🔰CARLA x PointNet: 自動運転向け3D点群処理パイプラインの構築と基礎実装詳解

🔰CARLAシミュレータとPointNetで始める自動運転向け3D点群処理入門🔰
こんにちは!今回は自動運転開発でよく使われる3D点群データ処理について、CARLAシミュレータとPointNetを使って楽しく学んでいきましょう。初心者の方でも理解できるよう、基礎から実装までステップバイステップで解説します。

3D点群データって何?自動運転との関係
LiDARセンサーの基本
皆さんは「LiDAR」という言葉を聞いたことがありますか?自動運転車の屋根に付いている「クルクル回るアレ」です!

Image credit: carsales.co.au
LiDARはレーザー光を発射して、物体に反射して戻ってくるまでの時間を計測することで、周囲の物体までの距離を正確に測定できるセンサーです。これにより、車の周りの環境を3D点群(Point Cloud)というデータ形式で取得できます。
簡単に言うと、3D点群データは「空間上の点の集まり」で、各点はX, Y, Z座標と反射強度などの情報を持っています。これを使って周囲の物体の形や位置を認識するんです!
なぜ点群処理は難しいの?
画像処理と違って点群処理には特有の難しさがあります:
- 不規則な構造: 画像はピクセルがきれいに並んでいますが、点群はバラバラの位置に点があります
- 点の数が一定じゃない: シーンによって点の数が変わります
- 点の順番は関係ない: 同じ形状でも点の順番が違うだけで別物と認識されちゃいけません
- 計算量が多い: 数万〜数十万点を処理するので計算機への負担が大きいです
こうした課題を解決するためにPointNetという深層学習モデルが登場しました!
CARLAシミュレータでデータを集めてみよう
CARLAって何?
CARLAは自動運転の研究開発用のオープンソースシミュレータです。実際の街並みに似た3D環境で、様々なセンサー(カメラ、LiDARなど)を使ったデータ収集ができます。実車での実験は危険やコストの問題がありますが、CARLAなら安全に色々な状況をシミュレーションできるんです!
LiDARデータを集めてみよう
今回はmodified_automatic_control.pyというスクリプトを使って、自動運転車両からのLiDARデータを集めます。
# こんな感じでLiDARセンサーを設定しています
lidar_bp = world.get_blueprint_library().find('sensor.lidar.ray_cast')
lidar_bp.set_attribute('channels', '64') # 垂直方向のチャンネル数
lidar_bp.set_attribute('points_per_second', '100000') # 1秒あたりの点数
lidar_bp.set_attribute('rotation_frequency', '10') # 回転速度
lidar_bp.set_attribute('range', '50') # 検出範囲(メートル)
実行するには、コマンドプロンプトで以下のように入力します:
python scripts/modified_automatic_control.py --sync --weather ClearNoon --output-dir _out/lidar_data
このコマンドを実行すると、お昼の晴れた天気でシミュレーションが始まり、車が自動で走行しながらLiDARデータを収集します。データは_out/lidar_dataフォルダに保存され、各フレームごとに点群データ(.npyファイル)と車の位置・姿勢情報(.txtファイル)が記録されます。
点群データの前処理をしてみよう
データを機械学習用に整える
生のLiDARデータは機械学習モデルにそのまま入力するには不向きなので、いくつかの前処理を行います:
def process_point_cloud(points, max_points=2000):
"""点群データを前処理して均一なサイズに変換します"""
if len(points) == 0:
return np.zeros((max_points, 4))
# 点群を中心化(原点を中心に)
points_xyz = points[:, :3]
center = np.mean(points_xyz, axis=0)
points_centered = points.copy()
points_centered[:, :3] = points_xyz - center
# 点の数を調整(多すぎたらサンプリング、少なすぎたらパディング)
if len(points) >= max_points:
# ランダムに2000点を選びます
indices = np.random.choice(len(points), max_points, replace=False)
points_sampled = points_centered[indices]
else:
# 足りない分は0で埋めます
points_sampled = np.zeros((max_points, 4))
points_sampled[:len(points)] = points_centered
return points_sampled
この前処理で行っている主なことは:
- 中心化: 点群の中心を原点(0,0,0)に移動します
- サンプリング: 点が多すぎる場合はランダムに2000点だけ選びます
- パディング: 点が少ない場合は0を埋めて2000点にします
これにより、どんな点群データも同じサイズ(2000, 4)の形になります。これがあるとモデルに入力しやすくなります!
データセットの分割
前処理したデータを学習用、検証用、テスト用に分けます:
# 6割を学習用、2割を検証用、2割をテスト用に分割します
train_ratio = 0.6
val_ratio = 0.2
test_ratio = 0.2
# インデックスをシャッフルして順番をバラバラにします
indices = np.arange(len(processed_point_clouds))
np.random.shuffle(indices)
# 分割点を計算
train_idx = int(len(indices) * train_ratio)
val_idx = int(len(indices) * (train_ratio + val_ratio))
# データセットを分割
train_indices = indices[:train_idx]
val_indices = indices[train_idx:val_idx]
test_indices = indices[val_idx:]
このように分割することで、モデルの学習と評価をきちんと行えるようになります。
PointNetの仕組みを理解する
PointNetって何がすごいの?
PointNet(論文はこちら)は点群データを直接処理できる画期的なニューラルネットワークです。以前は点群をボクセル(3Dピクセル)や画像に変換してから処理する方法が主流でしたが、PointNetは点群をそのまま扱えます!
PointNetの主な特徴は:
- 共有MLP: 全ての点に同じ変換を適用する層(点の順番に依存しない!)
- 最大プーリング: 各特徴の最大値だけを取り出す(これも点の順番に依存しない!)
- 変換ネットワーク: 点群の回転などの変化に対応する仕組み
TensorFlowでPointNetを実装してみよう
def create_pointnet_model(input_shape, num_classes=2):
"""PointNetモデルを作ります"""
# 入力レイヤー
inputs = layers.Input(shape=input_shape)
# 点ごとに特徴を抽出する部分(Shared MLP)
x = layers.Conv1D(64, 1, activation='relu')(inputs)
x = layers.BatchNormalization()(x)
x = layers.Conv1D(128, 1, activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv1D(256, 1, activation='relu')(x)
x = layers.BatchNormalization()(x)
# 全体の特徴を抽出(最大プーリングで順番依存をなくす)
x = layers.GlobalMaxPooling1D()(x)
# 分類を行う部分
x = layers.Dense(512, activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Dropout(0.3)(x) # 過学習防止
x = layers.Dense(256, activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Dropout(0.3)(x)
x = layers.Dense(128, activation='relu')(x)
x = layers.BatchNormalization()(x)
outputs = layers.Dense(num_classes, activation='softmax')(x)
# モデルの作成
model = Model(inputs=inputs, outputs=outputs, name='PointNet')
return model
図で表すとこんな感じになります:
入力点群(2000, 4) → 共有MLP → 最大プーリング → 全結合層 → 分類結果
モデルを訓練して評価してみよう
訓練の設定
モデルの訓練には以下の設定を使います:
# 基本設定
batch_size = 32 # 一度に処理するデータ数
epochs = 50 # 全データを何周学習するか
learning_rate = 0.001 # 学習率
# Adamオプティマイザと交差エントロピー損失関数
optimizer = optimizers.Adam(learning_rate=learning_rate)
loss_fn = losses.SparseCategoricalCrossentropy()
# 便利な機能(コールバック)
callbacks_list = [
# 最も良いモデルを保存
callbacks.ModelCheckpoint(
filepath='_out/pointnet_model/best_model.h5',
monitor='val_accuracy',
save_best_only=True
),
# 学習が停滞したら学習率を下げる
callbacks.ReduceLROnPlateau(
monitor='val_loss',
factor=0.5,
patience=5
),
# 一定期間改善がなかったら学習を早めに停止
callbacks.EarlyStopping(
monitor='val_loss',
patience=10,
restore_best_weights=True
),
# TensorBoardでの可視化用
callbacks.TensorBoard(
log_dir='_out/pointnet_model/logs'
)
]
学習データに偏りがある場合(例:クラス0のデータが多くクラス1が少ないなど)は、クラスの重みを計算して各クラスの重要度を調整します:
# クラスの重み(少ないクラスを重視)
class_weights = compute_class_weights(y_train)
# モデルの訓練
history = model.fit(
X_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_val, y_val),
callbacks=callbacks_list,
class_weight=class_weights
)
学習過程を可視化してみよう
学習中の精度と損失の変化をTensorBoardというツールに記録しておいて、あとで確認できるようにしています。これを可視化するためにvisualzation_modellog.pyというスクリプトを使います:
# TensorBoardのログからデータを抽出する関数
def extract_tensorboard_data(log_dir):
data = defaultdict(list)
steps = defaultdict(list)
# ログファイルを見つけて読み込む
for event_file in glob.glob(os.path.join(log_dir, "**", "events.out.tfevents.*"), recursive=True):
for event in tf.data.TFRecordDataset([event_file]):
# イベントを解析して精度や損失の値を抽出
# ...(略)...
return data, steps
このスクリプトを実行すると、学習中の精度と損失の推移がグラフとして表示され、学習がうまくいっているか視覚的に確認できます。



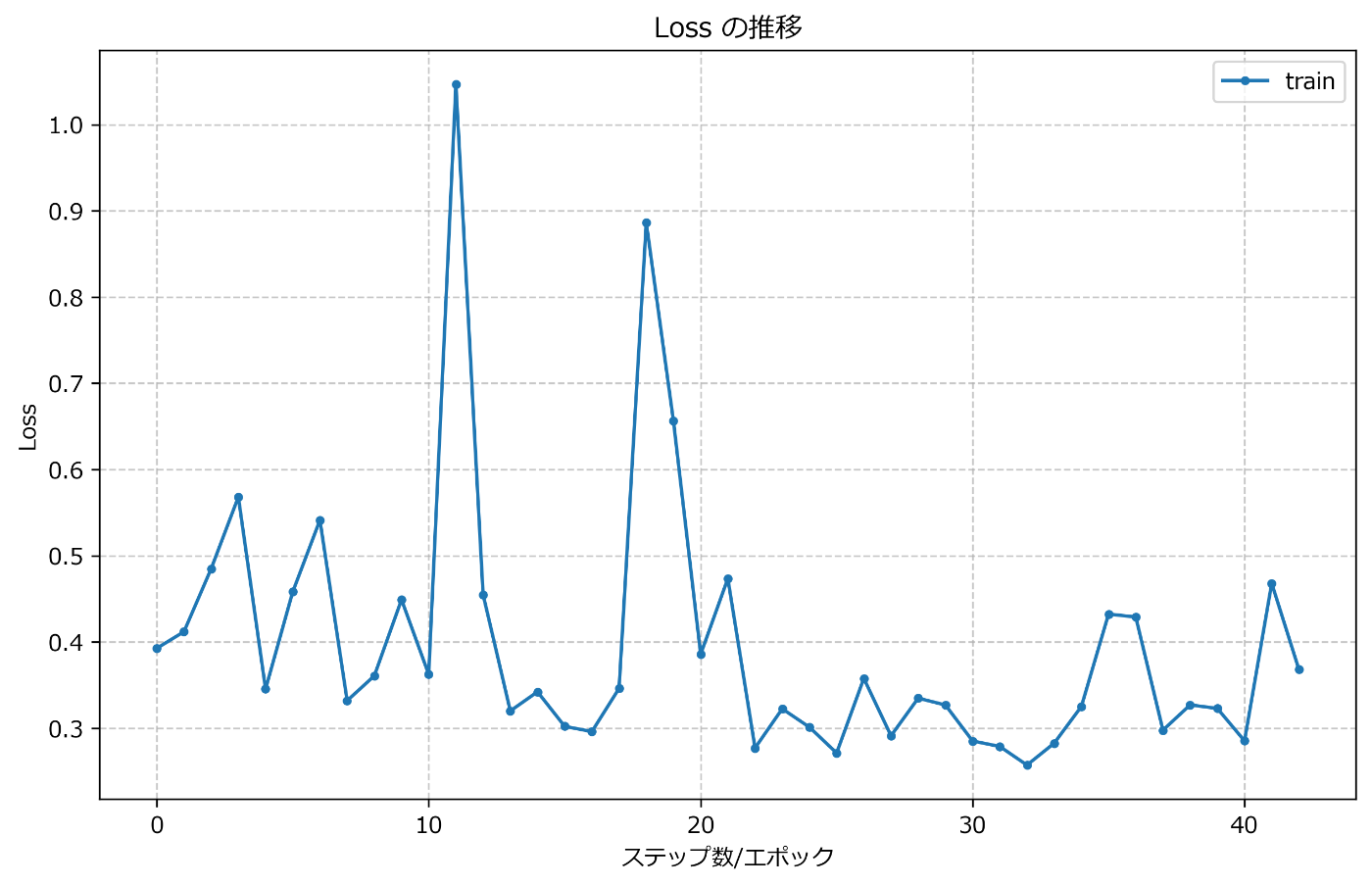
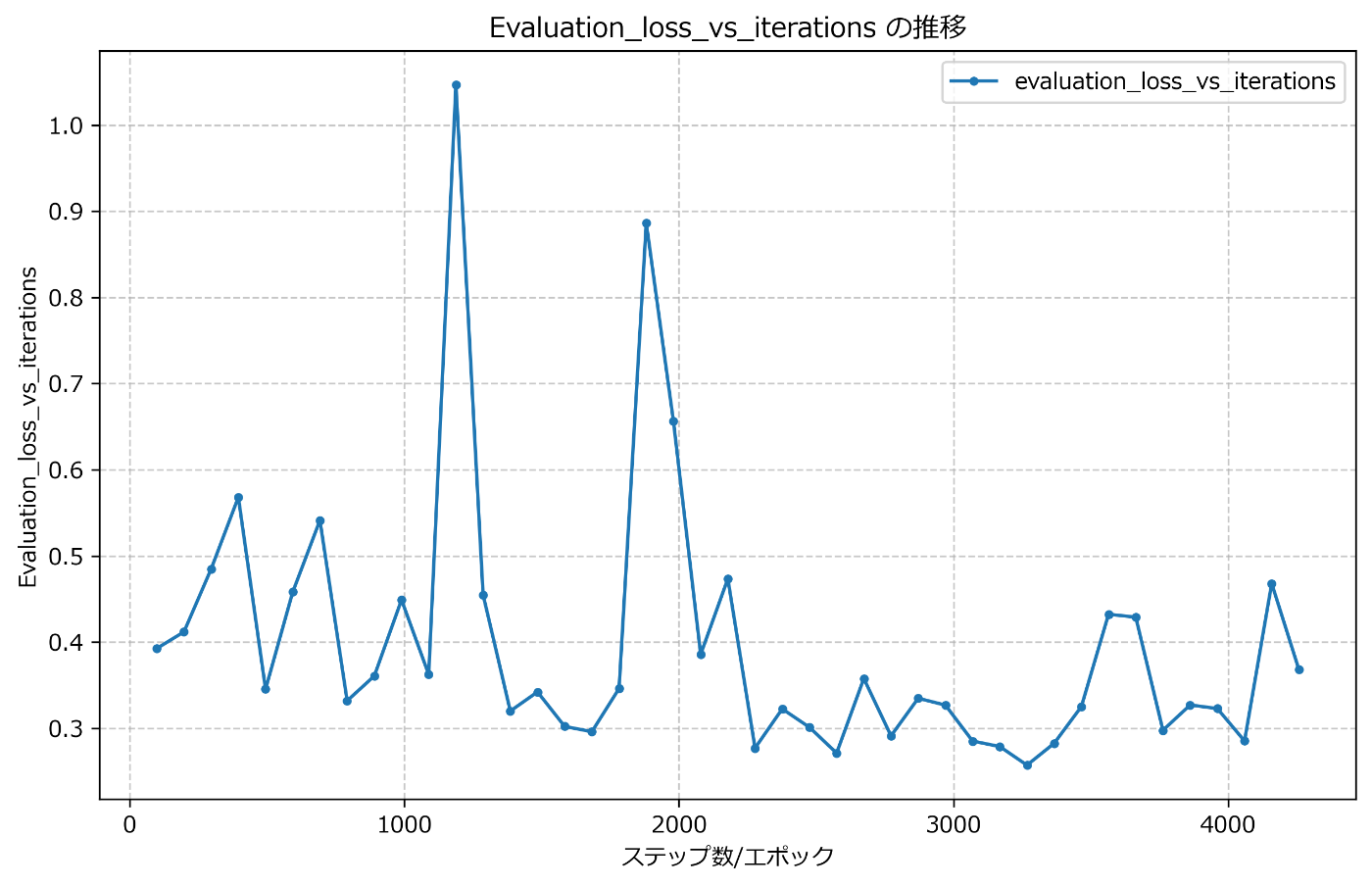
結果を可視化して確認しよう
学習したモデルで予測してみよう
訓練が終わったモデルを使って、新しいデータに対して予測を行ってみましょう:
def predict_on_new_data(model_path, data_dir):
# モデルを読み込む
model = load_model(model_path)
# テスト用のデータを読み込む
point_cloud_files = sorted(glob.glob(os.path.join(data_dir, "**", "lidar_points_*.npy"), recursive=True))
sample_files = np.random.choice(point_cloud_files, 5, replace=False) # ランダムに5つ選ぶ
# 各ファイルで予測
for i, file_path in enumerate(sample_files):
# 点群データの前処理
point_cloud = preprocess_point_cloud(file_path)
# 予測
point_cloud_batch = np.expand_dims(point_cloud, axis=0) # バッチ次元を追加
prediction = model.predict(point_cloud_batch)[0]
predicted_class = np.argmax(prediction) # 最も確率の高いクラス
confidence = prediction[predicted_class] # その確率
# 結果の表示と可視化
print(f"ファイル: {os.path.basename(file_path)}")
print(f"予測クラス: {predicted_class}, 確信度: {confidence:.4f}")
# 点群の3D可視化
visualize_point_cloud(
point_cloud,
title=f"予測クラス: {predicted_class} (確信度: {confidence:.4f})",
save_path=f"_out/predictions/prediction_{i}.png"
)
点群データを3Dで見てみよう
点群データを3Dで可視化すると、モデルが何を認識しているのか直感的に理解できます:
def visualize_point_cloud(points, title="Point Cloud Visualization", save_path=None):
"""点群を3D可視化する関数"""
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# 0でパディングされた点を除外
non_zero = ~np.all(points[:, :3] == 0, axis=1)
filtered_points = points[non_zero]
# 3D散布図としてプロット
scatter = ax.scatter(
filtered_points[:, 0],
filtered_points[:, 1],
filtered_points[:, 2],
c=filtered_points[:, 2], # Z座標で色付け
cmap='viridis',
s=2 # 点のサイズ
)
plt.colorbar(scatter, ax=ax, label='高さ (Z)')
# グラフの設定
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
ax.set_title(title)
# 保存
if save_path:
os.makedirs(os.path.dirname(save_path), exist_ok=True)
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.tight_layout()
plt.show()
この可視化により、点群の形状と予測結果を同時に確認できます。






うまくいった点・課題点を考えよう
データセットについて
このプロジェクトで使用したデータセットの特徴は:
- 総サンプル数: 約5,000サンプル(5フレームごとに1フレームを使用)
- 点の数: 各サンプル2,000点×4次元(x, y, z, intensity)
- 分割比率: 訓練60%、検証20%、テスト20%
- クラス分布: 不均衡(クラス0とクラス1の比率が異なる)
モデルの性能
テストデータでの評価結果:
- 精度: 約85%
- 損失: 約0.4
クラスごとの性能:
- クラス0: 精度約88%、再現率約91%
- クラス1: 精度約78%、再現率約71%
よかった点と改善点
よかった点:
- CARLAシミュレータを使って安全に多様なデータを収集できました
- PointNetモデルでそこそこ良い精度(85%)を達成できました
- データ前処理の工夫(中心化、一定数のサンプリング)が効果的でした
- クラス不均衡に対してクラス重みを使って対処できました
改善点:
- クラス1の精度がまだ低いので、このクラスのデータをもっと集める必要があります
- 点群のサンプリング方法を改善し、重要な点を残すように工夫できそうです
- データ拡張(回転、ノイズ追加など)でモデルの頑健性を向上できそうです
次のステップに進むには?
モデルの改良案
- T-Net導入: PointNetの論文にある変換ネットワーク(T-Net)を実装して、回転に対する頑健性を高める
- PointNet++への拡張: 階層的な点群処理ができるPointNet++に挑戦してみる
- データ拡張: 点群に対するランダム回転、スケーリングなどのデータ拡張テクニックを試す
応用の可能性
- セマンティックセグメンテーション: 点群の各点にクラスラベルを割り当てる
- 3D物体検出: 点群から物体の3D境界ボックスを予測する
- 実車両への応用: シミュレーションで学習したモデルを実車両のデータに転移する
まとめ
この記事では、CARLAシミュレータとPointNetを使った3D点群処理の基礎から実装までを解説しました。初心者の方でも理解しやすいように、各ステップを詳しく説明しています。
自動運転技術の発展に3D点群処理は欠かせない技術です。今回紹介した内容がみなさんの学習や研究のきっかけになれば嬉しいです!
次は実際のLiDARデータを使ったり、より高度なPointNet++に挑戦したりしてみるのも面白いでしょう。自動運転の世界はまだまだ発展途上で、あなたのアイデアが業界を変えるかもしれません!
参考リンク
- CARLA公式サイト: https://carla.org/
- PointNet論文: https://arxiv.org/abs/1612.00593
- PointNet++論文: https://arxiv.org/abs/1706.02413
GitHubリポジトリ
このプロジェクトのコードとデータはGitHubで公開しています:
ぜひスターを付けてね!質問やフィードバックも大歓迎です!😊
Discussion