はじめに
2023/10/21時点では大きく以下のLLMを使ったChatAPIが提供されています。
(小さいものは省く)
- ChatGPT(Open AI)
- Vertex AI(Goole)
- Amazon Bedrock(Amazon)
この中で料金が一番安いVertex AIのPaLM2を使ってBotにLLMによる返信機能を入れたいと考えました。
環境
- Python 3.10.5
- Google Colob(T4,ハイメモリではない)
実装
まずは、全体の大まかな実装構成です。

Googleの認証
VetexAIのAPIを外部から叩くには、Googleの以下の認証を使う必要があります。
- Google サービスアカウントを使った認証
- Google ユーザーアカウントを使った認証
これらは(慣れていない場合)、かなりコストが高いため別の方法を試します。
GASでBardのAPI(VertexAI API)を実行する方法!PaLM2の応答生成でGAS(Google Apps Script)から実行されている方がいたため、これを参考にして疑似APIを作製していきたいと思います。
以下のようにGASのdoPost()を使用して、外部から叩けるようにAPIを作製します
function doPost(e) {
var userName = e.parameter.name;
var content = e.parameter.content;
var d = {"response":chatPredict(userName,content)};
var out = ContentService.createTextOutput();
out.setMimeType(ContentService.MimeType.JSON);
out.setContent(JSON.stringify(d));
return out;
}
function chatPredict(name,content) {
//VertexAIのAPIを有効化したGCPプロジェクトの番号を設定する
const PROJECT_ID = 'project id';
//VertexAIのAPIのエンドポイントURLを設定する
let apiUrl = `https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/chat-bison:predict`;
//VertexAIへのプロンプトを設定
//英訳したプロンプトに加え、VertexのAPIリクエストに必要なペイロードを設定
const payload = {
"instances": [{
"context": "事前の埋め込みプロンプト",
"examples": [
{
"input": {"content": "contextに対する質問例"},
"output": {"content": "contextに対する質問の回答"}
}],
"messages": [
{
"author": name,
"content": content,
}],
}],
"parameters": {
"temperature": 0.2,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
};
//payloadやHTTP通信種別、認証情報をoptionで設定
const options = {
'payload': JSON.stringify(payload),
'method' : 'POST',
'muteHttpExceptions': true,
'headers': {"Authorization": "Bearer " + ScriptApp.getOAuthToken()},
'contentType':'application/json'
};
//VertexAIにAPIリクエストを送り、結果を変数に格納
const response = JSON.parse(UrlFetchApp.fetch(apiUrl, options).getContentText());
return response.predictions[0].candidates[0].content;
}
コマンドの実装
Commandの実装では、以下の流れの処理になります。
- GASにリクエストを送る
- レスポンスをbotに送信する
このときにレスポンスが一定時間以上たつとDiscordの返信でエラーがあるので、一時的な返信を以下を使って実装します
await ctx.response.defer()
await ctx.followup.send(message)
実装のコードは以下になります
GASへのリクエスト
def chatPredict(self, name: str, text: str) -> str: # POSTで送るデータ
payload = {
"name": name,
"content": text
}
# POSTリクエストを送る
response = requests.post(self.endPoint, data=payload)
return response.json()['response']
Command側の実装
@com.command(name="chat", description="ミラのコマンド一覧を表示するコマンド")
async def chat(
self,
ctx: discord.ApplicationContext,
content: Option(
str,
description="ミラに話しかける内容",
)
):
await ctx.response.defer()
response = self.vertexAIUtil.chatPredict(ctx.author.display_name, content)
await ctx.followup.send("ミラ: " + response)
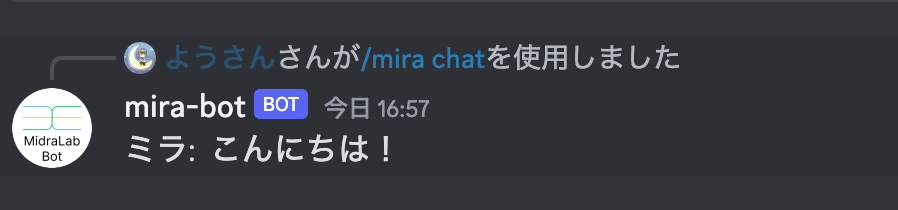
実際にコマンドを叩いた時は、以下のように返ってきます
GASによるオーバーヘッドの計測
今回の実装では、GASを途中で挟んでいるためGASによるオーバーヘッドが発生している状況になります。
そのため、念のためどのくらいのオーバーヘッドがあるのかを計測しました
比較対象としては、Google Colobで直接VertexAIのAPIを叩いた場合とGASを経由した場合で推論速度を比較しています。
以下が実行回数と処理時間になります。
| 実装環境 | 1回目 | 2回目 | 3回 |
|---|---|---|---|
| Google Colob | 1.49s | 1.63s | 1.63s |
| GAS経由 | 2.01s | 2.19s | 2.04s |
結果GASによるオーバーヘッドが0.5sくらいでした。そのため今回のbotの実装にはあまり影響がなさそうです
Goole ColobでGAS経由の実装
# 必要なライブラリをインストール
!pip install requests
import requests
import time
class ChatPredictor:
def __init__(self, endPoint: str):
self.endPoint = endPoint
def chatPredict(self, name: str, text: str) -> str:
payload = {
"name": name,
"content": text
}
# POSTリクエストを送る
response = requests.post(self.endPoint, data=payload)
return response.json()['response']
start_time = time.time()
# 使用例
predictor = ChatPredictor(endPoint="GAS EndPoint")
response = predictor.chatPredict(name="ようさん", text="こんにちは")
elapsed_time = time.time() - start_time
print(f"Elapsed time: {elapsed_time} seconds")
print(response)
Googel Colobで直接叩く場合
import vertexai
import time
from vertexai.preview.language_models import ChatModel, InputOutputTextPair
# vertexaiの初期化
vertexai.init(project=project_id, location=location)
start_time = time.time()
chat_model = ChatModel.from_pretrained("chat-bison")
parameters = {
"temperature": 0.2,
"max_output_tokens": 256,
"top_p": 0.8,
"top_k": 40
}
chat = chat_model.start_chat()
print(chat.send_message("こんにちは", **parameters))
elapsed_time = time.time() - start_time
print(f"Elapsed time: {elapsed_time} seconds")

midra-lab.notion.site/MidraLab-dd08b86fba4e4041a14e09a1d36f36ae 個人が興味を持ったこと × チームで面白いものや興味を持ったものを試していくコミュニティ
Discussion