[Go] 様々な文字列を描画する (font fallback, text shaping, BiDi 対応)
Go でフォントのフォールバック、text shaping、BiDi に対応した文字列描画を実現しました。
Go で文字列を画像に描画するためには様々な方法があります。
文字列といっても、単にアルファベットや日本語だけではなく様々な種類があります。
例えば、サンスクリット語などの表記に用いられるデーヴァナーガリー देवनागरी は、前後の文字列との組み合わせによってグリフの形が変わることがあります。
また、アラビア語などの表記に用いられるアラビア文字 الأبجدية العربية や、ディベヒ語の表記に使われるターナ文字 ތާނަ は、英語などとは異なり右から左に流れる向きを持つ文字です。
この記事では、いろいろなパターンについて、Go で文字列を描画する方法を記します。
シンプルな文字列の描画
まずは、1種類のフォントのみで描画でき、それぞれのグリフの形が独立していて文字列の結合なども発生せず、左から右に流れる向きの文字しかない、シンプルなケースについてです。
Go で文字列を画像に描画するライブラリとして golang.org/x/image/font が使用できます。
font.Drawer に描画先の画像 (Dst)、描画元に使用する画像 (Src)、フォント (Face)、位置 (Dot) を指定し、(font.Drawer).DrawString を描きたい文字列で呼ぶだけで、
画像に文字列が描画されます。
実装例
package main
import (
_ "embed"
"fmt"
"image"
"image/png"
"log"
"os"
"golang.org/x/image/font"
"golang.org/x/image/font/opentype"
"golang.org/x/image/math/fixed"
)
// https://www.unicode.org/udhr/d/udhr_tur.html
const text = "Yaşamak, hürriyet ve kişi emniyeti her ferdin hakkıdır."
func main() {
f, err := face()
if err != nil {
log.Fatal(err)
}
i := draw(text, f)
if err := export(i); err != nil {
log.Fatal(err)
}
}
//go:embed src/NotoSans-Regular.ttf
var fontFile []byte
func face() (font.Face, error) {
const fnName = "face"
tt, err := opentype.Parse(fontFile)
if err != nil {
return nil, fmt.Errorf("%s: %w", fnName, err)
}
face, err := opentype.NewFace(tt, &opentype.FaceOptions{
Size: 32,
DPI: 72,
Hinting: font.HintingFull,
})
if err != nil {
return nil, fmt.Errorf("%s: %w", fnName, err)
}
return face, nil
}
func draw(s string, f font.Face) image.Image {
a := font.MeasureString(f, text)
h := f.Metrics().Height
r := image.Rect(0, 0, a.Ceil(), h.Ceil())
dst := image.NewRGBA(r)
y := f.Metrics().Ascent
d := &font.Drawer{
Dst: dst,
Src: image.Black,
Face: f,
Dot: fixed.Point26_6{Y: y},
}
d.DrawString(s)
return dst
}
const imageFileName = "image.png"
func export(i image.Image) error {
const fnName = "export"
f, err := os.Create(imageFileName)
if err != nil {
return fmt.Errorf("%s: %w", fnName, err)
}
defer f.Close()
if err := png.Encode(f, i); err != nil {
return fmt.Errorf("%s: %w", fnName, err)
}
return nil
}
上の実装例により、以下の画像が得られます。

ここでは、フォントファイルはひとつしか読み込んでいません。
読み込んだフォントにない文字を指定して描画した場合、その文字の形のデータがないので、その文字を描画することができません。
// https://www.unicode.org/udhr/d/udhr_tir.html
const text = "10 ታሕሳስ 1948 ዓ.ም.ፈ ብሓፈሻዊ ጉባኤ ውድብ ሕቡራት መንግስታት ዝፀደቐን ዝተኦወጀን ድንጋገ 217 ኤ- III )"
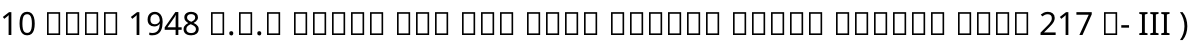
上の例では、数字や記号などフォントに含まれる文字は描画されていますが、他の文字は長方形(いわゆる tofu)になってしまっています。
では、複数の種類の文字を正しく描画するにはどうすればよいのでしょうか?
ひとつの方法としては、必要なグリフを集めたひとつのフォントファイルを作ってしまうことです。
しかし現実には、世の中のすべてのグリフを好きなデザインでひとつのフォントにまとめることは困難です。
そして、ひとつのフォントファイルに持たせることができるグリフの数に上限があります。
GNU Unifont のように全 Unicode スペースをカバーするプロジェクトもありますが、
フォントのデザインを調整するためにフォントに優先度を持たせたい場合や、必要なフォントのみを複数選択して使用する場合もあります。
このような場面では、フォントのフォールバックを行います。
フォントのフォールバック - 複数の種類のフォントが含まれる文字列の描画
フォントのフォールバックは、現在のフォントに含まれないグリフがあった場合、別のフォントを使ってそのグリフを描画することです。
これを実装するには、それぞれのグリフがフォントに含まれるかどうかを一文字ずつ判定する必要があります。
"1文字" を取得する
ところで、実際に表示される、私たちが認識している 1 文字と、プログラムの中での 1 文字は、必ずしも一致しません。
以下の例で使用されている文字は、どれも 1 文字ですが、異なる長さを持ちます。
fmt.Println(len("A")) // 1
fmt.Println(len("あ")) // 3
fmt.Println(len("ष्ट्रि")) // 18
fmt.Println(len("👩👩👧👧")) // 25
fmt.Println(len([]rune("A"))) // 1
fmt.Println(len([]rune("あ"))) // 1
fmt.Println(len([]rune("ष्ट्रि"))) // 6
fmt.Println(len([]rune("👩👩👧👧"))) // 7
つまり文字列を for でループしても、1 文字ずつ文字列を取得することはできません。
そこで、grapheme cluster という単位で文字列を分割する必要があります。
Grapheme cluster は Unicode Text Segmentation で定義されている、人が 1 文字だと考える単位のことです。
これは github.com/rivo/uniseg によって取得することができます。
文字があるフォントに対して描画可能か判定する
ある rune のグリフが特定のフォントに含まれるかは、(font.Face).GlyphAdvance などで判定が可能です。
ある文字が特定のフォントで描画可能か、つまり豆腐にならないかを判定するには、
その文字列 string のすべての rune に対して、そのグリフがフォントに含まれるかを判定すればよいです。
func canRender(s string, f font.Face) bool {
for _, r := range s {
if _, ok := f.GlyphAdvance(r); !ok {
return false
}
}
return true
}
さて、ここまででフォントのフォールバックが実現できます。
実装例は以下のようになります。
実装例
package main
import (
"embed"
"fmt"
"image"
"image/png"
"log"
"os"
"github.com/rivo/uniseg"
"golang.org/x/image/font"
"golang.org/x/image/font/opentype"
"golang.org/x/image/math/fixed"
)
// https://www.unicode.org/udhr/d/udhr_chr_cased.html
// https://www.unicode.org/udhr/d/udhr_tir.html
// https://www.unicode.org/udhr/d/udhr_tha.html
const text = `Ꮒꭼꮎꮫ Ꮧꭶꮓꮳꮃꮕꭲ Ꭰꮒᏼꮻ Ꭴꮒꮂ Ꭲᏻꮎꮫꮧꭲ
10 ታሕሳስ 1948 ዓ.ም.ፈ ብሓፈሻዊ ጉባኤ ውድብ ሕቡራት መንግስታት ዝፀደቐን ዝተኦወጀን ድንጋገ 217 ኤ- III )
คนทุกคนมีสิทธิในการดำรงชีวิต ꭳꭶꮣꮴꮅ ꭸꮢꭲ ꭰꮄ ꮎꮝꭹ ꭴꭶꮞꮝꮧ ᏼꮻ.`
func main() {
fs, err := faces()
if err != nil {
log.Fatal(err)
}
i := draw(text, fs)
if err := export(i); err != nil {
log.Fatal(err)
}
}
//go:embed src/*.ttf
var fontFiles embed.FS
var fontNames = []string{
"NotoSansCherokee-Regular",
"NotoSansEthiopic-Regular",
"NotoSansThaiLooped-Regular",
}
func faces() ([]font.Face, error) {
const fnName = "faces"
fs := []font.Face{}
for _, name := range fontNames {
f, err := face(name)
if err != nil {
return nil, fmt.Errorf("%s: %w", fnName, err)
}
fs = append(fs, f)
}
return fs, nil
}
func face(name string) (font.Face, error) {
const fnName = "face"
fileName := fmt.Sprintf("src/%s.ttf", name)
b, err := fontFiles.ReadFile(fileName)
if err != nil {
return nil, fmt.Errorf("%s: %w", fnName, err)
}
tt, err := opentype.Parse(b)
if err != nil {
return nil, fmt.Errorf("%s: %w", fnName, err)
}
face, err := opentype.NewFace(tt, &opentype.FaceOptions{
Size: 32,
DPI: 72,
Hinting: font.HintingFull,
})
if err != nil {
return nil, fmt.Errorf("%s: %w", fnName, err)
}
return face, nil
}
const (
width = 1300
height = 150
)
func draw(s string, fs []font.Face) image.Image {
r := image.Rect(0, 0, width, height)
dst := image.NewRGBA(r)
y := fs[0].Metrics().Ascent
d := &font.Drawer{
Dst: dst,
Src: image.Black,
Face: fs[0],
Dot: fixed.Point26_6{Y: y},
}
gr := uniseg.NewGraphemes(s)
for gr.Next() {
cl := gr.Str()
drawGraphemeCluster(cl, d, fs)
}
return dst
}
func drawGraphemeCluster(cl string, drawer *font.Drawer, fs []font.Face) {
if cl == "\n" {
// Insert newline
drawer.Dot.X = 0
drawer.Dot.Y += drawer.Face.Metrics().Height
return
}
// Font fallback
for _, f := range fs {
if canRender(cl, f) {
drawer.Face = f
break
}
}
drawer.DrawString(cl)
}
func canRender(s string, f font.Face) bool {
for _, r := range s {
if _, ok := f.GlyphAdvance(r); !ok {
return false
}
}
return true
}
// ...
上の実装例により、以下の画像が得られます。

もとの文字列には、数字や記号、チェロキー文字、ゲエズ文字、タイ文字が含まれていますが、
豆腐化することなくレンダリングされています。
しかし、タイ文字の表示が部分的に崩れていますね。
修飾記号の位置がずれてしまっています。
実はこのままだと、デーヴァナーガリーやチベット文字を正しく表示することはできません。
// https://www.unicode.org/udhr/d/udhr_hin.html
// https://www.unicode.org/udhr/d/udhr_sin.html
// https://www.unicode.org/udhr/d/udhr_bod.html
const text = `(१) प्रत्येक व्यक्ति को अपने देश के शासन में प्रत्यक्ष रूप से या स्वतन्त्र रूप से चुने गए प्रतिनिधियों के ज़रिए हिस्सा लेने का अधिकार है ।
2. තම රටේ රාජ්ය සේවයට ඇතුළත් වීමට සෑම පුද්ගලයකුටම සමාන අයිතිවාසිකම් ඇත.
༣ མི་མང་གི་འདོད་པ་ནི་གཞུང་གི་དབང་ཆའི་གཞི་རྩར་འཛིན་དགོས་པ་ཡིན་ཞིང༌། འདོད་པ་དེ་ནི་དུས་སྐབས་སོ་སོར་འདེམས་བསྐོ་ངོ་མ་བྱེད་པའི་ཐོགགསལ་བར་འདོན་དགོས་པ་དང༌།
དེ་ཡང་ཡོངས་ཁྱབ་དང་འདྲ་མཉམ་གྱི་འོས་བསྡུའམ། གསང་བ་དང༌། རང་དབང་ཅན་གྱི་འོས་བསྡུ་བྱེད་པ་ལ་བརྟེནནས་ལ ག་ལེན་བསྟར་དགོས་པ་ཡིན༎`

デーヴァナーガリーはうまく変形していませんし、他の文字もところどころ線が重なってぐちゃぐちゃになってしまっています。
そこで、text shaping が必要になってきます。
Text shaping - 周囲の文字列によって形を変える文字列の描画
Text shaping は、複数の文字列を結合してグリフにすることです。
同じ文字でも、周囲の文字との組み合わせによって形を変えるものがあります。
例えば、アラビア文字は単語の中の位置によって語末形、語中形、語頭形、独立形と形を変えます。
このような文字を正しくレンダリングするときに、shaping が必要となります。
さきほど挙げたデーヴァナーガリーも、shaping が必要な文字になります。
デーヴァナーガリーの ष्ट्रि を、shaping なし(上の実装例)でレンダリングすると、次のようになり、形が全く異なることがわかります。

現状では golang.org/x/image/font は text shaping を実現するのには不十分です。
Text shaping も含めた文字のレンダリングは、github.com/go-text/typesetting を使用してパス情報を取得し、
golang.org/x/image/vector を使用してベクタを描画することで実現できます。
具体的には (shaping.Shaper).Shape が shaping 処理を行っています。
その引数として、フォントの他に文字の種類を表す Script や言語 Language を渡します。
言語を渡すのは、同じ文字でも言語によって shaping の条件が異なることがあるからです。
実装例
package main
import (
"bytes"
"embed"
"fmt"
"image"
"image/draw"
"image/png"
"log"
"os"
"github.com/go-text/typesetting/font"
"github.com/go-text/typesetting/language"
"github.com/go-text/typesetting/opentype/api"
"github.com/go-text/typesetting/shaping"
"github.com/rivo/uniseg"
"golang.org/x/image/math/fixed"
"golang.org/x/image/vector"
)
const text = `ष्ट्रि`
func main() {
fs, err := faces()
if err != nil {
log.Fatal(err)
}
d := newDrawer(fs)
i := d.draw(text)
if err := export(i); err != nil {
log.Fatal(err)
}
}
// Font load
//go:embed src/*.ttf
var fontFiles embed.FS
type fontDefinition struct {
name string
script language.Script
language language.Language
}
var fonts = []fontDefinition{
{
name: "NotoSansDevanagari-Regular",
script: language.Devanagari,
language: "hi",
},
{
name: "NotoSansSinhala-Regular",
script: language.Sinhala,
language: "si",
},
{
name: "NotoSerifTibetan-Regular",
script: language.Tibetan,
language: "bo",
},
}
type fontData struct {
face font.Face
script language.Script
language language.Language
}
func faces() ([]fontData, error) {
const fnName = "faces"
fs := []fontData{}
for _, font := range fonts {
f, err := face(font.name)
if err != nil {
return nil, fmt.Errorf("%s: %w", fnName, err)
}
fs = append(fs, fontData{
face: f,
script: font.script,
language: font.language,
})
}
return fs, nil
}
func face(name string) (font.Face, error) {
const fnName = "face"
fileName := fmt.Sprintf("src/%s.ttf", name)
b, err := fontFiles.ReadFile(fileName)
if err != nil {
return nil, fmt.Errorf("%s: %w", fnName, err)
}
face, err := font.ParseTTF(bytes.NewReader(b))
if err != nil {
return nil, fmt.Errorf("%s: %w", fnName, err)
}
return face, nil
}
// Draw
const (
width = 80
height = 50
)
type drawer struct {
dst draw.Image
rast *vector.Rasterizer
shaper shaping.Shaper
faces []fontData
currentFace fontData
strBuf string
x fixed.Int26_6
y fixed.Int26_6
baseY fixed.Int26_6
lineHeight fixed.Int26_6
}
func newDrawer(faces []fontData) *drawer {
d := &drawer{}
rect := image.Rect(0, 0, width, height)
d.dst = image.NewRGBA(rect)
d.rast = vector.NewRasterizer(width, height)
d.rast.DrawOp = draw.Src
d.shaper = &shaping.HarfbuzzShaper{}
d.faces = faces
d.currentFace = faces[0]
return d
}
func (d *drawer) draw(s string) image.Image {
gr := uniseg.NewGraphemes(s)
for gr.Next() {
cl := gr.Str()
if cl == "\n" {
d.flushStrBuf()
// Insert newline
d.x = 0
d.y += d.lineHeight
continue
}
// Font fallback
var ok bool
for _, f := range d.faces {
if canRender(cl, f.face) {
if d.currentFace != f {
d.flushStrBuf()
}
d.currentFace = f
ok = true
break
}
}
if !ok {
fmt.Println("tofu", cl)
}
d.strBuf += cl
}
d.flushStrBuf()
d.rast.Draw(d.dst, d.dst.Bounds(), image.Black, image.Point{})
return d.dst
}
func canRender(s string, f font.Face) bool {
for _, r := range s {
if _, ok := f.Cmap.Lookup(r); !ok {
return false
}
}
return true
}
const fontSize = 32
func (d *drawer) flushStrBuf() {
if d.strBuf == "" {
return
}
runes := []rune(d.strBuf)
in := shaping.Input{
Text: runes,
RunEnd: len(runes),
Size: fixed.I(fontSize),
Face: d.currentFace.face,
Script: d.currentFace.script,
Language: d.currentFace.language,
}
out := d.shaper.Shape(in)
if d.x == 0 {
// If the grapheme cluster is the first character in the line,
// set base Y position and line height.
d.baseY = out.LineBounds.Ascent
d.lineHeight = out.LineBounds.LineHeight()
}
scale := fixed26_6ToFloat32(out.Size) / float32(out.Face.Upem())
baseX := d.x
for _, g := range out.Glyphs {
data, ok := out.Face.GlyphData(g.GlyphID).(api.GlyphOutline)
if !ok {
continue
}
d.drawGlyph(data.Segments, scale, baseX)
baseX += g.XAdvance
}
d.x += out.Advance
d.strBuf = ""
}
func fixed26_6ToFloat32(x fixed.Int26_6) float32 {
return float32(x>>6) + (float32(x&(1<<6-1)) / (1 << 6))
}
func (d *drawer) drawGlyph(segments []api.Segment, scale float32, baseX fixed.Int26_6) {
segs := make([]api.Segment, len(segments))
for i, seg := range segments {
segs[i] = seg
for j := range seg.Args {
segs[i].Args[j].X *= scale
segs[i].Args[j].Y *= scale
segs[i].Args[j].Y *= -1
}
}
x := fixed26_6ToFloat32(baseX)
y := fixed26_6ToFloat32(d.y + d.baseY)
for _, seg := range segs {
switch seg.Op {
case api.SegmentOpMoveTo:
d.rast.MoveTo(seg.Args[0].X+x, seg.Args[0].Y+y)
case api.SegmentOpLineTo:
d.rast.LineTo(seg.Args[0].X+x, seg.Args[0].Y+y)
case api.SegmentOpQuadTo:
d.rast.QuadTo(
seg.Args[0].X+x, seg.Args[0].Y+y,
seg.Args[1].X+x, seg.Args[1].Y+y,
)
case api.SegmentOpCubeTo:
d.rast.CubeTo(
seg.Args[0].X+x, seg.Args[0].Y+y,
seg.Args[1].X+x, seg.Args[1].Y+y,
seg.Args[2].X+x, seg.Args[2].Y+y,
)
}
}
}
// ...
この実装例を実行すると以下の画像が得られます。

ष्ट्रि が正しい形でレンダリングされています。
さきほどのデーヴァナーガリー、シンハラ文字、チベット文字の例も、以下のように正しくレンダリングされるようになりました。

ところで、(shaping.Shaper).Shape の引数 shaping.Input には、Direction というものも指定できます。
これは、文字の流れる方向を表す値です。
ターナ文字などの右から左に書く文字も、これによってうまく書くことができます。
// https://www.unicode.org/udhr/d/udhr_div.html
// https://www.unicode.org/udhr/d/udhr_arb.html
// https://www.unicode.org/udhr/d/udhr_heb.html
const text = `ހަމަ ކޮންމެ މީހަކަށްމެ ދިރިހުރުމުގެ ޙައްޤާއި، މިނިވަންކަމުގެ ޙައްޤާއި، ތިމާގެހަށިގަނޑާއި ނަފްސުގެ ރައްކާތެރިކަމުގެ ޙައްޤު ލިބިގެންވެއެވެ.
لا يجوز إسترقاق أو إستعباد أي شخص. ويحظر الإسترقاق وتجارة الرقيق بكافة أوضاعهما.
לא יהיה אדם נתון לעינויים, ולא ליחס או לעונש אכזריים, בלתי אנושיים או משפילים.`
func (d *drawer) flushStrBuf() {
// ...
in := shaping.Input{
Text: runes,
RunEnd: len(runes),
Size: fixed.I(fontSize),
Face: d.currentFace.face,
Script: d.currentFace.script,
Language: d.currentFace.language,
+ Direction: di.DirectionRTL,
}
out := d.shaper.Shape(in)
- if d.x == 0 {
+ if d.x == fixed.I(width) {
// If the grapheme cluster is the first character in the line,
// set base Y position and line height.
d.baseY = out.LineBounds.Ascent
d.lineHeight = out.LineBounds.LineHeight()
}
+ d.x -= out.Advance
// ...
- d.x += out.Advance
d.strBuf = ""
}

Shaping も行われており、アラビア文字のつながりや合字も表現できています。
ところが、右から左に流れる文字が、左から右に流れる文字と同じ行に書かれたとき、処理は複雑になります。
次の文章は、UDHR in Unicode のアラビア語の文章です。
(リンク元では . が左端に来ていますが、環境によっては右端に来てしまいます)
文字はどのような流れになっているでしょうか?
اعتُمد بموجب قرار الجمعية العامة 217 ألف (د-3) المؤرخ في 10 كانون الأول / ديسمبر 1948.
カーソルで選択してみると少し不思議な動きになると思います。
アラビア語では、アラビア文字は右から左に流れますが、数字は左から右に流れます。
記号は基本的には文字の流れにあわせて右から左に流れ、場合によっては左右反転した形になります。
この文章を、さきほどの実装例でレンダリングすると、次の画像が得られます。
// https://www.unicode.org/udhr/d/udhr_arb.html
const text = `اعتُمد بموجب قرار الجمعية العامة 217 ألف (د-3) المؤرخ في 10 كانون الأول / ديسمبر 1948.`
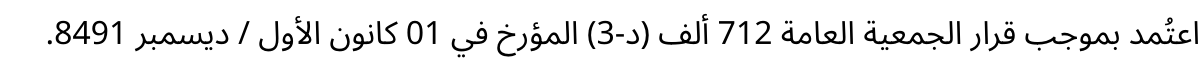
数字が右から左に流れてしまっています。
左書き文字と右書き文字が混在するテキストを正しく描画するには、文字の描画方向をある程度統制する必要があります。
このような処理は BiDi アルゴリズムと呼ばれ、Unicode Bidirectional Algorithm で定義されています。
BiDi - 左書き文字と右書き文字が混在する文字列の描画
BiDi では、強い右書き文字 (ラテン文字など)、強い左書き文字 (アラビア文字など)、中立的な文字 (記号など) といったように、
各文字が持つ属性 (クラス) に基づいて方向を決定しています。
また、段落がどの文字で始まるかによって、段落も方向を持ち、その内部の文字の流れる方向が決められます。
Go では、golang.org/x/text/unicode/bidi をうまく用いることで BiDi 処理後の描画されるべき順番を得ることができます。
以下の例では、文字列を受け取って左から描画される順番に並びかえた文字列を返す関数を定義しています。
package main
import (
"fmt"
"log"
"golang.org/x/text/unicode/bidi"
)
const s = "اعتُمد بموجب قرار الجمعية العامة 217 ألف (د-3) المؤرخ في 10 كانون الأول / ديسمبر 1948."
func main() {
t, err := visualOrdered(s)
if err != nil {
log.Fatal(err)
}
for _, r := range t {
fmt.Println(string(r))
}
}
func visualOrdered(s string) (string, error) {
const fnName = "visualOrdered"
p := &bidi.Paragraph{}
if _, err := p.SetString(s); err != nil {
return "", fmt.Errorf("%s: %w", fnName, err)
}
ord, err := p.Order()
if err != nil {
return "", fmt.Errorf("%s: %w", fnName, err)
}
pd := ord.Direction()
var text string
for i := 0; i < ord.NumRuns(); i++ {
run := ord.Run(i)
str := run.String()
d := run.Direction()
if d == bidi.RightToLeft {
str = bidi.ReverseString(str)
}
if pd == bidi.RightToLeft {
text = str + text
} else {
text += str
}
}
return text, nil
}
Output
.
1
9
4
8
ر
ب
م
س
ي
د
/
ل
و
أ
ل
ا
ن
و
ن
ا
ك
1
0
ي
ف
خ
ر
ؤ
م
ل
ا
(
3
-
د
)
ف
ل
أ
2
1
7
ة
م
ا
ع
ل
ا
ة
ي
ع
م
ج
ل
ا
ر
ا
ر
ق
ب
ج
و
م
ب
د
م
ُ
ت
ع
ا
実際にはこの実装のままではうまくいかない場合があるので、ちゃんとやるならループの中で bidi.LookupRune と (bidi.Properties).Class を用いて文字クラスを判定し、適切に順番を処理する必要がありそうです。
このような関数をつくって文字列を左からの描画順に並べることができれば、あとはこの結果の文字列を左から順番に描画していけばよいです。
行が左始まりか右始まりかによって描画の開始位置を変えたい場合は、段落の方向も必要になります。
BiDi 対応込みで実装をすると以下のようになります。
ここでは、行が右向き文字で始まる場合は左端から、左向き文字で始まる場合は右端から描画するようにしています。
実装例
package main
import (
"fmt"
"strings"
"golang.org/x/text/unicode/bidi"
)
const newLineCharacter = "\n"
type paragraph struct {
str string
isRTL bool
}
// newParagraphs returns bidi-processed paragraphs for a given string.
func newParagraphs(s string) ([]*paragraph, error) {
const fnName = "newParagraphs"
var ps []*paragraph
lines := strings.Split(s, newLineCharacter)
for _, line := range lines {
if line == "" {
continue
}
p, err := newParagraph(line)
if err != nil {
return nil, fmt.Errorf("%s: %w", fnName, err)
}
ps = append(ps, p)
}
return ps, nil
}
func newParagraph(s string) (*paragraph, error) {
const fnName = "newParagraph"
p := &bidi.Paragraph{}
if _, err := p.SetString(s); err != nil {
return nil, fmt.Errorf("%s: %w", fnName, err)
}
ord, err := p.Order()
if err != nil {
return nil, fmt.Errorf("%s: %w", fnName, err)
}
pd := ord.Direction()
var text string
for i := 0; i < ord.NumRuns(); i++ {
run := ord.Run(i)
str := run.String()
d := run.Direction()
if d == bidi.RightToLeft {
str = bidi.ReverseString(str)
}
if pd == bidi.RightToLeft {
text = str + text
} else {
text += str
}
}
if pd == bidi.RightToLeft {
text = bidi.ReverseString(text)
}
par := ¶graph{
str: text,
isRTL: pd == bidi.RightToLeft,
}
return par, nil
}
package main
import (
"bytes"
"embed"
"fmt"
"image"
"image/draw"
"image/png"
"log"
"os"
"github.com/go-text/typesetting/di"
"github.com/go-text/typesetting/font"
"github.com/go-text/typesetting/language"
"github.com/go-text/typesetting/opentype/api"
"github.com/go-text/typesetting/shaping"
"github.com/rivo/uniseg"
"golang.org/x/image/math/fixed"
"golang.org/x/image/vector"
)
// https://www.unicode.org/udhr/d/udhr_sin.html
// https://www.unicode.org/udhr/d/udhr_arb.html
// https://www.unicode.org/udhr/d/udhr_heb.html
// https://www.unicode.org/udhr/d/udhr_tha.html
// https://www.unicode.org/udhr/d/udhr_urd.html
// https://www.unicode.org/udhr/d/udhr_mlt.html
// https://www.unicode.org/udhr/d/udhr_mri.html
// https://www.unicode.org/udhr/d/udhr_div.html
const text = `මානව අයිතිවාසිකම් පිළිබඳ විශ්ව ප්රකාශනය
اعتُمد بموجب قرار الجمعية العامة 217 ألف (د-3) المؤرخ في 10 كانون الأول / ديسمبر 1948.
הואיל והכרה בכבוד הטבעי אשר לכל בני משפחת האדם ובזכויותיהם השוות והבלתי נפקעות הוא יסוד החופש, הצדק והשלום בעולם.
มนุษย์ทั้งหลายเกิดมามีอิสระและเสมอภาคกันในเกียรติศักด[เกียรติศักดิ์]และสิทธิ اس لئے انہیں ایک دوسرے کے ساتھ بھائی چارے کا سلوک کرنا چاہیئے۔
סעיף ב. ජාති, වංශ, වර්ණ, جنس، زبان، مذہب ความคิดเห็นทางการเมืองหรือทางอื่น
oriġini nazzjonali jew soċjali, الثروة أو الميلاد أو أي وضع آخر no tetahi tunga whai-tikanga ranei ހަމަ ކޮންމެ މީހަކަށްމެ`
func main() {
fs, err := faces()
if err != nil {
log.Fatal(err)
}
d := newDrawer(fs)
ps, err := newParagraphs(text)
if err != nil {
log.Fatal(err)
}
i := d.draw(ps)
if err := export(i); err != nil {
log.Fatal(err)
}
}
// Font load
//go:embed src/*.ttf
var fontFiles embed.FS
type fontDefinition struct {
name string
script language.Script
language language.Language
}
var fonts = []fontDefinition{
{
name: "NotoSansArabic-Regular",
script: language.Arabic,
language: "ar",
},
{
name: "NotoSansHebrew-Regular",
script: language.Hebrew,
language: "he",
},
{
name: "NotoSansSinhala-Regular",
script: language.Sinhala,
language: "si",
},
{
name: "NotoSansThaana-Regular",
script: language.Thaana,
language: "dv",
},
{
name: "NotoSansThaiLooped-Regular",
script: language.Thai,
language: "th",
},
}
// ...
// Draw
const (
width = 2000
height = 400
)
type drawer struct {
dst draw.Image
rast *vector.Rasterizer
shaper shaping.Shaper
faces []fontData
currentFace fontData
strBuf string
x fixed.Int26_6
y fixed.Int26_6
baseY fixed.Int26_6
lineHeight fixed.Int26_6
isFirstWord bool
isParagraphRTL bool
}
func (d *drawer) draw(ps []*paragraph) image.Image {
for _, p := range ps {
d.isParagraphRTL = p.isRTL
d.isFirstWord = true
d.resetX()
d.drawParagraph(p)
// Break the line before going to the next paragraph.
d.flushStrBuf()
d.y += d.lineHeight
}
d.rast.Draw(d.dst, d.dst.Bounds(), image.Opaque, image.Point{})
return d.dst
}
func (d *drawer) resetX() {
if d.isParagraphRTL {
d.x = fixed.I(d.dst.Bounds().Dx())
} else {
d.x = 0
}
}
func (d *drawer) drawParagraph(p *paragraph) {
gr := uniseg.NewGraphemes(p.str)
for gr.Next() {
cl := gr.Str()
// Font fallback
var ok bool
for _, f := range d.faces {
if canRender(cl, f.face) {
if d.currentFace != f {
d.flushStrBuf()
}
d.currentFace = f
ok = true
break
}
}
if !ok {
fmt.Println("tofu", cl)
}
d.strBuf += cl
}
d.flushStrBuf()
}
func (d *drawer) flushStrBuf() {
if d.strBuf == "" {
return
}
runes := []rune(d.strBuf)
in := shaping.Input{
Text: runes,
RunEnd: len(runes),
Size: fixed.I(fontSize),
Face: d.currentFace.face,
Script: d.currentFace.script,
Language: d.currentFace.language,
Direction: directionality(d.isParagraphRTL),
}
out := d.shaper.Shape(in)
if d.isFirstWord {
// If the grapheme cluster is the first character in the line,
// set base Y position and line height.
d.baseY = out.LineBounds.Ascent
d.lineHeight = out.LineBounds.LineHeight()
d.isFirstWord = false
} else {
h := out.LineBounds.LineHeight()
if h > d.lineHeight {
d.lineHeight = h
}
}
// Move drawing position to left when the paragraph direction is RTL.
if d.isParagraphRTL {
d.x -= out.Advance
}
scale := fixed26_6ToFloat32(out.Size) / float32(out.Face.Upem())
baseX := d.x
for _, g := range out.Glyphs {
data, ok := out.Face.GlyphData(g.GlyphID).(api.GlyphOutline)
if !ok {
continue
}
d.drawGlyph(data.Segments, scale, baseX)
baseX += g.XAdvance
}
d.strBuf = ""
// Move next drawing position to right when the paragraph direction is LTR.
if !d.isParagraphRTL {
d.x += out.Advance
}
}
func directionality(isParagraphRTL bool) di.Direction {
if isParagraphRTL {
return di.DirectionRTL
}
return di.DirectionLTR
}
// ...

この記事が参考になれば幸いです。
では!👋
Discussion