完全で完璧なWebページが取得できるpywebcopy
はじめに
スクレイピングを行う際、多くの場合、HTMLを取得するだけで十分です。
しかしながら、まれにCSSや画像などのHTMLから参照されているファイルも同時に取得したい場合があります。
Chromeの場合は、ファイル⇨ページを別名で保存にて完全なHTMLとして保存することができます。
同じようなことがpywebcopyを使用することでプログラム上で実現できます。
pywebcopyについて
pywebcopyはオフラインで表示するために、Webサイトの全部または一部をハードディスクにローカルにコピーするためのpythonのツールです。
GitHub上の最新はver7.0です。
pipでインストールできる最新はver6.3です。
今回はver6.3を使用した実験結果となります。
簡単なサンプル
url = "https://hotel.testplanisphere.dev/ja"
from pywebcopy import save_webpage
kwargs = {'project_name': 'some-fancy-name'}
save_webpage(
url=url,
project_folder='./downloads_sample1',
**kwargs
)
実行後に作成されるフォルダ
downloads_sample1
├── some-fancy-name
│ ├── hotel.testplanisphere.dev
│ │ ├── css
│ │ │ ├── "data:image
│ │ │ │ └── svg+xml,<svg xmlns='http:
│ │ │ │ └── www.w3.org
│ │ │ │ └── 2000
│ │ │ └── 1c0665e6__bootstrap.min.css
│ │ ├── dist
│ │ │ ├── 700c4d93__index.bundle.js
│ │ │ └── vendor
│ │ │ ├── 691c23fe__jquery-3.6.0.min.js
│ │ │ └── ff4d0680__bootstrap.bundle.min.js
│ │ └── ja
│ │ └── index.html
│ └── plausible.io
│ └── js
│ └── a20c9876__plausible.js
└── some-fancy-name.zip
some-fancy-name.zip
some-fancy-nameフォルダをzipで圧縮したファイル
downloads_sample1/some-fancy_name/hotel.testplanisphere.dev/ja/index.html
指定したページ。画像やCSSなどへの参照はローカルファイルのものに書き変わっており、ローカルのファイルをブラウザで開くことで、CSSなどが適用されていることが確認できます。
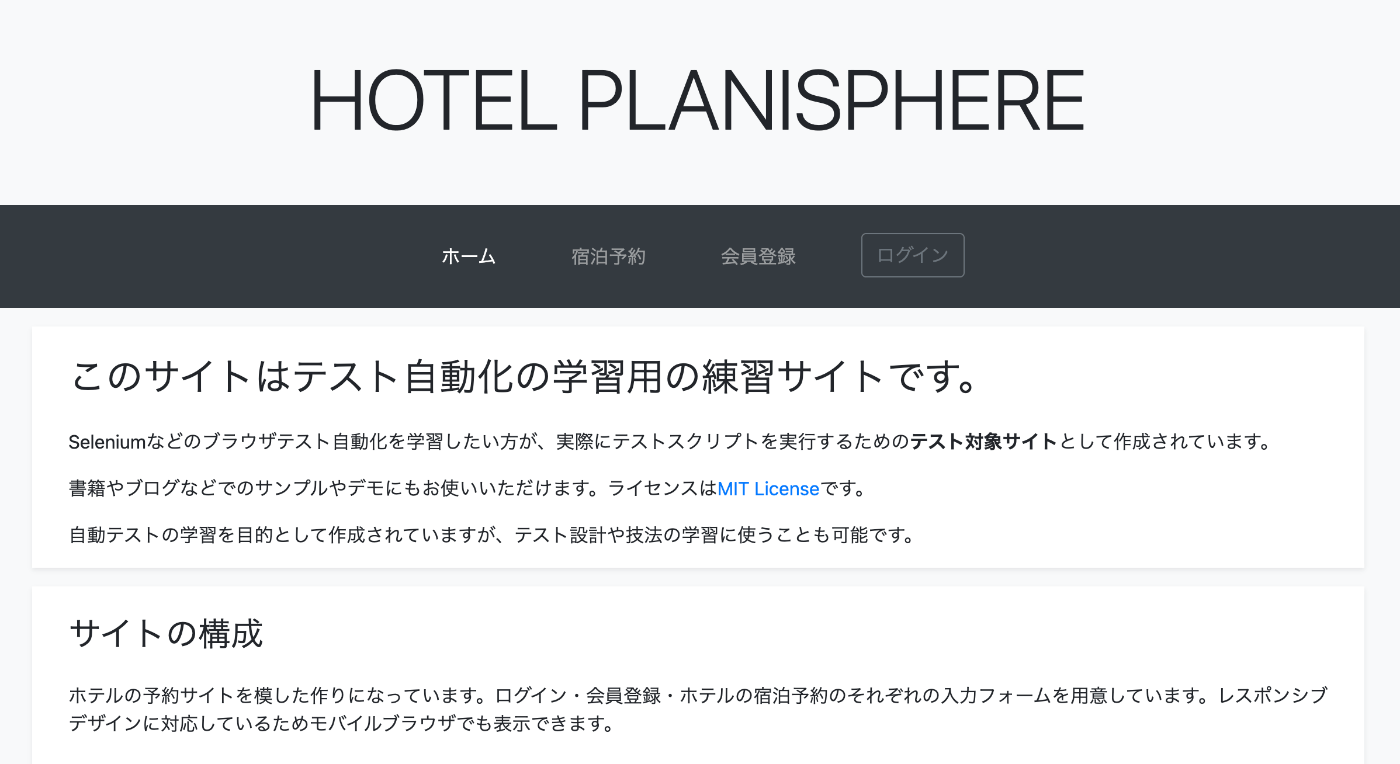
簡単なサンプルの問題
v6.3では以下のような問題が存在します。
- 日本語がコードとして保存される
- まれにハングする
- SSL検証で失敗するサイトが取得できない
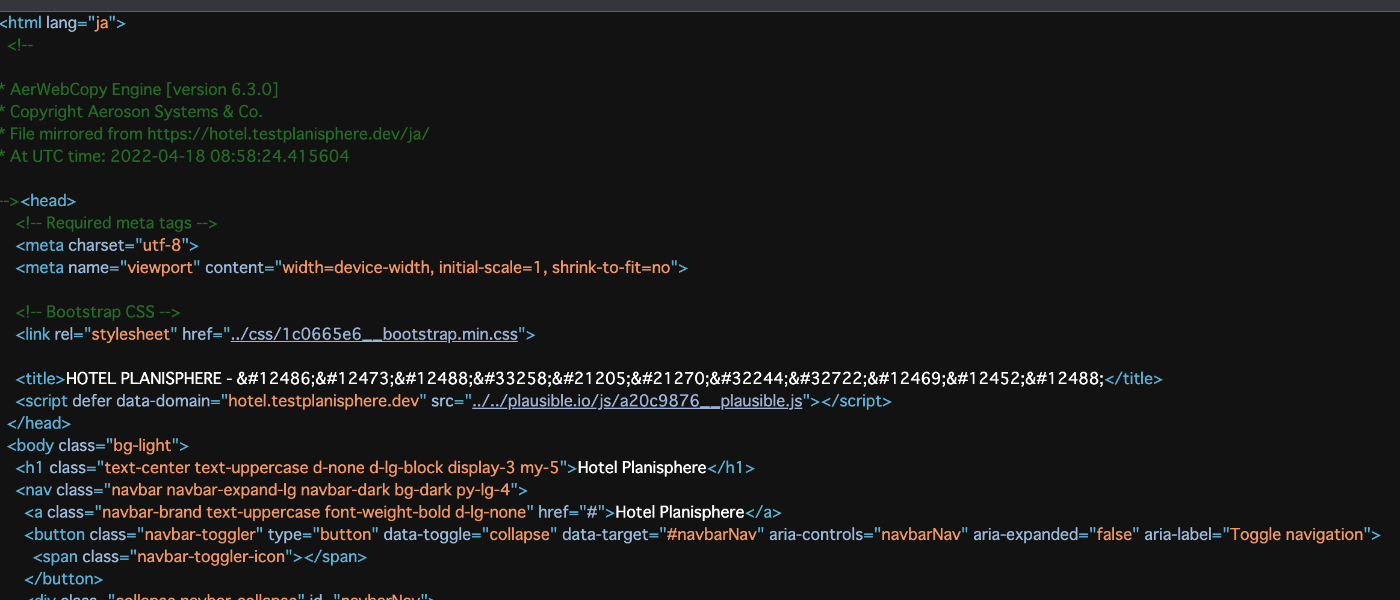
問題1:日本語がコードとして保存されている。
downloads_sample1/some-fancy_name/hotel.testplanisphere.dev/ja/index.htmlをテキストエディタで開くと日本語ではなく、コードになっていることが確認できます。
原因は、getroottree().writeでencodeを指定していないため、文字コードとして保存されているためです。
class WebPage(Parser, _ElementFactory):
# 略
def save_html(self, file_name=None, raw_html=False):
"""Saves the html of the page to a default or specified file.
:type file_name: str
:type raw_html: bool
:param file_name: path of the file to write the contents to
:param raw_html: whether write the unmodified html or the rewritten html
"""
LOGGER.info("Starting save_html Action on url: {!r}".format(self.utx.url))
if not file_name:
file_name = self.utx.file_path
# Create directories if necessary
if not os.path.exists(os.path.dirname(file_name)):
os.makedirs(os.path.dirname(file_name))
if raw_html:
src = getattr(self, '_source')
if not src or not hasattr(src, 'read'):
raise Exception(
"Parser source is not set yet!"
"Try .get() method or .set_source() method to feed the parser!"
)
with open(file_name, 'wb') as fh:
fh.write(self.get_source().read())
else:
if not getattr(self, '_parseComplete'):
self.parse()
root = self.root
if not hasattr(root, 'getroottree'):
raise ParseError("Tree is not being generated by parser!")
## ここでencodeを指定しないとコードとして保存される。
root.getroottree().write(file_name, method="html")
LOGGER.info("WebPage saved successfully to %s" % file_name)
問題2:ハングする場合がある
たまにプログラムが終了せずにハングしたような挙動になります。
上記のチケットの内容だとマルチスレッドのせいでハングするとあり、シングルスレッドにすれば改善するとあります。
しかし、チケットの内容通り対応してもハングは改善しないケースがあります。
これは、内部で使用しているrequests.getにてタイムアウトを指定していないためです。
タイムアウトを指定しない場合のrequestはページによっては永遠に待ち続けることになります。
問題3:SSL検証で失敗するサイトが取得できない
SSLの認証が不適切なサイトでエラーが発生します。
これは内部でrequestsを使用しているため、規定ではSSLの検証を行うためです。このため、このSSLの検証に失敗するサイトではエラーが発生して動作しません。
これを回避するには検証を無視する必要があります。
上記の問題を改善したコード
url = "https://hotel.testplanisphere.dev/ja"
import errno
from xml.etree.ElementTree import ParseError
from pywebcopy import WebPage
import logging
import os
from pywebcopy.configs import SESSION
from pywebcopy.configs import config
from pywebcopy.core import is_allowed
from shutil import copyfileobj
from mimetypes import guess_all_extensions
LOGGER = logging.getLogger("webpage")
# 問題3:SSLの検証を無効とする
SESSION.verify = False
# WebPageを継承して問題が発生しないように修正する
class EncodingWebPage(WebPage):
def __init__(self, **kwargs):
super().__init__(**kwargs)
def save_assets(self):
"""Save only the linked files to the disk."""
if not self.elements:
LOGGER.error("No elements found for downloading!")
return
LOGGER.info("Starting save_assets Action on url: {!r}".format(self.utx.url))
elms = list(self.elements)
LOGGER.log(100, "Queueing download of <%d> asset files." % len(elms))
error_cnt = 0
for elem in elms:
# 問題2:5秒でタイムアウトするようにする
EncodingWebPage.elem_download_file(elem, 5)
def save_html(self, file_name=None, raw_html=False):
"""Saves the html of the page to a default or specified file.
:type file_name: str
:type raw_html: bool
:param file_name: path of the file to write the contents to
:param raw_html: whether write the unmodified html or the rewritten html
"""
LOGGER.info("Starting save_html Action on url: {!r}".format(self.utx.url))
if not file_name:
file_name = self.utx.file_path
# Create directories if necessary
if not os.path.exists(os.path.dirname(file_name)):
os.makedirs(os.path.dirname(file_name))
if raw_html:
src = getattr(self, "_source")
if not src or not hasattr(src, "read"):
raise Exception(
"Parser source is not set yet!"
"Try .get() method or .set_source() method to feed the parser!"
)
with open(file_name, "wb") as fh:
fh.write(self.get_source().read())
else:
if not getattr(self, "_parseComplete"):
self.parse()
root = self.root
if not hasattr(root, "getroottree"):
raise ParseError("Tree is not being generated by parser!")
# 問題1:エンコードを指定する
root.getroottree().write(file_name, method="html", encoding=self.encoding)
LOGGER.info("WebPage saved successfully to %s" % file_name)
print("file_name:", file_name)
return file_name
def elem_download_file(elem, timeout):
"""Retrieves the file from the internet.
Its a minimal and verbose version of the function
present the core module.
*Note*: This needs `url` and `file_path` attributes to be present.
"""
file_path = elem.file_path
file_ext = os.path.splitext(file_path)[1]
url = elem.url
assert file_path, "Download location needed to be specified!"
assert isinstance(file_path, str), "Download location must be a string!"
assert isinstance(url, str), "File url must be a string!"
if os.path.exists(file_path):
if not config["over_write"]:
LOGGER.info("File already exists at location: %r" % file_path)
return
else:
#: Make the directories
try:
os.makedirs(os.path.dirname(file_path))
except OSError as e:
if e.errno == errno.EEXIST:
pass
req = SESSION.get(url, stream=True, timeout=timeout)
req.raw.decode_content = True
if req is None or not req.ok:
LOGGER.error(
"Failed to load the content of file %s from %s" % (file_path, url)
)
return
#: A dynamic file type check is required to take in context of
#: server generated files like e.g. images. These types of file urls
#: doesn't necessarily include a file extension. Thus a dynamic guess
#: list is prepared a all the guesses are checked if they hold true
#: First check if the extension present in the url is allowed or not
if not is_allowed(file_ext):
mime_type = req.headers.get("content-type", "").split(";", 1)[0]
#: Prepare a guess list of extensions
file_suffixes = guess_all_extensions(mime_type, strict=False) or []
#: Do add the defaults if present
if elem.default_suffix:
file_suffixes.extend(["." + elem.default_suffix])
# now check again
for ext in file_suffixes:
if is_allowed(ext):
file_ext = ext
break
else:
LOGGER.error(
"File of type %r at url %r is not allowed "
"to be downloaded!" % (file_ext, url)
)
return
try:
# case the function will catch it and log it then return None
LOGGER.info("Writing file at location %s" % file_path)
with open(file_path, "wb") as f:
#: Actual downloading
copyfileobj(req.raw, f)
f.write(elem._watermark(url))
except OSError:
LOGGER.critical(
"Download failed for the file of "
"type %s to location %s" % (file_ext, file_path)
)
except Exception as e:
LOGGER.critical(e)
else:
LOGGER.info(
"File of type %s written successfully " "to %s" % (file_ext, file_path)
)
# 修正したClassを使用してダウンロード
wp = EncodingWebPage()
wp.path = "download_sample2"
wp.get(url)
# cssなどの取得
wp.save_assets()
# htmlの取得
local_html = wp.save_html()
wp.shutdown(10)
print(local_html)
以下のように文字コードではなく、日本語が保存されている。
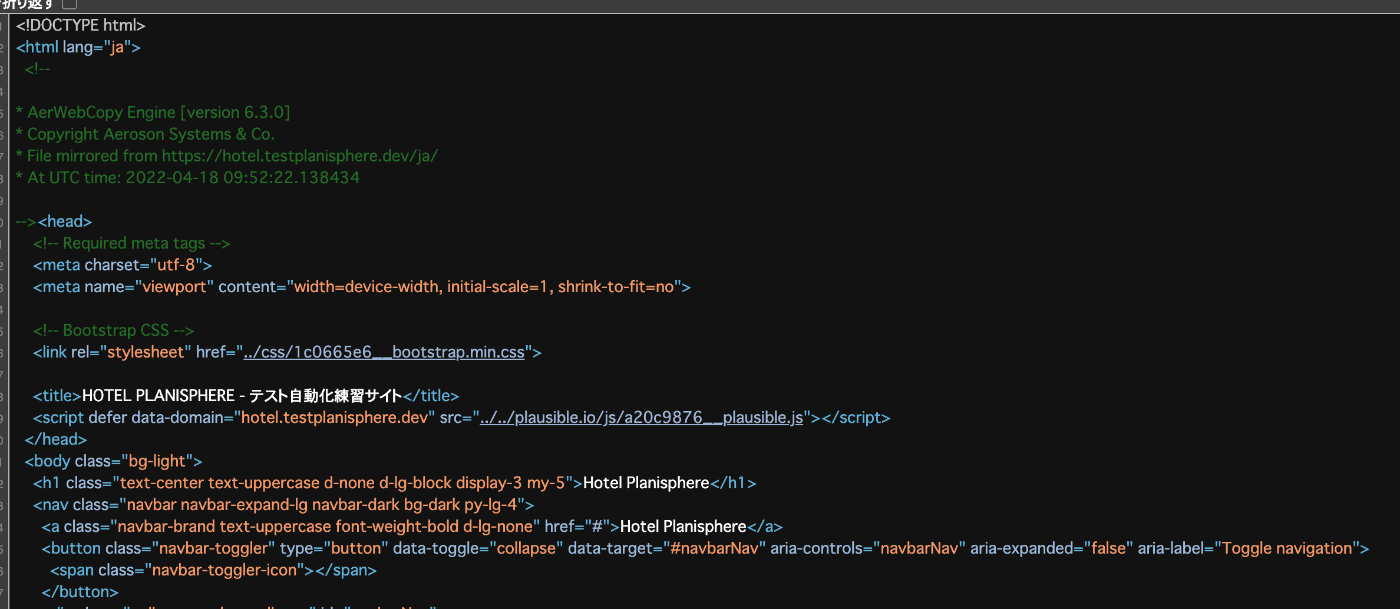
動的に作成されるページの取得方法
pywebcopyはrequestsで実装しているため、クライアントサイドでDOMを構築している場合、その内容は反映されません。
その場合はseleniumを使用して操作した結果のhtmlをローカルに保存しておき、そのローカルファイルをもとにpywebcopyを使用することで対応できます。
まず、以下のようにseleniumを起動します。
docker run --rm -d -p 14444:4444 --name seleniumA
その後、seleniumをpipでインストールします。
最後に次のスクリプトを実行します。
from selenium import webdriver
from selenium.webdriver.common.by import By
# Seleniumを使用してWebPageを操作してHTMLをローカルに保存
tmp_path = "tmp.html"
selenium_url = "http://127.0.0.1:14444/wd/hub"
chromeOptions = webdriver.ChromeOptions()
chromeOptions.add_argument("--headless")
driver = webdriver.Remote(selenium_url, options=chromeOptions)
driver.get(url)
# TODO seleniumで任意の操作を行って対象のタグが表示されるのを待機する
element = driver.find_element(by=By.TAG_NAME, value="html")
with open(tmp_path, "w") as f:
f.write(element.get_attribute("outerHTML"))
driver.quit()
# 修正したClassを使用してダウンロード
wp = EncodingWebPage()
wp.path = "download_sample3"
# ローカルファイルを指定してpywebcopyを実行する
wp.encoding = 'utf-8'
handle = open(tmp_path, "rb")
wp.set_source(handle, encoding='utf-8')
wp.url = url
# cssなどの取得
wp.save_assets()
# htmlの取得
local_html = wp.save_html()
wp.shutdown(10)
print(local_html)
まとめ
pywebcopyを使用することでプログラムで完全なHTMLを取得できます。
pywebcopyはURLからファイルを取得するだけでなく、ローカルのファイルをもとに関連するファイルのダウンロードが行えるため、seleniumと組み合わせることができます。
いくつかの不具合については最新のバージョンを使用するか、ここで紹介した通りにパッチを当てることで回避できます。
Discussion