こんにちは。
先日、Azure-Samples 上に infra-support-copilot というレポジトリを公開しました。
今回は、このレポジトリで実装しているツールについて解説をしていきます (2025 / 9 / 26 現在時点の内容です) 。
1. はじめに - 課題
クラウド運用に携わるインフラ エンジニアは、次のような課題を抱えていることがよくあります。
- 構成管理:
- 手元にあるエクセルのインベントリ情報が古くなっていて、対象サーバーを管理している部署がわからない
- 部署ごとの呼称の差分により、インベントリ情報に表記ゆれがあり、完全一致検索だとうまく検索ができないケースがある
- 障害対応
- 監視ログの検索に必要なクエリ作成が難しく、ログ調査に時間がかかる
- 対応しているチケットと類似した過去のインシデント情報をうまく参照できていない
これらは、Azure でも例外ではありません。特に、マルチクラウドに対応した構成管理ツールである Azure Arc を使用して構成を管理している現場では、色んな情報が離散してしまう傾向が強く、上記のような問題が頻出します。
そこで、インフラ業務をサポートするための AI チャット アプリケーション「Infra Support Copilot」を開発しました。
このシステムでは、障害の原因が判明していることを前提として、その後の対応を AI にサポートしてもらえるようなものを目指しています。
2. 全体像

システムの流れは以下のようになります。
- ユーザーの入力から、LLM が以下の 3 つのツールから何を利用するかを決定する (参考: Azure AI Foundry モデルで Azure OpenAI で関数呼び出しを使用する方法)
| ツール名 | ツール概要 |
|---|---|
| SQL クエリ実行ツール | SQL Database 上に格納した Azure Arc に登録されているマルチクラウド環境のリソース情報をクエリする |
| AI Search による検索ツール | 各サーバの管理組織情報や過去の障害情報を検索する |
| Log Analytics クエリ実行ツール | Log Analytics をクエリし、メトリックやログの情報を取得する |
- 検索した結果をもとに LLM が回答を生成する
それぞれのツールについて詳しく解説していきます。
2-1. SQL クエリ実行ツール
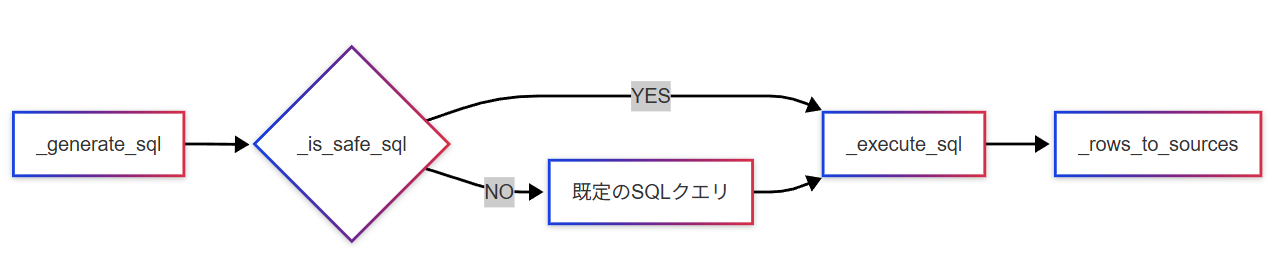 こちらのツールでは、「リソース情報を集約して、全数調査や一覧取得を行う」という機能を提供します。
こちらのツールでは、「リソース情報を集約して、全数調査や一覧取得を行う」という機能を提供します。
Azure Arc とは、「マルチクラウドとオンプレミスで一貫した管理プラットフォームを提供することにより、ガバナンスと管理を簡素化」するためのツールです。(参考: Azure Arc の概要)
今回は、あらかじめこの Azure Arc にオンプレミス・マルチクラウドのリソースを登録してあり、それらのデータを Azure Functions 等で Azure SQL Database に格納した、という状況を想定しています。サンプルコードでは、virtual_machines / network_interfaces / installed_software の 3 つのテーブルが作成されます。
LLM は、どのテーブルがどういう情報をもっているかをすべてコンテキストとして与えられた状態で、ユーザーのニーズに合うクエリを生成します。そのためのプロンプトは以下の通りです。
SQL クエリ生成のためのプロンプト
You are an expert SQL query generator for Azure infrastructure data. Generate a read-only SQL query based on the user's requirements.
User Query: {user_query}
INSTRUCTIONS:
- Analyze the user query to determine the logical order for the required columns in the SELECT clause
- Use LEFT OUTER JOIN to ensure all columns appear in results, even when related data doesn't exist
- Determine appropriate ORDER BY clause based on the user query context
- Use table aliases for readability (vm for virtual_machines, ni for network_interfaces, sw for installed_software)
- Only use SELECT statements - no INSERT, UPDATE, DELETE, DROP, etc.
- Join tables appropriately: vm.resource_id = ni.vm_resource_id for VM-NIC relationship
Available Tables and Schema:\n{self.table_info}
EXAMPLE OUTPUT FORMATS:
SELECT vm.resource_group, vm.name AS resource_name, ni.name AS network_interface_name
FROM dbo.virtual_machines AS vm
LEFT OUTER JOIN dbo.network_interfaces AS ni ON vm.resource_id = ni.vm_resource_id
ORDER BY vm.resource_group, vm.name;
Generate ONLY the SQL query without any explanation or markdown formatting:
💡ポイント
- 勝手にテーブルの編集を行わないようにプロンプトを工夫
- テーブルから情報をできるだけ多く得るため、クエリは OUTER JOIN を行うように指示
サンプル レポジトリは、取得するカラムやテーブルを手動でユーザーが指定するか、AI が自動で決定するかを選ぶことができるようになっています。
LLM によるクエリ文生成が完了したら、そこに UPDATE / DELETE 等の操作がないことを確認し、クエリを実行します。その後、クエリをした結果は見やすさのために Markdown の表形式に整形して返します。
2-2. AI Search による検索ツール
 こちらのツールでは、「各サーバーの管理組織の取得・過去障害情報の検索を行う」という機能を提供します。
こちらのツールでは、「各サーバーの管理組織の取得・過去障害情報の検索を行う」という機能を提供します。
今回は、情報の検索制度を上げるために「各サーバーの管理組織情報」「過去障害情報」で別々のインデックスを作成しています。そのため、まずはユーザーの入力を基にどのインデックスを使って検索するかを LLM を用いて決定します (複数選択可) 。
その後、選択したインデックスを用いて検索を行い、取得したドキュメントの情報を統合して返します。ただし、「各サーバーの管理組織情報」に関しては参照すべきドキュメントが 1 つしかないので 1 ドキュメントのみの検索、「過去障害情報」は input token の長さ制限も考慮して 3 ドキュメントの検索をするように設定をしています。
2-3. Log Analytics クエリ実行ツール
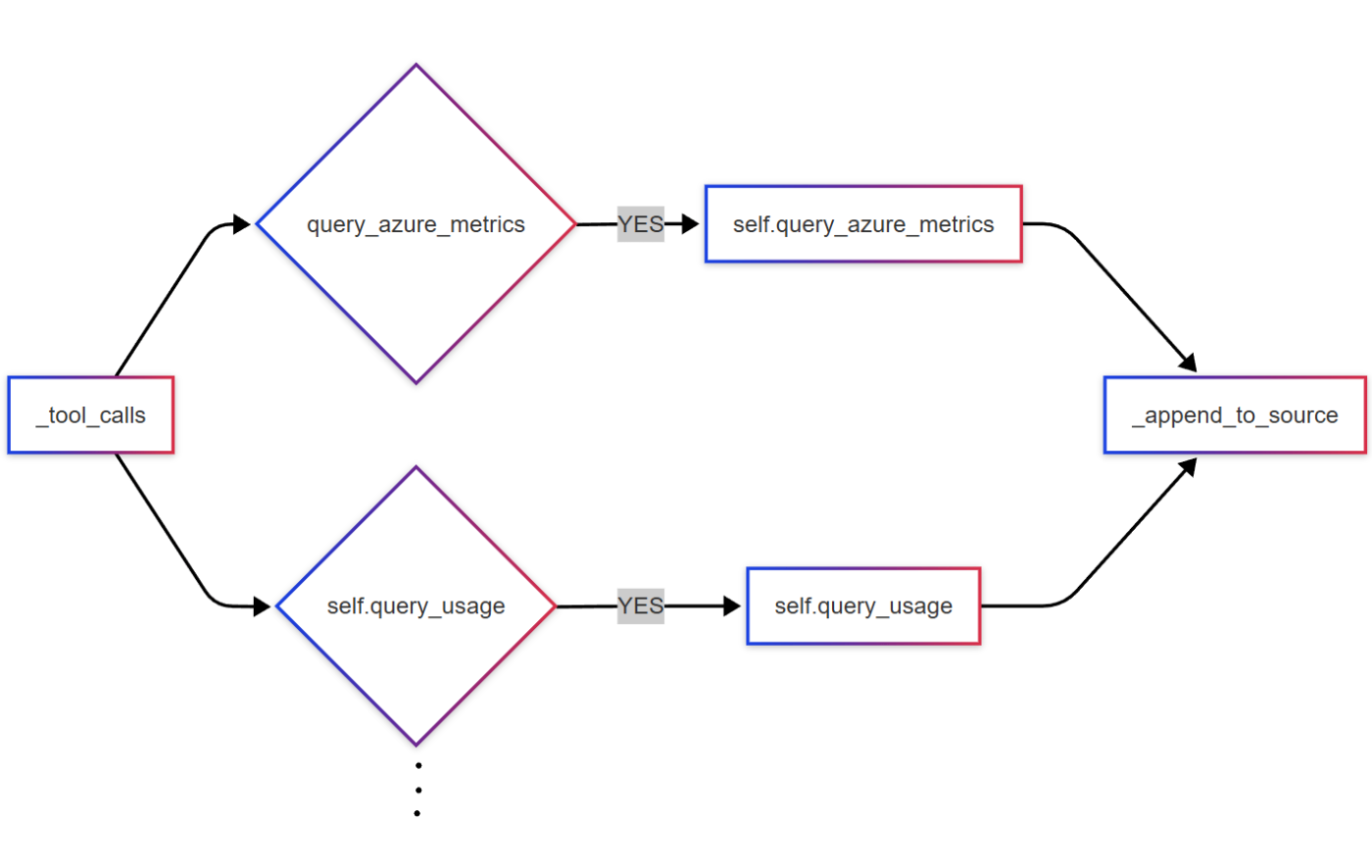 こちらのツールでは、「Log Analytics 上でメトリクスやログのクエリを行う」という機能を提供します。
こちらのツールでは、「Log Analytics 上でメトリクスやログのクエリを行う」という機能を提供します。
まず初めに、LLM を用いてユーザーの入力を基にどのメトリクス / ログに関するクエリを行うかを決定します。その後実際にクエリを行いますが、現在のサンプルではクエリ文はハードコーディングしています。これは、KQL クエリ文の生成を精度よく行うことがうまくできなかったためです。今後は、この部分も動的に LLM による生成ができるとより良いと考えています。
その後、クエリ結果を Markdown 形式に整形した上で返します。ここで、クエリ結果があまりにも長いと input token の長さ制限に引っかかってしまうので、直近 50 行程度のみ返すようにしています。この部分も、過去のより重大な情報を参照できるように実装を工夫をする余地があります。
3. IaC について
サンプルレポジトリでは Windows 環境で azd up の実行を行えば環境が一括で再現できるように整備しています。
3-1. azure.yaml
このファイル内で、provision 前後の操作を指定しています。
preprovision では、SQL Database へのアクセスを許可する IP アドレスをユーザーが今使用している IP アドレスに限定するため、現在の IP アドレスを保存します (スクリプト: scripts/get_ip_adress.ps1)。
続いて、postprovision では scripts/set_up_environment.ps1 を実行します。このスクリプトでは、docs/ 配下のサンプルデータについて以下のような操作を行います。
| プログラム ファイル | 概要 |
|---|---|
scripts/upload_data_to_blob_storage.py |
Blob Storage にドキュメントをアップロードする |
scripts/create_index.py |
Azure AI Search で Blob Storage にアップロードしたドキュメントに対する index を作成する |
scripts/upload_arc_data_to_azure_sql.py |
SQL Database に Azure Arc を模したサンプルデータをアップロードする |
scripts/ensure_db_user.py |
Entra ID 認証を利用した Azure SQL Database user を作成する |
3-2. main.bicep
こちらでは使用するリソースを定義しています。今回は詳細な内容の説明は割愛し、デモとしてデプロイをする場合に主にカスタマイズできる部分についていくつか紹介します。
| 該当箇所 | 説明 |
|---|---|
| App Service Plan の SKU | デフォルトでは SKU は P1v3 になっていますが、ニーズに応じて書き換えてください (参考: Azure App Service プランとは) |
| OpenAI のモデル | デフォルトでは GPT-4.1 を使用していますが、好きなモデルに変更可能です。 |
4. 今後の機能拡張について
今後は、
- Microsoft Entra ID による認証機能の追加
- Azure Arc 経由で VM にカスタムスクリプト拡張機能を導入し、VM の内部の状態を確認する
などの機能の実装を検討しています。
5. まとめ
今回は、インフラ障害時の手助けになるようなチャットシステム infra-support-copilot の提案と解説を行いました。
現時点で実装している機能には以下のものがあります。
- Azure AI Search によるドキュメント検索
- Azure SQL Database のクエリ
- Log Analytics のクエリ
将来は Copilot in Azure や SRE Agent が担うような機能だと思いますが、どういう機能が実現できそうか考える場にできればと思っています。
読んでいただいてありがとうございました 📚

Discussion