
こういうこと、ありませんか ↓
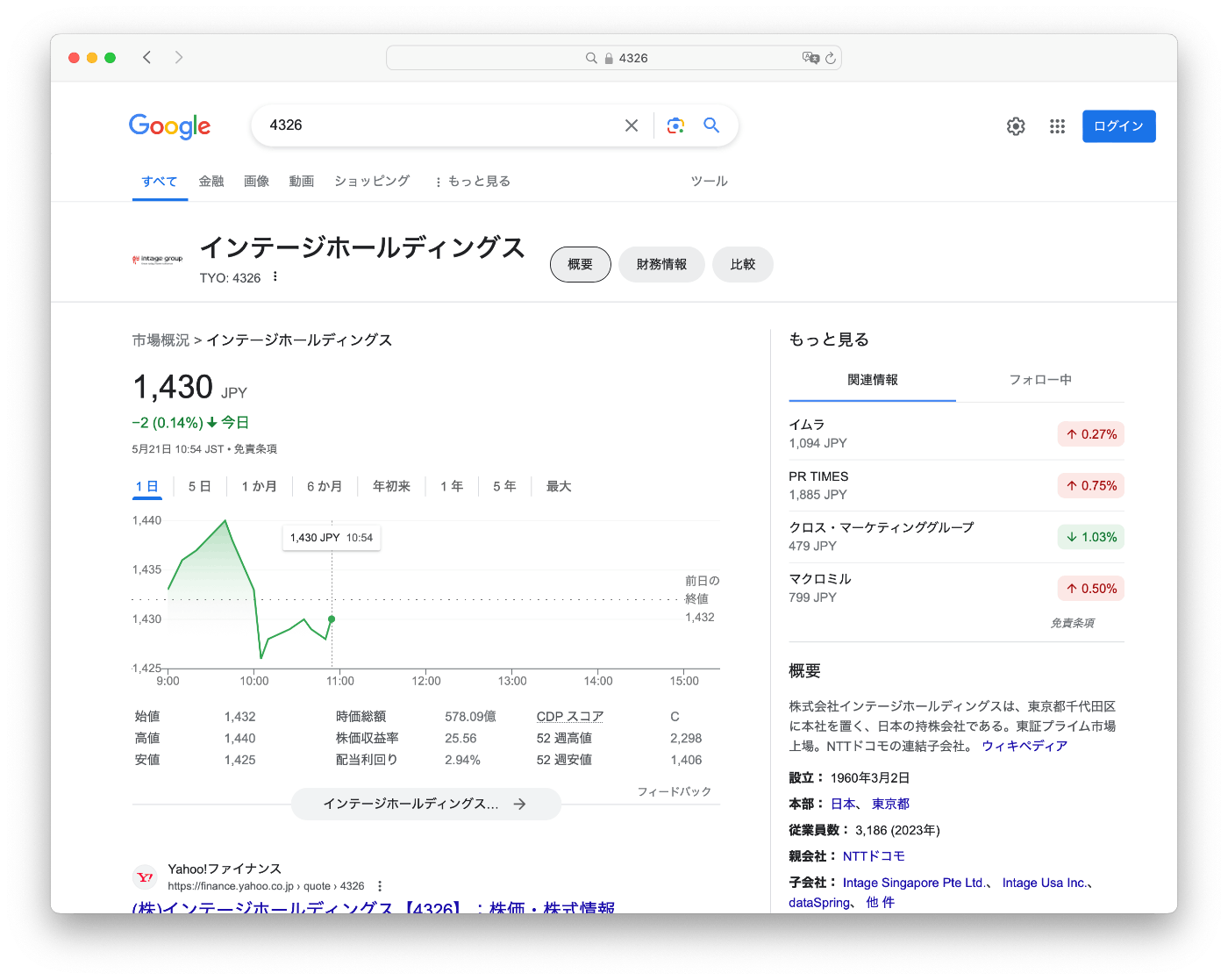
位置情報・地理空間情報の座標参照系(CRS)を指し示す「EPSGコード」と、証券取引所に上場する企業に対し付与される識別番号「証券コード(銘柄コード)」は、多くが4桁の数字であり、パッと見ると似通っています。実際、多くのコードは共通しています。
それらコードを見分けられるよう訓練するためのWebアプリを作りました:
コードやデータ、前処理のスクリプトは、以下のレポジトリで公開しています:
"X or Y" クイズ
これまで、数多の「XかYか」を判別するクイズが作られてきました。以下に、いくつかの例を紹介します:
- IKEA or Death (現在は停止)
- Is it Pokémon or Big Data?
- Prof or Hobo? - Quiz
- シャアかグレタかクイズ | クイズメーカー
- 椎名林檎かポケカの拡張パックか | クイズメーカー
- ちいかわか米津玄師か当てるクイズ | クイズメーカー
松屋と西松屋

地図を用いた例として、多田瑛貴さんによる「松屋 vs 西松屋」があります。多田さんは、私の所属するMIERUNE社にも以前、インターンに来てくれていて、その際にこのアプリをさらりと作られていました:
ジョージア文字とミャンマー文字
私自身も以前、「ジョージア文字」と「ミャンマー文字(ビルマ文字)」を当てるアプリを作ったことがあります。ジョージアを旅した友人と「ジョージア文字とミャンマー文字似てるよね!」と盛り上がった流れで作りました。どちらも素敵ですよね。


ちなみに、ジョージア文字は「アルファベット(母音と子音が独立)」、ミャンマー文字は「アブギダ(子音が主体で、母音が子音に付随して変化)」という種類の音素文字だそうです。
この二つが似通っていると思ったのは私だけではないようで、以下の英語ページでも、同様の疑問を投げかけている人がいました:
また、後日、どの国からも承認されていない国家「アジャリア」に行く :: デイリーポータルZという記事で、日本国外務省のシンハラ語エキスパート、岩瀬喜一郎さんによる以下の言及を見て、おおっ...!と思いました。
岩瀬: 私としては、 ジョージア文字は、よりミャンマー文字に近いと感じますね。 ミャンマー文字は、南インド系なので、おおざっぱに申し上げて「丸っこい南インド系のシンハラ文字に似ている」と言えるのではないでしょうか。
[...]
岩瀬: 当時の文字は、 ヤシ(シュロ)の葉に鉄の棒で書くことが多いので、丸い文字である必要がありました。 なぜなら、まっすぐな文字だと、葉っぱが切れてしまうためです。だからシンハラ文字の基になった南インドの文字は丸く、それを導入したミャンマー文字も丸いのです。
[...]
岩瀬: 結論としては、ジョージア文字もシンハラ文字もアラム文字系という同根ではあります。じっさい、丸い文字も似通っています。でも、シンハラ文字やミャンマー文字の丸さがその筆記方法に由来するに対して、9~13世紀に定着したジョージア文字が丸っこい理由は不明です。南アジアの文字が現在のミャンマーに伝わったと考えられる7世紀前後を含め、 歴史上、南アジアとコーカサスの間には強大なイスラム帝国があったので、文字が直接伝わったとは考えにくいものがあります。
EPSGコード
「CRS(Coordinate Reference System; 座標参照系)」は、測地系(≒地球の楕円体形状の捉え方)と、座標系(数値による位置の表し方のルール)の組み合わせのことをいいます。多くのCRSは、「EPSGコード」という識別子を用いて区別されます(参考: 井口奏大『現場のプロがわかりやすく教える 位置情報エンジニア養成講座』(秀和システム, 2023), p.21-23)。
世の中には多種多様なEPSGコードがあります。例えば 4326 は「経緯度(WGS84)」、 3857 (900913) は「ウェブメルカトル」、 6668 は「日本測地系2011(JGD2011)における地理座標系」、などなど。
先日開催されたジオ展2024では、私の所属するMIERUNEのブースでは、「好きな地図投影法(EPSG)は何ですか?」というボードを用意したのですが、マニアックすぎてあまり投票されていませんでした。むしろXのリプ欄のほうが盛り上がっていました 😇
EPSGコードは、 epsg.io というサイトで手軽に確認することができます:
EPSGコードのデータ
今回は手軽に、pyproj(汎用的な座標変換ソフトウェアPROJのPythonインタフェース)を使って、コード一覧とその情報を取得しました。
get_codes() という関数で、authority(今回は"EPSG")ごとの、PROJデータベースにあるコード一覧が取得できます。そのEPSGコードの詳細を CRS.from_epsg() を用いて確認しています:
from pyproj import CRS
from pyproj.database import get_codes
epsg_codes = {}
for code in get_codes("EPSG", "CRS"):
crs = CRS.from_epsg(code)
epsg_codes[code] = {
"name": crs.name,
"area_of_use": crs.area_of_use.name,
"coordinate_operation": crs.coordinate_operation.name if crs.coordinate_operation else None,
"datum": crs.datum.name if crs.datum else None,
}
この方式で、6,934件のEPSGが取得できました。そのうち、5,119件(74%)が4桁、1,815件(26%)が5桁の数字でした。数字以外の文字を含むコードはありません。今回は最終的には、後述の証券コードと揃えるため、4桁の数字に絞って利用しました。
データ処理の詳細は、次のJupyter Notebookで確認できます: epsg-or-jpx/data/epsg.ipynb at main · sorami/epsg-or-jpx
参考: epsg.org のデータセット
PROJを用いた上記のやり方のほかに https://epsg.org/ からもととなるデータセットを取得するやり方もあります。データのダウンロードには、ユーザー登録が必要です。
以下の形式でダウンロードすることができます:
- MS ACCESS データベース
- MySQL スクリプト
- ORACLE スクリプト
- PostgreSQL スクリプト
- WKT
PostgreSQLスクリプトのデータを見てみると、以下のようになっています:

一方、WKTのデータは、以下のようになっています:

WKTデータセットをみると、9,698の .wkt ファイルがあります。
例えばこのWKTファイルの名前から、EPSGコードの一覧を取得することができます。しかし、その詳細を pyprojの CRS.from_epsg() を使って確認しようとすると、2,762のEPSGコード(全体の28.5%)がエラー(PROJにCRSが存在しない)になります。
他のやり方として、このWKTファイル自体を読み込んで解釈することもできます(WKTはテキストファイルで、CRS情報が記述されています - 参考: Well-known text - Wikipedia):
with open("EPSG-CRS-4326.wkt") as f:
wkt_text = f.read()
crs = CRS.from_wkt(wkt_text)
しかしこの場合でも、2,690のWKTファイル(全体の27.7%)がエラーとなり、読み取ることができませんでした。「入力がCRSではない」「不正な投影法」「不正なWKT文字列」といったエラーがありました。
これらの詳細は、次のJupyter Notebookで確認できます: epsg-or-jpx/data/epsg.ipynb at main · sorami/epsg-or-jpx
証券コード
「証券コード」は、証券取引所に上場する企業に対し付与される識別番号です。ちなみに、この語は株式会社東京証券取引所の登録商標だそうです。
証券コードにも種類があり、一般に知られる 任天堂 <7974> というような「4桁の数字」は「銘柄コード」です。
証券コードのデータ
今回は、日本取引所グループ(JPX)が公開する、東証上場銘柄一覧のデータを利用しました。以下のページから、Excelファイルをダウンロードすることができます:
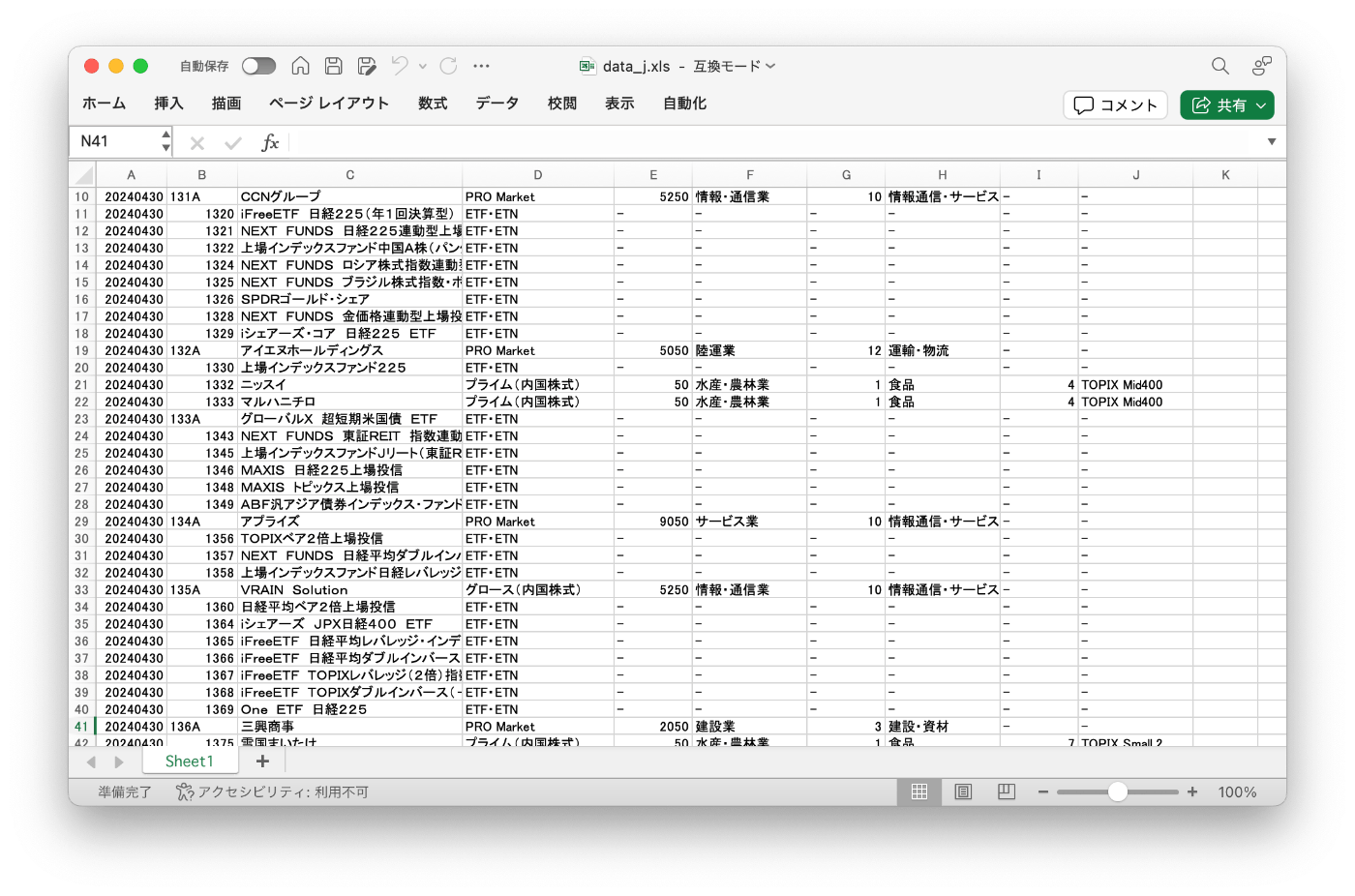
「東証上場銘柄一覧(2024年4月末)」データを見ると、4360銘柄が収録されています。
そのうち、2件のみが、「4桁ではない数字」でした:
-
25935「伊藤園 優先株式」(プライム) -
94345「ソフトバンク 優先株式」(プライム)
また、 130A 「Veritas In Silico」(グロース)のように、英字を含むコードも53件ありました。この形式は、2024年1月から始まったそうです:
5桁のコード、および英字を含むコードは、先述のEPSGコードと合わせるため、利用時には除外しました。
データ処理の詳細は、次のJupyter Notebookで確認できます: epsg-or-jpx/data/jpx.ipynb at main · sorami/epsg-or-jpx
Webアプリの実装
上記で用意したデータを元に、Webアプリを作成しました。
実装にはWebフレームワーク「SvelteKit」を用いました。今年(2024)4月にRelease Candidateが出た「Svelte 5」の記法を用いて実装しています:
Svelteは、手軽に多様なアニメーションを実現できてイイカンジです。今回は svelte/transition にデフォルトで用意されている fade や blur を用いています。加えて、タイプライターのようにテキストを一文字づつ表示するアニメーションは、カスタムのJavaScriptトランジションにより実現しており、これはSvelteの公式チュートリアルにあった例を元にしています:
画面を”振動”させるアニメーションは、今年(2024)4月に出たPLATEAU Past/Future for Action #001 Earthquakeというサイトで用いられてるのを見て良いなと思い、真似てみました。以下のようなCSSアニメーションで実現しています:
@keyframes shake {
0% {transform: translate(1px, 1px) rotate(0deg);}
10% {transform: translate(-1px, -2px) rotate(-1deg);}
20% {transform: translate(-3px, 0px) rotate(1deg);}
30% {transform: translate(3px, 2px) rotate(0deg);}
40% {transform: translate(1px, -1px) rotate(1deg);}
50% {transform: translate(-1px, 2px) rotate(-1deg);}
60% {transform: translate(-3px, 1px) rotate(0deg);}
70% {transform: translate(3px, 1px) rotate(-1deg);}
80% {transform: translate(-1px, -1px) rotate(1deg);}
90% {transform: translate(1px, 2px) rotate(0deg);}
100% {transform: translate(1px, -2px) rotate(-1deg);}
}
.shake {
animation: shake 0.5s;
}
紙吹雪(confetti)には「canvas-confetti」というライブラリを用いています:
アトミックCSSエンジン「UnoCSS」も利用しています。(現行の)Tailwind CSSがPostCSSプラグインなのに対して、これはそうではありません。よりフレキシブルに扱え、例えばCDNランタイムによるその場でのCSS生成などもできるそうです(参考)。加えて、Webフォントやアイコンを便利に扱える機能があったりと、イイカンジで、愛用しています:
数字テキストには、Google Fontsでも公開されている「Orbitron」というフォントを用いました。UnoCSSのWeb fonts presetを用いれば、サッと導入できます:
import { defineConfig } from 'unocss'
import presetWebFonts from '@unocss/preset-web-fonts'
import presetUno from '@unocss/preset-uno'
export default defineConfig({
presets: [
presetUno(),
presetWebFonts({ digit: 'Orbitron' }),
],
})
<div class="font-digit">4326</div>
コードやデータ、前処理のスクリプトは、以下のレポジトリで公開しています:
Enjoy coding 🎉

Discussion