はじめに
今回は、GPT、Claude、Gemini、Llama、Mistralのそれぞれのモデルの使い所を考えてみたいと思います。
筆者はお客様から、LLMってGPTとかClaude,Geminiとか色々あるけど結局どれがいいの?という質問をよくいただきます。
「ケースバイケースですねぇ...」と一口に言うのは簡単なので、少し踏み込んでどのケースにどのLLMが必要となるのかを考えてみたいと思います。
各LLMの特徴
まずは、LLMの特徴について整理しましょう。
現在、より多く使われているLLMが以下かと思います。
- GPTモデル
- Claudeモデル
- Geminiモデル
- Llamaモデル
- Mistralモデル
比較検討する前にざっくりと特徴をまとめてみます。
GPTモデル

OpenAI社が開発したLLM
最近では以下のモデルが人気。
- o1-preview
- o1-mini
- GPT-4o
- GPT-4o-mini
特徴・コスト・スピードの観点でまとめると以下。
| モデル名 | 特徴 | コスト - 1M tokensあたり - (低いほど嬉しい) | スピード - tokens/secondあたり - (高いほど嬉しい) |
|---|---|---|---|
| o1-preview | 複雑な推論を実行するために強化学習でトレーニングされたモデル。数学オリンピックで89%の得点率だとか。 | $26 | 30 |
| o1-mini | o1-mini は o1-preview よりも 80% 安価で、推論は必要だが広範な世界知識は必要ないアプリケーション向け |
$5.3 | 68 |
| GPT-4o | テキスト、音声、画像、ビデオのあらゆる組み合わせを入力に対応出来、スピードも早い。 | $4.4 | 87 |
| GPT-4o-mini | GPT-4oの軽量版で、gpt-4oと比べて回答精度は落ちるが、スピード早く、コストも安い | $0.3 | 100 |
Claudeモデル

Anthropic社によって開発されたLLM
最近では以下のモデルが人気。
- Claude 3.5 Sonnet
- Claude 3.5 Haiku
特徴・コスト・スピードの観点でまとめると以下。
| モデル名 | 特徴 | コスト - 1M tokensあたり - (低いほど嬉しい) | スピード - tokens/secondあたり - (高いほど嬉しい) |
|---|---|---|---|
| Claude 3.5 Sonnet | 複雑なタスクに優れた精度を発揮し、温かみのある人間のような口調で話すことが出来る。詩的な文脈でも強く、ビジネスドキュメントや創造的なライティングに最適。文書生成に強いんですね。 | $6 | 57 |
| Claude 3.5 Haiku | 短い回答やシンプルなタスクに特化。すばやい応答時間と改善された推論機能を兼ね備えているため、スピードとインテリジェンスの両方が必要になるタスクに最適。 | $0.5 | 124 |
Geminiモデル

Google社が開発したLLM
最近では以下のモデルが人気。
- Gemini 1.5 Pro
- Gemini 1.5 Flash
特徴・コスト・スピードの観点でまとめると以下。
| モデル名 | 特徴 | コスト - 1M tokensあたり - (低いほど嬉しい) | スピード - tokens/secondあたり - (高いほど嬉しい) |
|---|---|---|---|
| Gemini 1.5 Pro | 高度なパフォーマンスを誇り、複雑な問題解決や専門的な用途に対応。AI支援のビジネスアプリケーションに最適。 | $2.2 | 60 |
| Gemini 1.5 Flash | シンプルなタスクに特化し、非常に高速な応答を提供。日常的なやり取りや高速処理が求められるアプリケーション向け。 | $0.1 | 266 |
Llamaモデル

Meta社が開発したLLM
最近では以下のモデルが人気。
- Llama 3.1 Instinct 405B
特徴・コスト・スピードの観点でまとめると以下。
| モデル名 | 特徴 | コスト - 1M tokensあたり - (低いほど嬉しい) | スピード - tokens/secondあたり - (高いほど嬉しい) |
|---|---|---|---|
| Llama 3.1 Instinct 405B | 128,000トークンの長いコンテキストウィンドウをサポートし、長文の処理や複雑な文脈理解に優れる。日本語対応はまだみたい。 | $5.1 | 23 |
Mistralモデル

Mistral AI社が開発したLLM
最近では以下のモデルが人気。
- Mistral Large 2
特徴・コスト・スピードの観点でまとめると以下。
| モデル名 | 特徴 | コスト - 1M tokensあたり - (低いほど嬉しい) | スピード - tokens/secondあたり - (高いほど嬉しい) |
|---|---|---|---|
| Mistral Large 2 | 128,000トークンの長いコンテキストウィンドウをサポートし、長文の処理や複雑な文脈理解に優れる。日本語も対応 | $4.5 | 42 |
上記をざっくりまとめると...
LLMをまとめると以下の3つのグループに分割出来ると考えています。
-
回答精度特化型: 精度が命!コストとかスピードとかは知ったことか!(ex. GPT-o1-preview) -
スピード特化型: スピードが命!精度などある程度で良いわ!(ex. Gemini 1.5 Flash) -
バランス型: 精度・スピード・コストバランスこそ全て!(ex. GPT-4o, Claude 3.5 Sonnet)
それぞれ、ユースケースに合わせて使い分けたいですね。
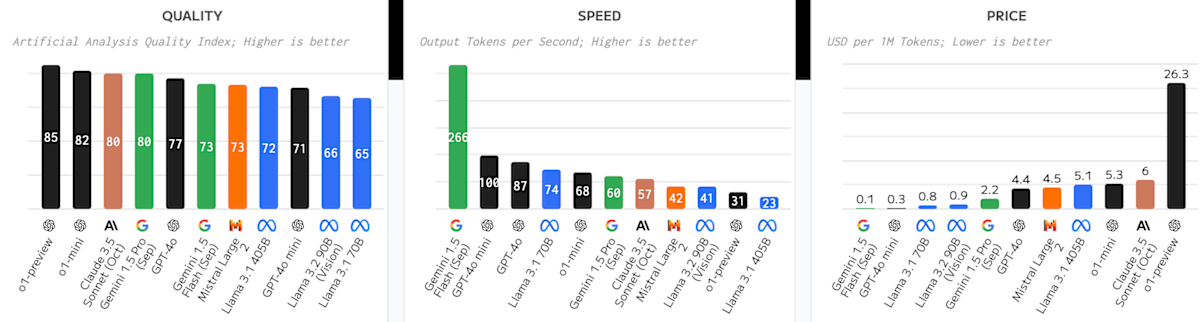
LLMをそれぞれクオリティ部門・スピード部門・コスト部門でグラフで表すと以下のようになります。
クオリティ部門

回答精度の観点から質で言うとOpenAI社のGPT-o1モデルが抜きん出ているようですね。
次はClaude 3.5 SonnetやGemini 1.5 Proが続くようです。
スピード部門

スピードは抜群にGemini 1.5 Frashが速いですね。
その次がGPT-4o-mini, GPT-4oとなるようです。
コスト部門

最後にコストです。
1Mあたりのtokenにかかる料金をUSD🇺🇸で算出しています。
よって、グラフが低い方が安いです。
最も安いのはGemini 1.5 Flashみたいですね。
次がGPT-4o-mini, Llma 3.1 70Bと続くようです。
選定軸をどうするかが大事
パフォーマンス・スピード・コストで比較検討してきましたが、それぞれLLMをご使用される際のユースケースで最適なモデルは変わってくると思います。
それも、皆様が担当されているプロジェクトはコストなんぼかかってもええから、パフォーマンスを出してくれ!みたいな単純な状況は少ないかなと思います。
例えば以下のようなシチュエーションが考えられます。
パフォーマンス:精度高い回答が欲しい
コスト:出来る限り安く抑えたい
スピード:回答のスピードは最低限閾値があるが、それよりも質を優先したい
上記の場合、優先順位としては
パフォーマンス > コスト > スピード
となりますね。
なので、3つの軸からまずはパフォーマンスが高いモデル(gpt-o1-preview, gpt-4o)を選定し、コストを見合いながら許容範囲を調べ、最低限のスピードの閾値を検証しながら決めていく方式になると思います。
例えば以下の図では、縦軸にパフォーマンス・横軸にスピードをとったものになります。

パフォーマンスが第一優先順位なので、赤枠ぐらいのLLMに狙いを定め、

スピードがどこまで欲しいかを右側にずらしながら検証していくような決め方になると思います。

なので、LLMの選定はパフォーマンス > コスト > スピードのそれぞれの優先順位と最低の許容値みたいなところを検証しながら探っていくことになります。
ちなみに、パフォーマンスを縦軸に、コストを横軸にすると以下のような図になります。

パフォーマンスの観点からはo1モデルが現状ぬきん出ているように見えますね。
現状では、o1-miniを個社ごとにカスタマイズして使うのがパフォーマンス・スピード・コストの最適解なのかなと感じてます。
Big Techとの繋がり

そして、話をよりややこしくするのが、LLMを開発している会社のBigTechとのつながりです。
各クラウドプロバイダーがLLMを開発している会社と戦略的パートナーシップを結んだり、LLMを自社開発することで、LLMの開発競争が激化しています。
ざっくりそれぞれのクラウドで使用できるLLMをまとめるといかになります。
Microsoft Azure
Azureで使えるLLMモデルは以下
- GPT
- Llama
- MistralAI
Amazon Web Service
awsで使えるLLMモデルは以下
- Claude
- Llama
- MistralAI
Google Cloud Platform
GCPで使えるLLMモデルは以下
- Gemini
- Llama
- MistralAI
- Claude
先ほどお伝えしたパフォーマンス・スピード・コストに加えて、自社がどのクラウドベンダーと契約しており、抱えているエンジニアがどのスキルスタックかを把握しながらも、これから5年先にどのLLMモデルが覇権をとるかは誰もわからないので、よりマルチクラウドに向かせてどんな戦況にも対応出来る状態にしておくのが良いと考えております。
まとめ
本記事をまとめると以下になります。
- 各LLMのモデルには特徴はあるが、
回答精度特化型,スピード特化型,バランス型にグルーピングできること - 利用するユースケースを鑑みて、パフォーマンス・スピード・コストの観点からLLMを選定すること
- 現在契約しているクラウドベンダーももちろん素敵だが、マルチクラウド化することで今後どのようなLLMの戦況になってもついていける状態にすること
乱立するLLMの戦国時代をうまく乗りこなしていきたいところですね。
それでは👋
参考文献

Discussion