LangChainにおいて記憶を日本語で保持する
はじめに
みなさんLangChainは使っていますでしょうか?
AI系のアプリケーションを作るのに大変便利なのですが、やはり英語が中心となって開発されているので、日本語での利用は少し難しいところがあります。
私もAITuberに記憶を導入しようとして、記憶を英語で保持されてしまい少し詰まりました。
そこで、今回は記憶を日本語で保持する方法を紹介します。
TL;DR
このように、記憶要約に使っているプロンプトを日本後に訳して上書きすれば良いです。
from langchain import LLMChain, PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationSummaryBufferMemory
template = """
{history}
Human: {input}
AI:"""
prompt = PromptTemplate(
input_variables=["history", "input"],
template=template
)
llm = ChatOpenAI(
temperature=0.2,
openai_api_key="<<<<<ここにOPEN AIのAPI KEYを入れる>>>>>",
model_name="gpt-3.5-turbo",
)
summary_prompt = PromptTemplate(
input_variables=["summary", "new_lines"],
template='''
会話の行を徐々に要約し、前の要約に追加して新しい要約を返してください。
例:
現在の要約:
人間はAIに人工知能についてどう思うか尋ねます。AIは人工知能が善の力だと考えています。
新しい会話の行:
人間:なぜあなたは人工知能が善の力だと思いますか?
AI:人工知能は人間が最大限の潜在能力を発揮するのを助けるからです。
新しい要約:
人間はAIに人工知能についてどう思うか尋ねます。AIは人工知能が善の力だと考えており、それは人間が最大限の潜在能力を発揮するのを助けるからです。
例の終わり
現在の要約:
{summary}
新しい会話の行:
{new_lines}
新しい要約:
''',
)
memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=200,
prompt=summary_prompt ### <--- ここでプロンプトを上書き
)
chain = LLMChain(
prompt=prompt,
memory=memory,
llm=llm
)
LangChainの記憶
一例として、この記事のTL;DRのコードで用いているConversationSummaryBufferMemoryは、直近の会話を指定のバッファ量で要約するMemoryです。使い勝手が良さそうなのでよく使われていそうです。
ただし、デフォルトだと英語で記憶を保持するようになっており、日本語を母語としている我々には少し不便です。
例えば以下の記事でも、英語で要約される旨が記載されています。
これを日本語で保持されるようにするにはどうしたら良いでしょうか?というのがこの記事です。簡単にできる一方でググっても出てこなかったので記事にしようと思いました。
さて、ConversationSummaryBufferMemoryはコードとしては以下で実装されています。
これのベースとなっている SummarizerMixin では、要約を行うためのプロンプトが以下定義されており、コンストラクタで指定することができます。
そして、そのプロンプトの定義元をたどるとこちらになっています。
これをChatGPTに投げて要約を実現しているんだと思います。
日本語で会話要約を行う方法
つまり、このプロンプトを日本語に訳して上書きすれば良いのです。
GPT-4に英語訳してもらいました。
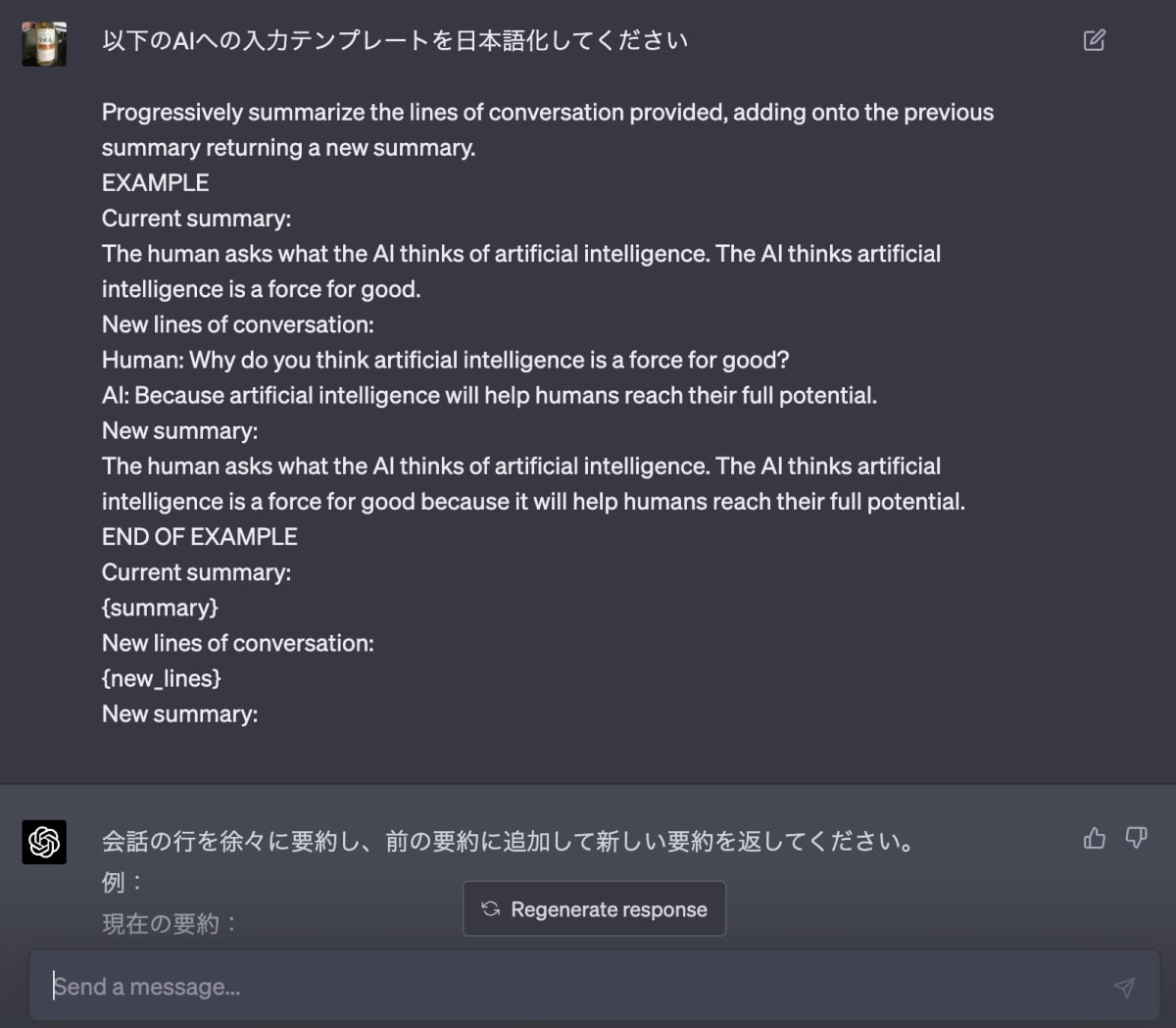
便利な時代になったものです。
コードとしては以下のようになります。
summary_prompt = PromptTemplate(
input_variables=["summary", "new_lines"],
template='''
<<<日本語訳したプロンプト>>>
''',
)
memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=200,
prompt=summary_prompt ### <--- ここでプロンプトを上書き
)
まとめ
この記事ではLangChainの会話要約の記憶を日本語で保持する方法について紹介しました。
LangChainはAI系のアプリケーションを作るのに大変便利なので、日本語での利用ももっと手軽にできるようになっていると良いなと思います。
正直この記事は技術的には大した内容ではないのですが、前述の通りググっても出なかった、かつ、需要がありそうだったので記事にしました。
みなさんのAIアプリケーション開発の参考になれば幸いです。
Discussion