なるべく安全にスポットインスタンスを利用したい on EKS
スポットインスタンスは安いから、できるだけ使いたい。
でも、アプリケーションがエラーまみれになってほしくない。
そんなワガママをなるべく叶えたくてやったことの記録です。
公式ベストプラクティス
-
Prepare individual instances for interruptions
- このあと考える。 EKSなのでPodのレベルでも留意する必要がある
-
Be flexible about instance types and Availability Zones
- このあと考える
- Use EC2 Auto Scaling groups or Spot Fleet to manage your aggregate capacity
- マネージドノードグループを使えば満たされる
- Use the price and capacity optimized allocation strategy
- マネージドノードグループを使うとcapacity optimizedになる
- Use proactive capacity rebalancing
- マネージドノードグループを使うと自動的に有効になっている
- Use integrated AWS services to manage your Spot Instances
- マネージドノードグループを使えば満たされる
- ノードのオートスケールにCluster Autoscalerを利用しているが、これはAWSのAPIを呼んでAuto Scaling Groupを操作しているので、これも問題ない
- Which is the best Spot request method to use?
- スポットインスタンスのリクエストには
CreateAutoScalingGroupかCreateFleetを使おうという話で、これもマネージドノードグループを使えば満たされる
- スポットインスタンスのリクエストには
-
長時間実行されるジョブやステートフルなアプリケーションにはスポットインスタンスを使用しないでください。
- このあと考える
- スポットインスタンスでマネージドノードグループを使用する。
- すでにマネージドノードグループのみを使用している
- 複数のインスタンスタイプをノードグループに追加する。
- 先ほどのドキュメントでも出てきた内容(このあと考える)
- 自己管理型のノードグループには AWS ノード終了ハンドラーを使用します。
- マネージドノードグループではハンドラーを使用する必要がない。またすでにマネージドノードグループのみを使用している
ここまででわかること:マネージドノードグループを使おう
特別な要件がないのであれば、マネージドノードグループを利用しておけば多くの推奨事項が自動的に満たされる。
これから考えること
ただマネージドノードグループを利用するだけでは満たすことのできない、追加で検討や対応が必要なベストプラクティスを抜き出すと以下が残る。
- Prepare individual instances for interruptions
- 「長時間実行されるジョブやステートフルなアプリケーションにはスポットインスタンスを使用しないでください」はこれに含まれる
- Be flexible about instance types and Availability Zones
中断への耐性編、インスタンスタイプとアベイラビリティゾーンの柔軟性編として考える。
中断への耐性編
扱っているPodの性質を確認
- 外部公開されたAPI(Deployment)
- データベースはRDSを使用しておりPod自体はステートレス
- 外部公開されないPod(Deployment)
- データベースはRDSを使用しておりPod自体はステートレス
- バッチ(Workflow)
- CronWorkflowにより所定の時間に仕事をして去っていく
- 実行が長時間にわたるものはない
長時間実行されるジョブやステートフルなアプリケーション
はないので、「これらのPodに中断への耐性があれば」全面的にスポットインスタンスを採用できそう。
(もし今後このようなジョブやアプリケーションが開発されたなら、オンデマンドインスタンスのノードグループを別途用意して、Node SelectorやTaintsでPodを配置し分けようという気持ちだけ、頭の片隅に残しておく)
中断に耐えられるPodにする
外部公開されたAPI Pod(Deployment)
顧客向けに公開しているAPIであるため中断は最小限にしたい。
そのためこれらのPodにはGraceful shutdown / Pod Disruption Budget / Topology Spread Constraintsを整備する。
すべての対応の根底には「スポットインスタンスのリバランスにより代替ノードの準備が整うとdrainが実行される」という動作がある。
Graceful shutdown
drainが実行されたときPodの突然死を防ぐ。
アプリの実装でSIGTERMの受信を契機にGraceful shutdownをするようにしてもらう。
またPodのPreStopフックではsleepなどでServiceからPodの切り離し時間を稼ぐ。
(整備されているとクラスターのメンテナンス時にも役立つ)
Pod Disruption Budget
リバランスに伴うdrainの実行時にReadyなPodが0個になることをなるべく防ぐために用意する。
(整備されているとクラスターのメンテナンス時にも役立つ)
Topology Spread Constraints
Podを配置するゾーンを散らしておくことにより、リバランスに伴うdrainが発生したときにPDBが守られやすくなる。
(整備されているとクラスターのメンテナンス時にも役立つ。またAZ障害の被害を軽減できる)
外部公開されないPod(Deployment)
これは外からのリクエストを受けないだけでなくクラスター内でも通信せず単独で働いているだけなので、特に対応は必要なかった。
バッチPod(Workflow)
前述の通り長時間実行されるものはない。また、冪等であるように作られているため、中断への対策としては「自動的な再実行」が実現できればよい。
幸いArgo Workflowsには再実行を自動化する仕組みが存在するので、これを利用する。
インスタンスタイプとアベイラビリティゾーンの柔軟性編
インスタンスタイプ構成について
Cluster Autoscalerからの要件として、同一ノードグループのインスタンスサイズは同じくらいである必要がある(バラバラなサイズが入り乱れていると計算が狂う)。
Note that the instance types should have the same amount of RAM and number of CPU cores, since this is fundamental to CA's scaling calculations. Using mismatched instances types can produce unintended results.
同じくらいのサイズのインスタンスを掴み取りするのにec2-instance-selectorが利用できる。
❯ ec2-instance-selector \
--vcpus 4 --memory-min 7 --memory-max 8 \ # サイズ指定
--cpu-architecture x86_64 \ # multi-arch build対応済みならここも広げられる
--current-generation # 古い世代を除く(母数少ない、中断率高い、あまり安くない場合が多いため)
c4.xlarge
c5.xlarge
c5a.xlarge
c5d.xlarge
c6i.xlarge
c6id.xlarge
inf1.xlarge # 機械学習用途向けなので使わない
ここからさらに中断率が高めのものを適宜除いてノードグループのインスタンスタイプ候補とした。
スポットインスタンスを起動できないとき、代わりにオンデマンドインスタンスを起動する
リバランスにおいて中断予定のスポットインスタンスに代わってオンデマンドインスタンスを起動することはできないが、Cluster Autoscalerによるスケール時には「まずスポットインスタンスの起動を試みて、だめならオンデマンドインスタンスにする」という戦略を取ることができる。
ConfigMapでPriority based expanderを設定することで利用できる。
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-autoscaler-priority-expander
namespace: kube-system
data:
priorities: |-
# 優先度はASGの名前に対して設定する
# この場合スポットインスタンスを使うASGは名前にspotを含める
# スポットインスタンスを使わないASGは名前にspotを含めない
20:
- ".*spot.*"
10:
- ".*"
HelmチャートならexpanderPriorities valueから設定できる。
オンデマンドインスタンスのノードグループを0台で待機させるための対応
オンデマンドインスタンスは普段から起動しておく必要はないので、最小台数を0台にして待機させておきたい。
ただしk8s 1.23以前を利用する場合、ASGには所定の形式でタグを付けておかないと0台のまま増えられなくなる(CAがスケールさせるべきASGを選択するのにタグを参照するが、マネージドノードグループ作成時に自動的に付かないため)。
※k8s 1.24以降はASGのタグはなくてもよくなった。
For Kubernetes 1.24, we have contributed a feature to the upstream Cluster Autoscaler project that simplifies scaling the Amazon EKS managed node group (MNG) to and from zero nodes. Before, you had to tag the underlying EC2 Autoscaling Group (ASG) for the Cluster Autoscaler to recognize the resources, labels, and taints of an MNG that was scaled to zero nodes.
アベイラビリティゾーンについて
スポットインスタンスのリバランスの観点では、複数のアベイラビリティゾーンにまたがるノードグループ(ASG)の方が都合がいい(「ap-northeast-1aで起動してくれ」よりも「ap-northeast1a or 1cのどこかで起動してくれ」の方が成功しやすいため)。
Whenever possible, you should create your Auto Scaling group in all Availability Zones within the Region. This way, Amazon EC2 Auto Scaling can look at the available capacity in each Availability Zone. If a launch fails in one Availability Zone, Amazon EC2 Auto Scaling keeps trying to launch Spot Instances across the specified Availability Zones until it succeeds.
ただし、Cluster Autoscalerを利用している場合はノードグループはAZごとに作る必要がある。
絶対に中断を防げるのか
防げない。リバランス推奨通知は中断通知よりも必ず早く来る保証はなく、中断完了前に代替インスタンスが起動できる保証もなく、したがってdrainを完全に実行しきる時間がある保証もないため。
なのでなるべく安全を期しつつも「中断は起きるもの」として監視をする必要がある。
アプリケーションの監視
- 外部公開APIの応答
- Datadog synthetic testsなど
- Workflowの実行成否
- Argo WorkflowsのログやKuberentesイベントなど
ASGアクティビティ監視
リバランス発生時中断予定インスタンスと代替インスタンスについてアクティビティが発行されるので、特に失敗アクティビティについて監視する(DatadogならAmazon Auto Scalingインテグレーションで取得できる)。
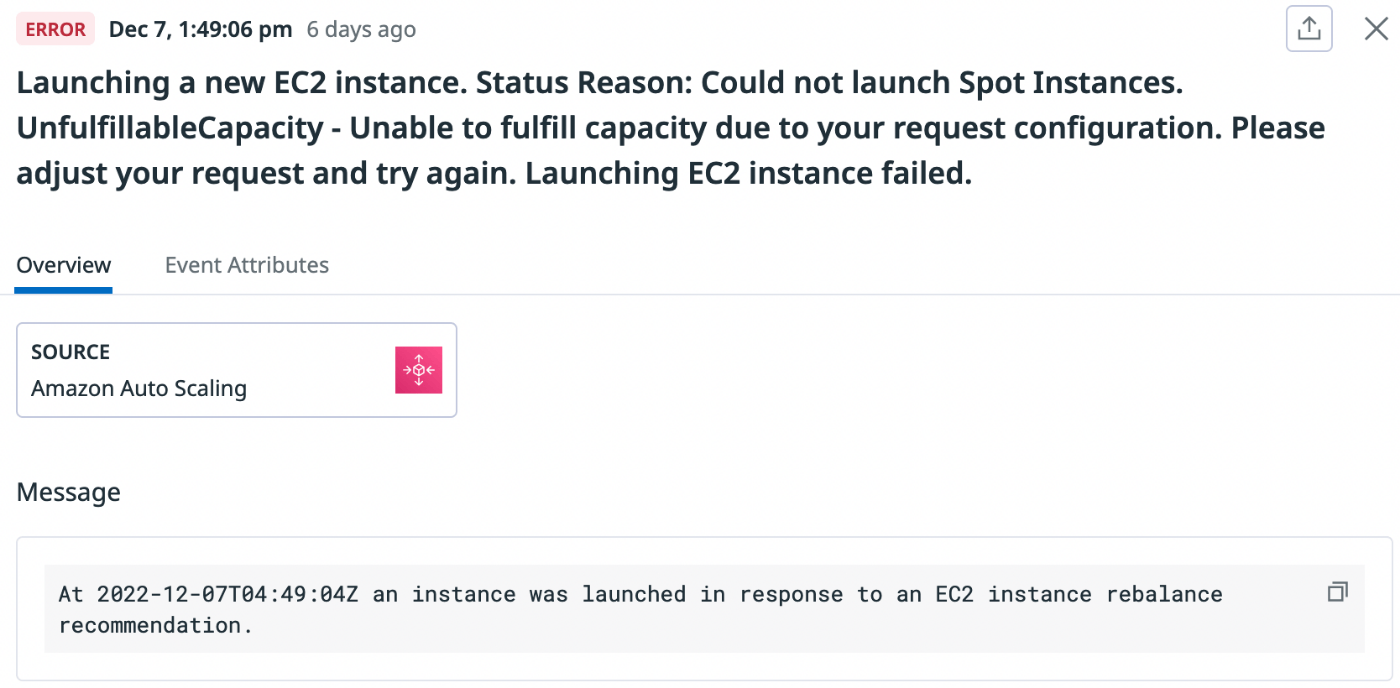
インスタンスタイプ候補に中断率が高いものがいるとリバランスが発生しやすい。また在庫が少ないインスタンスタイプが候補にいると代替ノードの起動に失敗しやすい。
そのため継続的に監視をしながらインスタンスタイプ候補をときどき刷新することになる。スポットインスタンスアドバイザーやスポットプレイスメントスコアが参考になる。
Discussion