GitHub Copilot
GitHub Copilotは、AIによるチャットやインラインでのコーディング補助を目的としたツールです。GitHub Copilotの動作特徴としてGitHub上に公開されているコードを学習したりRAGをしています。逆にいうと非公開の独自情報やベースになっているLLMが持っている記憶にない情報は答えることができません。[1]
カスタムインストラクション
上記のような課題を解決するために カスタムインストラクション機能がこの度追加されました。(執筆時点ではパブリックプレビュー)
カスタムインストラクションは文字通りカスタムの指示(Instruction)や情報(Context)をCopilotに対して与えられる機能です。
カスタムインストラクションの有効化
VS Codeの場合は規定で有効なのでこの手順はスキップできます。Visual Studioでは既定で無効になっているので設定が必要です。
VS Codeであえて無効にしたい場合も同様に設定で無効にできます。
その他のエディターのCopilotには現在対応していないようです。
カスタムインストラクションの与え方
カスタムインストラクションの与え方は2つあります。
.github/copilot-instructions.mdに記述
カスタムインストラクションはプロジェクトディレクトリ内の特定のファイル .github/copilot-instructions.mdに記述することで与えることができます。たったそれだけです。
私はこの手順を見た時に半ば感動を覚えました。
このような機能は深く考えずにVS Codeなどの環境設定項目として付けてしまいがちです(私はそうです)が、このようにプロジェクトディレクトリ内にファイルを作成することによりプロジェクトのソースコード同様にGit管理下においてバージョン管理をしたり、開発チームメンバーと共有してメンバー間で同じ環境を簡単に再現することができます。
.github/ディレクトリもGitHub ActionsやPull Requestテンプレートなどの設定ファイルを置く場所として使われているので、この場所に置くのは確かに自然な流れだと思います。あっぱれGitHubエコシステム・・・!
VS Codeのローカル設定
VS Codeの設定github.copilot.chat.codeGeneration.instructionsからユーザー環境ごとにカスタムインストラクションを与えることもできます。執筆時点ではJSONで書く必要がありますが、インストラクションをMarkdownで書いておいて、そのファイルを参照させることもできるようになっています。
"github.copilot.chat.codeGeneration.instructions": [
{
"text": "生成するコードには常に次のコメントをつけてください: 'Generated by Copilot'."
},
{
"file": "code-style.md" // import instructions from file `code-style.md`
}
],
未知の技術や概念を教える
というわけで使ってみます。
今回はMicrosoftが出しているプロンプト用のフォーマットであるPromptyを題材にしてみます。
Promptyは2024年の5月にアナウンスされたLLMのプロンプトを効率的に管理するためのフォーマットです。
詳細は以下の記事をご参照ください。
前述の通り比較的新しい技術のため、GitHub Copilotに聞いても概念すら知りません。
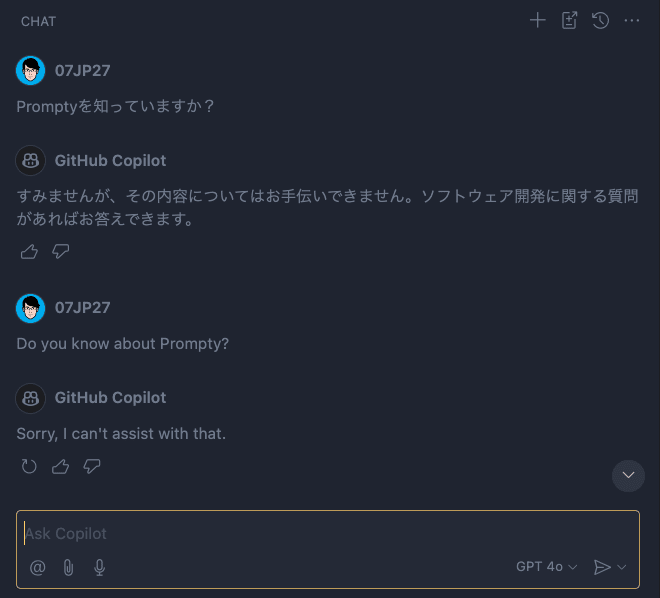
ここでカスタムインストラクションファイルを作成してカスタムの情報を与えてみます。
与える情報はPromptyのドキュメントにある概要やサンプルファイル、スキーマ情報などです。
カスタムインストラクションは長いので折りたたんでおきます。詳細を確認したい方は以下からご覧ください。
カスタムインストラクション全文を表示
- Prompty Components
The Prompty implementation consists of three core components - the specification (file format), the tooling (developer experience) and the runtime (executable code). Let's review these briefly.
1.1 The Prompty Specification
The Prompty specification defines the core .prompty asset file format. We'll look at this in more detail in the Prompty File Spec section of the documentation. For now, click to expand the section below to see a basic.prompty sample and get an intuitive sense for what an asset file looks like.
---
name: Basic Prompt
description: A basic prompt that uses the GPT-3 chat API to answer questions
authors:
- sethjuarez
- jietong
model:
api: chat
configuration:
api_version: 2023-12-01-preview
azure_endpoint: ${env:AZURE_OPENAI_ENDPOINT}
azure_deployment: ${env:AZURE_OPENAI_DEPLOYMENT:gpt-35-turbo}
sample:
firstName: Jane
lastName: Doe
question: What is the meaning of life?
---
system:
You are an AI assistant who helps people find information.
As the assistant, you answer questions briefly, succinctly,
and in a personable manner using markdown and even add some personal flair with appropriate emojis.
#
Customer
You are helping {{firstName}} {{lastName}} to find answers to their questions.
Use their name to address them in your responses.
user:
{{question}}
This schema represents the specification file for the prompty.
# _frontmatter_, not the content section.
$schema: http://json-schema.org/draft-07/schema#
$id: http://azureml/sdk-2-0/Prompty.yaml
title: Prompty front matter schema specification
description: A specification that describes how to provision a new prompty using definition frontmatter.
type: object
properties:
$schema:
type: string
# metadata section
model:
type: object
additionalProperties: false
properties:
api:
type: string
enum:
- chat
- completion
description: The API to use for the prompty -- this has implications on how the template is processed and how the model is called.
default: chat
configuration:
oneOf:
- $ref: "#/definitions/azureOpenaiModel"
- $ref: "#/definitions/openaiModel"
- $ref: "#/definitions/maasModel"
parameters:
$ref: "#/definitions/parameters"
response:
type: string
description: This determines whether the full (raw) response or just the first response in the choice array is returned.
default: first
enum:
- first
- all
name:
type: string
description: Name of the prompty
description:
type: string
description: Description of the prompty
version:
type: string
description: Version of the prompty
authors:
type: array
description: Authors of the prompty
items:
type: string
tags:
type: array
description: Tags of the prompty
items:
type: string
# not yet supported -- might add later
# base:
# type: string
# description: The base prompty to use as a starting point
sample:
oneOf:
- type: object
description: The sample to be used in the prompty test execution
additionalProperties: true
- type: string
description: The file to be loaded to be used in the prompty test execution
# the user can provide a single sample in a file or specify the data inline
# sample:
# messages:
# - role: user
# content: where is the nearest coffee shop?
# - role: system
# content: I'm sorry, I don't know that. Would you like me to look it up for you?
# or point to a file
# sample: sample.json
# also the user can specify the data on the command line
# pf flow test --flow p.prompty --input my_sample.json
# if the user runs this command, the sample from the prompty will be used
# pf flow test --flow p.prompty
inputs:
type: object
description: The inputs to the prompty
outputs:
type: object
description: The outputs of the prompty
# currently not supported -- might not be needed
# init_signature:
# type: object
# description: The signature of the init function
template:
type: string
description: The template engine to be used can be specified here. This is optional.
enum: [jinja2]
default: jinja2
additionalProperties: false
definitions:
# vanilla openai models
openaiModel:
type: object
description: Model used to generate text
properties:
type:
type: string
description: Type of the model
const: openai
name:
type: string
description: Name of the model
organization:
type: string
description: Name of the organization
additionalProperties: false
# azure openai models
azureOpenaiModel:
type: object
description: Model used to generate text
properties:
type:
type: string
description: Type of the model
const: azure_openai
api_version:
type: string
description: Version of the model
azure_deployment:
type: string
description: Deployment of the model
azure_endpoint:
type: string
description: Endpoint of the model
additionalProperties: false
# for maas models
maasModel:
type: object
description: Model used to generate text
properties:
type:
type: string
description: Type of the model
const: azure_serverless
azure_endpoint:
type: string
description: Endpoint of the model
additionalProperties: false
# parameters for the model -- for now these are not per model but the same for all models
parameters:
type: object
description: Parameters to be sent to the model
additionalProperties: true
properties:
response_format:
type: object
description: >
An object specifying the format that the model must output. Compatible with
`gpt-4-1106-preview` and `gpt-3.5-turbo-1106`.
Setting to `{ "type": "json_object" }` enables JSON mode, which guarantees the
message the model generates is valid JSON.
seed:
type: integer
description: >
This feature is in Beta. If specified, our system will make a best effort to
sample deterministically, such that repeated requests with the same `seed` and
parameters should return the same result. Determinism is not guaranteed, and you
should refer to the `system_fingerprint` response parameter to monitor changes
in the backend.
max_tokens:
type: integer
description: The maximum number of [tokens](/tokenizer) that can be generated in the chat completion.
temperature:
type: number
description: What sampling temperature to use, 0 means deterministic.
tools_choice:
oneOf:
- type: string
- type: object
description: >
Controls which (if any) function is called by the model. `none` means the model
will not call a function and instead generates a message. `auto` means the model
can pick between generating a message or calling a function. Specifying a
particular function via
`{"type": "function", "function": {"name": "my_function"}}` forces the model to
call that function.
`none` is the default when no functions are present. `auto` is the default if
functions are present.
tools:
type: array
items:
type: object
frequency_penalty:
type: number
description: What sampling frequency penalty to use. 0 means no penalty.
presence_penalty:
type: number
description: What sampling presence penalty to use. 0 means no penalty.
stop:
type: array
items:
type: string
description: >
One or more sequences where the model should stop generating tokens. The model
will stop generating tokens if it generates one of the sequences. If the model
generates a sequence that is a prefix of one of the sequences, it will continue
generating tokens.
top_p:
type: number
description: >
What nucleus sampling probability to use. 1 means no nucleus sampling. 0 means
no tokens are generated.
その後再度GitHub Copilotに聞いてみると、同じ質問文でPromptyについての情報を返してくれました。
インストラクションは英語のみの提示でしたが、環境で設定されている日本語に翻訳して回答してくれているあたりはさすがベースのLLMの強さといったところです。
チャット入力ボックスにはカスタムインストラクションファイルを参照していることがわかる表示がされています。
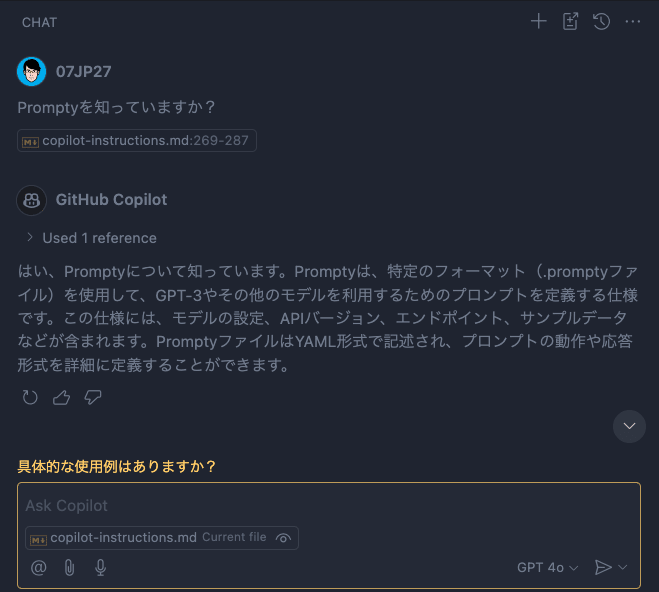
Promptyを知っていることが確認されたので、続いてPromptyのサンプルファイルの作成を依頼してみます。
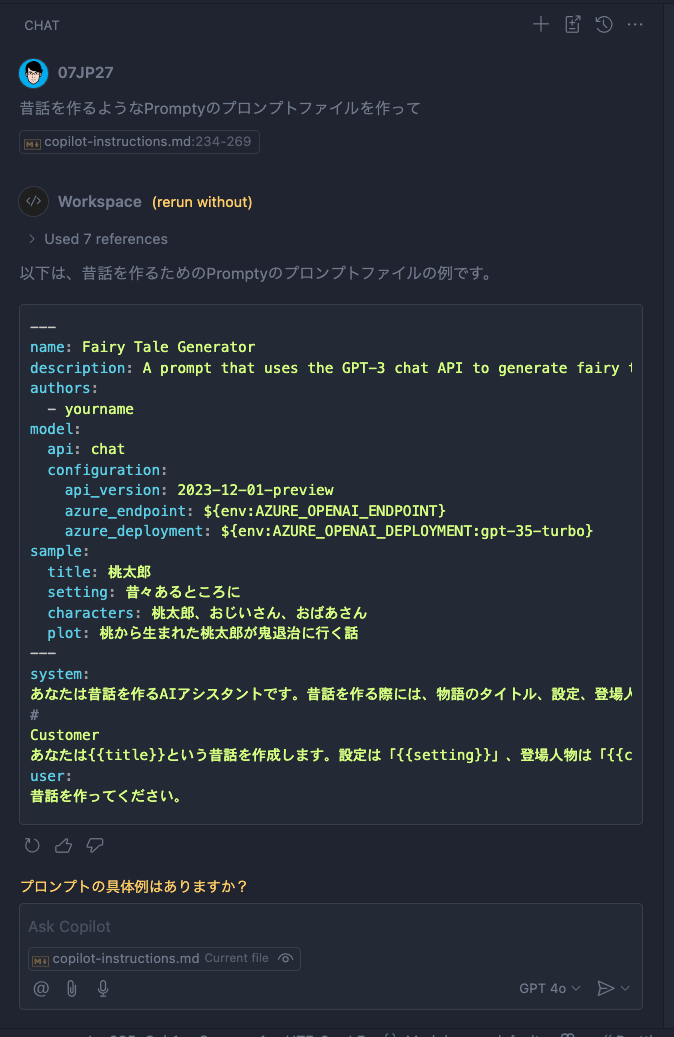
なんということでしょう。今までは概念すら知らなかったGitHub Copilotが実際にコードを生成してくれるまでになりました。
あとはGitHub Copilotが元々持っている機能の「Insert into new file(このコードを新しいファイルとして作成)」ボタンを押すだけで、ベースのファイルが作成されました。
GitHub Copilot Editsでも使えるぞ!
さてここまででベースのPromptyファイルができましたが、まだまだ望んだ内容のプロンプトではないかもしれません。そこで、これを元にGitHub Copilot Editsに対して編集を依頼してみます。
GitHub Copilot Editsも最近プレビューでリリースされた機能で、GitHub Copilotによってコードを編集してもらうことができます。
個人的にはこれもかなりの神機能で、コンテキストとして与えた複数ファイルにまたがって考え、変更を差分で表示提案してくれるのが素晴らしいと思います。
Copilot Editsに対してPromptyファイルを編集してもらうために、カスタムインストラクションのファイルもEditsのコンテキストに含めます。
ここでもカスタムインストラクションをファイルとして定義しているメリットが発揮されます。
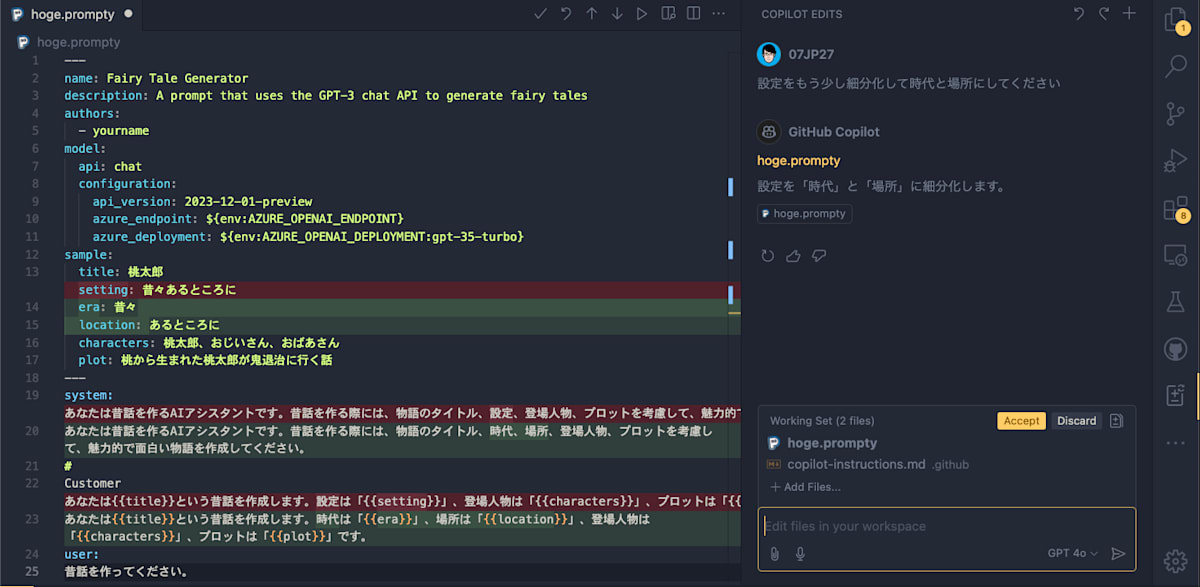
もはやここまでくると凄すぎてため息しか出ません。あとはAcceptボタンを押すだけでこの変更が適用されます。
与えられた情報とコンテキストから自律的に何をどのように変更すべきかを考え、実際にそれを行う。まさにAgentのお手本のような動きです。
まとめ
この記事で紹介したようにカスタムインストラクションによってGitHub Copilotに対してLLMがまだ知らない最新情報を教え込むことができるようになりました。
今回は割愛しましたが、最新の情報だけではなく、社内のコーディング規約やプロジェクト特有のルール(例えば、特定のライブラリを使わない、変数の命名規則)を教え込むことも可能です。
GitHub Copilotの挙動をカスタムできることにより開発の可能性が無限に広がります。
繰り返しになりますが、カスタムインストラクションをファイルとしてプロジェクトで管理できる点は開発者個人の生産性を向上させるだけでなく、チーム全体の生産性を向上させたいというGitHubの熱意が感じられました。
余談 - より良いカスタムインストラクションの書き方
GitHub Copilotのカスタムインストラクションのドキュメントにはしない方がよいプロンプトの例がいくつか挙げられています。
このような事項も念頭に置いてカスタムインストラクションを書くことで、より効果的な指示を与えることができます。
- 応答を作成するときに外部リソースを参照するという要求(例:microsoft/promptyのリポジトリの情報から答えてください)
- 特定のスタイルで回答するという指示(例:親しみやすい友達のように答えてください)
- 常に特定の詳細レベルで応答するという要求(例:100文字以内で回答してください)
-
GitHub Copilot Enterpriseは独自の非公開リポジトリコードをファインチューニングできたりします。 ↩︎

Discussion