv_tagはdigitsの数と符号情報をもっています。
ob_digitはlv_tagで指定した数だけ拡張することができます。
サンプルコードと出力結果
サンプルコード
import ctypes, sys, struct
assert sys.version_info.major == 3
assert sys.version_info.minor == 13
assert sys.implementation.name == 'cpython'
assert sys._is_gil_enabled()
# _object
# 実際には何も PyObject として宣言されていないが、あらゆる Python オブジェクトへのポインタは PyObject* にキャストできる。
# これは手作業で実現した継承に相当する。
# 同様に、可変サイズの Python オブジェクトへのポインタは、さらに PyVarObject* にキャストできる。
# https://github.com/python/cpython/blob/3.13/Include/object.h
# GILが有効であることが前提である
class PyObject(ctypes.Structure):
_fields_ = [
("ob_refcnt", ctypes.c_ssize_t),
("ob_type", ctypes.c_void_p),
]
# PyLongObject
# https://github.com/python/cpython/blob/3.13/Include/cpython/longintrepr.h#L98
class PyLongObject(ctypes.Structure):
_fields_ = [
("head", PyObject),
# lv_tag
# 下位 2 ビット: 符号 0:正 1: Zero 2:負
# 3ビット目 “immortality(不滅)” フラグ用 現在未使用
# その他: digitsの数
("lv_tag", ctypes.c_void_p)
# 本当はこの後にdigitsが続くが可変のため、ここでの定義はしない
]
def inspect_base(addr):
# 指定のポインタをPyObjectの型にキャストする
obj = ctypes.cast(addr, ctypes.POINTER(PyObject)).contents
ob_refcnt = obj.ob_refcnt
ob_type = obj.ob_type
try:
type_obj = ctypes.cast(ob_type, ctypes.py_object).value
except Exception as e:
type_obj = f"<cannot cast to py_object: {e}>"
return {
"addr": hex(addr),
"ob_refcnt": ob_refcnt,
"ob_type": hex(ob_type),
"type_obj": type_obj
}
def inspect_int(addr):
res_base = inspect_base(addr)
assert res_base.get('type_obj') == int
obj = ctypes.cast(addr, ctypes.POINTER(PyLongObject)).contents
sign = obj.lv_tag & 0b11
flag = obj.lv_tag & 0b100 # 未使用
ndigits = obj.lv_tag >> 3
# digit の ctypes 型を決定
fmt_char = {1: 'B', 2: 'H', 4: 'I', 8: 'Q'}
digit_bytes = (sys.int_info.bits_per_digit + 7) // 8
if digit_bytes == 2:
digit_ctype = ctypes.c_uint16
elif digit_bytes == 4:
digit_ctype = ctypes.c_uint32
elif digit_bytes == 8:
digit_ctype = ctypes.c_uint64
else:
raise RuntimeError(f'unexpected digit_bytes {digit_bytes}')
digits = []
if ndigits > 0:
BufType = digit_ctype * ndigits
buf = BufType.from_address(addr+ctypes.sizeof(PyLongObject)) # 危険: アドレスが有効であることが前提
mv = memoryview(buf)
# struct.unpack_from は memoryview も受け取る
digits_raw = struct.unpack_from(f'{ndigits}{fmt_char.get(digit_bytes)}', mv, 0)
for b in digits_raw:
digits.append(f"0x{b:08x}")
dict_sign = {
0: "正",
1: "Zero",
2: "負",
}
res = {
"lv_tag": hex(obj.lv_tag),
"sign": dict_sign.get(sign),
"flag": flag,
"ndigits": ndigits,
"digit_bytes": digit_bytes,
"digits": digits
}
return res | res_base
def print_int(name, addr, indent=0):
res = inspect_int(addr)
print('------------------------')
print(" " * indent, "name:", name)
print(" " * indent, "addr:", res.get('addr'))
print(" " * indent, "ob_refcnt:", res.get('ob_refcnt'))
print(" " * indent, "ob_type:", res.get('ob_type'))
print(" " * indent, "型:", res.get('type_obj'))
print(" " * indent, "lv_tag:", res.get('lv_tag'))
print(" " * indent, "sign:", res.get('sign'))
print(" " * indent, "ndigits:", res.get('ndigits'))
print(" " * indent, "digits:", res.get('digits'))
var1 = 0
print_int("整数: 0", id(var1))
var2 = 1
print_int("整数: 1", id(var2))
var3 = -1
print_int("整数: -1", id(var3))
var4 = 1024
print_int("整数: 1024", id(var4))
var5 = 1 << 30
print_int(f"整数: {var5}", id(var5))
var6 = 2147483647
print_int(f"整数: 2147483647", id(var6))
var7 = 4294967295
print_int(f"整数: 4294967295", id(var7))
var8 = 1 << (30*2)
print_int(f"整数: {var8}", id(var8))
出力結果
------------------------
name: 整数: 0
addr: 0x1027c74a0
ob_refcnt: 4294967295
ob_type: 0x10279eec0
型: <class 'int'>
lv_tag: 0x1
sign: Zero
ndigits: 0
digits: []
------------------------
name: 整数: 1
addr: 0x1027c74c0
ob_refcnt: 4294967295
ob_type: 0x10279eec0
型: <class 'int'>
lv_tag: 0x8
sign: 正
ndigits: 1
digits: ['0x00000001']
------------------------
name: 整数: -1
addr: 0x1027c7480
ob_refcnt: 4294967295
ob_type: 0x10279eec0
型: <class 'int'>
lv_tag: 0xa
sign: 負
ndigits: 1
digits: ['0x00000001']
------------------------
name: 整数: 1024
addr: 0x101ef7450
ob_refcnt: 3
ob_type: 0x10279eec0
型: <class 'int'>
lv_tag: 0x8
sign: 正
ndigits: 1
digits: ['0x00000400']
------------------------
name: 整数: 1073741824
addr: 0x10205f2f0
ob_refcnt: 3
ob_type: 0x10279eec0
型: <class 'int'>
lv_tag: 0x10
sign: 正
ndigits: 2
digits: ['0x00000000', '0x00000001']
------------------------
name: 整数: 2147483647
addr: 0x10205f3b0
ob_refcnt: 3
ob_type: 0x10279eec0
型: <class 'int'>
lv_tag: 0x10
sign: 正
ndigits: 2
digits: ['0x3fffffff', '0x00000001']
------------------------
name: 整数: 4294967295
addr: 0x10205c3f0
ob_refcnt: 3
ob_type: 0x10279eec0
型: <class 'int'>
lv_tag: 0x10
sign: 正
ndigits: 2
digits: ['0x3fffffff', '0x00000003']
------------------------
name: 整数: 1152921504606846976
addr: 0x1021611a0
ob_refcnt: 3
ob_type: 0x10279eec0
型: <class 'int'>
lv_tag: 0x18
sign: 正
ndigits: 3
digits: ['0x00000000', '0x00000000', '0x00000001']
オブジェクトのアドレスからPyLongObjectを表現する
Cで記載されたPyLongObjectはctypes.Structureを継承したクラスで表現することが可能です。
class PyLongObject(ctypes.Structure):
_fields_ = [
("head", PyObject),
# lv_tag
# 下位 2 ビット: 符号 0:正 1: Zero 2:負
# 3ビット目 “immortality(不滅)” フラグ用 現在未使用
# その他: digitsの数
("lv_tag", ctypes.c_void_p)
# 本当はこの後にdigitsが続くが可変のため、ここでの定義はしない
]
本来はlv_tagの後にdigit型が1つ以上、存在します。digitの取得方法については後述します。
idを使用して取得したオブジェクトのアドレスから、ctypes.Structureを継承したクラスにキャストすることが可能です。
obj = ctypes.cast(addr, ctypes.POINTER(PyLongObject)).contents
lv_tagの確認
lv_tagはビットの場所により符号、immortalityフラグ情報、digitsの数を表現します。
| ビットの場所 | 説明 |
|---|---|
| 1-2bit | 符号 0:正 1: Zero 2:負 |
| 3bit | immortalityフラグ情報(現在未使用) |
| 4bit- | digitsの数 |
これは以下の実装で取得することが可能です
sign = obj.lv_tag & 0b11
flag = obj.lv_tag & 0b100 # 未使用
ndigits = obj.lv_tag >> 3
符号についてはvar1 = 0、var2 = 1とvar3 = -1の出力結果を比較することで0と正と負で値が変化することが確認することができます。
digitsの確認
digitsはプラットフォームに応じて 30 ビットまたは 15 ビットの桁ごとに構成されます。
これが30ビットごとか、15ビットごとになるかはsys.int_info.bits_per_digitで確認することができます。
仮にこれが30ビットとした場合、digitはuint32に格納されて、30ビットのみ有効となります。
30ビットを超える数値の場合、digitsは拡張されます。
この数は、lv_tagのndigitsで確認できます。
digitをuint32の型でndigits個文取得するサンプルは以下のようになります。
fmt_char = {1: 'B', 2: 'H', 4: 'I', 8: 'Q'}
digit_bytes = (sys.int_info.bits_per_digit + 7) // 8
if digit_bytes == 2:
digit_ctype = ctypes.c_uint16
elif digit_bytes == 4:
digit_ctype = ctypes.c_uint32
elif digit_bytes == 8:
digit_ctype = ctypes.c_uint64
else:
raise RuntimeError(f'unexpected digit_bytes {digit_bytes}')
digits = []
if ndigits > 0:
BufType = digit_ctype * ndigits
buf = BufType.from_address(addr+ctypes.sizeof(PyLongObject)) # 危険: アドレスが有効であることが前提
mv = memoryview(buf)
# struct.unpack_from は memoryview も受け取る
digits_raw = struct.unpack_from(f'{ndigits}{fmt_char.get(digit_bytes)}', mv, 0)
for b in digits_raw:
digits.append(f"0x{b:08x}")
実際の数値がdigitsには以下のように格納されることが出力結果から確認できます。
| 値 | digits |
|---|---|
| 0 | [] *signがZero |
| 1 | [0x00000001] *signが正 |
| -1 | [0x00000001] *signが負 |
| 1024 | ['0x00000400'] |
| 30bitで表現できない数 1073741824 |
['0x00000000', '0x00000001'] |
| 2147483647 | ['0x3fffffff', '0x00000001'] |
| 4294967295 | ['0x3fffffff', '0x00000003'] |
| 60bitで表現できない数 1152921504606846976 |
['0x00000000', '0x00000000', '0x00000001'] |
このように30ビットごと分割してdigitsに格納するため、無制限の桁を表現することが可能になっています。
PyBytesObjectの探索
pythonのbytes型はPyBytesObject構造体で表せます。
サンプルコードと出力結果
サンプルコード
import ctypes, sys, struct
assert sys.version_info.major == 3
assert sys.version_info.minor == 13
assert sys.implementation.name == 'cpython'
assert sys._is_gil_enabled()
# _object
# 実際には何も PyObject として宣言されていないが、あらゆる Python オブジェクトへのポインタは PyObject* にキャストできる。
# これは手作業で実現した継承に相当する。
# 同様に、可変サイズの Python オブジェクトへのポインタは、さらに PyVarObject* にキャストできる。
# https://github.com/python/cpython/blob/3.13/Include/object.h
# GILが有効であることが前提である
class PyObject(ctypes.Structure):
_fields_ = [
("ob_refcnt", ctypes.c_ssize_t),
("ob_type", ctypes.c_void_p),
]
# PyVarObject
# https://github.com/python/cpython/blob/3.13/Include/object.h#L224
class PyVarObject(ctypes.Structure):
_fields_ = [
("ob_base", PyObject),
("ob_size", ctypes.c_ssize_t),
]
# https://github.com/python/cpython/blob/3.13/Include/cpython/bytesobject.h#L5
class PyBytesObject(ctypes.Structure):
_fields_ = [
("head", PyVarObject),
# ob_shash is the hash of the byte string or -1 if not computed yet.
# python3.11で非推奨
("ob_shash", ctypes.c_ssize_t),
# この後にchar ob_svalが続く
]
def inspect_base(addr):
# 指定のポインタをPyObjectの型にキャストする
obj = ctypes.cast(addr, ctypes.POINTER(PyObject)).contents
ob_refcnt = obj.ob_refcnt
ob_type = obj.ob_type
try:
type_obj = ctypes.cast(ob_type, ctypes.py_object).value
except Exception as e:
type_obj = f"<cannot cast to py_object: {e}>"
return {
"addr": hex(addr),
"ob_refcnt": ob_refcnt,
"ob_type": hex(ob_type),
"type_obj": type_obj
}
def inspect_byte(addr):
res_base = inspect_base(addr)
assert res_base.get('type_obj') == bytes
obj = ctypes.cast(addr, ctypes.POINTER(PyBytesObject)).contents
ob_size = obj.head.ob_size
ob_shash = obj.ob_shash
data = []
if ob_size > 0:
BufType = ctypes.c_ubyte * ob_size
buf = BufType.from_address(addr+ctypes.sizeof(PyBytesObject)) # 危険: アドレスが有効であることが前提
mv = memoryview(buf)
# struct.unpack_from は memoryview も受け取る
raw = struct.unpack_from(f'{ob_size}B', mv, 0)
for b in raw:
data.append(f"0x{b:02x}")
res = {
"ob_size": ob_size,
"ob_shash": ob_shash,
"ob_sval": data
}
return res | res_base
def print_bytes(name, addr, indent=0):
res = inspect_byte(addr)
print('------------------------')
print(" " * indent, "name:", name)
print(" " * indent, "addr:", res.get('addr'))
print(" " * indent, "ob_refcnt:", res.get('ob_refcnt'))
print(" " * indent, "ob_type:", res.get('ob_type'))
print(" " * indent, "型", res.get('type_obj'))
print(" " * indent, "ob_size", res.get('ob_size'))
print(" " * indent, "ob_shash", res.get('ob_shash'))
print(" " * indent, "ob_sval", res.get('ob_sval'))
var1 = b"\x01\x0A\x1F\xEF"
print_bytes("bytesデータA", id(var1))
var2 = b"\x01\x0A\x1F\xEE"
print_bytes("bytesデータB(Aと違う値)", id(var2))
var3 = b"\x01\x0A\x1F\xEF"
print_bytes("bytesデータC(Aと同じ値)", id(var3))
var4 = b""
print_bytes("bytesデータD(空)", id(var4))
出力結果
------------------------
name: bytesデータA
addr: 0x10761bcc0
ob_refcnt: 4
ob_type: 0x107c703c0
型 <class 'bytes'>
ob_size 4
ob_shash -4882734533440356415
ob_sval ['0x01', '0x0a', '0x1f', '0xef']
------------------------
name: bytesデータB(Aと違う値)
addr: 0x10761bde0
ob_refcnt: 4
ob_type: 0x107c703c0
型 <class 'bytes'>
ob_size 4
ob_shash -5159122674606314679
ob_sval ['0x01', '0x0a', '0x1f', '0xee']
------------------------
name: bytesデータC(Aと同じ値)
addr: 0x10761bcc0
ob_refcnt: 5
ob_type: 0x107c703c0
型 <class 'bytes'>
ob_size 4
ob_shash -4882734533440356415
ob_sval ['0x01', '0x0a', '0x1f', '0xef']
------------------------
name: bytesデータD(空)
addr: 0x107caa4c0
ob_refcnt: 4294967295
ob_type: 0x107c703c0
型 <class 'bytes'>
ob_size 0
ob_shash 0
ob_sval []
オブジェクトのアドレスからPyBytesObjectを表現する
Cで記載されたPyBytesObjectはctypes.Structureを継承したクラスで表現することが可能です。
class PyBytesObject(ctypes.Structure):
_fields_ = [
("head", PyVarObject),
# ob_shash is the hash of the byte string or -1 if not computed yet.
# python3.11で非推奨
("ob_shash", ctypes.c_ssize_t),
# この後にchar ob_svalが続く
]
ob_shashの、のちにob_svalがPyVarObject.ob_sizeの数だけ続きます。この取得方法については後述します。
idを使用して取得したオブジェクトのアドレスから、ctypes.Structureを継承したクラスにキャストすることが可能です。
obj = ctypes.cast(addr, ctypes.POINTER(PyBytesObject)).contents
ob_size = obj.head.ob_size
ob_shash = obj.ob_shash
ob_shashの確認
ob_shashはbytesの中身から計算されたハッシュ値が格納されます。
この値はvar1.__hash__()で取得した値と一致します。
また、同じプロセスにおいては、同じ内容の場合は一致することが出力結果から確認できます。
| データ | ob_shash | 説明 |
|---|---|---|
| b"\x01\x0A\x1F\xEF" | -4882734533440356415 | 基準データ |
| b"\x01\x0A\x1F\xEE" | -5159122674606314679 | 基準データと違う内容の場合、ob_shashは異なる |
| b"\x01\x0A\x1F\xEF" | -4882734533440356415 | 基準データと同じデータの場合、ob_shashは一致する |
| b"" | 0 | 空の場合はob_shashは0となる |
なお、ob_shashはPython3.11以降では非推奨のフィールドとなっています。
ob_svalの確認
Pythonで確認するにはob_shashの後から、PyVarObject.ob_sizeバイト数を取得するようにします。
data = []
if ob_size > 0:
BufType = ctypes.c_ubyte * ob_size
buf = BufType.from_address(addr+ctypes.sizeof(PyBytesObject)) # 危険: アドレスが有効であることが前提
mv = memoryview(buf)
# struct.unpack_from は memoryview も受け取る
raw = struct.unpack_from(f'{ob_size}B', mv, 0)
for b in raw:
data.append(f"0x{b:02x}")
PyASCIIObject/PyCompactUnicodeObject/PyUnicodeObjectの探索
pythonのunicode文字列型についてはPEP0393に規定されています。
unicodeでstr型を作成した場合、文字の内容と後述のcompact表現かどうかによって以下の3つの形式になります。
-
PyASCIIObject
- ASCII のみ(U+0000–U+007F)かつ compact表現の文字列
-
PyCompactUnicodeObject
- 非ASCIIを含む文字列で compact 表現のもの
-
PyUnicodeObject
- 非compactな文字列(レガシーオブジェクト)
compact表現というのは基本構造体の後に文字データが続く形式か否かです。
データ作成時にサイズと最大文字数が既知であるオブジェクトの場合はcompact表現になります。
str のサブクラスを作るなどした場合はcompact表現ではなくなります。
以下が、PyASCIIObject/PyCompactUnicodeObject/PyUnicodeObjectのCでの構造体になります。
typedef struct {
PyObject_HEAD
Py_ssize_t length; /* Number of code points in the string */
Py_hash_t hash; /* Hash value; -1 if not set */
struct {
unsigned int interned:2;
unsigned int kind:3;
unsigned int compact:1;
unsigned int ascii:1;
unsigned int statically_allocated:1;
unsigned int :24;
} state;
} PyASCIIObject;
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding the
* terminating \0. */
char *utf8; /* UTF-8 representation (null-terminated) */
} PyCompactUnicodeObject;
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;
PyCompactUnicodeObjectとPyUnicodeObjectはヘッダとしてPyASCIIObjectを保持することになっています。
PyASCIIObjectの保持するcompact、asciiの組み合わせで、そのオブジェクトがPyASCIIObjectかPyCompactUnicodeObjectかPyUnicodeObjectの判断が可能です
stateの概要は以下の通りです。
| フィールド名 | 幅(bit) | 説明 |
|---|---|---|
| interned | 2 | 0: 非インターン / 1: インターン / 2: インターンかつイモータル / 3: インターン+イモータル+静的 参照 |
| kind | 3 | 1: Py_UCS1 (8 bits, unsigned) 2: Py_UCS2 (16 bits, unsigned) 4: Py_UCS4 (32 bits, unsigned) |
| compact | 1 | 1: コンパクト表現(ヘッダ直後に文字データ) / 0: レガシー表現(別領域へポインタ) |
| ascii | 1 | 1: 全文字がASCII(U+0000–007F) |
| statically_allocated | 1 | 1: 静的領域に確保(解放しない)* ビルド時に埋め込まれた静的文字列などの扱い。 |
| (予約) | 24 | 予約(未使用) |
以下のサンプルコードはPyASCIIObject/PyCompactUnicodeObject/PyUnicodeObjectを検証したものになります。
サンプルコードと出力結果
サンプルコード
import ctypes, sys, struct
assert sys.version_info.major == 3
assert sys.version_info.minor == 13
assert sys.implementation.name == 'cpython'
assert sys._is_gil_enabled()
# _object
# 実際には何も PyObject として宣言されていないが、あらゆる Python オブジェクトへのポインタは PyObject* にキャストできる。
# これは手作業で実現した継承に相当する。
# 同様に、可変サイズの Python オブジェクトへのポインタは、さらに PyVarObject* にキャストできる。
# https://github.com/python/cpython/blob/3.13/Include/object.h
# GILが有効であることが前提である
class PyObject(ctypes.Structure):
_fields_ = [
("ob_refcnt", ctypes.c_ssize_t),
("ob_type", ctypes.c_void_p),
]
# https://github.com/python/cpython/blob/3.13/Include/cpython/unicodeobject.h#L50
class PyASCIIObject(ctypes.Structure):
_fields_ = [
("head", PyObject),
("length", ctypes.c_ssize_t),
("hash", ctypes.c_ssize_t),
("interned", ctypes.c_uint, 2),
("kind", ctypes.c_uint, 3),
("compact", ctypes.c_uint, 1),
("ascii", ctypes.c_uint, 1),
("statically_allocated", ctypes.c_uint, 1),
("_pad", ctypes.c_uint, 24),
]
class PyCompactUnicodeObject(ctypes.Structure):
_fields_ = [
("_base", PyASCIIObject),
("utf8_length", ctypes.c_ssize_t),
("utf8", ctypes.c_void_p),
]
class PyUnicodeObject(ctypes.Structure):
_fields_ = [
("_base", PyCompactUnicodeObject),
("data_any", ctypes.c_void_p), # union data
]
def inspect_base(addr):
# 指定のポインタをPyObjectの型にキャストする
obj = ctypes.cast(addr, ctypes.POINTER(PyObject)).contents
ob_refcnt = obj.ob_refcnt
ob_type = obj.ob_type
try:
type_obj = ctypes.cast(ob_type, ctypes.py_object).value
except Exception as e:
type_obj = f"<cannot cast to py_object: {e}>"
return {
"addr": hex(addr),
"ob_refcnt": ob_refcnt,
"ob_type": hex(ob_type),
"type_obj": type_obj
}
def inspect_unicode(addr):
SSTATE_NAMES = {
0: "NOT_INTERNED", 1: "INTERNED",
2: "INTERNED_IMMORTAL", 3: "INTERNED_IMMORTAL_STATIC",
}
res_base = inspect_base(addr)
assert issubclass(res_base.get('type_obj'), str)
obj = ctypes.cast(addr, ctypes.POINTER(PyASCIIObject)).contents
compact = obj.compact
ascii = obj.ascii
length = obj.length
kind = obj.kind
res = {
"hash": obj.hash,
"statically_allocated": obj.statically_allocated,
"interned": SSTATE_NAMES.get(obj.interned),
"compact": compact,
"ascii": ascii,
"kind": kind,
"length": length,
}
# 形に応じてデータ開始アドレスを決める
if compact and ascii:
# compact ASCII: ヘッダ直後がデータ
data_addr = addr + ctypes.sizeof(PyASCIIObject)
elif compact and not ascii:
# compactの場合はPyCompactUnicodeObjectの直後にデータが存在する
data_addr = addr + ctypes.sizeof(PyCompactUnicodeObject)
compact_obj = ctypes.cast(addr, ctypes.POINTER(PyCompactUnicodeObject)).contents
res['utf8'] = compact_obj.utf8
res['utf8_length'] = compact_obj.utf8_length
else:
# legacy(主にサブクラス)
# 別の領域にデータがある
legacy_obj = ctypes.cast(addr, ctypes.POINTER(PyUnicodeObject)).contents
data_addr = legacy_obj.data_any
# 要素幅(バイト/コードポイント)
if kind == 1:
Elem = ctypes.c_uint8
elif kind == 2:
Elem = ctypes.c_uint16
elif kind == 4:
Elem = ctypes.c_uint32
else:
raise RuntimeError(f"unexpected kind={kind}")
fmt_char = {1: 'B', 2: 'H', 4: 'I'}[kind] # 1/2/4 バイト符号なし整数
BufType = Elem * length
buf = BufType.from_address(data_addr) # 危険: アドレスが有効であることが前提
mv = memoryview(buf)
# struct.unpack_from は memoryview も受け取る
data_array = struct.unpack_from(f'{length}{fmt_char}', mv, 0)
display_data = []
for b in data_array:
disp_b = {1: f"0x{b:02x}", 2: f"0x{b:04x}", 4: f"0x{b:08x}"}[kind]
display_data.append(disp_b)
res["data"] = display_data
return res | res_base
def print_unicode(name, addr, indent=0):
res = inspect_unicode(addr)
print('------------------------')
print(" " * indent, "name:", name)
print(" " * indent, "addr:", res.get('addr'))
print(" " * indent, "ob_refcnt:", res.get('ob_refcnt'))
print(" " * indent, "ob_type:", res.get('ob_type'))
print(" " * indent, "型:", res.get('type_obj'))
print(" " * indent, "length:", res.get('length'))
print(" " * indent, "hash:", res.get('hash'))
print(" " * indent, "interned:", res.get('interned'))
print(" " * indent, "kind:", res.get('kind'))
print(" " * indent, "compact:", res.get('compact'))
print(" " * indent, "ascii:", res.get('ascii'))
print(" " * indent, "statically_allocated:", res.get('statically_allocated'))
print(" " * indent, "utf8:", res.get('utf8'))
print(" " * indent, "utf8_length:", res.get('utf8_length'))
print(" " * indent, "data:", res.get('data'))
class S(str):
pass
# kind=1になる
var1 = '12345abcd'
print_unicode(f"compact表現のascii: {var1}", id(var1))
# kind=2になる
var2 = '12345あabcd'
print_unicode(f"compact表現の非ascii(Py_UCS2): {var2}", id(var2))
# kind=4になる
var3 = '12345😊abcd'
print_unicode(f"compact表現の非ascii(Py_UCS3): {var3}", id(var3))
# compact表現ではないので別領域から文字のデータをとる
var4 = S('xxxxx')
print_unicode(f"legacy表現: {var4}", id(var4))
# 以下の結果はvar1のhashと一致する
var5 = '12345abcd'
print_unicode(f"var1とハッシュ値が同じか確認: {var5}", id(var5))
print("var5.__hash__()の結果", var5.__hash__())
# 空文字
# interned:INTERNED_IMMORTAL_STATICとstatically_allocated=1を確認
var6 = ''
print_unicode("空文字", id(var6))
# interned:INTERNED_IMMORTAL_STATICとstatically_allocated=1を確認
var7 = 'a'
print_unicode(f"ascii1文字A {var7}", id(var7))
# interned:INTERNED_IMMORTAL_STATICとstatically_allocated=1を確認
var8 = '+'
print_unicode(f"ascii1文字B {var8}", id(var8))
var9 = "".join(['12345','abcd'])
print_unicode(f"var1と同じ内容をjoinで作る {var9}", id(var9))
assert var1 == var9
assert var1 is not var9
var10 = sys.intern(var9)
print_unicode(f"var9をinternする {var10}", id(var10))
assert var1 == var10
assert var1 is var10
# utf8とutf8_lengthに値を格納する例
# PyUnicode_AsUTF8() / PyUnicode_AsUTF8AndSize() が呼ばれたときに UTF-8 表現が生成・キャッシュされ、utf8 と utf8_length に入ります
# 以下のコードはvar2に対してPyUnicode_AsUTF8を実行した例になります
PyUnicode_AsUTF8 = ctypes.pythonapi.PyUnicode_AsUTF8
PyUnicode_AsUTF8.restype = ctypes.c_char_p
PyUnicode_AsUTF8.argtypes = [ctypes.py_object]
ptr = PyUnicode_AsUTF8(var2)
print_unicode(f"compact表現の非asciiに対してPyUnicode_AsUTF8を実施: {var2}", id(var2))
出力結果
------------------------
name: compact表現のascii: 12345abcd
addr: 0x10abc45f0
ob_refcnt: 3
ob_type: 0x10b200c10
型: <class 'str'>
length: 9
hash: 2615342146504599036
interned: INTERNED
kind: 1
compact: 1
ascii: 1
statically_allocated: 0
utf8: None
utf8_length: None
data: ['0x31', '0x32', '0x33', '0x34', '0x35', '0x61', '0x62', '0x63', '0x64']
------------------------
name: compact表現の非ascii(Py_UCS2): 12345あabcd
addr: 0x10aa95470
ob_refcnt: 3
ob_type: 0x10b200c10
型: <class 'str'>
length: 10
hash: 4408673876641812804
interned: NOT_INTERNED
kind: 2
compact: 1
ascii: 0
statically_allocated: 0
utf8: None
utf8_length: 0
data: ['0x0031', '0x0032', '0x0033', '0x0034', '0x0035', '0x3042', '0x0061', '0x0062', '0x0063', '0x0064']
------------------------
name: compact表現の非ascii(Py_UCS3): 12345😊abcd
addr: 0x10ab1c650
ob_refcnt: 3
ob_type: 0x10b200c10
型: <class 'str'>
length: 10
hash: 3692057203771936543
interned: NOT_INTERNED
kind: 4
compact: 1
ascii: 0
statically_allocated: 0
utf8: None
utf8_length: 0
data: ['0x00000031', '0x00000032', '0x00000033', '0x00000034', '0x00000035', '0x0001f60a', '0x00000061', '0x00000062', '0x00000063', '0x00000064']
------------------------
name: legacy表現: xxxxx
addr: 0x10abd4350
ob_refcnt: 1
ob_type: 0x7fb36e034020
型: <class '__main__.S'>
length: 5
hash: -5889910096978768055
interned: NOT_INTERNED
kind: 1
compact: 0
ascii: 1
statically_allocated: 0
utf8: None
utf8_length: None
data: ['0x78', '0x78', '0x78', '0x78', '0x78']
------------------------
name: var1とハッシュ値が同じか確認: 12345abcd
addr: 0x10abc45f0
ob_refcnt: 4
ob_type: 0x10b200c10
型: <class 'str'>
length: 9
hash: 2615342146504599036
interned: INTERNED
kind: 1
compact: 1
ascii: 1
statically_allocated: 0
utf8: None
utf8_length: None
data: ['0x31', '0x32', '0x33', '0x34', '0x35', '0x61', '0x62', '0x63', '0x64']
var5.__hash__()の結果 2615342146504599036
------------------------
name: 空文字
addr: 0x10b2217d8
ob_refcnt: 4294967295
ob_type: 0x10b200c10
型: <class 'str'>
length: 0
hash: 0
interned: INTERNED_IMMORTAL_STATIC
kind: 1
compact: 1
ascii: 1
statically_allocated: 1
utf8: None
utf8_length: None
data: []
------------------------
name: ascii1文字A a
addr: 0x10b22c0f8
ob_refcnt: 4294967295
ob_type: 0x10b200c10
型: <class 'str'>
length: 1
hash: -6101737322674053506
interned: INTERNED_IMMORTAL_STATIC
kind: 1
compact: 1
ascii: 1
statically_allocated: 1
utf8: None
utf8_length: None
data: ['0x61']
------------------------
name: ascii1文字B +
addr: 0x10b22b6d8
ob_refcnt: 4294967295
ob_type: 0x10b200c10
型: <class 'str'>
length: 1
hash: 5732640424058351956
interned: INTERNED_IMMORTAL_STATIC
kind: 1
compact: 1
ascii: 1
statically_allocated: 1
utf8: None
utf8_length: None
data: ['0x2b']
------------------------
name: var1と同じ内容をjoinで作る 12345abcd
addr: 0x10abac9f0
ob_refcnt: 1
ob_type: 0x10b200c10
型: <class 'str'>
length: 9
hash: -1
interned: NOT_INTERNED
kind: 1
compact: 1
ascii: 1
statically_allocated: 0
utf8: None
utf8_length: None
data: ['0x31', '0x32', '0x33', '0x34', '0x35', '0x61', '0x62', '0x63', '0x64']
------------------------
name: var9をinternする 12345abcd
addr: 0x10abc45f0
ob_refcnt: 5
ob_type: 0x10b200c10
型: <class 'str'>
length: 9
hash: 2615342146504599036
interned: INTERNED
kind: 1
compact: 1
ascii: 1
statically_allocated: 0
utf8: None
utf8_length: None
data: ['0x31', '0x32', '0x33', '0x34', '0x35', '0x61', '0x62', '0x63', '0x64']
------------------------
name: var9の単純参照ではinternになっていない 12345abcd
addr: 0x10abac9f0
ob_refcnt: 2
ob_type: 0x10b200c10
型: <class 'str'>
length: 9
hash: 2615342146504599036
interned: NOT_INTERNED
kind: 1
compact: 1
ascii: 1
statically_allocated: 0
utf8: None
utf8_length: None
data: ['0x31', '0x32', '0x33', '0x34', '0x35', '0x61', '0x62', '0x63', '0x64']
------------------------
name: compact表現の非asciiに対してPyUnicode_AsUTF8を実施: 12345あabcd
addr: 0x10aa95470
ob_refcnt: 3
ob_type: 0x10b200c10
型: <class 'str'>
length: 10
hash: 4408673876641812804
interned: NOT_INTERNED
kind: 2
compact: 1
ascii: 0
statically_allocated: 0
utf8: 4472899952
utf8_length: 12
data: ['0x0031', '0x0032', '0x0033', '0x0034', '0x0035', '0x3042', '0x0061', '0x0062', '0x0063', '0x0064']
オブジェクトのアドレスからPyASCIIObject/PyCompactUnicodeObject/PyUnicodeObjectを表現する
Cで記載されたPyASCIIObject/PyCompactUnicodeObject/PyUnicodeObject
はctypes.Structureを継承したクラスで表現することが可能です。
class PyASCIIObject(ctypes.Structure):
_fields_ = [
("head", PyObject),
("length", ctypes.c_ssize_t),
("hash", ctypes.c_ssize_t),
("interned", ctypes.c_uint, 2),
("kind", ctypes.c_uint, 3),
("compact", ctypes.c_uint, 1),
("ascii", ctypes.c_uint, 1),
("statically_allocated", ctypes.c_uint, 1),
("_pad", ctypes.c_uint, 24),
]
class PyCompactUnicodeObject(ctypes.Structure):
_fields_ = [
("_base", PyASCIIObject),
("utf8_length", ctypes.c_ssize_t),
("utf8", ctypes.c_void_p),
]
class PyUnicodeObject(ctypes.Structure):
_fields_ = [
("_base", PyCompactUnicodeObject),
("data_any", ctypes.c_void_p), # union data
]
idを使用して取得したオブジェクトのアドレスから、PyASCIIObjectに、まずキャストします。
その後、asciiとcompactの状態によって、必要に応じてキャストをおこないます。
- ascii=1 かつ compact=1の場合
- compact = 0の場合
obj = ctypes.cast(addr, ctypes.POINTER(PyASCIIObject)).contents
compact = obj.compact
ascii = obj.ascii
length = obj.length
kind = obj.kind
... 略
# 形に応じてデータ開始アドレスを決める
if compact and ascii:
# compact ASCII: ヘッダ直後がデータ
data_addr = addr + ctypes.sizeof(PyASCIIObject)
elif compact and not ascii:
# compactの場合はPyCompactUnicodeObjectの直後にデータが存在する
data_addr = addr + ctypes.sizeof(PyCompactUnicodeObject)
compact_obj = ctypes.cast(addr, ctypes.POINTER(PyCompactUnicodeObject)).contents
res['utf8'] = compact_obj.utf8
res['utf8_length'] = compact_obj.utf8_length
else:
# legacy(主にサブクラス)
# 別の領域にデータがある
legacy_obj = ctypes.cast(addr, ctypes.POINTER(PyUnicodeObject)).contents
data_addr = legacy_obj.data_any
文字データの取得例
文字データの開始アドレスはPyASCIIObject/PyCompactUnicodeObjectの場合は構造体の直後になり、PyCompactUnicodeObjectの場合はPyCompactUnicodeObject.data_anyが開始アドレスになります。
1文字の文字の長さはPyASCIIObject.kindによって可変となります。
| kind | 1文字のバイト数 |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 4 | 4 |
文字の長さはPyASCIIObject.lengthなので、文字データは開始アドレス〜PyASCIIObject.length * 1文字のバイト数分の範囲となります。
以下のようなコードで開始アドレスから文字データを取得することができます。
# 要素幅(バイト/コードポイント)
if kind == 1:
Elem = ctypes.c_uint8
elif kind == 2:
Elem = ctypes.c_uint16
elif kind == 4:
Elem = ctypes.c_uint32
else:
raise RuntimeError(f"unexpected kind={kind}")
fmt_char = {1: 'B', 2: 'H', 4: 'I'}[kind] # 1/2/4 バイト符号なし整数
BufType = Elem * length
buf = BufType.from_address(data_addr) # 危険: アドレスが有効であることが前提
mv = memoryview(buf)
# struct.unpack_from は memoryview も受け取る
data_array = struct.unpack_from(f'{length}{fmt_char}', mv, 0)
display_data = []
for b in data_array:
disp_b = {1: f"0x{b:02x}", 2: f"0x{b:04x}", 4: f"0x{b:08x}"}[kind]
display_data.append(disp_b)
res["data"] = display_data
出力例
| 変数の宣言方法 | length | kind | 文字データ |
|---|---|---|---|
| var1 = '12345abcd' | 9 | 1 | ['0x31', '0x32', '0x33', '0x34', '0x35', '0x61', '0x62', '0x63', '0x64'] |
| var2 = '12345あabcd' | 10 | 2 | '0x0031', '0x0032', '0x0033', '0x0034', '0x0035', '0x3042', '0x0061', '0x0062', '0x0063', '0x0064'] |
| var3 = '12345😊abcd' | 10 | 4 | ['0x00000031', '0x00000032', '0x00000033', '0x00000034', '0x00000035', '0x0001f60a', '0x00000061', '0x00000062', '0x00000063', '0x00000064'] |
hashの確認
hashはstrの中身から計算されたハッシュ値が格納されます。
この値はvar1.__hash__()で取得した値と一致します。
また、同じプロセスにおいては、同じ内容の場合は一致することが出力結果から確認できます。
| データ | hash | 説明 |
|---|---|---|
| var1 = '12345abcd' | 2615342146504599036 | 基準データ |
| var2 = '12345あabcd' | 4408673876641812804 | var1と異なる値 |
| var5 = '12345abcd' | 2615342146504599036 | var1と同じ値 |
internedとstatically_allocatedの確認
pythonには文字列にはInternedという概念があります。
インターン済み文字列は同じ値についてポインタの等価性(is)で比較できます。
このことにより、辞書や属性の検索を最適化するために使用されます。
また、空文字や"a"や"+"といった「1 文字の Latin-1 文字列」についてはプロセス起動時にシングルトンとして静的に登録されます。
internedとstatically_allocatedが出力例において、どのようになるかを確認します。
| 宣言方法 | interned | statically_ allocated |
説明 |
|---|---|---|---|
| var1 = '12345abcd' | INTERNED | 0 | asciiのリテラルを格納したケースだとインターン済み文字列になるケースがある |
| var2 = '12345あabcd' | NOT_INTERNED | 0 | 非asciiのリテラルを格納したケースだとインターン済み文字列とはならない |
| var6 = '' | INTERNED_IMMORTAL_STATIC | 1 | 初期化時にシングルトンとして静的に登録されている |
| var7 = 'a' | INTERNED_IMMORTAL_STATIC | 1 | 初期化時にシングルトンとして静的に登録されている |
| var8 = '+' | INTERNED_IMMORTAL_STATIC | 1 | 初期化時にシングルトンとして静的に登録されている |
| var9 = "".join(['12345','abcd']) | NOT_INTERNED | 0 | var1と同じ値であるが、joinで結合して作成した場合はインターン済み文字列にはならない var1と値は同じであるがポインタは異なる assert var1 == var9 assert var1 is not var9 |
| var10 = sys.intern(var9) | INTERNED | 0 | sys.internを使用した場合、インターン済み文字列になる。 var1と値とポインタが一致する assert var1 == var10 assert var1 is var10 |
utf8とutf8_lengthの確認
PyCompactUnicodeObjectの場合、utf8とutf8_lengthフィールドがあります。
しかし単純にvar2 = '12345あabcd'などでcompact表現の非asciiのオブジェクトを作ってもこれらの値は設定されません。
PyUnicode_AsUTF8() / PyUnicode_AsUTF8AndSize() が呼ばれたときに UTF-8 表現が生成・キャッシュされ、utf8 と utf8_length に入ります。
pythonでPyUnicode_AsUTF8() / PyUnicode_AsUTF8AndSize()を実行するには以下のようにします。
PyUnicode_AsUTF8 = ctypes.pythonapi.PyUnicode_AsUTF8
PyUnicode_AsUTF8.restype = ctypes.c_char_p
PyUnicode_AsUTF8.argtypes = [ctypes.py_object]
ptr = PyUnicode_AsUTF8(var2)
print_unicode(f"compact表現の非asciiに対してPyUnicode_AsUTF8を実施: {var2}", id(var2))
tuple, list, dict型のケース
後編で記載します。
Discussion