
はじめに
この記事は Microsoft Fabric Data Agent と Azure AI Agent Service を連携させて、ビッグデータを AI Agent で分析するシステムを最小単位で構築します。
2025/4/1 に AI Agent Service から Microsoft Fabric のコネクタがリリースされました。
この Update により、Microsoft Fabric Data Agent を使用して、OneLake 内のデータを AI Agent が参照出来るアプリケーションが簡単に構築することが出来ます。
すなわち、Microsoft Fabric × Azure AI Agent Service を連携して、以下のフローを自動化することが出来ることになります。
データレイクによる情報収集 → データウェアハウスでのデータ構造化 → データマートで必要箇所のデータの区分分け →AI が必要となるデータ部分を参照し、最適な意思決定を実施 →AI Agent を用いたアクションの実行
データ収集から構造化、分析、意思決定、アクションに至るまでのプロセスをいい感じにやってくれそうですね。
少し話はそれますが、データレイク・データウェアハウス・データマートの説明は以下になります。
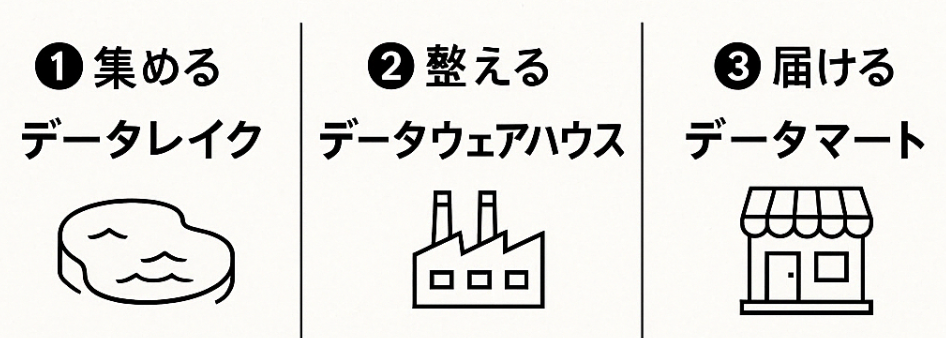
| ステージ | 主役 | 役割 (ざっくり 説明) |
|---|---|---|
| ① 集める | データレイク | ありのままを “全部貯める池” だと理解すれば OK• ログ・画像・CSV・Parquet など多種多様 • スキーマ‑オン‑リード (読むときに意味づけ) • 安価で無限スケール |
| ② 整える | データウェアハウス | 統合・整形した高品質データ • フォーマット統一・欠損補完・型変換 • スキーマ‑オン‑ライト (書込時に定義) • 列指向・インデックスで高速集計 |
| ③ 届ける | データマート | データを小分けして配布する機能 • 部門/業務特化 (販売、人事 など) • 要件に合わせて列・粒度を絞り込み • 自サービスで BI を作る際に利用 |
データレイクへのデータ蓄積とデータウェアハウスでのデータ構造化やデータマートの構築を Fabric を使って行い、意思決定プロセスを AI Agent Service を用いてアプリケーション側で実施することが本記事の目標です。
ビッグデータ分析から AI Agent の利活用を検討されている方に参考になれば幸いです。
大目標
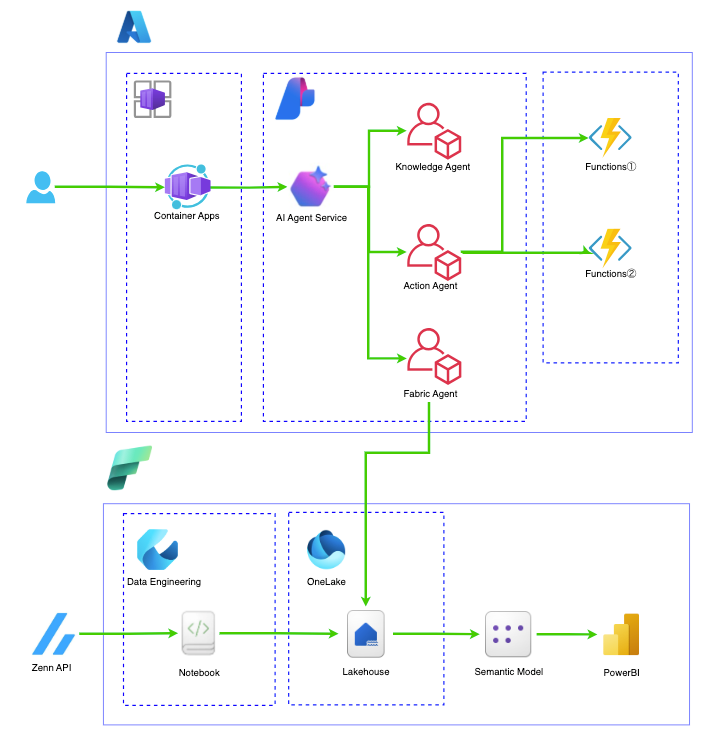
Microsoft Fabric で OneLake へ蓄積、Data Engineering にて分析したデータを AI Agent 経由でアプリケーションから AgentRAG を実施すること
目標とする構成
Microsoft Fabric データ エージェント利用の前提条件
Microsoft Fabric データ エージェント利用の為には以下の設定を実施する必要があります。
- ファブリック容量リソースの使用
- Fabric データ エージェントのテナント設定が有効になっている。
- Copilot テナント スイッチ が有効になっています。
- AI のクロス geo 処理が有効になっています。
- AI のクロスジオ格納が有効になっています。
- データを含む、ウェアハウス、レイクハウス、1 つ以上の Power BI セマンティック モデル、または KQL - データベースのうち少なくとも 1 つ。
- POWER BI セマンティック モデルのデータ ソースに対して、XMLA エンドポイントテナントスイッチ を介して Power BI セマンティック モデルが有効になります。
上記の設定をしていきます。
Microsoft Fabric データ エージェント利用の各種設定
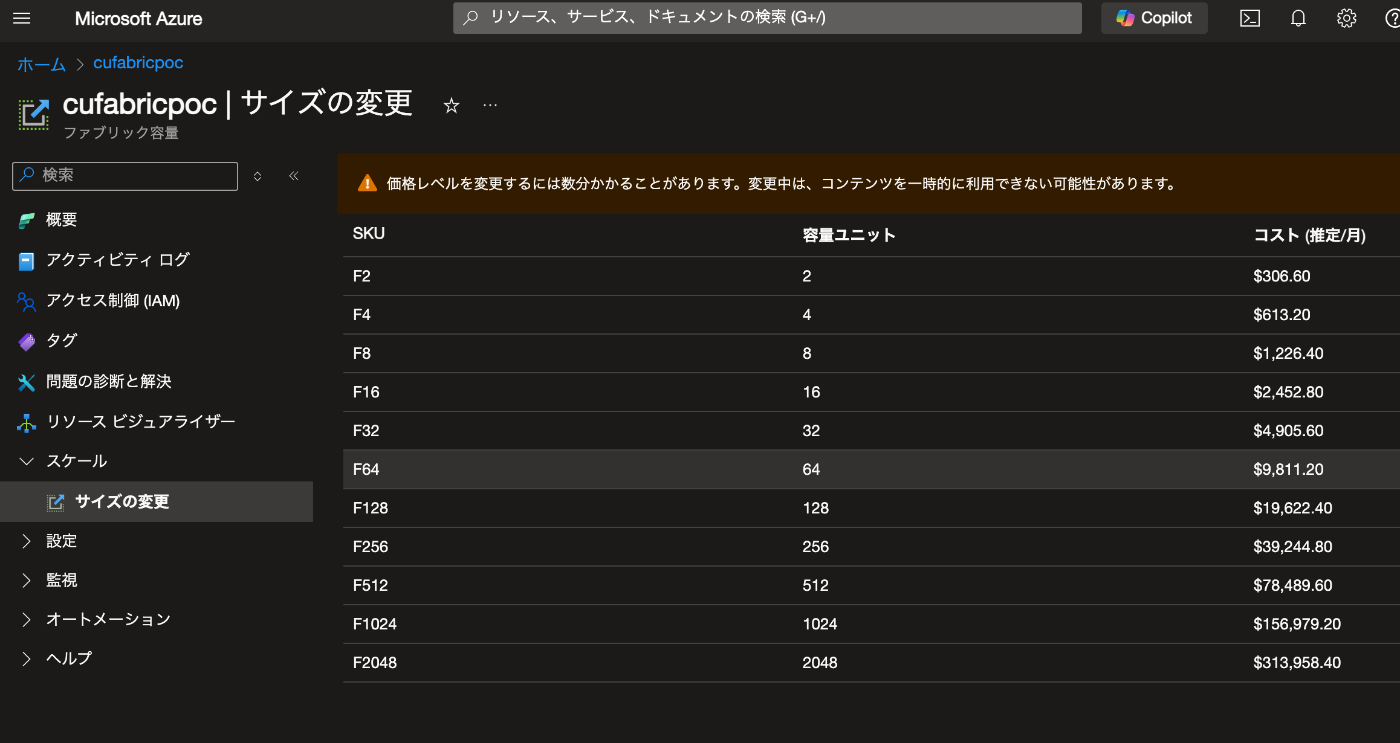
ファブリック容量リソースの使用
今回は Azure の Fabric→ スケール → サイズの変更から F64 を選択
Fabric データ エージェントのテナント設定が有効になっている。
Fabric へアクセスして右上の歯車をクリックし、管理ポータルを選択
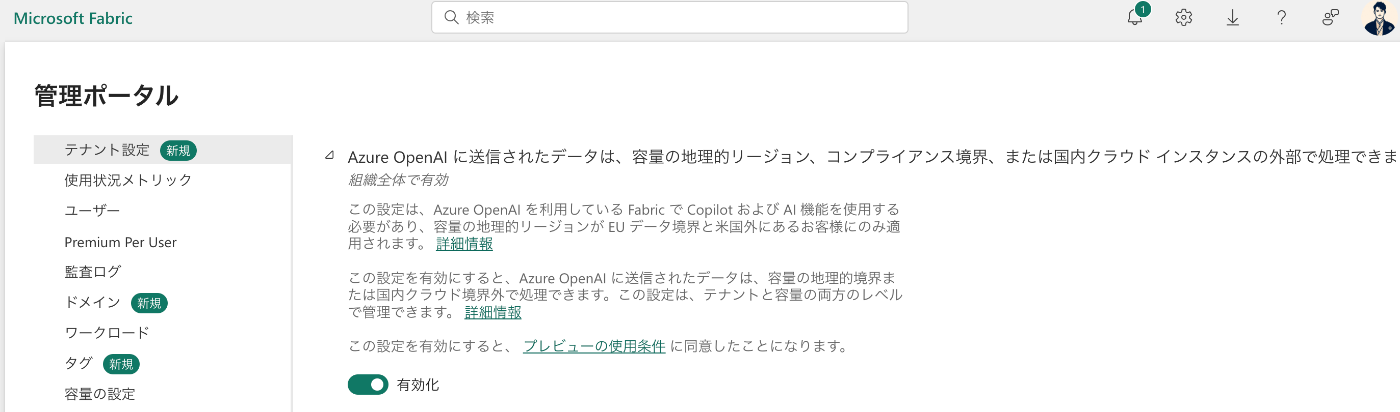
テナントの設定からCopilot と Azure OpenAI Serviceの箇所は全て On に設定する
-
Copilot と Azure OpenAI テナント スイッチを有効にする を On に設定

-
Azure OpenAI に送信されるデータは、容量の地理的領域、コンプライアンス境界、または国内クラウド インスタンスの外部で処理される可能性がある箇所も念の為 On へ設定
以下二つの設定も On へ変更
- 容量は Fabric Copilot 容量として指定できます
- Azure OpenAI に送信されたデータは、容量の地理的リージョン、コンプライアンス境界、または国内クラウド インスタンスの外部に格納できます
Fabric データ エージェントのテナント設定を有効にするの設定を確認します。
[テナント設定] で、[Fabric データ エージェント] セクションを見つけます。
この設定を有効にするには、次のスクリーンショットに示すように、テナント設定 のオプションをオンにします。

XMLA エンドポイントを使用して Power BI セマンティック モデルの統合を有効にします。
Fabric データ エージェントは、XMLA (XML for Analysis) エンドポイントを使用して、Power BI セマンティック モデルのクエリと管理をプログラムで実行できます。 この機能を有効にするには、XMLA エンドポイントを正しく構成する必要があります。
[テナント設定]で、[統合設定] セクションに移動します。
次のスクリーンショットに示すように、[XMLA エンドポイントとオンプレミスのデータセットを使用した "Excel で分析" を許可する] を見つけて有効にします。

Fabric データ エージェントを作成
新しい Fabric データ エージェントを作成するには、まずワークスペースに移動し、[+ 新しい項目] ボタンを選択します。
次に、[すべてのアイテム] タブで、Fabric データ エージェントを選択
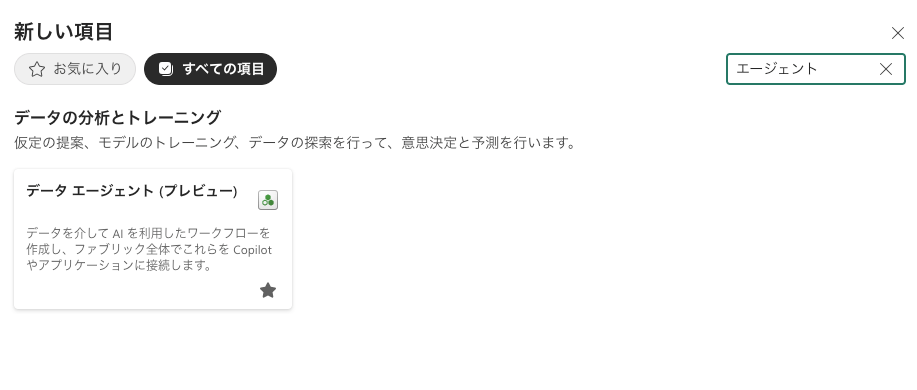
※2025/4/20 段階では、East US, East US2, South Central US, and West US のエリアで利用出来ます。
データエージェントに名前をつけてあげましょう。
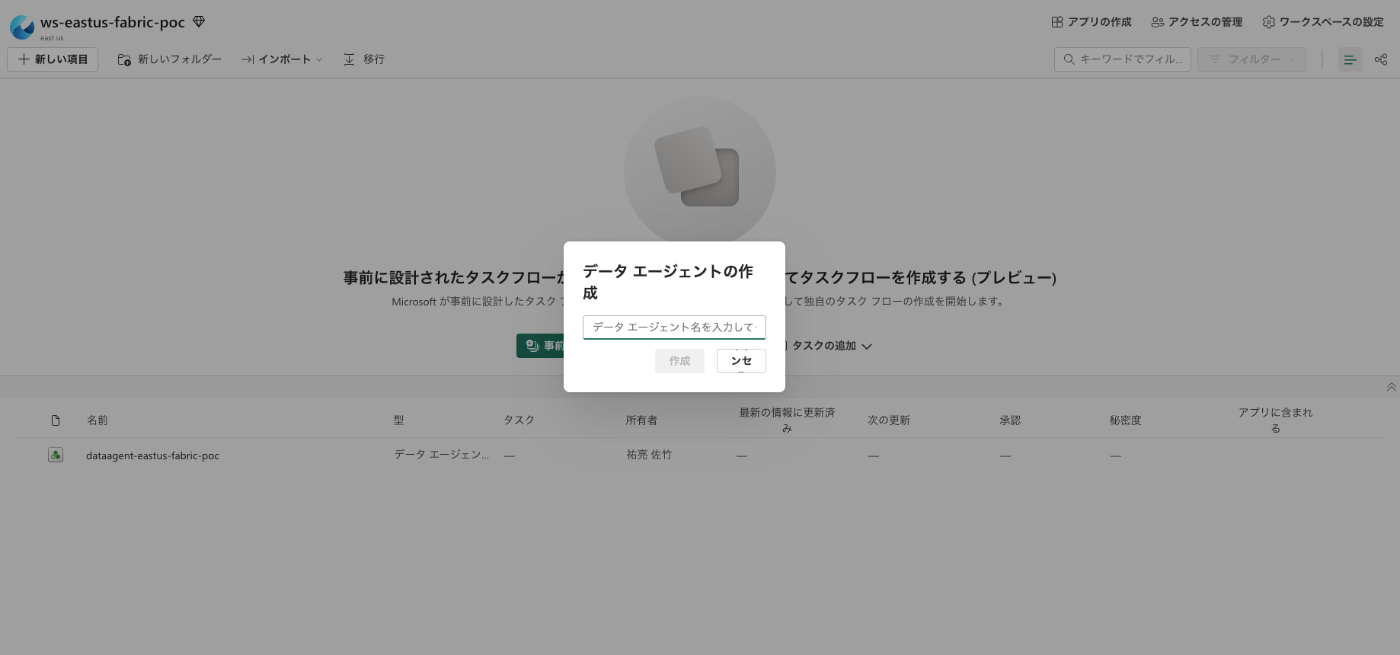
Fabric データエージェントが参照するデータを選択
Fabric データ エージェントを作成した後は、レイクハウス、ウェアハウス、Power BI セマンティック モデル、KQL データベース など、最大 5 つのデータ ソースを任意の組み合わせで追加できます。 たとえば、5 つの Power BI セマンティック モデル、または 2 つの Power BI セマンティック モデル、1 つの lakehouse、1 つの KQL データベースを追加できます。
初めて Fabric データ エージェントを作成する場合は、名前を指定する際に OneLake カタログが自動的に表示され、ここからデータ ソースを追加できます。 データ ソースを追加するには、+データソース をクリックして、追加をクリック。
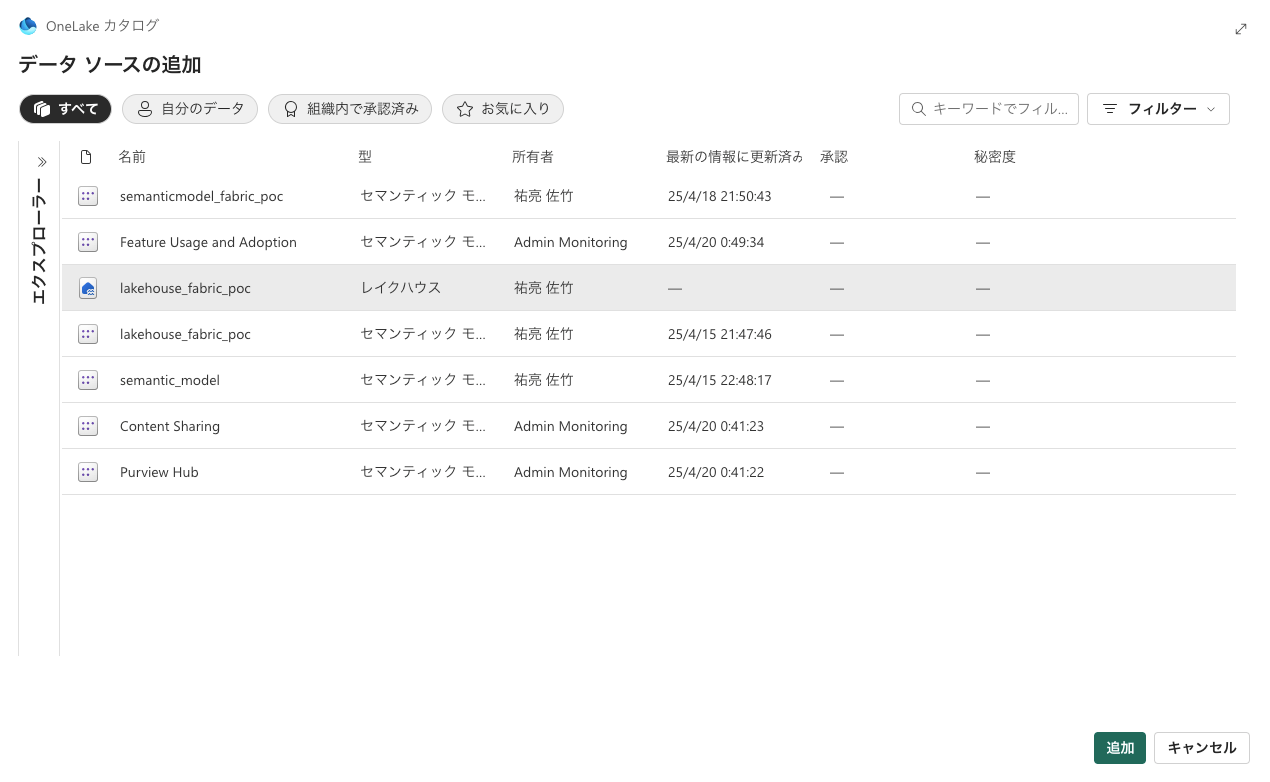
Fabric データエージェントの動作確認と公開
データ ソースを追加すると、Fabric データ エージェント ページの左側のペインにあるエクスプローラーに、使用可能なテーブルが選択したデータ ソースごとに設定されます。
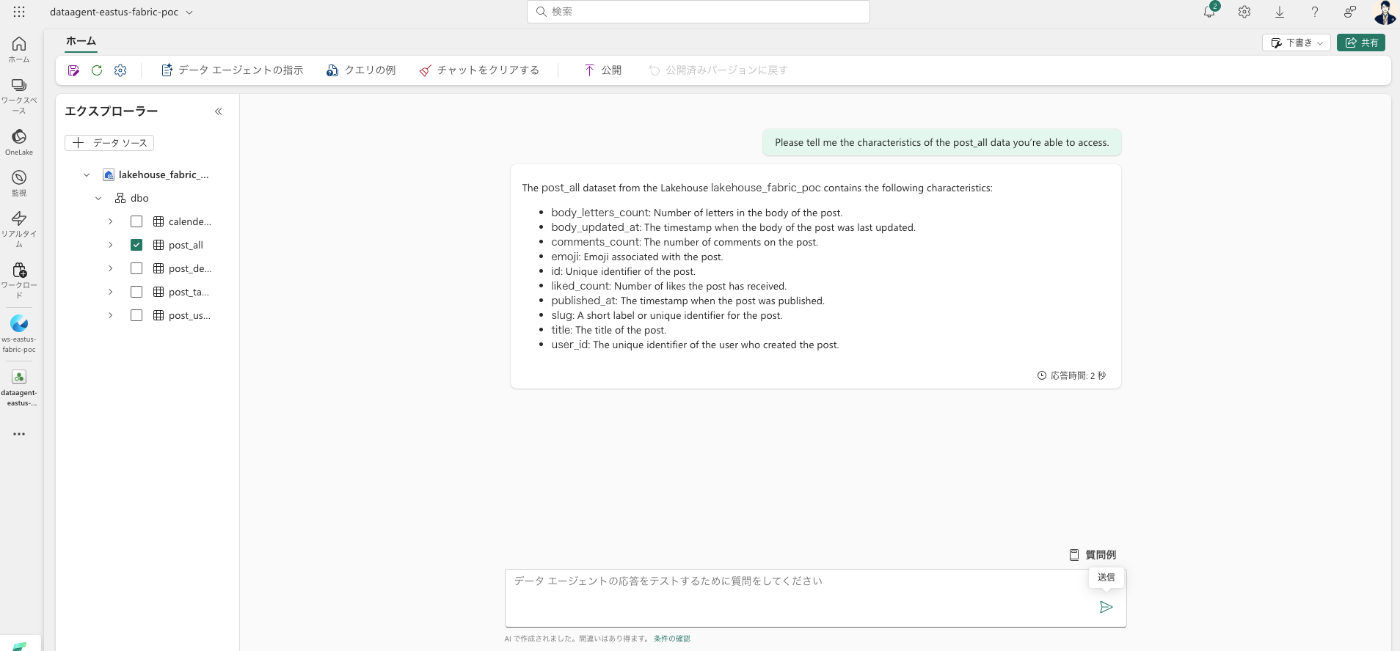
今回選択したのは、私の zenn の記事を Notebook から API で取得し、DataLake に格納しています。
特徴を教えて!と質問すると、こんな感じでエクスプローラーで選択したデータソースを参照して AI が回答を考えてくれます。
では、画面上部の公開ボタンから Data Agent を公開していきます。

こんな感じで公開されます。

Azure AI Agent Service と Microsoft Fabric Data Agent を連携
では、AI Agent Service 側から Microsoft Fabric で公開した Data Agent を AI Agent と連携させましょう。
AI Foundry にアクセスして、エージェントから新しいエージェントを作成
今回は Fabric-Agent と名前をつけました。
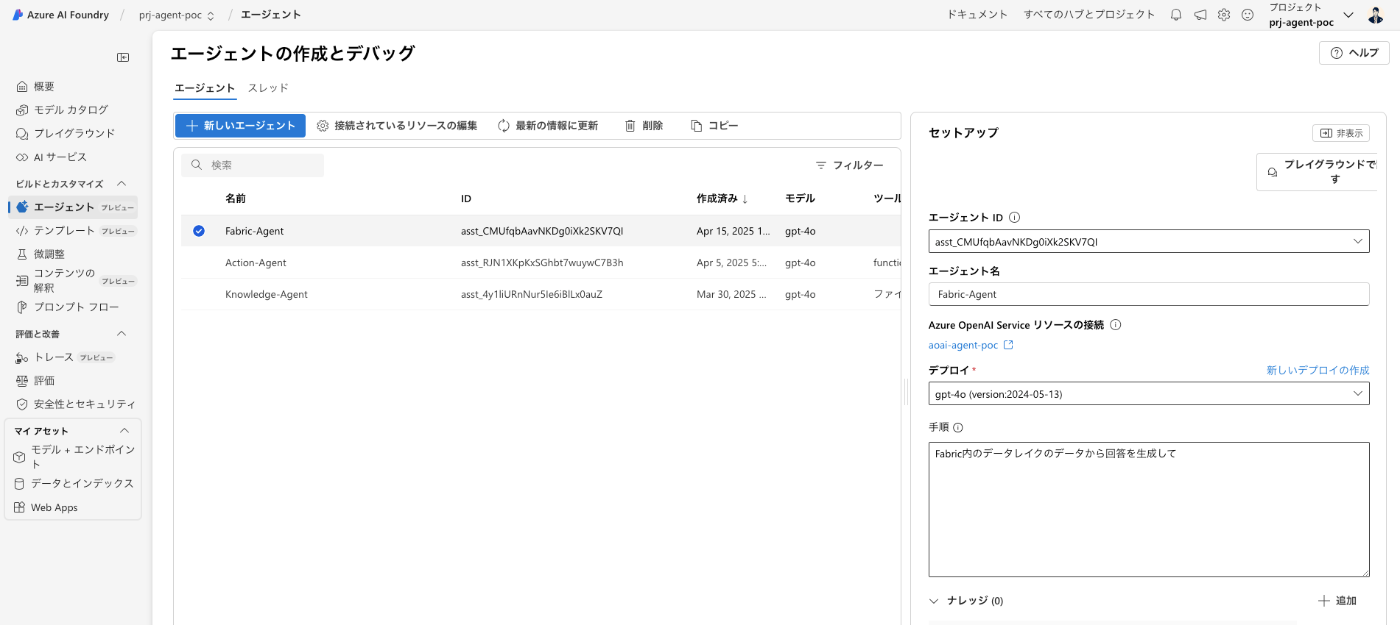
ナレッジを+追加をクリック

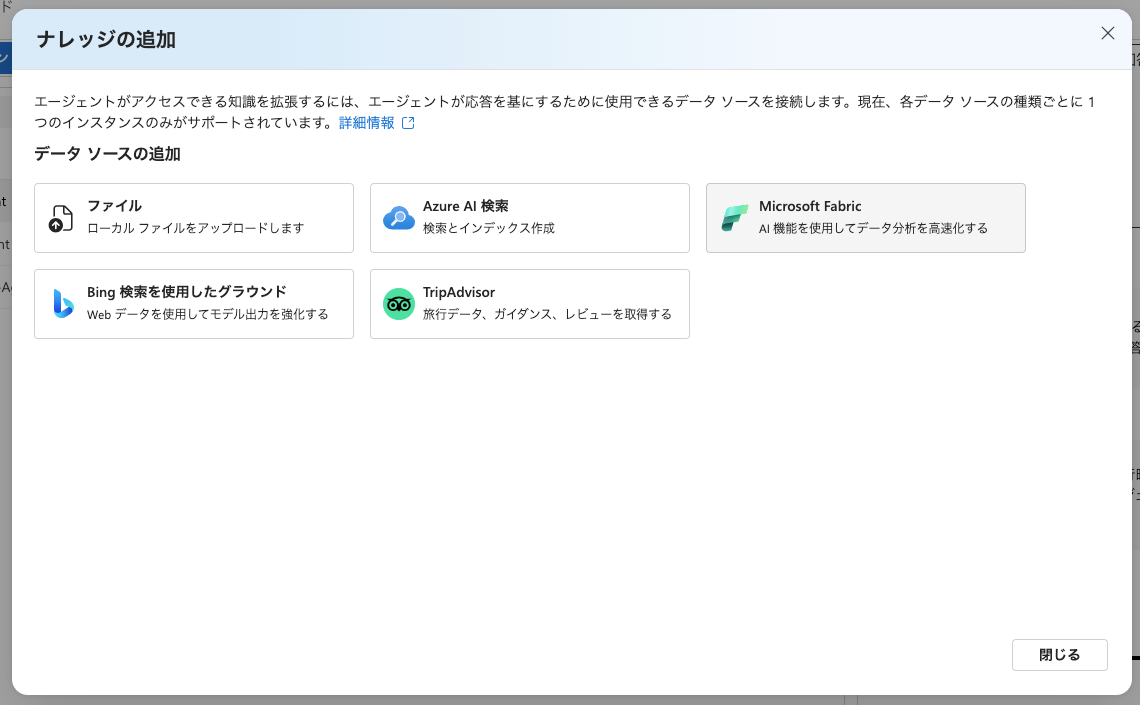
Fabric を選択
作成した Data Agent のコネクタを選択し接続ボタンをクリック
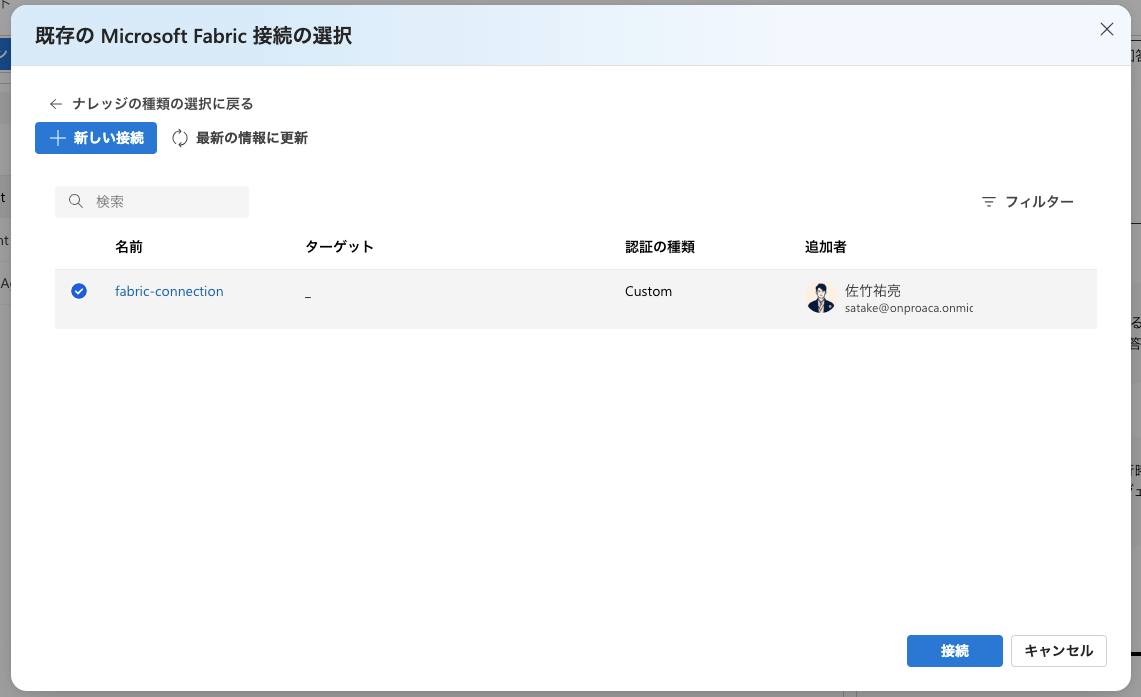
これで Fabric と AI Agent Service の連携が完了です。
おつかれさまでした。
これをコードから呼び出す場合、コードは コードの表示 の箇所に記載してくれています。
import { AIProjectsClient } from "@azure/ai-projects";
import { DefaultAzureCredential } from "@azure/identity";
async function runAgentConversation() {
const client = AIProjectsClient.fromConnectionString(
"eastus2.api.azureml.ms;xxxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx;xxxxxxxxxxx",
new DefaultAzureCredential()
);
const agent = await client.agents.getAgent("asst_xxxxxxxxxxxxxxxxxxxx");
console.log(`Retrieved agent: ${agent.name}`);
const thread = await client.agents.getThread("thread_xxxxxxxxxxxxxxxxxxxxx");
console.log(`Retrieved thread, thread ID: ${thread.id}`);
const message = await client.agents.createMessage(thread.id, {
role: "user",
content: "Hello!"
});
console.log(`Created message, message ID: ${message.id}`);
// Create run
let run = await client.agents.createRun(thread.id, agent.id);
// Poll until the run reaches a terminal status
while (
run.status === "queued" ||
run.status === "in_progress"
) {
// Wait for a second
await new Promise((resolve) => setTimeout(resolve, 1000));
run = await client.agents.getRun(thread.id, run.id);
}
console.log(`Run completed with status: ${run.status}`);
// Retrieve messages
const messages = await client.agents.listMessages(thread.id);
// Display messages
for (const dataPoint of messages.data.reverse()) {
console.log(`${dataPoint.createdAt} - ${dataPoint.role}:`);
for (const contentItem of dataPoint.content) {
if (contentItem.type === "text") {
console.log(contentItem.text.value);
}
}
}
}
// Main execution
runAgentConversation().catch(error => {
console.error("An error occurred:", error);
});
是非ご活用ください。
BigData の分析 × AI Agent でのデータの分析及びアクションが可能となり、データの構造化から AI の利活用までの流れが一気に加速することが期待されます。
これからも Data/AI 分野の発展に期待が高めて本日の記事を終了したいと思います。
最後に
今回の構成で Microsoft Fabric と Azure AI Agent Service を使って、ビッグデータの構造化と AI Agent の連携を実現することが出来ました。
今後も Azure AI Agent Service の SDK がより多くのコネクタに対応するようになりそうなので、引き続き check していきたいと思います。
それでは 👋
スタートアップ企業様向けのお知らせ
日本マイクロソフトでは、スタートアップ企業様向けに、ビジネスを支援するプログラムをご提供しています。
Azure の無料クレジットが最大$150,000もらえるので、是非チェックしてみてください。
参考資料

Discussion