Pythonで作る!文章要約アプリケーション





はじめに
皆さん、こんにちは!最近spaCyを学んだ成果として文章要約アプリケーションを作成したので、その開発過程と成果を皆さんと共有したいと思います。初心者の視点から、つまずいたポイント、解決策などを含めて、詳しくお話しします。
実行環境
- Python 3.8以上
- tkinter(GUIライブラリ)
- spaCy(自然言語処理ライブラリ)
- NetworkX(グラフ理論ライブラリ)
- scikit-learn(機械学習ライブラリ)
- docx2txt(Wordファイル読み込み用)
- PyPDF2(PDFファイル読み込み用)
必要条件
アプリケーションを動作させるには、以下のコマンドを実行してライブラリをインストールする必要があります:
pip install spacy networkx scikit-learn docx2txt PyPDF2
python -m spacy download ja_core_news_sm
python -m spacy download en_core_web_sm
最後の2行は、日本語と英語の言語モデルをダウンロードするコマンドです。これらのモデルは結構サイズが大きいので、ダウンロードに少し時間がかかる場合があります。
Githubダウンロード
以下のリンクからGithubに飛んでダウンロード
もしくはリポジトリのクローンをしてください。
使い方
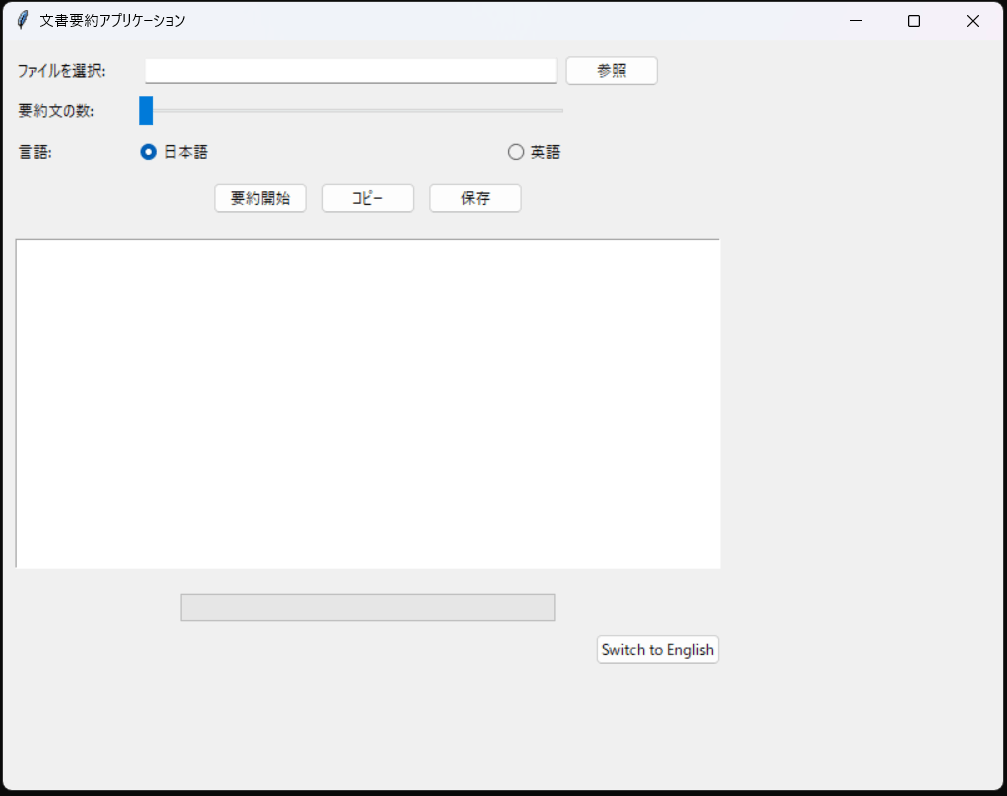
- 「ファイルを選択:」の横にある「参照」ボタンをクリックして、要約したいファイルを選択します。
- 「要約文の数:」のスライダーを使って、生成したい要約文の数を調整します。
- 「言語:」のセクションで、入力文書の言語を選択します。「日本語」か「英語」のいずれかを選びます。
- 設定が完了したら、「要約開始」ボタンをクリックして要約プロセスを開始します。
- 要約結果は下部の大きなテキストエリアに表示されます。
- 要約が生成されたら、「コピー」ボタンをクリックしてクリップボードにコピーするか、「保存」ボタンをクリックしてファイルとして保存することができます。
- 画面下部のプログレスバーは、要約処理の進行状況を示します。
- 右下の「Switch to English」ボタンをクリックすると、アプリケーションの言語を英語に切り替えることができます。
主な機能
では、実装した主な機能について、詳しく解説していきます。
多言語対応
日本語と英語の両方に対応させました。最初は日本語だけで良いかなと思っていたのですが、せっかくなら英語にも対応させようと思い実装しました。
ユーザーインターフェースも言語切り替えが可能です。これは、辞書型のデータ構造を使って実現しました。例えば:
translations = {
'ja': {
'title': "文書要約アプリケーション",
'file_select': "ファイルを選択:",
# ... 他の翻訳項目 ...
},
'en': {
'title': "Document Summarization App",
'file_select': "Select a file:",
# ... 他の翻訳項目 ...
}
}
このように定義しておくことで、言語切り替えがとてもスムーズになります。
複数のファイル形式サポート
テキストファイル(.txt)、Wordファイル(.docx)、PDFファイル(.pdf)の3種類のファイル形式に対応させました。自己満です。
ただし、PDFファイルについては、PyPDF2に依存しているため、
PDFの構造によっては正確にテキストを抽出できないケースがあります。この点は、今後の改善ポイントの一つです。
TextRankアルゴリズムによる要約
TextRankアルゴリズムは、Googleの検索アルゴリズムとして有名なPageRankを、テキスト要約に応用したものです。
基本的な流れは以下の通りです:
- テキストを文単位に分割
- 各文をベクトル化し、文同士の類似度を計算
- 文の重要度をグラフ理論に基づいて計算
- 重要度の高い文を抽出して要約を生成
カスタマイズ可能な要約長
ユーザーが要約の長さを自由に調整できるようにするため、tkinterのScaleウィジェットを使用しました。1文から10文までの範囲で調整可能です。
self.num_sentences = ttk.Scale(main_frame, from_=1, to=10, orient=tk.HORIZONTAL, length=200)
結果のコピー及び保存機能
要約結果のコピーや保存機能も実装しました。これは、tkinterのclipboard_clear()とclipboard_append()メソッド、そしてfiledialogモジュールを使用しています。
def copy_summary(self):
summary = self.output_text.get(1.0, tk.END)
self.clipboard_clear()
self.clipboard_append(summary)
messagebox.showinfo("情報", "要約がクリップボードにコピーされました!")
つまずいたポイントと解決策
- PDFファイルからのテキスト抽出の精度
【問題点】
- PyPDF2を使用してPDFファイルからテキストを抽出する際、レイアウトが複雑なPDFや画像を多く含むPDFで正確にテキストを抽出できないケースがありました。
【解決策】
- OCRツールの導入を検討しましたが、実装の複雑さを考慮し、現段階では見送りました。
- 将来的には、より高度なPDF解析ライブラリ(例:pymupdf)の導入を検討しています。
- 長い文章の処理時間
【問題点】
- 非常に長い文章(例:数百ページの小説)を処理する際、アプリケーションの応答が遅くなり、ユーザーエクスペリエンスが低下しました。
【解決策】
- 処理をバックグラウンドスレッドで実行するようにコードを修正しました。これにより、UIがフリーズすることなく、プログレスバーで進捗を表示できるようになりました。
- 大きなテキストを分割して処理する機能を追加し、メモリ使用量を最適化しました。
- 将来的には、より効率的なアルゴリズムの導入や、分散処理の実装を検討しています。
まとめ
GUIアプリケーションの作成、自然言語処理の基礎、ファイル操作、そしてアルゴリズムの実装と異なる要素を一つのアプリケーションに統合する過程で全体の構造が見えないなかでの実装に苦戦しました。また、アルゴリズムの実装だけでなく、ユーザビリティやパフォーマンスの最適化も非常に重要であることを実感し、より使いやすいアプリケーションUIにしたいと考えるようになりました。
Discussion