Rustまとめ(The Rust Programming Languageのメモ)
cargo newのオプション
- --bin : バイナリターゲット(src/main.rs)を持つパッケージを作成する
「The Rust Programming Language 日本語版」より
- cargo newを使ってプロジェクトを作成できる
- cargo buildを使ってプロジェクトをビルドできる
- cargo runを使うとプロジェクトのビルドと実行を1ステップで行える
- cargo checkを使うとバイナリを生成せずにプロジェクトをビルドして、エラーがないか確認できる
- Cargoは、ビルドの成果物をコードと同じディレクトリに保存するのではなく、target/debugディレクトリに格納する
prelude: 標準ライブラリから一般的に使われるアイテム(構造体、関数、トレイトなど)を自動的にすべてのプログラムのスコープに取り込んだセットのこと
基本的にRustでは変数はデフォルトで不変(immutable)になるので、可変変数にしたいときは宣言時にmutをつける必要がある。
let mut a = 5; // mutableのmut
参照を引数として渡す。
次のような関数呼び出しがあるかつその引数が関数内で値の変更をする場合、&mutをつけて渡す必要がある。
test_func(&mut test)
&は参照であることを示し、複数の処理が同じデータにアクセスしてもそのデータ自体を何度もメモリにコピーしなくて済む。
ここで大事なのは参照もデフォルトでは不変であるということ。
クレート: Rustソースコードを集めたもの
クレートの種類
- バイナリクレート: 実行可能ファイル
- ライブラリクレート: 他のプログラムで使用するためのコードが含まれていて単独では実行できない
レジストリ: Crates.ioのデータのコピー
Crates.ioは、Rustのエコシステムにいる人たちがオープンソースのRustプロジェクトを投稿し、他の人が使えるようにする場所
let x = 2;
let x = x + 1;
{
let x = x * 5;
println!("スコープ内のxの値: {}", x);
}
println!("xの値: {}", x);
Rustでは前の変数の値を新しい値で隠すことが可能。これをシャドーイングという。
シャドーイングの嬉しいところは今までだと変数名を変えて宣言しなければならなかったものを変数名を再利用して宣言できるところ。
例えば、Jsonの形で帰ってきた文字列型のレスポンスをJsonオブジェクトに変換するときなど
定数はグローバルスコープも含めてどこでも定義できる。
Rustの定数の命名規則は、すべて大文字でアンダースコアで単語区切りにすること。
const TEST_VALUE :u32 = 100_000;
関数
Rustの関数の命名規則はスネークケースが慣例になっている。
Rustのコンパイラは関数がどこで定義されているかは気にしない。どこかで定義されていればOK。
関数本体は、文と式を含む
- 文: 何らかの動作をして値を返さない命令
- 式: 結果値に評価される
次の関数はx+1がyに束縛されることを表している。
fn main() {
let y = {
let x = 3;
x + 1
};
println!("The value of y is: {}", y);
}
他の言語とは違ってRustでは返り値の前にreturnを書かない。
また、式は文末にセミコロンを含まない。
制御フロー
Rustでは条件式は必ずbool型でなければならい。
他の言語のように論理値以外の値が、自動的に論理値に変換されることはない。
let文内でif式を使う
ifは式なので、let文の右辺に持ってくることができる。
let condition = true;
let number = if condition {5} else {6}
ループでの繰り返し
loopでコードを繰り返す
loopキーワードを使用することで、同じコードを無限に明示的にやめさせるまで実行する。
loop{
println!("loop!!");
}
fn main() {
let mut count = 0;
'counting_up: loop {
println!("count = {}", count);
let mut remaining = 10;
loop {
println!("remaining = {}", remaining);
if remaining == 9 {
break;
}
if count == 2 {
break 'counting_up;
}
remaining -= 1;
}
count += 1;
}
println!("End count = {}", count);
}
forでコレクションを覗き見る
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a {
println!("the value is: {}", element);
}
}
while文で実装するのに比べてこちらのほうが早い。
なぜなら、コンパイラが実行時にループの各回ごとに境界値チェックを行うようなコードを追加するため。
所有権
Rustのメモリの使用方法:コンパイラがコンパイル時にチェックする一定の規則とともに所有権システムを通じて管理されている。どの所有権機能も、実行中にプログラムの動作を遅くすることはない。
所有権規則
- Rustの各値は、所有者と呼ばれる変数と対応している、
- いかなる時も所有者は一つである。
- 所有者がスコープから外れたら、値は破棄される。
{ // sは、ここでは有効ではない。まだ宣言されていない
let s = "hello"; // sは、ここから有効になる
// sで作業をする
} // このスコープは終わり。もうsは有効ではない
String型
ユーザー入力を受け付け、それを保持したいという場合にString型を使う。
String型はヒープにメモリを確保するので、コンパイル時にはサイズが不明なテキストも保持することができる。
from関数を使用して文字列リテラルからString型を生成できる。
let mut s = String::from("rust");
s.push_str("acian");
メモリと確保
-
文字列リテラルの場合
中身はコンパイル時に判明しているので、テキストは最終的なバイナリファイルに直接ハードコードされる。このことから、文字列リテラルは、高速で効率的になる。 -
String型の場合
可変かつ伸長可能なテキスト破片をサポートするために、コンパイル時には不明な量のメモリをヒープに確保して内容を保持する。
- メモリは、実行時にOSに要求される
- String型を使用し終わったら、OSにこのメモリを変換する方法が必要である。
Rustでは二番目のことをスコープから抜けたら自動的にメモリを返還することで実現している。
(※GCは使われなくなったことを検知したら都度メモリを開放していた。)
スコープから抜けるときに自動的にdropと呼ばれるメモリを返還する特別な関数を呼び出す。
注釈: C++では、要素の生存期間の終了地点でリソースを解放するこのパターンを時に、 RAII(Resource Aquisition Is Initialization: リソースの獲得は、初期化である)と呼んだりします。 Rustのdrop関数は、あなたがRAIIパターンを使ったことがあれば、馴染み深いものでしょう。
変数とデータの相互作用
二重解放エラー: メモリを2回解放することは、memory corruption (訳注: メモリの崩壊。意図せぬメモリの書き換え) につながり、 セキュリティ上の脆弱性を生む可能性があります。
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);
Rustでは宣言した変数を別の変数に代入したときに、コンパイラは最初に宣言した変数の参照を無効化する。これはムーブと呼ばれ、上記のコード例ではs1はs2にムーブされたという。
変数とデータの相互作用法:クローン
deep copyをしたい場合はcloneと呼ばれるメソッドを使うことができる。
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);
※cloneの実行コストは高い
スタックのみのデータ: コピー
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);
整数のようなコンパイル時に既知のサイズを持つ型は、スタック上にすっぽり保持されるので、実際の値をコピーするのも高速なので、xは有効のままyにムーブはされない。
RustにはCopyトレイトと呼ばれる特別な注釈があり、 整数のようなスタックに保持される型に対して配置することができます
Copyの型の一部
- あらゆる整数型(u32など)
- 論理値型である。
- あらゆる浮動小数点型(f64など)
- 文字型(char)
- タプル。ただし、Copyの型だけを含む場合に限られる。(i32,String)などはだめ。
所有権と関数
関数に値を渡すことと、値を変数に代入することは似ている。
関数に変数を渡すと、代入のようにムーブやコピーされる。
fn main() {
let s = String::from("hello"); // sがスコープに入る
takes_ownership(s); // sの値が関数にムーブされ...
// ... ここではもう有効ではない
let x = 5; // xがスコープに入る
makes_copy(x); // xも関数にムーブされるが、
// i32はCopyなので、この後にxを使っても
// 大丈夫
} // ここでxがスコープを抜け、sもスコープを抜ける。ただし、sの値はムーブされているので、何も特別なことは起こらない。
//
fn takes_ownership(some_string: String) { // some_stringがスコープに入る。
println!("{}", some_string);
} // ここでsome_stringがスコープを抜け、`drop`が呼ばれる。後ろ盾してたメモリが解放される。
//
fn makes_copy(some_integer: i32) { // some_integerがスコープに入る
println!("{}", some_integer);
} // ここでsome_integerがスコープを抜ける。何も特別なことはない
戻り値とスコープ
値を返すことでも、所有権は移動する。
fn main() {
let s1 = gives_ownership(); // gives_ownershipは、戻り値をs1に
// ムーブする
let s2 = String::from("hello"); // s2がスコープに入る
let s3 = takes_and_gives_back(s2); // s2はtakes_and_gives_backにムーブされ
// 戻り値もs3にムーブされる
} // ここで、s3はスコープを抜け、ドロップされる。s2もスコープを抜けるが、ムーブされているので、
// 何も起きない。s1もスコープを抜け、ドロップされる。
fn gives_ownership() -> String { // gives_ownershipは、戻り値を
// 呼び出した関数にムーブする
let some_string = String::from("hello"); // some_stringがスコープに入る
some_string // some_stringが返され、呼び出し元関数に
// ムーブされる
}
// takes_and_gives_backは、Stringを一つ受け取り、返す。
fn takes_and_gives_back(a_string: String) -> String { // a_stringがスコープに入る。
a_string // a_stringが返され、呼び出し元関数にムーブされる
}
Q)所有権を取り、またその所有権を戻す、ということを全ての関数でしていたら、ちょっとめんどくさいですね。 関数に値は使わせるものの所有権を取らないようにさせるにはどうするべきでしょうか。
A) 参照を使う
参照と借用
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
// '{}'の長さは、{}です
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
値の所有権をもらう代わりに引数としてオブジェクトへの参照をとっている。
アンド記号が参照であり、これのおかげで所有権をもらうことなく値を参照することができる。
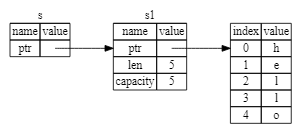
&s1という記法はs1の値を参照する参照を生成しているが、s1の参照を所有することはない。
fn calculate_length(s: &String) -> usize { // sはStringへの参照
s.len()
} // ここで、sはスコープ外になる。けど、参照しているものの所有権を持っているわけではないので
// 何も起こらない
借用: 関数の引数に参照をとること
借用したものを変更しようとしたら、エラーになる。
これは変数が標準で不変なのと同様に参照も不変のため。
可変な参照
先ほどの処理では参照に変更を加えることはできなかったですが、次のようにすることで変更が可能になります。
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
関数に渡す変数の宣言でmutをつけ、関数側の仮引数にも&mutをつける。
そして、関数呼び出しの実引数を渡すときに&mut 変数名の形で渡す必要がある。
しかし、可変な参照には制約がある。
特定のスコープで、ある特定のデータに対しては、一つしか可変な参照を持てないこと。
この制約の利点はコンパイラはコンパイル時にデータ競合を防ぐことができること。
データ競合の条件
- 2つ以上のポインタが同じデータに同時にアクセスする。
- 少なくとも一つのポインタがデータに書き込みを行っている。
- データへのアクセスを同期する機構が使用されていない。
データ競合は未定義の振る舞いを引き起こし、実行時に追いかけようとした時に特定し解決するのが難しい問題です。 しかし、Rustは、データ競合が起こるコードをコンパイルさえしないので、この問題が発生しないようにしてくれるわけです。
いつものように、波かっこを使って新しいスコープを生成し、同時並行なものでなく、複数の可変な参照を作ることができます。
fn main() {
let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1はここでスコープを抜けるので、問題なく新しい参照を作ることができる
let r2 = &mut s;
}
Q 可変と不変な参照を組み合わせるとどうなるか?
A エラーが起きる(不変な参照をしている間は、可変な参照をすることはできない。ただし複数の不変参照をすることは可能)
宙に浮いた参照
ダングリングポインタ: 無効なメモリ領域を指すポインタのこと。本来有効だったメモリ領域が解放処理などによって無効化されたにもかかわらず、そのメモリ領域を参照し続けるポインタのこと
Rustでは、コンパイラが、 参照がダングリング参照に絶対ならないよう保証してくれる。
つまり、何らかのデータへの参照があったら、 コンパイラは参照がスコープを抜けるまで、データがスコープを抜けることがないよう確認してくれる
参照の規則
- 任意のタイミングで、一つの可変参照か複数の不変な参照のどちらかを行える。
- 参照は常に有効でなければならない。
スライス型
スライス: 所有権のない別のデータ型のこと
スライスにより、コレクション全体ではなく、そのうちの一連の要素を参照することができる。
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
iter(): コレクション内の各要素を返すメソッド
enumerate(): iterの結果をラップして、結果をそのまま返す代わりにタプルの一部として各要素を返す。第一要素は添え字,第二要素はコレクションの要素への参照になる。
文字列スライス
Stringの一部への参照のこと
fn main() {
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
}

[starting_index..ending_index]と指定することで、角かっこに範囲を使い、スライスを生成できます。
内部的にはスライスデータ構造は、開始地点とスライスの長さを保持しており、スライスの長さはending_indexからstarting_indexを引いたものに対応する。
&str: 文字列スライスを意味する型
構造体
Rustではフィールドの値を変更したい場合はインスタンス全体を可変にしなければならない
let mut user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");
フィールドと変数が同名時にフィールド初期化省略記法を使う
冗長な初期化例
fn build_user(email: String, username: String) -> User {
User {
email: email,
username: username,
active: true,
sign_in_count: 1,
}
}
email,usernameにそれぞれemail,usernameを指定している。
フィールドと変数が同名の場合、振る舞いはそのままで指定を省略することができる
構造体更新記法で他のインスタンスからインスタンスを生成する
構造体更新記法 : 前のインスタンスの値を使用しつつ、変更する箇所だけ更新して新しいインスタンスを生成する記法
let user2 = User {
email: String::from("another@example.com"),
username: String::from("anotherusername567"),
..user1
};
(JavaScriptのスプレッド構文に似てる)
異なる型を生成する名前付きフィールドのないタプル構造体を使用する
タイプ構造体: 構造体名により追加の意味を含むが、フィールドに紐付けられた名前がないフィールドの型だけのタプルに似た構造体のこと
利点: タプル全体に名前を付け、そのタプルを他のタプルとは異なる型にしたい場合に有用
struct Color(i32, i32, i32);
let black = Color(0, 0, 0);
フィールドのないユニット様構造体
ユニット様構造体: フィールドのない構造体
ある型にトレイトを実装するが、型自体に保持させるデータは一切ない場面で有効になる
※補足
構造体のフィールドの型には&str(文字列スライス型)が使えない。
これは、構造体のインスタンスには全データを所有してもらう必要があり、このデータは構造体全体が有効な場合はずっと有効である必要がある。
トレイトの導出で有用な機能を追加する
波括弧の整形はDisplayと呼ばれ、エンドユーザー向けの出力。
基本型(u32やStringなど)はDisplayが実装されているので出力できる。
Q.構造体などを標準出力させるにはどうすればいいか?
A.波括弧{}の中に「:?」や「:#?」を入れて、構造体の上に#[derive(Debug)]を追記する
メソッドを定義する
メソッド: 構造体の文脈(あるいはenumかトレイトオブジェクトの)で定義されるという点で、関数とは異なり、最初の引数は必ずselfになる。selfはメソッドが呼び出されている構造体インスタンスを表す。
関数の代替としてメソッドを使う利点:
→ 体系化
コードの将来的な利用者にある構造体の機能を提供しているライブラリの各所でその機能を探させるのではなく、この型のインスタンスでできることを一つのimplブロックでまとめ上げている
関連関数
関連関数: implブロック内にselfを引数に取らない関数を定義できること。
関連関数は関数であり、メソッドではない。理由は対象となる構造体のインスタンスが存在しないから。
使用場面
関連関数は、構造体の新規インスタンスを返すコンストラクタによく使用される。
impl Rectangle {
fn square(size: u32) -> Rectangle {
Rectangle { width: size, height: size }
}
}
複数のimplブロック
各構造体には複数のimplブロックを存在させることができる。
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
Enumを定義する
enum IpAddrKind {
V4,
V6,
}
各enumの列挙子に直接データを添付することが可能
enum IpAddr {
V4(String),
V6(String),
}
let home = IpAddr::V4(String::from("127.0.0.1"));
let loopback = IpAddr::V6(String::from("::1"));
Option enumとNull値に勝る利点
Rustにはnullがないが、値が存在するかどうかという概念をコード化するEnumならある。
そのEnumがOption<T>で次のように標準ライブラリに定義されている。
enum Option<T> {
Some(T),
None,
}
<T>は、Option enumのSome列挙子が、 あらゆる型のデータを1つだけ持つことができることを意味している
Q.None値がある場合、nullと同じことを意図しているが、なぜOption<T>のほうが、nullよりも多少好ましいのか?
A.Option<T>とTは異なる型なので、コンパイラがOption<T>の値を確実に有効な値かのように使用させてくれない。
例えば、i8型の変数とOption<i8>型の変数を足し合わせようとするとエラーになる。
コンパイラがOption<i8>の変数に値があるかどうかを気にかけてくれる。
よって、Option<T>を処理で使う前にTに変換する必要がある
nullになる可能性のある値を保持するには、その値の型をOption<T>にすることで明示的に同意しなければならない。そして、その値を使用する際に、値がnullである場合を明示的に処理する必要がある。
match制御フロー演算子
match: 一連のパターンに対して値を比較し、マッチしたパターンに応じてコードを実行させてくれる強力な制御フロー演算子
アームコードが一行の場合は波括弧はいらないが、複数行書く時には必要
Option<T>とのマッチ
matchはOption<T>も扱える。
enumに対し、matchし、内部のデータに変数を束縛させ、それに基づいたコードを実行する
enum Coin{
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn value_in_cents(coin:Coin) -> u32 {
match coin {
Coin::Penny => {
println!("Lucky penny!");
1
},
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter(state) => {
println!("State quarter from {:?}!", state);
25
}
}
}
マッチは包括的
Rustにおけるマッチは包括的である。
全てのあらゆる可能性を網羅し尽くさなければ、コードは有効になることはない。
特に、Option<T>の場合には、明示的にNoneの場合を処理するのを忘れないようにしてくれる。
(10億ドルの失敗を犯さないようコンパイラが保護してくれる)
_というプレースホルダー
matchが包括的であるからと言って、u32など、莫大なパターンがある場合、すべての場合を列挙するのは現実的ではない。
Rustにはこのような場合に回避策が用意されていて、「_」というプレースホルダーを使うことができる。
let some_u8_value = 0u8;
match some_u8_value {
1 => println!("one"),
3 => println!("three"),
5 => println!("five"),
7 => println!("seven"),
_ => (),
}
他のプログラミング言語で出てくるdefaultのようなもの。
これで列挙されていないすべてのパターンが「_」でカバーされる。
if letで簡潔な制御フロー
match式をたった一つの場合のために書くのは少し冗長である。この場合、有用になる記法がif let記法である。
次に、Option<u8>にマッチするが、値が3の時にだけコードを実行したいプログラムを示す。
let some_u8_value = Some(0u8);
if let Some(3) = some_u8_value {
println!("Three");
}
if letという記法は等号記号で区切られたパターンと式をとり、式がmatchに与えられ、パターンが最初のアームになったmatchと同じ動作をする。
メリット
if letを使うと、タイプ数が減り、インデントも少なくなり、定型コードも減る。
デメリット
matchでは強制された包括性チェックを失ってしまう。
matchかif letかの選択は、特定の場面でどんなことをしたいかと簡潔性を得ることが包括性チェックを失うのに適切なトレードオフとなるかによる。
if letは値が一つのパターンにマッチしたときにコードを走らせ、他は無視するmatchへの糖衣構文と考えることができる。また、if letにはelseを含むこともできる。
let mut count = 0;
if let Coin::Quarter(state) = coin {
println!("State quarter from {:?}!", state);
} else {
count += 1;
}
パッケージとクレート
クレート: バイナリかライブラリのどちらか。
クレートルート: Rustコンパイラの開始点(エントリーポイント)となり、クレートのルートモジュールを作るソースファイルのこと。
クレートルートと呼ばれる理由はモジュールツリーと呼ばれるクレートのモジュール構造のルートにcrateというモジュールを形成するため。
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
パッケージ: ある機能群を提供する一つ以上のクレート
パッケージはCargo.tomlという、それらのクレートをどのようにビルドするかを説明するファイルを持っている。
パッケージのルール
- パッケージは0個か1個のライブラリクレートを持っていなければならない。それ以上は持ってはいけない。
- バイナリクレートはいくつあってもいい。
ファイルをsrc/binディレクトリに置くことで、パッケージは複数のバイナリクレートを持つことができる。
モジュールを定義して、スコープとプライバシーを制御する
モジュール: クレート内のコードをグループ化し、可読性と再利用性を上げるのに役立つ
モジュールは要素のプライバシーも制御できる。
プライバシー: 要素がコードの外側で使える(public)のか、内部の実装の詳細であり、外部では使えない(private)のかを表すもの。
モジュールは、modキーワードを書き、次にモジュールの名前を指定することで定義される。
モジュールの中には、他のモジュールを置くこともできる。
モジュールには他の要素(構造体、enum、定数、トレイト、関数など)も定義できる
モジュールツリーの要素を示すためのパス
二種類のパス
- 絶対パス: クレートの名前に
crateを使うことで、クレートルートからスタートする。 - 相対パス:
self,'super'または今のモジュール内の識別子を使うことで、現在のモジュールからスタートする。
crate::front_of_house::hosting::add_to_waitlist();
front_of_house::hosting::add_to_waitlist();
相対パスを使うか絶対パスを使うかは、プロジェクトによって決める。 要素を定義するコードを、その要素を使うコードと別々に動かすか一緒に動かすか、どちらが起こりそうかによって決めるのが良い。
構造体とenumを公開する
構造体の場合は、公開する際に構造体名の前にpubを置いただけだと構造体内で宣言されているフィールドは非公開のまま。
それぞれのフィールドの公開・非公開を選べる。
enumは前にpubを置くだけですべて公開される。
useキーワードでパスをスコープに持ち込む
useでパスをスコープに追加することは、ファイルシステムにおいてシンボリックリンクを張ることに似ている。
次に示すコードは絶対パスと相対パスの場合である
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
use self::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
hosting::add_to_waitlist();
hosting::add_to_waitlist();
}
また、慣例的にモジュールの関数を使用する際のuse宣言はフルパスではなく親モジュールまでにする。
そうすることで、mainの関数内で呼ぶときに「親モジュール::関数」の形式となり、ローカルで定義されていないことを明らかにできるため。
一方で、構造体やenumその他の要素をuseで持ち込む場合はフルパスで書く
新しい名前をasキーワードで与える
同じ名前の二つの型をuseを使って同じスコープに持ち込むという課題の解決策の一つとしてasがある。
パスの後に「as+新しいローカル名(エイリアス)」で指定すればいい
use std::io::Result as IoResult;
pub useを使って名前を再公開する
自身のプロジェクトでuseを使ってモジュールをスコープに追加したとき、そのモジュール内の関数などを呼び出せるのは自身のプロジェクト内のプログラムのみ。外部から呼ばれるときはuseで追加したものは非公開扱いなので呼ぶことはできない。
それを解決するのがpub use
自分たちのスコープに持ち込むだけでなく、他の人がその要素をその人のスコープに持ち込むことも可能にすることから再公開(re-exporting) と呼ばれている。
再公開の有用性
コードの内部構造とそのコードを呼び出すプログラマーたちのその領域に関しての見方が異なるときに有用。(※ しかし、pub useのような書き方があると、乱用される気がする)
外部のパッケージを使う
Calgo.tomlのdependencyに加える
巨大なuseのリストをネストしたパスを使って整理する
同じクレートか同じモジュールで定義された複数の要素を使おうとするとき、それぞれの要素を一行一行並べると、縦に大量のスペースをとってしまう。
代わりに、ネストしたパスを使うことで同じ一連の要素を1行でスコープに持ち込める。
use std::{cmp::Ordering, io};
use std::io;
use std::io::Write;
上二つをネストで表現すると次のようになる。
use std::io::{self,Write};
glob演算子
ワイルドカードみたいなのがglob演算子。
どの名前がスコープ内にあり、プログラムで使われている名前がどこで定義されたのか分かりづらくなるので、テストコード以外では用いないようにする
モジュールを複数のファイルに分割する
modo <モジュール名>の後にブロックではなくセミコロンを使うと、Rustにモジュールの中身をモジュールと同じ名前をした別のファイルから読み込むように命令する。
useはどのファイルがクレートの一部としてコンパイルされるかになんの影響も与えないということに注意する。 modキーワードがモジュールを宣言したなら、Rustはそのモジュールに挿入するためのコードを求めて、モジュールと同じ名前のファイルの中を探す。
ベクタ(Vec<T>)で値のリストを保持する
ベクタは単体のデータ構造でありながら複数の値を保持でき、それらの値をメモリ上に隣り合わせに並べる。
新しいベクタを生成する
let v: Vec<i32> = Vec::new();
ベクタをドロップすれば、要素もドロップする
他のあらゆる構造体と同様に、ベクタもスコープを抜ければ解放される。
ベクタの要素を読む
ベクタに保持された値を参照する方法二つ
- 添え字記法
-
getメソッド
+演算子、またはformat!マクロで連結
let s1 = String::from("Hello, ");
let s2 = String::from("World!");
let s3 = s1 + &s2;
println!("s3 is {}",s3);
+演算子は、addメソッドを使用する。
シグニチャは文字列で使用した場合、次のようになる。
fn add(self, s: &str) -> String {
Q.Stringには&strしか追加することはできなかったはずなのに、&Stringを追加して実行できるのはなぜでしょうか?
A.コンパイラが&String引数を&strに型強制してくれるため。
addメソッド呼び出しの際に、コンパイラは参照外し型強制というものを使用して、ここでは&s2を&s2[..]に変えている。
この処理は、s1の所有権を奪い、s2の中身のコピーを追記し、結果の所有権を返している。
複雑な文字列の場合はformat!を使用すると、所有権も奪わずにStringを返すのでこちらを使おう
キーとそれに基づいた値をハッシュマップに格納する
ハッシュマップ:
HashMap<K,V>型はK型のキーとV型の値の対応関係を保持する。この対応関係の保持をハッシュ関数を介して行う。
ハッシュ関数:
キーと値のメモリ配置方式を決めるもの。
新規ハッシュマップの生成
空のハッシュマップをnewで作り、要素をinsertで追加できる。
ベクタと同様ハッシュマップはデータをヒープに保持する。
※キーはすべて同じ型でなければならず、値もすべて同じ型でなければならない
別の生成方法
→ タプルのベクタに対してcollectメソッドを使用する。
collectメソッドは様々なコレクション型にデータをまとめ上げ、その中の一つにHashMapも含まれている。
let teams = vec![String::from("Blue"), String::from("Yellow")];
let initial_scores = vec![10, 50];
let scores: HashMap<_,_ > = teams.iter().zip(initial_scores.iter()).collect();
collectはいろんなデータ構造にまとめ上げることができるので、型注釈が必要になることに注意する。
キーと値の型引数については、 アンダースコアを使用しており、コンパイラはベクタのデータ型に基づいてハッシュマップが含む型を推論することができる。
ハッシュマップと所有権
Copyトレイトを実装する型については、値はハッシュマップにコピーされる。
Stringのような所有権のある値なら、値はムーブされ、ハッシュマップはそれらの所有者になる。
値への参照をハッシュマップに挿入したら、値はハッシュマップにムーブされない。
参照が指している間は、最低でもハッシュマップが有効な間は、有効でなければならない。
ハッシュマップの値にアクセスする
キーをgetメソッドに渡すことでハッシュマップから値を取り出せる。
getはOption<&V>を返す。なければNoneを返す。
forループを使ってハッシュマップのキーと値のペアを走査することができる。
この時、出力される順番はランダムになる。
ハッシュマップの更新
値を上書きする
キーと値をハッシュマップに挿入し、同じキーを異なる値で挿入したら、そのキーに紐づけられている値は置換される。
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Blue"), 25); // <- 置換
キーに値がなかったときのみ値を挿入する
entry: 特定の値にキーがあるか確認するためのAPI
メソッドの戻り値はEntryと呼ばれるEnumであり、存在したりしなかったりする可能性のある値を表す。
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.entry(String::from("Yellow")).or_insert(50);
scores.entry(String::from("Blue")).or_insert(50);
Entryのor_insertメソッドは、対応するEntryキーが存在したときにそのキーに対する値への可変参照を返すために定義されている。
なかったら、引数をこのキーの新しい値として挿入し、新しい値への可変参照を返す。
古い値に基づいて値を更新する
ハッシュマップの一般的なユースケースとして、キーの値を探し、古い値に対してそれを更新することである。
let text = "hello world wonderful world";
let mut map = HashMap::new();
for word in text.split_whitespace() {
let count = map.entry(word).or_insert(0);
*count += 1;
}
or_insert関数はキーに対する値への可変参照(&mut V)を返す。
ここで、可変参照をcount変数に保持しているので、その値に代入するためにアスタリスク(*)で参照外しをする必要がある。
countはforループ内で宣言されているのでループの終端でスコープを抜けるのでこれらの変更は安全である。
ハッシュ関数
標準では、HashMapはサービス拒否(DoS)アタックに対して抵抗を示す暗号学的に安全なハッシュ関数を使用します。 これは、利用可能な最速のハッシュアルゴリズムではありませんが、パフォーマンスの欠落と引き換えに安全性を得るというトレードオフは、 価値があります。自分のコードをプロファイリングして、自分の目的では標準のハッシュ関数は遅すぎると判明したら、 異なるhasherを指定することで別の関数に切り替えることができます。hasherとは、 BuildHasherトレイトを実装する型のことです。トレイトについてとその実装方法については、第10章で語ります。 必ずしも独自のhasherを1から作り上げる必要はありません; crates.ioには、 他のRustユーザによって共有された多くの一般的なハッシュアルゴリズムを実装したhasherを提供するライブラリがあります。
Resultで回復可能なエラー
enum Result<T, E> {
Ok(T),
Err(E),
}
TとEは、ジェネリックな型引数
Tが成功したときにOk列挙子に含まれて返される値の型を表すこと
Eが失敗したときにErr列挙子に含まれて返されるエラーの型を表すこと
Option enumのように、Result enumとその列挙子は、初期化処理でインポートされている
let f = File::open("hello.txt");
let f = match f {
Ok(file) => file,
Err(ref error) if error.kind() == ErrorKind::NotFound => {
match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => {
panic!(
//ファイルを作成しようとしましたが、問題がありました
"Tried to create file but there was a problem: {:?}",
e
)
},
}
},
Err(error) => {
panic!(
"There was a problem opening the file: {:?}",
error
)
},
};
if error.kind() == ErrorKind::NotFound このような条件式をマッチガードという
マッチガード: そのアームのコードが実行されるには真でなければいけない
&の代わりにrefが用いられているが、パターンの文脈において、&は参照にマッチし、その値を返すが、refは値にマッチしてそれへの参照を返す。
エラー時にパニックするショートカット: unwrapとexpect
Result<T,E>型には、いろいろな作業をするヘルパーメソッドが多く定義されている。
unwrap: match式と同じように実装された短絡メソッド。Result値がOk列挙子なら、unwrapはOkの中身を返す。ResultがErr列挙子なら、unwrapはpanic!マクロを呼んでくれる。
expected: panic!のエラーメッセージを指定できる。
エラーを委譲する
失敗する可能性のある何かを呼び出す実装をした関数を書く際、関数内でエラーを処理する代わりに、呼び出し元がどうするかを決められるようにエラーを返すことができる。
自分のコードの文脈内で利用可能なものよりも、エラーの処理法を規定する情報やロジックがより多くある呼出し元のコードに制御を明け渡す。
以下がエラーの扱いを呼び出し元に委譲している関数である。
fn read_username_from_file() -> Result<String, io::Error> {
let f = File::open("hello.txt");
let mut f = match f {
Ok(file) => file,
Err(e) => return Err(e),
};
let mut s = String::new();
match f.read_to_string(&mut s) {
Ok(_) => Ok(s),
Err(e) => Err(e),
}
}
match式を使わずに?を使って以下のように書くこともできる。
fn read_username_from_file() -> Result<String, io::Error> {
let mut s = String::new();
File::open("hello.txt")?.read_to_string(&mut s)?;
Ok(s)
}
match式と?演算子の違い
?を使ったエラー値は、標準ライブラリのFromトレイトで定義され、エラーの型を別のものに変換するfrom関数を通る。
?関数がfrom関数を呼び出すと、受け取ったエラー型が現在の関数の戻り値型で定義されているエラー型に変換される。これは、個々がいろんな理由で失敗する可能性があるにも関わらず、関数が失敗する可能性をすべて一つのエラー型で表現するのに有用
?演算子は戻り値にResultを持つ関数でしか使用できない
ジェネリックなデータ型
fn largest<T>(list: &[T]) -> T {
let mut largest = list[0];
for &item in list.iter() {
if item > largest {
largest = item;
}
}
largest
}
この関数は動作しない。 2項演算>は、型Tに適用できませんというエラーが出る。
これは、値が順序付け可能な型のみしか使用できない。比較を可能にするために、標準ライブラリには型に実装できるstd::cmp::PartialOrdトレイトがある。
構造体定義では
struct Point<T> {
x: T,
y: T,
}
Point<T>構造体が何らかの型Tに関して、ジェネリックである。xとyのフィールドは両方その同じ型になっている。
let wont_work = Point { x: 5, y: 4.0 };
これはコンパイルできない。
以下のように書き換えるとコンパイル可能
struct Point<T, U> {
x: T,
y: U,
}
enum定義では
構造体のように、列挙子にジェネリックなデータ型を保持するenumを定義することができる。
OptionやResultがいい例
enum Option<T>{
Some(T),
None,
}
enum Result<T,U>{
Ok(T),
Err(U),
}
メソッド定義では
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
impl Point<f32> {
fn distance_from_origin(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
ジェネリックな型を持つPoint<T>インスタンスではなく、Point<f32>だけにメソッドを実装することもできる。
このコードは、Point<f32>にはdistance_from_originというメソッドが存在するが、 Tがf32ではないPoint<T>の他のインスタンスにはこのメソッドが定義されないことを意味する。
ジェネリクスを使用したコードのパフォーマンス
Rustでは、ジェネリクスを、具体的な型があるコードよりもジェネリックな型を使用したコードを実行するのが遅くならないように実装している。
コンパイラは、ジェネリクスを使用しているコードの単相化をコンパイル時に行うことで達成している。
単相化(monomorphization):コンパイル時に使用されている具体的な型を入れることで、ジェネリックなコードを特定のコードに変換する過程のこと。
コンパイラは、ジェネリックなコードが呼び出されている箇所全部を見て、 ジェネリックなコードが呼び出されている具体的な型のコードを生成する
Rustでは、ジェネリックなコードを各インスタンスで型を指定したコードにコンパイルするので、 ジェネリクスを使用することに対して実行時コストを払うことはない。コードを実行すると、 それぞれの定義を手作業で複製した時のように振る舞う。単相化の過程により、 Rustのジェネリクスは実行時に究極的に効率的になる。
トレイト:共通の振る舞いを定義する
トレイト:Rustコンパイラに、特定の型に存在し、他の型と共有できる機能
トレイトを使用すると、共通の振る舞いを抽象的に定義できる。
トレイトを定義する
トレイト定義は、メソッドシグニチャをあるグループにまとめ、なんらかの目的を達成するのに必要な一連の振る舞いを定義する手段
(※JavaやC#でいうところのインターフェースもしくは抽象クラスのようなものか?)
pub trait Summary {
fn summarize(&self) -> String;
}
トレイトを型に実装する
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
トレイト実装で注意すべき制限の一つは、トレイトか対象の型が自分のクレートに固有であるときのみ、型に対してトレイトを実装できるということ。
外部のトレイトを外部の型に対して実装することはできない。Vec<T>に対してDisplayトレイトを実装することはできない。
この制限は、コヒーレンス(coherence)、特に**孤児のルール(orphan rule)**と呼ばれるプログラム特性の一部で、親の型が存在しないためにそう命名された。この規則により、他の人のコードが自分のコードを壊したり、その逆が起きないことを保証してくれる。
デフォルト実装
トレイトのすべてあるいは一部のメソッドに対してデフォルトの振る舞いを設定できる。
これによって、特定の型にトレイトを実装する際、各メソッドのデフォルト実装を保持するかオーバーライドするか選択ができるようになる。
引数としてのトレイト
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}
引数がSummaryトレイトを実装しているような何らかの型
トレイト境界構文
impl Trait構文は単純なケースを解決するが、実はより長い**トレイト境界(trait bound)**と呼ばれる糖衣構文である。
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}
複数のトレイト境界を+構文で指定する
例)notifyにsummarizeメソッドに加えてitemの画面出力形式を使わせたいとする。
pub fn notify(item: &(impl Summary + Display)) {
+構文はジェネリック型につけたトレイト境界に対しても使える。
pub fn notify<T: Summary + Display>(item: &T){
where句を使ったより明確なトレイト境界
あまりたくさんのトレイト境界を使うことには欠点もある。
それぞれのジェネリックな型がそれぞれのトレイト境界を持つので、複数のジェネリック型の引数をもつ関数は、関数名と引数リストの間に大量のトレイト境界に対する情報を含むことがある。
これだと関数のシグネチャが読みにくくなってしまう。Rustはトレイト境界を関数シグネチャの後のwhere句の中で指定するという別の構文を用意している
before
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {
after
fn some_function<T,U>(t: &T,u:&U) -> i32
where T: Display + Clone,
U: Clone + Debug
{
トレイトを実装している型を返す
以下のように、impl Trait構文を戻り値型のところで使うことにより、あるトレイトを実装する何らかの型を返すことができる。
fn returns_summarizable() -> impl Summary {
Tweet {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
retweet: false,
}
}
impl Traitは一種類の型を返す場合にのみ使えます。 たとえば、以下のように、戻り値の型はimpl Summaryで指定しつつ、NewsArticleかTweetを返すようなコードは失敗します
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Penguins win the Stanley Cup Championship!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
}
} else {
Tweet {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
retweet: false,
}
}
}
トレイト境界を使用して、メソッド実装を条件分けする
ジェネリックな型引数を持つimplブロックにトレイト境界を与えることで、特定のトレイトを実装する型に対するメソッド実装を条件分けできる。
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}
また、別のトレイトを実装するあらゆる型に対するトレイト実装を条件分けすることもできます。 トレイト境界を満たすあらゆる型にトレイトを実装することは、ブランケット実装(blanket implementation)と呼ばれ、 Rustの標準ライブラリで広く使用されています。例を挙げれば、標準ライブラリは、 Displayトレイトを実装するあらゆる型にToStringトレイトを実装しています。 標準ライブラリのimplブロックは以下のような見た目です:
impl<T: Display> ToString for T {
// --snip--
}
ライフタイム省略規則
-
参照である各引数は、独自のライフタイム引数を得るというもの。1引数の関数は、1つのライフタイム引数を得るということ。
-
一つだけ入力タイム引数があるなら、そのライフタイムがすべての出力タイムライフ引数に代入されるというもの
-
複数の入力ライフタイム引数があるが、メソッドなのでそのうちの一つが&selfや&mut selfだったら、selfのライフタイムが全出力ライフタイム引数に代入される
入力ライフタイム:関数やメソッドの引数のライフタイム
出力ライフタイム:戻り値のライフタイム
ジェネリック引数とFnトレイトを使用してクロージャを保存する
クロージャやクロージャの呼び出し結果の値を保存する構造体を作る
メモ化または遅延評価: 結果の値が必要な場合のみにその構造体はクロージャを実行し、その結果の値をキャッシュすることで、残りのコードは、結果を保存し、再利用する責任を負わないで済むようにするパターン
一連の要素をイテレータで処理する
イテレータ: 各要素を繰り返し、シーケンスが終わったことを決定するロジックの責任を負う。
イテレータを使用すると、自身でそのロジックを再実装する必要がなくなる
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
v1_iterを可変にしているのは、イテレータのnextメソッドを呼び出すと、今シーケンスのどこにいるかを追いかけるためにイテレータが使用している内部の状態が変わるため。
イテレータを消費するメソッド
nextを呼び出すメソッドは、消費アダプタと呼ばれる。
呼出しがイテレータの使い込みになるため。
他のイテレータを生成するメソッド
Iteratorトレイトに定義された他のメソッドは、イテレータアダプタとして知られている。
イテレータを別の種類のイテレータに変えさせてくれる。
let v1: Vec<i32> = vec![1, 2, 3];
v1.iter().map(|x| x + 1).collect();
collectメソッドはイテレータを消費し、結果の値をコレクションデータ型に集結させる。