TL;DR
- 現代風デザインの歴史地図サービス「れきちず」の、ひらがな・英語表示
- 地図データへのひらがな・英語情報付与
- 大量の地名を扱うため、OpenAI APIを活用
- 精度は約9割。全出力を手動確認・修正
- データ量が膨大なものは、LLMではなくルールベースで処理
- SvelteKitアプリの国際化(i18n)
- i18nライブラリParaglide JSを導入
- Claude Codeにより、実装とUI文言の翻訳を効率化
「れきちず」とは
私たちMIERUNEは位置情報の専門家集団です。歴史的な地図を現代の地図感覚で楽しめるウェブサービス「れきちず」を開発しています。
本プロジェクトは、当社デザイナー@chizutodesignが2023年に趣味で始めたものが発端です。その後、会社へ移管され、エンジニアとの協働により、機能が大きく拡充されていっています。
先日(2025年10月)開催されたFOSS4G 2025 Japanでは、プロジェクトのこれまでとこれからについてお話ししました。
発表では、今後のアイデアとして「多言語化対応」を挙げました。幅広い層へ向け、さまざまな言語や表記での表示を提供するというものです。

イベント後に改めて検討したところ、複数のツールやサービスを活用することで短期間での実現が可能と判断。実際に約3週間で完了させることができました。
これにより、より幅広い層の利用が可能となり、「誰にでもわかりやすい歴史地図」というコンセプトの実現に寄与できたと考えています。
多言語・表記、具体的には「ひらがな」「英語」への対応には、「地図データ(地名)」と「アプリ」、それぞれに対処する必要がありました。
地名への「ひらがな」「英語」表記の付与
まず、地図データ(地名)の処理です。各地名に「ひらがな(読み)」と「英語(翻字・翻訳)」を付与する必要があります。
れきちずのデータ
れきちずには、@chizutodesignが全国の図書館を巡ったりして大量の文献から作成したデータがあります。
POI(Point of Interest, お寺やお城など地点)だけでなく、道路や河川、境界線など、様々な種類の情報が含まれます。地物数は合計約1.2万件。そのうちの約8,000件に、名前が付与されています。


これに加えて、れきちずには外部データも掲載されています。今回はROIS-DS人文学オープンデータ共同利用センターとの連携による、以下2点のデータセットを対象として、ひらがな・英語付与を行いました。
- 『日本歴史地名大系』地名項目データセット(ジャパンナレッジで公開する平凡社刊行の『日本歴史地名大系』(全50巻)を元にしたデータ - 約8万件)
- 江戸マップ地名データセット(江戸切絵図「尾張屋版」を元にしたデータ - 約8,000件)
英語表記の基準
一貫性を持って英語表記を付与するために、基準が必要です。今回は、国土交通省国土地理院が提供する以下の文書をベースにしました。
ここで述べられる適用ルールには「置換方式」と「追加方式」があります。
置換方式では、例えば 筑波山 を、 筑波(Tsukuba) + 山(san) と捉え、sanをMt.に置き換え Mt. Tsukuba とします。
置換方式の英語から元の日本語の地名を認識することが困難な場合は「追加方式」を適用します。例えば 荒川 が Ara River では認識が困難なため Arakawa River とします。また他の例として、 八重干瀬 は名称にサンゴ礁が含まれず置換方式は適用不能であるため Yabiji Coral Reef とします。
詳細はぜひ上記の元資料をご覧ください。

これに加え、れきちずではその性質上、現代の地図では見られない歴史的な地名・地物が多く含まれます。それらの英語表記を定めるにあたっては、地理院の基準を参考にしつつ、プロジェクト内で独自の表記ルールを制定しました。
例えば、「茶屋」は Teahouse のような説明的な名称ではなく、地名にハイフンを付けて -chaya と表記する形式に統一しました。ルールの一部を以下に紹介します。
- 関所:
Barrier(例:Hakone Barrier) - 番所:
Guardhouse(例:Hyakunin Bansho Guardhouse) - 口留番所:
Checkpoint - 遠見番所:
Lookout - 奉行所:
Site - 河岸:
Wharf(例:Kisarazu-gashi Wharf) - 新田:
Shinden(New Fieldsとすると冗長になるため) - 宿:
-shuku,-juku(Naito-shinjukuのようにハイフンがない場合もある)
手法の検討: LLM+人手修正 / ルールベース
対象となるデータ量は以下の通りです。
- れきちず本体データ: 約8,000件
- 外部データ「『日本歴史地名大系』地名項目データセット」: 約8万件
- 外部データ「江戸マップ地名データセット」: 約8,000件
全てに人手でひらがな・英語を付与するには多大な労力を要するため、一定の自動処理を導入することにしました。
パターンマッチや形態素解析器などを用いた古典的な自然言語処理手法も検討しましたが、サンプルでの試行結果を踏まえ、LLMによる処理をベースとする方針を採用しました。
ただし、LLM出力には誤りが含まれるため、これら全数を人手で確認・修正しました。ゼロから人手で作業するのではなく、一定の品質を持つLLM出力を起点とすることで、人的コストを大幅に削減できます。このアプローチは、私が以前関わったNLPによる個人情報の仮名化(民事判決のオープンデータ化)と同様の考え方です。
ただし後述するように、データ量が膨大な一部データセットについては、LLMではなくルールベースでの処理を行いました。
OpenAI APIによる付与
LLMを用いた処理には、最終的にOpenAI APIを利用しました。
予備調査の段階では、ChatGPT、Claude、Geminiのプロンプトに直接データファイルを渡す方法を試しました。しかし、ファイルサイズが一定以上になると処理できなくなりました。これはGPTsでも同様でした。
そこで、Pythonスクリプトでデータを前処理し、OpenAI API経由で処理する方式に切り替えました。出力結果は改めてPythonで元のデータへ統合します。
まず、先述した地理院の英語表記規程や独自ルールを記述したファイルをAPI経由でアップロードしました。
DPATH_REFERENCE = Path("../reference")
reference_file_paths = [
DPATH_REFERENCE / "000138865.pdf",
DPATH_REFERENCE / "000138867.pdf",
DPATH_REFERENCE / "れきちず翻訳案.pdf",
]
file_ids = []
for path in reference_file_paths:
f = client.files.create(file=open(path, "rb"), purpose="assistants")
print(f"Uploaded {path} → {f.id}")
file_ids.append(f.id)
その上で、以下のプロンプトで処理を指示しました。
SYSTEM_PROMPT = """
あなたは、日本の地名表記に関する専門家であり、
以下の3つの公式資料(添付ファイルとして提供)に基づいて地名の読み(ひらがな)および英語表記(ローマ字+地形語)を付与します。
## 参照資料(すでに添付済み)
1. 000138865.pdf:「地名等の英語表記規程」全文(国土地理院公式文書)
2. 000138867.pdf:「資料-1 地名等の英語表記ルール概要」
あなたはこれらの資料を参照し、そこに定義された原則・例・方針に従って出力してください。
### 基本ルール
- 読みはひらがな表記(現代仮名遣い)
- ローマ字はヘボン式(長音省略、促音は重ね、"ん"→n)
- ハイフン(-)は複合要素や接頭語(東・西・新・旧など)の直後に使用
### 備考欄の使用
- 必要がない場合は空欄にすること
- 以下の場合に備考欄を使用:
- 資料に記載のない特殊なケースの判断理由
- 複数の解釈が可能な場合の選択根拠
- 歴史的表記と現代表記の相違点
"""
当初は平文で出力していましたが、MIERUNE同僚のNEKOYASANさんからStructured Outputsの存在を教えてもらい、出力の型定義を導入しました。
class Feature(BaseModel):
original: str
name_hira: str
name_en: str
note: str | None = None
class FeatureList(BaseModel):
features: List[Feature]
def process_batch(batch_names):
user_text = "以下の地名を変換してください:\n" + "\n".join(batch_names)
response = client.responses.parse(
model=MODEL,
input=[
{
"role": "system",
"content": [{"type": "input_text", "text": SYSTEM_PROMPT}],
},
{
"role": "user",
"content": [
{
"type": "input_text",
"text": user_text,
},
*[{"type": "input_file", "file_id": fid} for fid in file_ids],
],
},
],
text_format=FeatureList,
)
return response.output_parsed
100語ごとにバッチ処理し、結果を統合して元データへ反映しました。
モデル選定では、当初gpt-4.1-miniを使用していました(gpt-5-nanoより圧倒的に速かった)。しかし最終的には品質を優先し、gpt-5-miniを採用しました。
れきちず本体データ約8,000件の全数処理に5時間程度、料金は数ドル程度でした。
今回初めてOpenAI APIを利用しましたが、新旧さまざまな仕様が混在しており、最初は戸惑いました。ChatGPTに質問しても古い情報が返ってくることがあり、少し混乱しました。ただし、仕様を把握してからは、比較的スムーズに利用できるようになりました。
ルールベースによる付与
「『日本歴史地名大系』地名項目データセット」については、約8万件と膨大なこと、また元データにひらがな(読み)が付与されていることもあり、ルールベースで対応しました。
ルールベースでは統計的手法と異なり、出力を厳密にコントロールできます。そのため、このデータセットについては人手での確認・修正を行いませんでした。
具体的には、Pythonライブラリjaconvを用いて、ひらがな(読み)からヘボン式ローマ字へ変換しました。
その際、頻出する一部の表記は英語翻訳を適用しました。全8万件の末尾バリエーションを確認すると、以下の結果が確認できました。
-
-村: 81.8% -
-町: 10.4% -
-新田: 2.6%
この結果を踏まえ、-村という表記に限り、muraではなくVillageへ変換しました。
ただし、イレギュラーな読みを持つ地名は除外しています。例えば、琉球には「久米村(くにんだ)」という地名があり、これはKunindaとしています。
以下に、変換スクリプトの一部を紹介します。
from jaconv import kana2alphabet
def yomi_to_en(kanji, yomi):
# 「村」を含むケース
if kanji.endswith("村"):
# 想定内の読み(「〜むら」「〜そん」)の場合
if yomi.endswith("むら") or yomi.endswith("そん"):
return kana2alphabet(yomi[:-2]).capitalize() + " Village"
# 括弧を含む場合
elif "(" in yomi and yomi.endswith(")"):
assert yomi.count("(") == 1 and yomi.count(")") == 1
yomi_1, yomi_2 = yomi.split("(")
yomi_2 = yomi_2[:-1] # 末尾の括弧 ")" を削除
assert yomi_1.endswith("むら") or yomi_1.endswith("そん")
en_str = (
kana2alphabet(yomi_1[:-2]).capitalize()
+ " Village"
+ f" ({kana2alphabet(yomi_2).capitalize()})"
)
print(f"⚙️ 「村」(括弧を含む): '{kanji}', '{yomi}' => '{en_str}'")
return en_str
# それ以外の想定外の読みの場合 - Villageとせず、読みをそのままローマ字化
else:
print(f"⚠️ 「村」(想定外の読み): {kanji}, {yomi}")
return kana2alphabet(yomi).capitalize()
# それ以外の全て
return kana2alphabet(yomi).capitalize()
LLM出力の人手修正
上記のLLM出力を元に、人間(@chizutodesign)が全件を確認・修正しました。
実作業を担当した彼からは「正解率は90%台前半くらい」「難読地名にやや弱い印象だが、ほぼ人間を超えているのではないか(れきちずを作る前の自分だったら知らなかったかも・・・)」とのコメントがありました。
専門家ではない私から見ると、読めない地名も多々あり、LLM出力の方がはるかに高品質に感じられました。
出力結果を見ると、曖昧性があってこれは間違えるなと納得できる誤りが多い印象でした。つまり、一般的に読める地名は、ほぼ正確に処理されていました。
例えば「御城」という地物は、LLMは Oshiro Castle と判断していましたが、人間により Edo Castle と修正されました。
作業自体は、1,400件を修正した時点で実働3時間くらいでした。れきちず地名約8,000件を全て確認・修正するのに数日かかりました。
余談ですが、処理しているときに「野根」という地名の英語表記が None なため不具合が生じたのが面白かったです。詳細は以下の記事で述べました。
地図タイルとスタイルの作成
れきちずは、Web地図ライブラリMapLibre GL JSとベクトルタイルを採用しています。
上記のひらがな・英語情報を付与したデータを元に、tippecanoeで「地図タイル」を生成しました。
その上で、このタイルを元にした「地図スタイル」を、各表記用に3種類、作成しました。
スタイルファイルはGitHubレポジトリで管理しており、人間がスタイルエディタMaputnikなどを用いて編集しています。スタイルファイルの多重管理は避けたいため、元となるオリジナルの style.json のみを編集し、他二つの表記のスタイルファイルはGitHub Actionsを用いてスクリプトで自動生成しています。
れきちずのタイルデータ・スタイルは一般公開しており、CC BY-NC-ND 4.0の下、自由に利用することが出来ます。
スタイルのURLは、以下の通りです。
- 日本語: https://mierune.github.io/rekichizu-style/styles/street/style.json
- ひらがな: https://mierune.github.io/rekichizu-style/styles/street/style_hira.json
- 英語: https://mierune.github.io/rekichizu-style/styles/street/style_en.json
詳細はれきちずホームページをご覧ください。
参考: OpenStreetMapスタイルのひらがな・英語化
れきちずでは、江戸時代の地図に加えて、現代地図も比較用に提供しています。現代地図には、オープンデータの地図プロジェクト「OpenStreetMap(OSM)」を利用しています。
OSMデータを元に、れきちずのデザインに合わせた独自スタイルを作成しています。

OpenStreetMapには多言語・多表記の情報が含まれているため、これを利用して各表記のスタイルを作成しました。
元のスタイルでは、以下のように複数のプロパティをcoalesce式でフォールバックして表示しています。
["coalesce", ["get", "name:ja"], ["get", "name"], ["get", "name:en"]]
ひらがなの場合は、ja-Hiraとname:ja_kanaというプロパティを利用します。
英語の場合は、name:en、name:ja-Latn、name:ja_rmというプロパティを利用します。
ja-Hira, ja-LatnはBCP 47に則った形式のタグですが、その他にも伝統的に使われているタグ ja_kana, ja_rm がありました。
OSMでは、全ての地物に各表記でのデータが記載されているわけではありません。しかし、これはオープンなプラットフォームであるため、誰でもデータを編集・追加できます。不足している情報があれば、自らコントリビュートすることで地図を改善できます。
余談ですが、元々のスタイルではLINE Seedというフォントを利用していました。しかし、このフォントには「マクロン」(長音符記号、Tōkyō の ō)がありませんでした。れきちずデータでは長音符表記を採用していないため問題ありませんでしたが、OSMデータにはこの表記があります。そのため最終的には、OSMの英語スタイルに関しては、別のフォント(Lexend Deca)を利用することにしました。
改善の可能性
今回の人手修正を元に、それら事例をプロンプトなどに含めてLLMへ渡すことで、出力結果が改善する余地があるでしょう。
ただし、文脈がないと人間でも判断しようがないケース(例えば「神奈川県の大山(おおやま)」「鳥取県の大山(だいせん)」)は、与えられたデータだけでは正答できません。元データにある座標情報も併せて提供することで、LLMがより適切に判断できるかもしれません。
他には、元データのひらがな(読み)からローマ字へ変換した 『日本歴史地名大系』地名項目データセットに関しては、かなり長い地名も多く、可読性が低いことがあります。
例えば 通四丁目東新道 は、読みが とおりよんちようめひがししんみち で、ローマ字表記では Tooriyonchiyoumehigashishinmichi となります。

これについては、「〜ちょうめ」といったルールを記述し、それに伴う処理を書いたり(「〜村」を「~ Village」としたのと同じアプローチ)、形態素解析器による分割をもとに、ハイフンや空白で区切った表記にし、可読性を向上させることができるかもしれません。
所感 - LLMの時代、人間の役割
私は以前、形態素解析器の開発に関わった経験があるのですが、今回はそういった類の手法を用いていません。
先日(2025年10月)、自然言語処理を10年ぐらいやってきたという記事がありました。私自身も10年以上自然言語処理に関わってきて、LLMという新しいパラダイムの体験に新鮮な思いがありました。
しかし、LLMの処理結果が高品質だとしても、人間の役割が不要になったわけではないと思います。
今回の例のように、データの前処理や後処理、そしてそもそもどのアプローチを採用するか、それぞれの利点・欠点を踏まえた判断といったことは依然として必要です。
また、今回は人間による最終的な確認・修正を行いましたが、そこでは単に誤りを正すだけでなく、「どういった翻訳基準を採用するか」という意思決定が求められました。答えが自明ではないそういった判断は、人が下すことが求められます。
この「れきちず」というプロダクトは、リード開発者である@chizutodesignのこだわりが詰まっており、彼が「この表記がいい!」と決めることに価値があるでしょう。そういった意思決定の積み重ねが、代替できない作品の個性を生み出すのだと感じました。
アプリの国際化(i18n)
データを作成したら、次はアプリの国際化です。地図自体の表記は、先述したスタイルを切り替えることで変更できますが、アプリのUI自体もあわせて替える必要があります。
ロケール: ja, ja-Hira, en
今回は以下3つのロケールに対応しました。
-
ja: 日本語(オリジナル) -
ja-Hira: 日本語・ひらがな表記(BCP 47に則った形式) -
en: 英語
i18nライブラリ「Paraglide JS」
れきちずは、Webフレームワーク「Svelte」を用いて実装しています。
i18nには、自作なども検討しましたが、最終的には、MIERUNE同僚のNEKOYASANさんに教えてもらったライブラリ「Paraglide JS」を利用しました。
まず、ロケールごとにテキストを用意します。
{
"$schema": "https://inlang.com/schema/inlang-message-format",
"title": "れきちず",
"image": "https://rekichizu.jp/social.png",
"imageAlt": "見慣れた現代風デザインで歴史地図が閲覧できるサービス「れきちず」の画面",
"description": "歴史の学び方が変わる。「れきちず」は、見慣れた現代風デザインで歴史地図が閲覧できるサービス。GPS機能や3D地形表示だけでなく、現代地図との重ね合わせ・比較機能も! 地図アプリ感覚で、気軽に江戸時代にタイムスリップ!",
...
{
"$schema": "https://inlang.com/schema/inlang-message-format",
"title": "れきちず",
"image": "https://rekichizu.jp/social.png",
"imageAlt": "みなれたげんだいふうでざいんでれきしちずがえつらんできるさーびす「れきちず」のがめん",
"description": "れきしのまなびかたがかわる。「れきちず」は、みなれたげんだいふうでざいんでれきしちずがえつらんできるさーびす。GPSきのうや3Dちけいひょうじだけでなく、げんだいちずとのかさねあわせ・ひかくきのうも!ちずあぷりかんかくで、きがるにえどじだいにたいむすりっぷ!",
...
{
"$schema": "https://inlang.com/schema/inlang-message-format",
"title": "Rekichizu",
"image": "https://rekichizu.jp/social_en.png",
"imageAlt": "A view of Rekichizu, a modern design history map service",
"description": "Discover history in a whole new way. Rekichizu lets you dive into historical maps with a modern, familiar design. Compare old maps with today’s, explore in 3D, and use GPS to time-travel back to the Edo period—just like using your favorite map app!",
...
ちなみに今回は、「ひらがな」ということにしていますが、より広い層へ向けた対応という観点では、表記の転写だけでなく、「やさしい日本語」へ対応していくと良いかとも考えます。
上記のテキストを、各コンポーネント内で呼び出して利用します。
<script lang="ts">
import { m } from '$lib/paraglide/messages.js';
</script>
<nav class="flex flex-wrap justify-center gap-x-6 gap-y-2 font-bold">
<a href="#features">{m.footer_nav_features()}</a>
<a href="#projects">{m.footer_nav_projects()}</a>
<a href="#news">{m.footer_nav_news()}</a>
<a href="#data-usage">{m.footer_nav_data_usage()}</a>
<a href="#external-data">{m.footer_nav_external_data()}</a>
<a href="#contact">{m.footer_nav_contact()}</a>
<a href="#references">{m.footer_nav_references()}</a>
</nav>
ロケールの判別や設定は、 getLocale(), setLocale() という関数で行います。
import { getLocale, setLocale } from '$lib/paraglide/runtime.js';
パスは、各ロケールごとに指定しています。
-
https://rekichizu.jp/map (デフォルトの
jaロケール)
に対応して、
-
https://rekichizu.jp/ja-Hira/map (
ja-Hiraロケール) -
https://rekichizu.jp/en/map (
enロケール)
このURLを元に、ロケールを判別しています。そのほか、ローカルストレージやクッキーを用いた指定もできます。各種戦略の詳細は、以下のページをご覧ください。
ちなみにGoogle for Developersドキュメントを見ると、URLパラメータによるロケール指定は非推奨となっています。
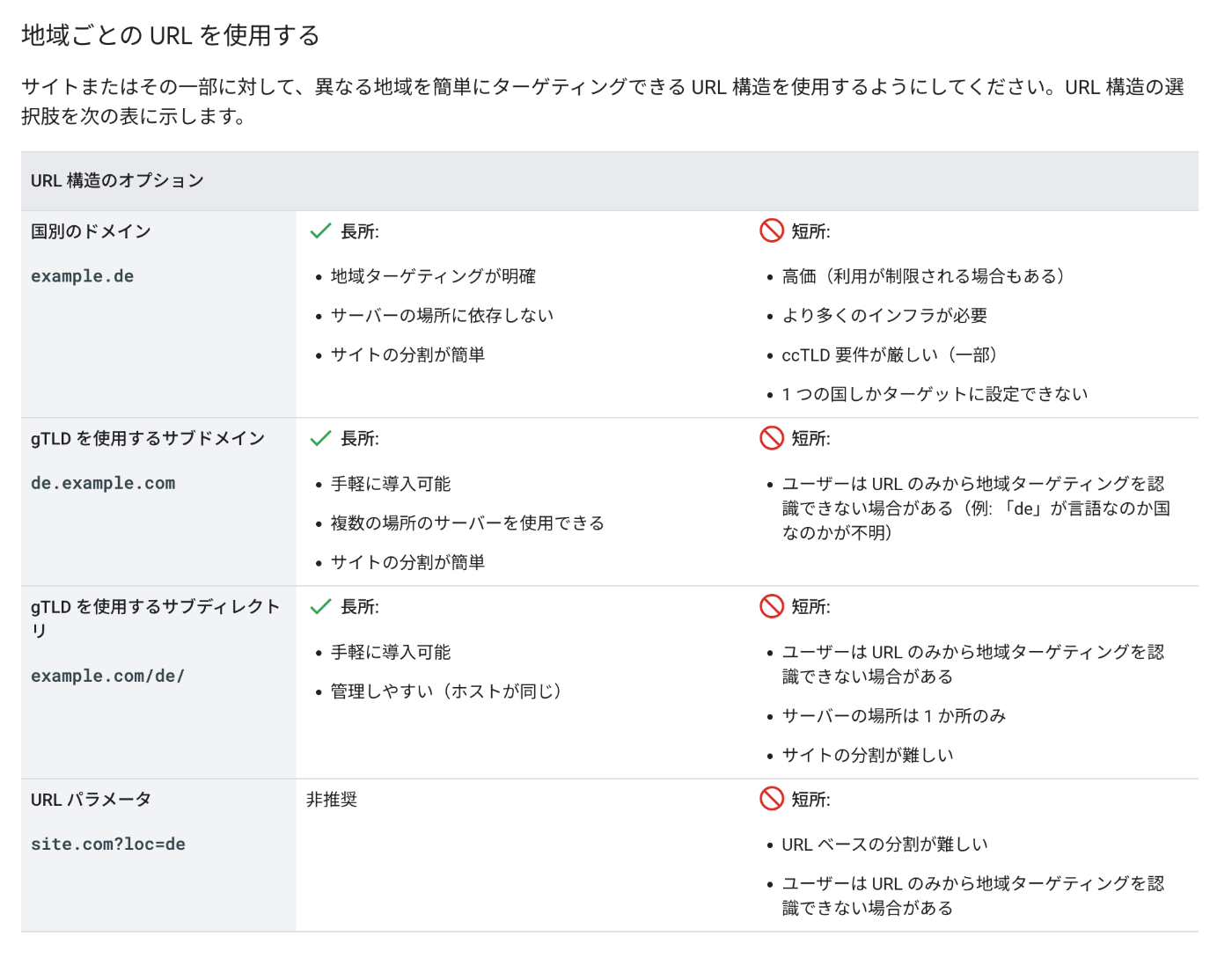
図: 多地域、多言語サイトの管理 | Google 検索セントラル | Documentation | Google for Developers
また、Paraglide JSには「Sherlock」というVSCode拡張機能が用意されており、これを用いることで、元のJSONファイルを直接開くことなく、各コンポーネントにあるテキスト一覧を列挙・編集できます。
Claude Codeによるi18n導入
今回のParaglide JS導入には、最近の開発のほとんどと同様にClaude Codeを用いました。
ある程度のファイル構成を用意した上で、「全コンポーネントのテキストを抽出して、ひらがな・英語の表記を記述して」と指示すると、aria-labelなども含めた全テキストが列挙され、そしてひらがな・英語テキストが生成されました。
抽出に関しては100%漏れなし、ひらがな・英語についても、9割以上はそのまま使える品質のものでした。
ソフトウェア開発におけるAI導入において、このように設計自体が求められない定型タスクであれば、大幅な効率化が実現できることを改めて実感しました。
とはいえ、「機械翻訳」は、以前の自然言語処理の時代には決して「簡単なタスク」ではありませんでした。翻訳専用モデルでもない汎用LLMで、ここまでの品質のものがさらりと出力されるのを見ると、本当に遠くまで来たのだと改めて驚きます。
おわりに
この記事では、現代風の歴史地図サービス「れきちず」のひらがな・英語化について、データ作成やアプリ実装の観点から紹介しました。
さまざまなツールやサービスの恩恵を受けることで、想像以上に短期間で実現することができました。また、現代における自然言語処理を体験する良い機会となりました。
これにより、より幅広い層の利用が可能となり、「誰にでもわかりやすい歴史地図」というコンセプトの実現に寄与できたと考えています。
ぜひ、れきちずで遊んでみてください!🥳

Discussion