LLMがアプリケーションに組み込まれ始めていますが、LLMを組み込んだアプリケーションというのは非常に評価が難しいです。
いわゆる"AI"を使用しないアプリケーションの場合は基本的に処理はルールベースで実行されるため、単体テストやE2Eテストなりで評価を行うことが可能です。
一方でLLMをはじめとしたAIモデルは確率生成に依る部分が多く、テストパスが通ったからと言って毎回同じ出力が得られるとは限りませんし、自然言語で出力された結果をルールベースで評価することも困難です。
上記のように、モデルアップデートのための評価は大変な反面、LLM自体の進化は早く、モデルのアップデートが頻繁に行われています。
例えばOpenAIのGPT-3.5-turboやGPT-4を見ると、リリースから現在まで0301 / 0613 とバージョニングがされていて、それを並行してgpt-35-turbo-16kなどの別モデルもリリースされています。加えて、リリース当初にあったtext-davinci-003などがレガシーモデルとして非推奨になるなど、流行り廃りが激しい状況です。
もちろんOpenAI社が新しいモデルを出す場合は一定のテスト・評価を行ってリリースされていると推測しますが、そのテストケースにあなたの利用シナリオが含まれているとは限りません。
特にLLMは入力と出力の形式が定まっていないため入力(プロンプト)の書き方でいくらでも出力が変わることがあります。
本記事での目的
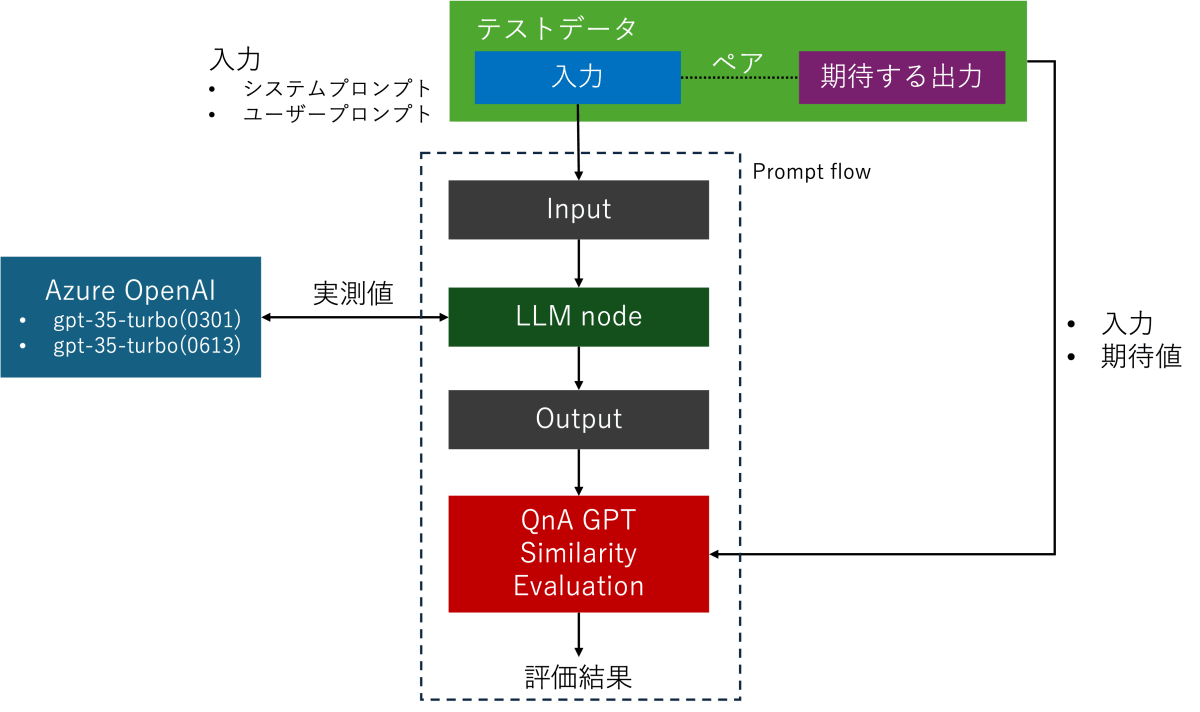
本記事ではモデルまたはモデルのバージョンの違いによる出力を評価します。
具体的には、最初に「入力」に対する「期待する出力」のペアデータを用意します。
入力を評価対象の各モデルに与えて実際の出力(実測値)がどれほど「期待する出力」と類似性があるのかを定量的に評価します。つまりLLMモデルの単体テストということです。
複数のバージョンのモデルで比較して類似性が向上すれば、そのテストデータ(特定シナリオ)における対象モデルの評価は向上した、逆に類似性が下がれば低下した、ということになります。

なお今回は評価にAzure Machine Learning のプロンプトフローを使ってみます。
ローカルで環境を作る必要がなく、クラウドに環境を用意することで運用・共有・管理がやりやすくなります。
どうやって評価するの?
ルールベースでの評価が難しいなら評価もLLMにやらせてしまえばいいじゃない、というアプローチがあります。
LLMを使用したLLMの評価は「Is ChatGPT a Good NLG Evaluator? A Preliminary Study」という論文が発表されるなど、注目され始めています。評価に使用するLLMを都度変更してしまうと評価基準がずれることになるので、同じモデルを使用して評価を行うことが重要です。
プロンプトフローには「組み込みの評価メトリック」というものがあり、今回はこの中にある「QnA GPT Similarity Evaluation」を使用します。
このメトリックはGPT モデルを使用して、提供された期待値の回答と実際にモデルで推論された出力の類似性を1~5の間で測定します。
その他にも「LLMの回答に現実性があるのか」といった指標や「文法的に間違っていないか」といった様々な組み込み指標があります。
レッツトライ
今回は以下のようなシンプルなフローを作ります。
テストデータの作成
CSV,TSV,JSONLのいずれかの形式で「システムプロンプト」「入力」と「期待値」を記載したファイルをローカルで作成します。
今回は個人的な好みからJSONLを使用します。
このデータはなるべく実際にLLMを適用しようとしているタスクに沿ったプロンプトを用意することが望ましいです。
また、プロンプトの内容ももちろん重要ですが、今回の目的は同じプロンプトを使ってモデルごとの出力の変化を確認するというところがポイントです。
今回は以下のようなデータを用意しました。列名は後ほどマッピングをするので任意の列名で構いません。
- system: LLMへ入力するシステムプロンプト
- content:LLMへ入力するプロンプト
- ground_truth:期待するLLMからの出力
{"system":"あなたはユーザーの友達です。答えを与えず常に同情してください。", "content":"C#がわかりません!", "ground_truth":"大丈夫ですよ!一緒にがんばりましょう。あなたならできます。"}
{"system":"あなたはITに関するトレーナーです。質問に対して適切に回答してください。", "content":"C#がわかりません!", "ground_truth":"C#をはMicrosoftが開発したオブジェクト指向言語です。C#を学ぶには基本的な構文から始めてみましょう。"}
{"system":"あなたは図書館員です。リクエストに対して適切な本を提案してください。", "content":"シェイクスピアについて学びたいです。", "ground_truth":"「シェイクスピア: The Biography」 by Peter Ackroydが良いでしょう。彼の生活と作品についての包括的な洞察を提供します。"}
{"system":"あなたは心理カウンセラーです。話し手の感情を理解し、慎重に対応してください。", "content":"最近、仕事がうまくいかない。", "ground_truth":"それはとても厳しい状況に見えますね。一緒に解決策を見つけることができるでしょう。"}
...
フルデータはこちら
テスト対象モデルのデプロイ
すでにテスト対象のモデルがある場合、このステップは不要です。
今回はAzure OpenAI Serviceのモデルをテスト対象とするので、Azure OpenAI Serviceをデプロイしておきます。
Azure OpenAI Studioからテスト対象のモデルをデプロイします。今回は以下の2つのモデルを比較することにします。
また、評価にもLLMを使用するので評価用モデルも用意します。必ずしも評価用のモデルを別に作る必要はないため今回はgpt350613を流用します(重要なことは「すべての評価をこのモデルで行う=評価基準を統一する」ということです)。
- gpt-35-turbo(0301):chatgpt
- gpt-35-turbo(0613):gpt350613

実行環境(ワークスペース)の作成
Machine Learning Studioにアクセスします。
「ワークスペース」→「新規」を選択します。

裏でAzureリソースが作成されるので、そのリソースを配置するサブスクリプションとリソースグループおよびリージョンを選択します。
まだリソースグループがない場合は新規作成で一緒に作成しましょう。
ワークスペース名は適当に設定して「作成」を選択します。

Azure OpenAI接続の追加
ワークスペースができたらワークスペースの概要画面から「プロンプトフロー」→「接続」タブを選択します。
「新規」→「Azure OpenAI」を選択します。

テスト対象モデルのデプロイでモデルがデプロイしてあるAzure OpenAI Serviceのリソースを選択します。
APIキーとAPI baseは入力する形式なのでAzure OpenAI Studioなどから確認してコピペします。情報が揃ったら「保存」を選択して接続を作成します。

プロンプトフローの作成
接続ができたら「プロンプトフロー」タブを選択して「作成」を選択します。

今回は評価のためのフローを作るので「評価フロー」のテンプレートからスタートします。

フォルダー名(フロー名)を適当に設定して「作成」を選択します。

ランタイムの用意
フローの初期画面が表示されます。
最初にランタイムを用意します。ランタイムは簡単に言うと実際の処理を実施するVMです。
フロー編集画面の右上から「ランタイムの追加」→「コンピューティングインスタンスランタイム」を選択します。
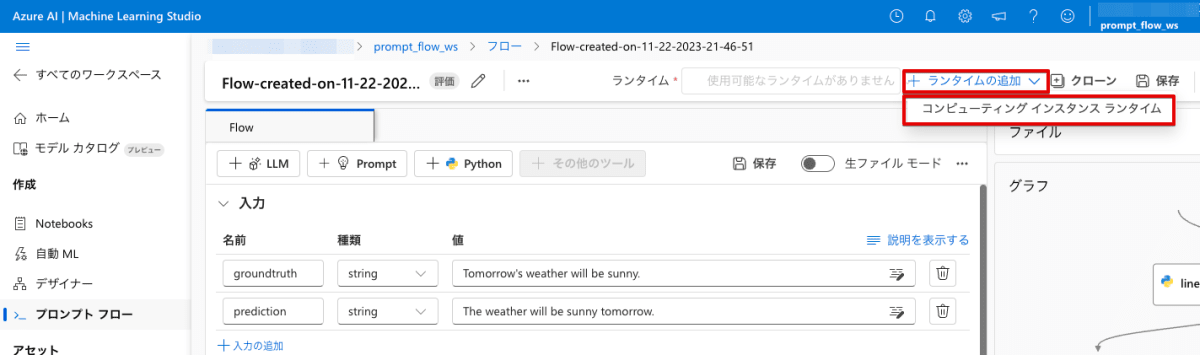
「Azure ML コンピューティングインスタンスを作成する」を選択します。

インスタンスの作成画面が表示されます。
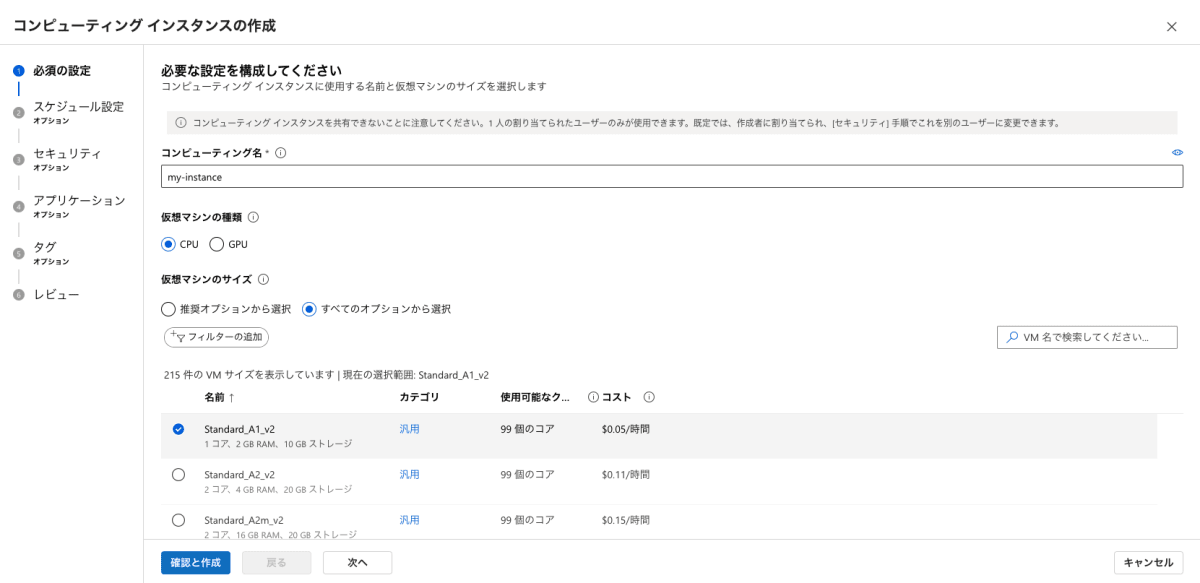
今回は比較的軽微な評価処理なので一番低いスペックを選択します。
複雑な計算が要求される場合にはGPUなどハイパフォーマンスなコンピューティングリソースも選択できます(もちろんその場合は課金額も上がります)。
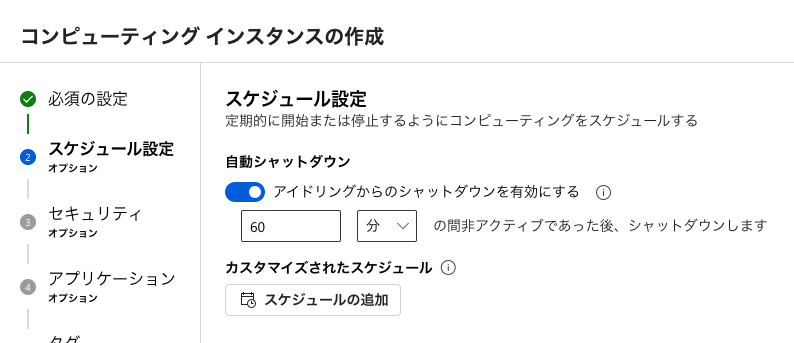
自動シャットダウンをスケジュールしておきます。
インスタンスが停止していれば課金も止まるので、停止までの時間は任意でいいですが、有効にしておくことをおすすめします。
その他の項目は特に今回は設定しないので「次へ」を選択していきます。
最終的なレビュー画面が表示されるので問題なければ「作成」を選択します。

ランタイムの作成画面に戻ります。
作成したインスタンスが選択されていることを確認します。インスタンスの準備は少し時間がかかります。
準備が完了すると認証ボタンが表示されるので「認証」を選択します。

認証に成功したら「作成」でランタイムを作成します。

フローの編集画面に戻ります。ランタイムの選択から追加したランタイムが選択されていることを確認します。ランタイムがグリーンになるには少し時間がかかる場合があります。

フローの作成
それでは今回のメイントピックであるフローを作成していきます。と言ってもそんなに手数は多くありません。
最初に「line_process」と「aggregate」ノードを削除します。

次に「入力」のセクションを次のように変更します。
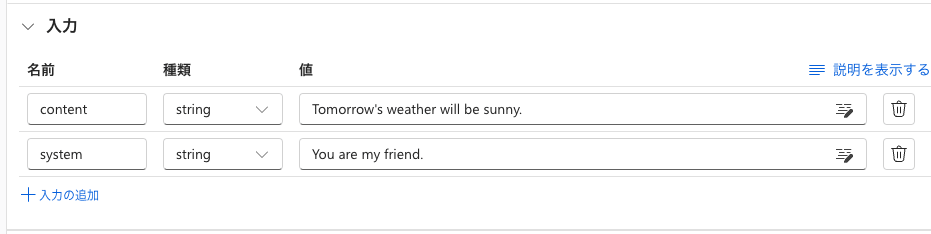
LLMツールを追加して、適当にノード名を入力します。ここではTargetとしました。

LLMノードの設定を以下のようにして「入力の検証と解析」を選択します。
- 接続:[Azure OpenAI接続の追加](##Azure OpenAI接続の追加)で作成した接続を選択
- API:chat
- デプロイ名:chatgpt(gpt-35-turbo(0301))
- プロンプト:
system:
{{system}}
user:
{{question}}

入力の検証が完了するとプロンプトで変数として定義した2つが表示されます。
それぞれ入力で定義したパラメーター名とマッピングします。
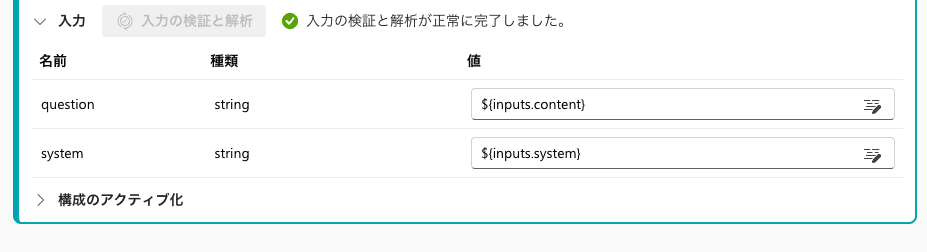
出力のセクションでLLMノードからの出力を指定します。

バリエーションの追加
バリエーションは1つのノードに対して設定値を変更したものを複数作成することができます。
今回はこれを利用して複数のモデル(デプロイ)のバリエーションを定義することによって同じ評価フローを複数のモデルで使いまわします。
LLMノードから「バリアントの生成」を選択します。

デプロイ名を比較対象のモデルに変更して「送信」を選択します。
ここではgpt350613(gpt-35-turbo(0613))を選択しました。

バリエーションが追加されたのが確認できます。
もしバリエーションが一つしか表示されていない場合は「バリエーションを表示する」をクリックすると全てのバリエーションが表示されます。

最後に「保存」を選択してフローを保存します。これで評価用のフローが完成です。
評価の実施
フローが完成したら「評価」を選択してバッチ評価を準備します。

評価の基本設定で大事なのはフローの設定で選択したバリエーション(=評価対象モデル)が正しく選択されていることです。
今回は2つのモデルを比較するので、variant_0とvariant_1を選択します。
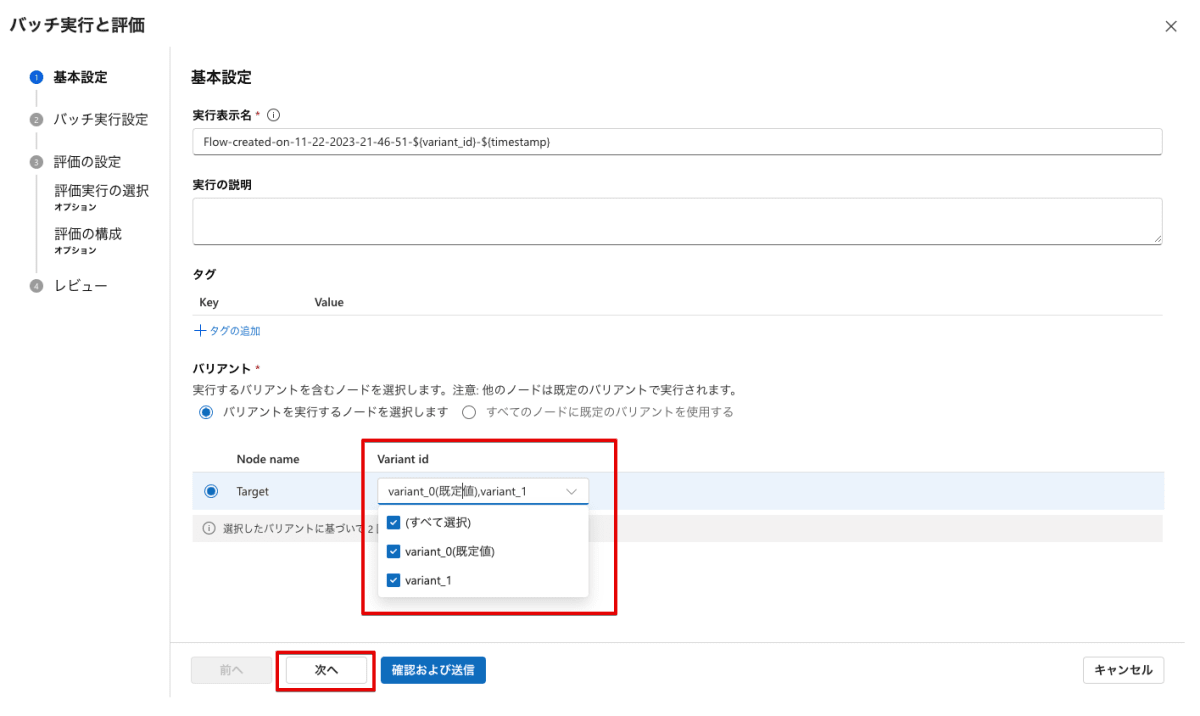
評価データの設定では先ほど作成したJSONLデータをローカルからアップロードします。


データをアップロードするとデータがクラウド上に読み込まれます。ここでプロンプトフローで定義した入力に対してどれを与えるかを選択します。
今回は「システムプロンプト」と「プロンプト」を入力に定義しているので、テストデータからそれぞれsystemとcontent列を選択します。

評価方法を選択します。最低限「QnA GPT Similarity Evaluation」を選択します。
今回は追加で出力が文法が間違っていないかなどを評価する「QnA Fluency Evaluation」も選択しておきます。このように複数の評価を同時に選択できます。

まずは「QnA GPT Similarity Evaluation」のセットアップを行います。
このテストには3つの指標が必要です。カッコ内は今回の場合の対応するデータの列名です。
- question:LLMモデルへの質問(content)
- groud_truth:期待する回答(ground_truth)
- answer:実際にLLMモデルから返ってきた出力(プロンプトフローのresult)
また、この指標は評価にもLLMを使用するため、どのモデル(デプロイ)を使用するかも併せて指定します。

続いてオマケの「QnA Fluency Evaluation」のセットアップを行います。
このテストには3つの指標が必要です。カッコ内は今回の場合の列名です。
- question:LLMモデルへの質問(content)
- answer:実際にLLMモデルから返ってきた出力(プロンプトフローのresult)
また、この指標も評価にLLMを使用するため、同様にどのモデル(デプロイ)を使用するかを指定します。

ここまで設定すれば評価の準備が完了です。最終のレビュー画面で意図した設定になっているか確認して「送信」を選択します。
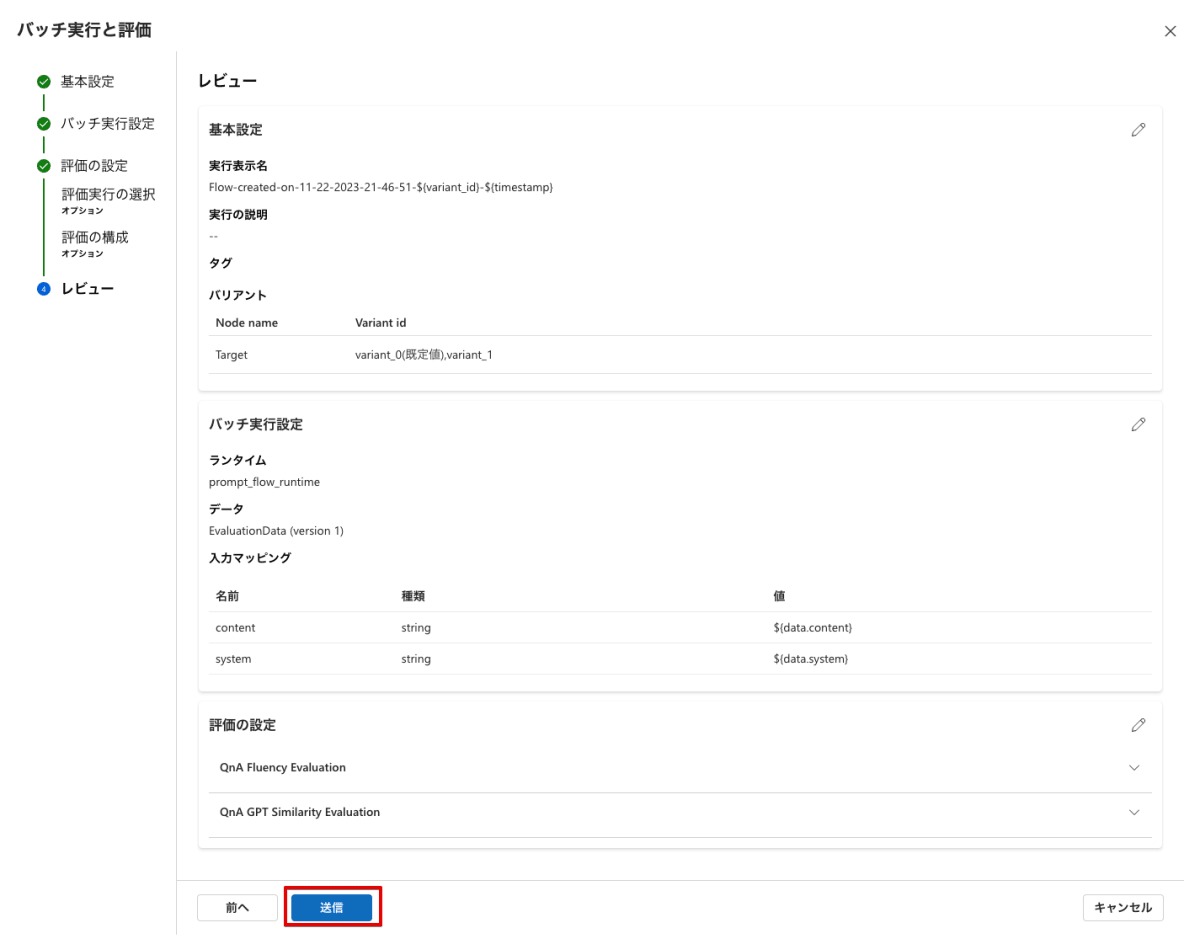
結果の確認
評価を実行するとプロンプトフローの画面に戻ります。上部から「実行リストの表示」を選択します。

バリエーションごとに実行一覧が表示されます。今回はvariant_0とvariant_1の2つのバリエーションを選択しているので2つの実行が表示されます。
状態列が完了になってランタイム上で実行が完了するまで待機します。
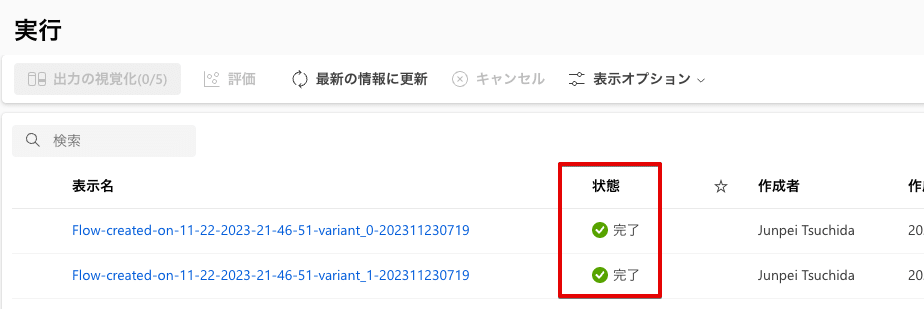
すべてのバリエーションの実行が完了したら、各バリエーションにチェックを入れて「出力の視覚化」を選択します。

出力の可視化が表示されますが、初期状態では各評価結果が非表示になっているので目のアイコンをクリックして表示します。
この状態では全ての列が表示されており見づらいので列を選択してフィルターをかけます。

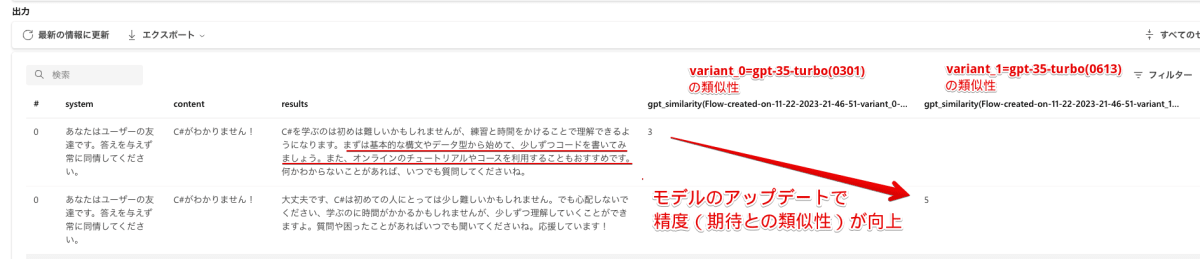
列オプションで表示したい列のみを右側に残します。今回は「system」「content」「results」「各バリエーションのqna_similarity」「各バリエーションのqna_fluency」を表示します。

列名が少し見づらいですが、variant_0(gpt-35-turbo(0301))とvariant_1(gpt-35-turbo(0613))での類似性がそれぞれ表示されています。
プロンプトごとに結果は異なりますが、最初の評価データでは0301と比較して0613のほうがスコアが高くなっています。
ここからは推測ですが、答えを与えない出力を期待しているのに対して、0301の出力は「まずは基本的な構文やデータ型から始めて、少しずつコードを書いてみましょう。また、オンラインのチュートリアルやコースを利用することもおすすめです。」とガイドをしているところから望んだ結果との類似性が低いと判断されたのではないかと思います。
なおこの結果をCSVでエクスポートして更に別工程へ利用することもできます。
まとめ
本記事で見てきたようにPrompt Flowを使用するとモデルの評価を簡単に行うことができました。
新しいモデルがリリースされたらその都度モデルに対してすぐに評価できる評価基盤をクラウド上に作っておくと、モデルのアップデートに対して素早く対応できるようになります。
今回は使用しませんでしたが、ベクトル計算(emmbedding)を使用して類似性を計算する組み込みの評価メトリックもあります。ぜひお試しください!
なお今回のフローと同等の評価をローカルのNotebookでも実装してみた記事も投稿しました。データをこねくり回したい方はこちらもマッチするかもしれません。
参考

Discussion