はじめに
Microsoft Ignite 2023 で発表された Azure OpenAI Service の GPT-4 Turbo with Vision のプレビューが開始しましたので、使い方などの情報をまとめました。
- What's new in Azure OpenAI Service
- GPT-4 Turbo with Vision on Azure OpenAI Service
- What's New in Generative AI? (Session code: BRK202H)
- Multimodal Conversational Interfaces with GPT and Vision AI (Session code: BRK205)
GPT-4 Turbo with Vision
GPT-4 Turbo と GPT-4 Turbo with Vision
OpenAI DevDay にて GPT-4 の改良版である GPT-4 Turbo が発表されました。GPT-4 Turbo は主に以下の点で改良されています。
- 最大トークンの拡張 (入力: 128,000 トークン、出力: 4,096 トークン)
- 値下げ
- プロンプトへの従いやすさの向上
- マルチモーダル入力対応
GPT-4 Turbo には、入力できるデータの種類が異なる 2 つのモデルが存在します。
| 通称 | 本家 OpenAI における名称 (モデル名) | Azure OpenAI Service における名称 (モデル名 (バージョン)) | 入力 | 出力 |
|---|---|---|---|---|
| GPT-4 Turbo | gpt-4-1106-preview | gpt-4 (1106-preview) | テキスト | テキスト |
| GPT-4 Turbo with Vision | gpt-4-vision-preview | gpt-4 (vision-preview) | テキスト + 画像 | テキスト |
Microsoft Ignite 2023 にて、これらのモデルが近いうちに Azure OpenAI Service でも利用可能になることが発表されていましたが、このたびマルチモーダル入力対応の GPT-4 Turbo with Vision のプレビューが開始しました。(テキスト入力のみを受け付ける無印 GPT-4 Turbo は一足先にプレビュー開始していました。)
参考
- New models and developer products announced at DevDay (本家 OpenAI)
- Azure OpenAI Service Launches GPT-4 Turbo and GPT-3.5-Turbo-1106 Models
- GPT-4 および GPT-4 Turbo プレビュー モデル
利用可能なリージョン
執筆時点で GPT-4 Turbo with Vision は以下のリージョンで利用可能です。
Australia East (オーストラリア東部)Sweden Central (スウェーデン中部)Switzerland North (スイス北部)West US (米国西部)
参考
クォータ
執筆時点で GPT-4 Turbo with Vision のクォータは 10 K TPM (Token per Minute) に設定されています。
参考
価格
執筆時点で GPT-4 Turbo と GPT-4 Turbo with Vision は入力: $0.01 / 1K トークン、出力: $0.03 / 1K トークン の価格設定がされています。これは GPT-4 と比較したときに入力で 1/3、出力で 1/2 の価格です。
GPT-4 Turbo with Vision に関しては執筆時点で個別に言及された記述を見つけられていませんが、おそらく同じか近い価格ではないかと推測されます。

※米国西部リージョン
参考
画像入力
高解像度モードと低解像度モード
GPT-4 Turbo with Vision では detail パラメーターを設定することにより、入力画像を高解像度で扱うか低解像度で扱うかを明示的に指定することができます。
low
- 高解像度モードがオフ。
- 入力画像を固定サイズとして扱う。
- 固定で 85 トークンが消費される。
high
- 高解像度モードがオン。
- まず、入力画像は縦横比を維持したまま 2,048 × 2,048 ピクセルの正方形に収まるように拡大縮小される。次に、短い辺の長さが 768 ピクセルになるように縮小される。最後に、画像は 512 ピクセルの正方形のタイルに分割され、このタイルの数(部分的なタイルは切り上げ)によって最終的なコストが決まる。
- ベースの 85 トークンに加えて、タイル数 x 170 トークンが消費される。
auto
- デフォルト値。
-
highを使うかlowを使うか自動判別される。
高解像度モードのトークン計算例
例えば 2,048 x 4,096 ピクセルの画像入力を行う場合。
- 1,024 × 2,048 ピクセルにリサイズされる。(2,048 ピクセルの正方形に収まるように拡大縮小される。)
- 768 x 1,536 ピクセルに縮小される。(短い辺の長さが 768 ピクセルになるように縮小される。)
- 全体をカバーするには 512 ピクセルのタイルが 6 枚必要。(512 ピクセルの正方形のタイルに分割する。)
- 合計コストは
170 × 6 + 85 = 1,105トークン。
イメージ図

リクエスト
REST API で高解像度モードを設定する例
{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": [
"Describe this picture:", { "image": "URL or base-64-encoded image", "detail": "high" }
]
}
],
"max_tokens": 100,
"stream": false
}
Python SDK で高解像度モードを設定する例
response = client.chat.completions.create(
model="gpt-4-vision", # model = "deployment_name".
messages=[
{
"role": "system", "content": "You are a helpful assistant."
},
{
"role": "user",
"content": [
"Describe this picture:",
{ "image": "URL or base-64-encoded image", "detail": "high" }
]
}
]
)
参考
- 画像処理の詳細パラメーター設定: low、high、auto
- Low or high fidelity image understanding (本家 OpenAI)
- REST API Reference - Chat completions
- 画像トークン (GPT-4 Turbo with Vision)
制約
GPT-4 Turbo with Vision では以下のような制約が存在します。Azure OpenAI Service の独自機能である Vision Enhancement (Vision 拡張) に関しては後述します。
画像入力
- 入力画像の最大サイズは 4 MB。
- サポートされる画像ファイルの形式は PNG (.png)、JPEG (.jpeg and .jpg)、WEBP (.webp)、 アニメーションなしの GIF (.gif)。
- 1 回のコールでアップロードできる画像は最大 10 枚まで。
- 低解像度モードで画像を解析すると、高速なレスポンスを行うことができるが、画像内の物体やテキスト認識の精度に影響を与える可能性がある。
- 1 回のチャットセッションで複数の画像に Vision Enhancement 機能を適用することはできない。
- Vision Enhancement 機能により物体の重複が検出された場合、重複ごとに個別のバウンディングボックスとラベルを生成するのではなく、すべての重複に対して 1 つのバウンディングボックスとラベルを生成する。
動画入力
- フレームは低解像度モードで解析が行われます。そのため、ビデオ中の小さな物体やテキストの認識精度に影響を与える可能性がある。
- サポートされる動画ファイルの形式は MP4 か MOV のいずれか。
- Azure OpenAI Studio から利用する場合は動画は 3 分以内でなければならない。API から利用する場合はこのような制約はない。
- 1 回のコールに含めることのできる動画は 1 つ。
- 解析時には動画全体から 20 フレームが選択されます。そのため、重要な瞬間や詳細をとらえることができない可能性がある。フレーム選択はプロンプトに応じて動画を通してほぼ均等に、もしくは特定の動画検索クエリによって焦点を当てることができる。
- トランスクリプトは第一言語として英語をサポートしている。曲中の歌詞に関する正確な情報を提供しない。
参考
ファインチューニング
執筆時点で GPT-4 Turbo with Vision はファインチューニングに対応していません。
参考
使い方
1. リソース作成
1.1. Azure OpenAI Service
GPT-4 Turbo with Vision が利用可能な任意のリージョンを選択して Azure OpenAI Service のリソースを作成します。なお、Azure OpenAI Service を使うためには利用申請が承認されている必要があります。
Australia EastSweden CentralSwitzerland NorthWest US
参考
1.2. Azure AI Vision
後述する Vision Enhancement 機能を使う場合、Azure AI Vision (Azure Portal 上の表記は Computer Vision) のリソースを別途作成する必要があります。その際、Azure OpenAI Service リソースと同じリージョンにリソースを作成する必要があります。価格レベル (Pricing tier) は Standard S1 を選択します。

参考
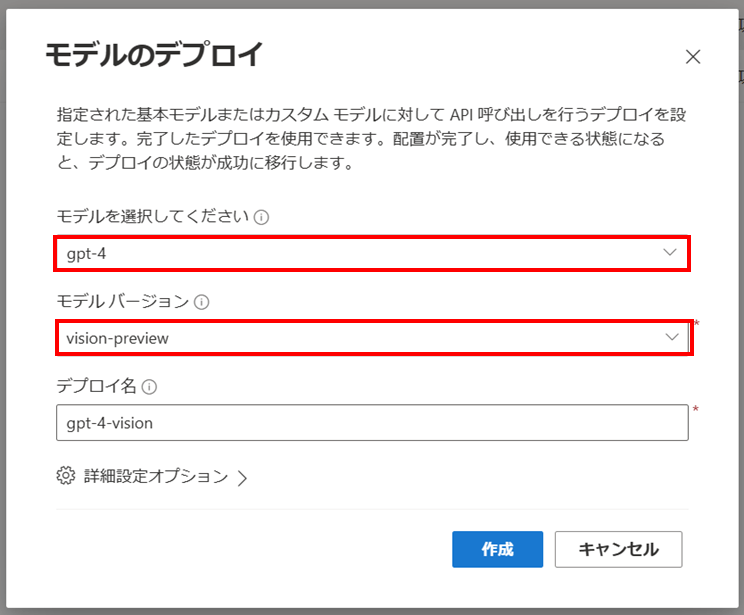
2. モデルデプロイ
ベースモデル gpt-4、モデルバージョン vision-preview を選択して GPT-4 Turbo with Vision のデプロイを行います。
参考
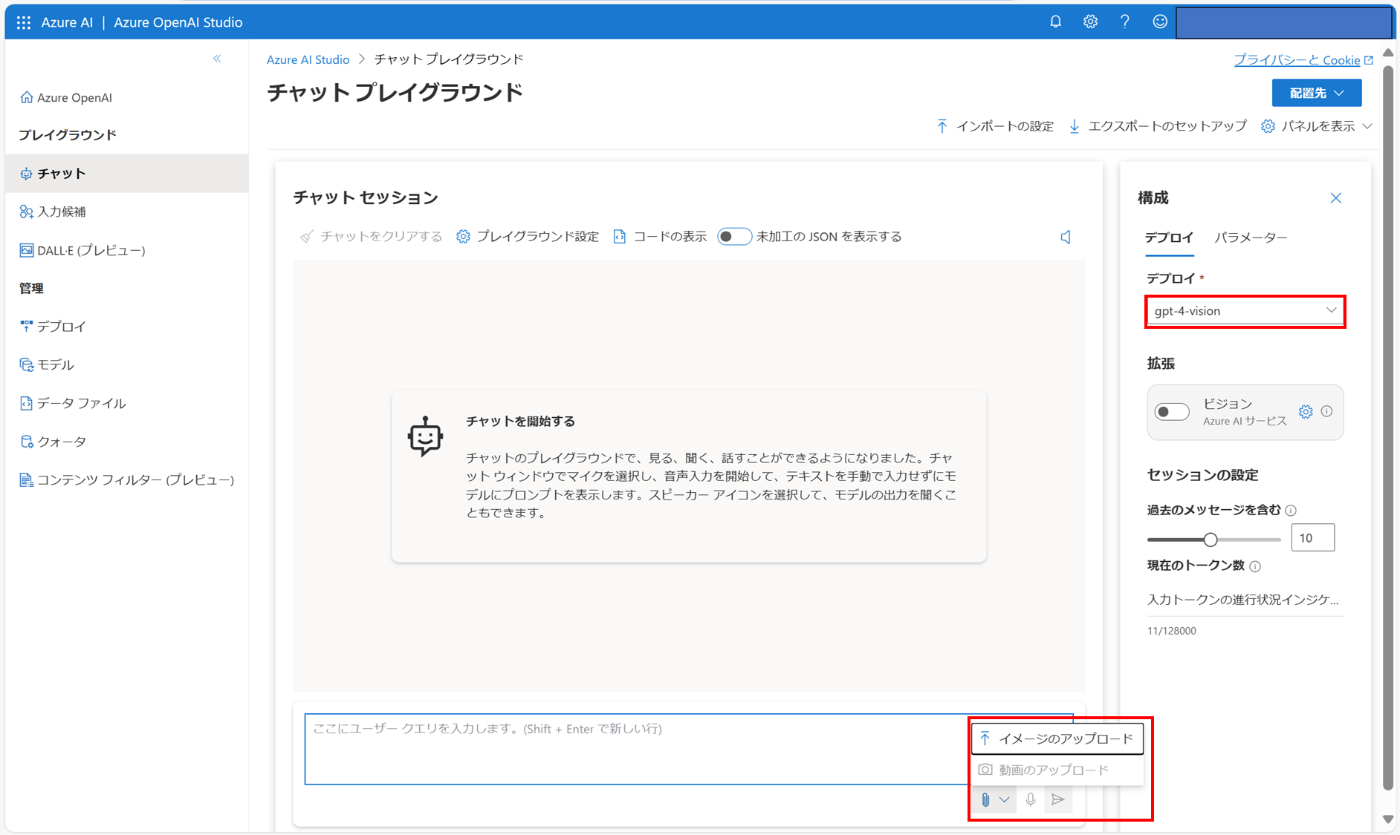
3. リクエスト
Azure OpenAI Studio のプレイグラウンドで事前にデプロイしたモデルを選択すると画像をアップロードできるようになります。
REST API からリクエストを行う場合は以下のサンプルのようにして画像の URL か Base64 エンコードをした画像を渡します。
{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": [
"Describe this picture:", { "image": "URL or base-64-encoded image" }
]
}
],
"max_tokens": 100,
"stream": false
}
参考
4. Vision Enhancement
Azrue OpenAI Service の GPT-4 Turbo with Vision には Vision Enhancement (Vision 拡張) という機能が存在します。この機能を使うと GPT-4 Turbo with Vision の素のレスポンスにさらに情報を付加したり、動画を入力データとして受け付けることができるようになります。
なお、この機能は本家 OpenAI には存在しない Azure OpenAI Service の独自機能で、別途 Azure AI Vision リソース作成して割り当てる必要があります。
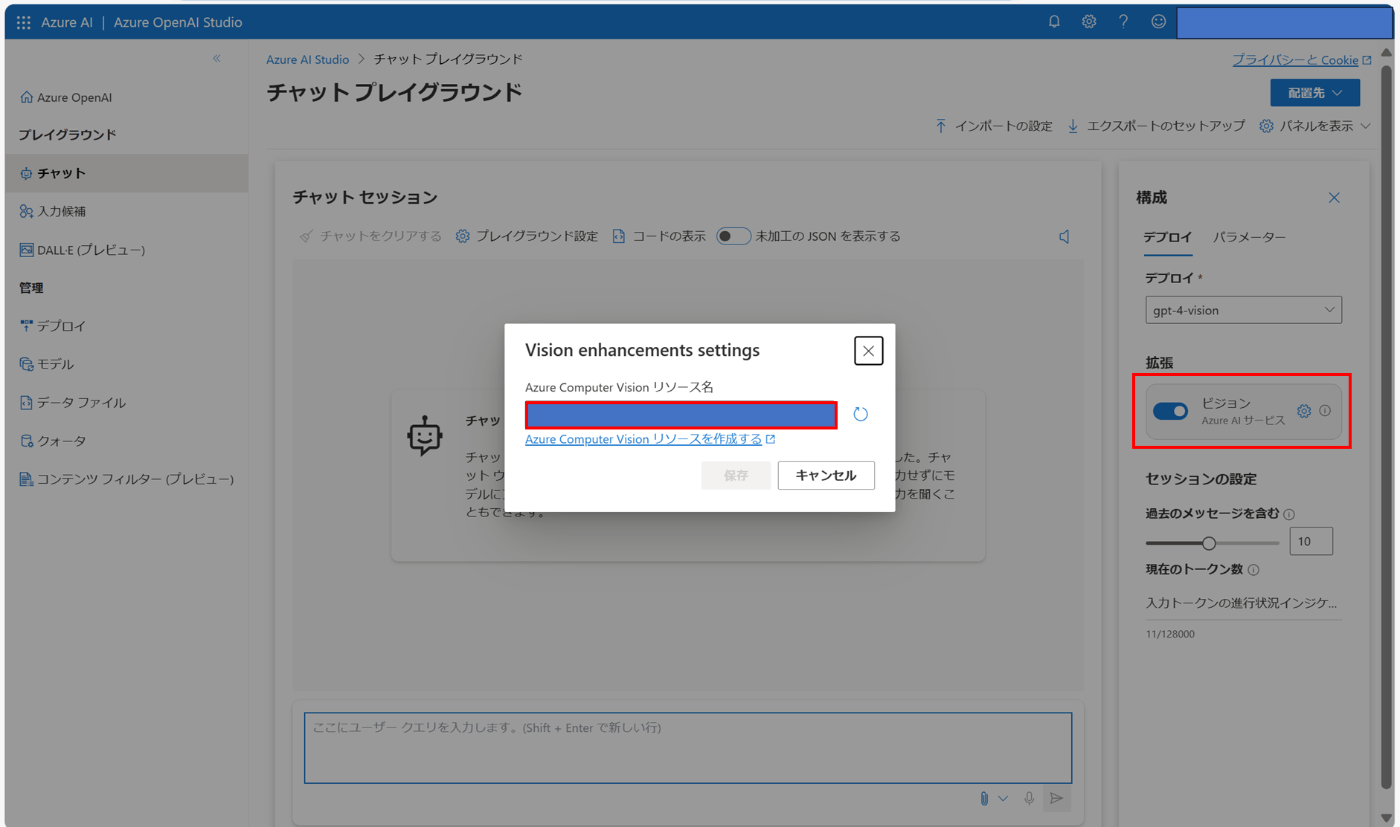
4.1. 有効化
Azure OpenAI Studio の場合は拡張 (Enhancements) のトグルをオンにして、事前に作成した Computer Vision のリソースを指定します。
4.2. 画像入力
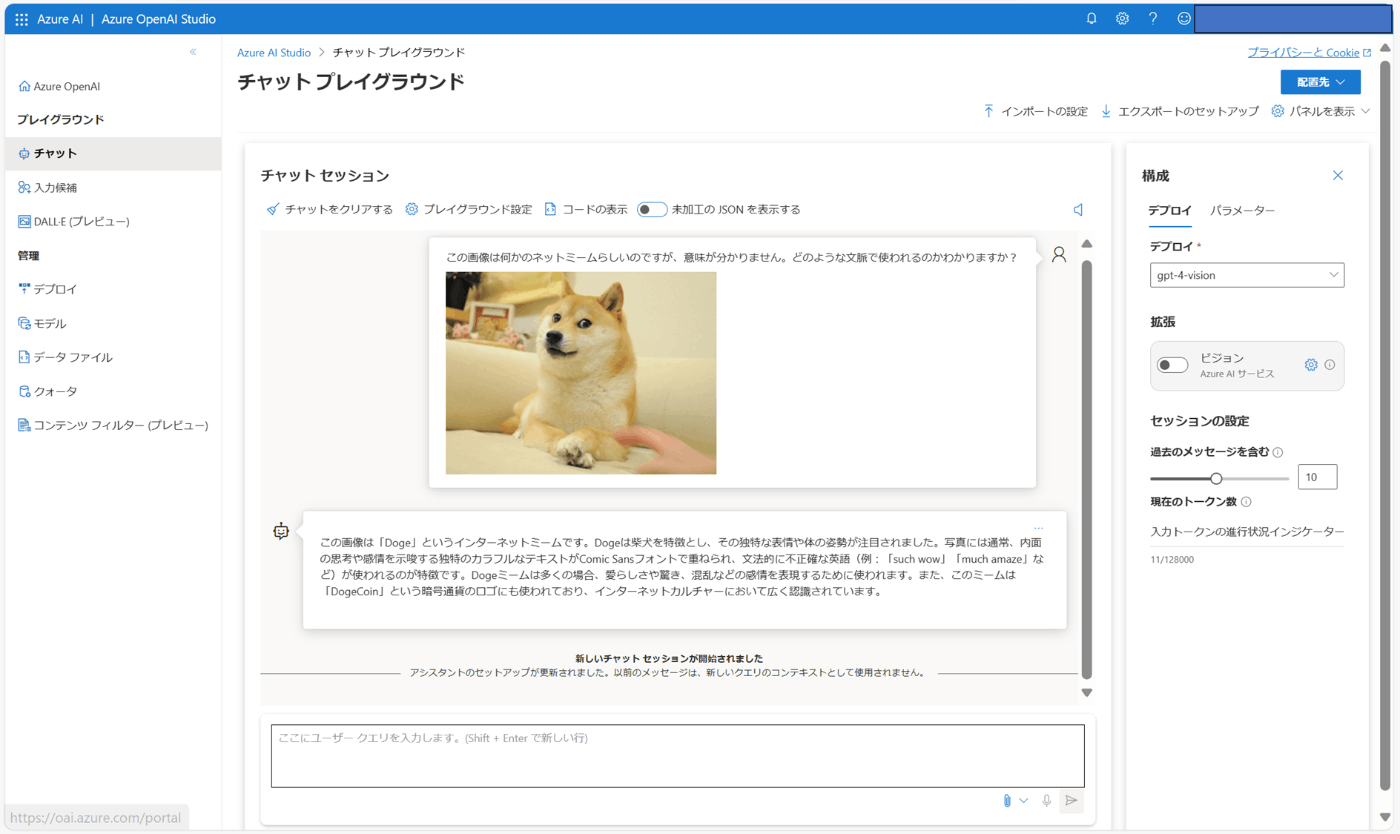
画像と "Describe this image. (この画像を説明して。)" というプロンプトを入力すると、Azure AI Vision による物体検出が行われた結果の情報が付加されます。なぜか日本語のプロンプトでうまくいかなかったため、以下の例では英語のプロンプトを与えています。
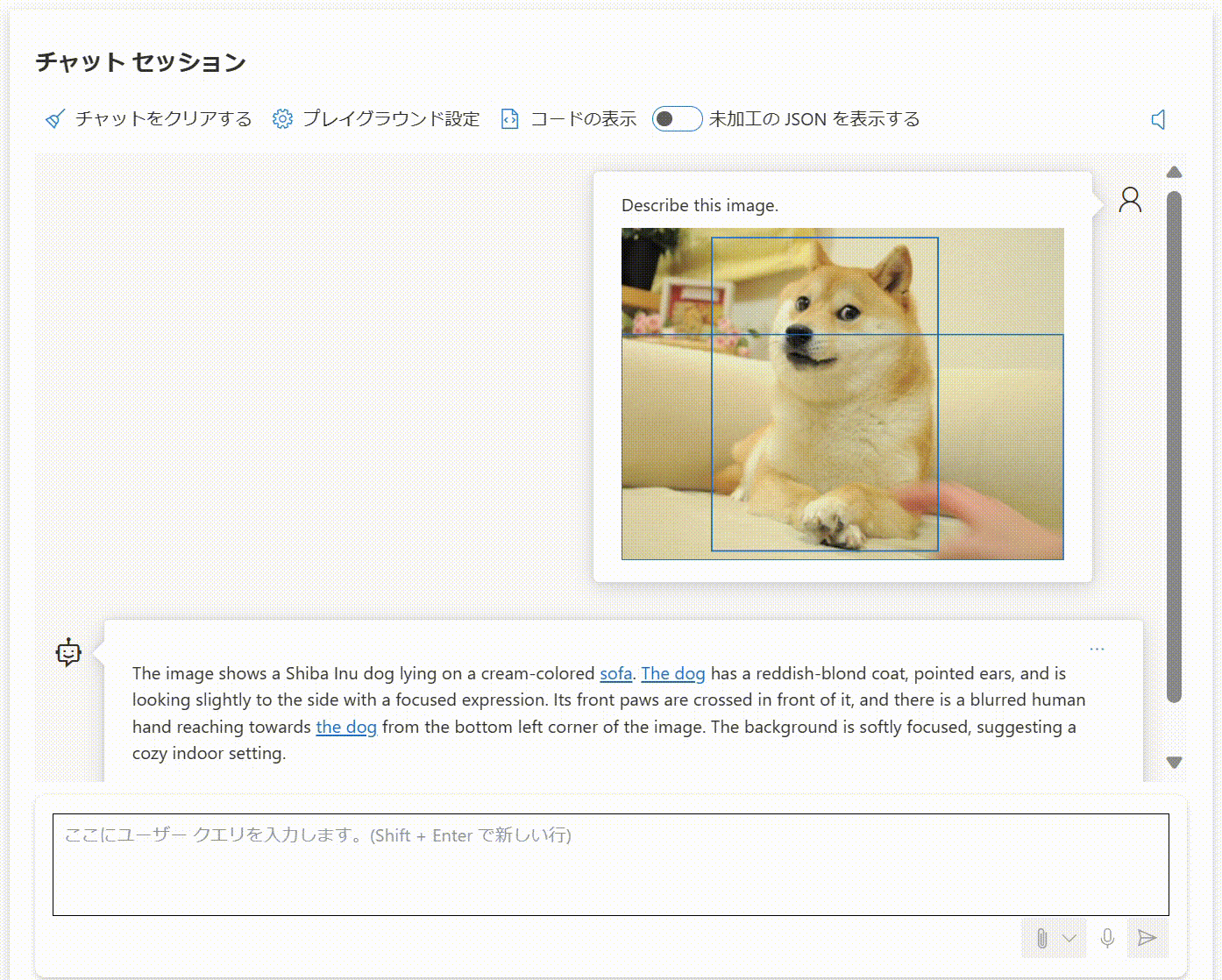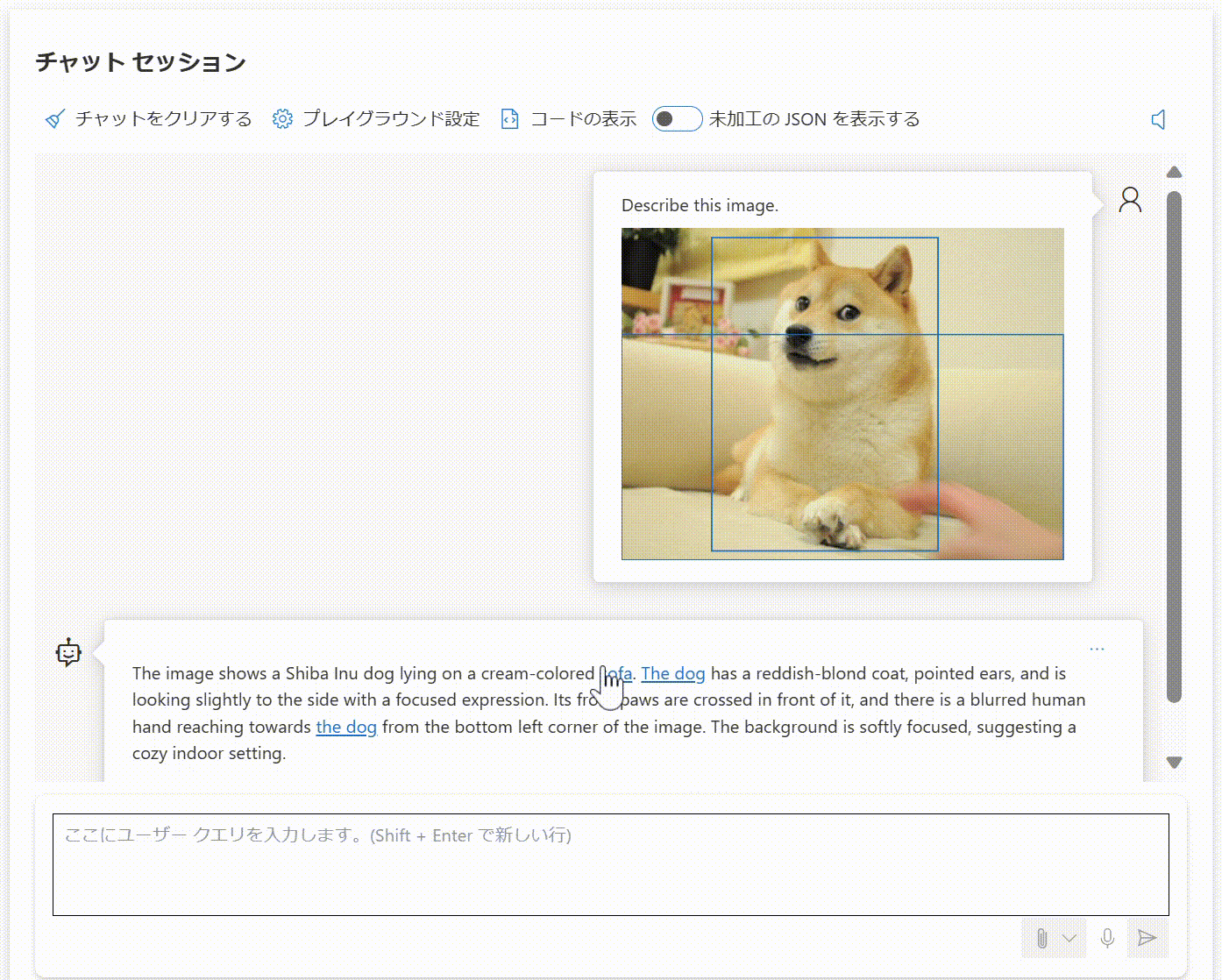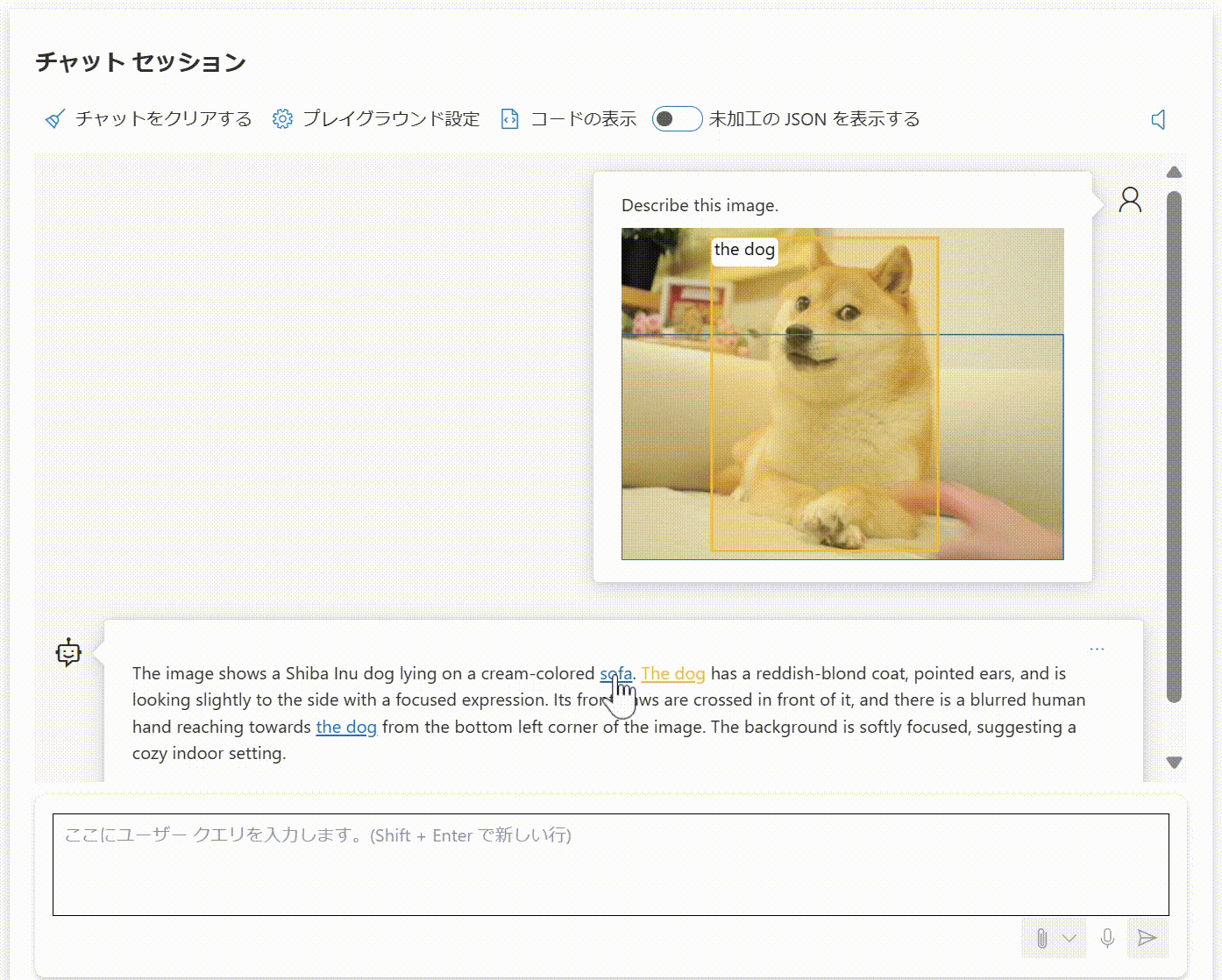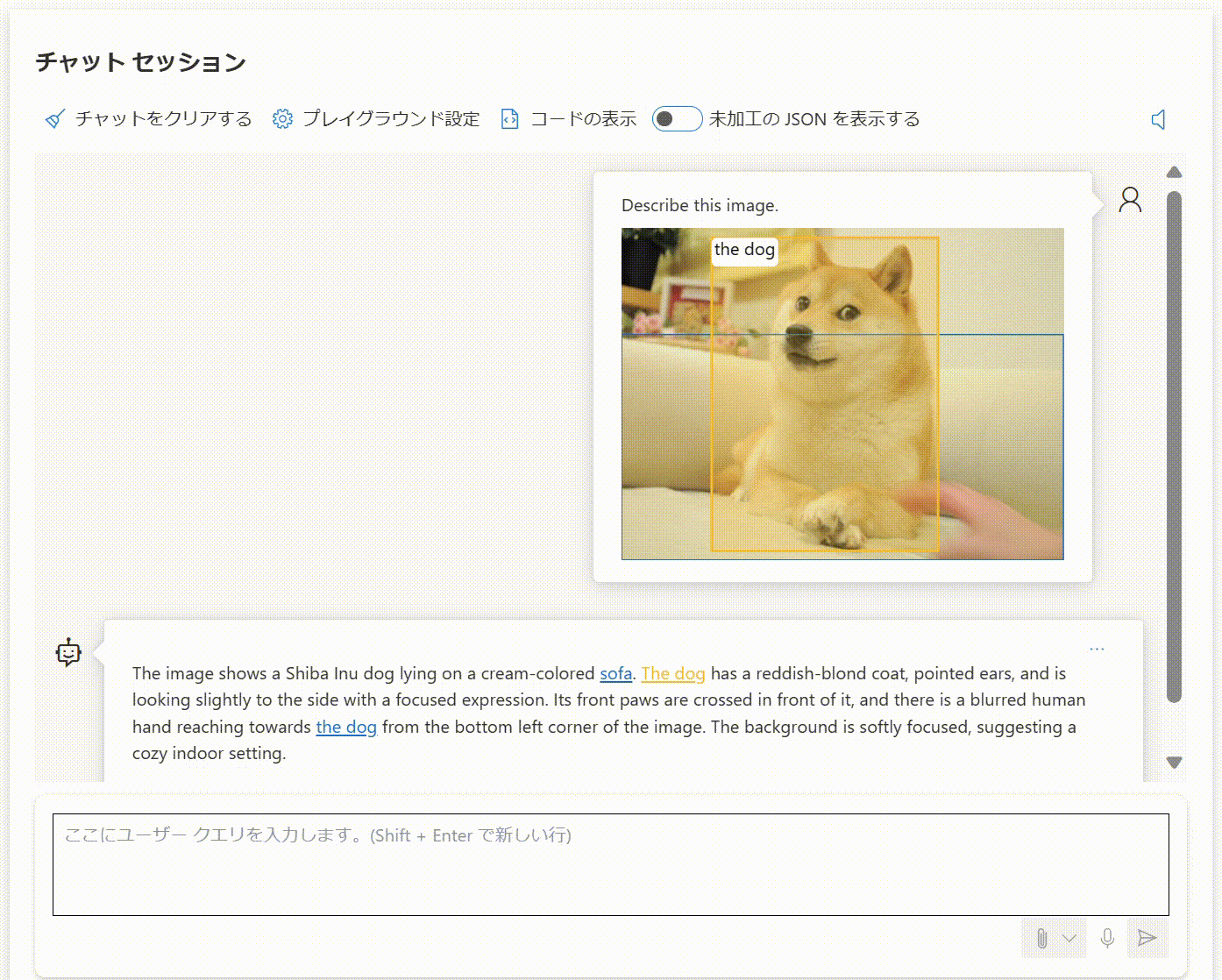
The image shows a Shiba Inu dog lying on a cream-colored sofa. The dog has a reddish-blond coat, pointed ears, and is looking slightly to the side with a focused expression. Its front paws are crossed in front of it, and there is a blurred human hand reaching towards the dog from the bottom left corner of the image. The background is softly focused, suggesting a cozy indoor setting.
(画像はクリーム色のソファに横たわる柴犬。犬は赤みがかったブロンドの被毛を持ち、尖った耳を持ち、集中した表情で少し横を向いている。前足は前で交差しており、画像の左下から犬に向かってぼやけた人間の手が伸びている。背景はソフトフォーカスで、居心地の良い室内を暗示している。)
REST API からリクエストを行う場合は以下のようにして dataSources パラーメーターで Azure AI Vision の情報を設定します。
{
"enhancements": {
"ocr": {
"enabled": true
},
"grounding": {
"enabled": true
}
},
"dataSources": [
{
"type": "AzureComputerVision",
"parameters": {
"endpoint": "<your_computer_vision_endpoint>",
"key": "<your_computer_vision_key>"
}
}],
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": [
"Describe this picture:", { "image": "URL or base-64-encoded image" }
]
}
],
"max_tokens": 100,
"stream": false
}
参考
4.3. 動画入力
動画と「この動画を説明して。」というプロンプトを入力すると、Azure AI Vision によるフレームの取得と場面の分析が行われた結果の情報が付加されます。こちらは日本語のプロンプトでもうまくいきました。以下の例では、このブレークアウトセッションの冒頭約 1 分間を入力データとして与えています。
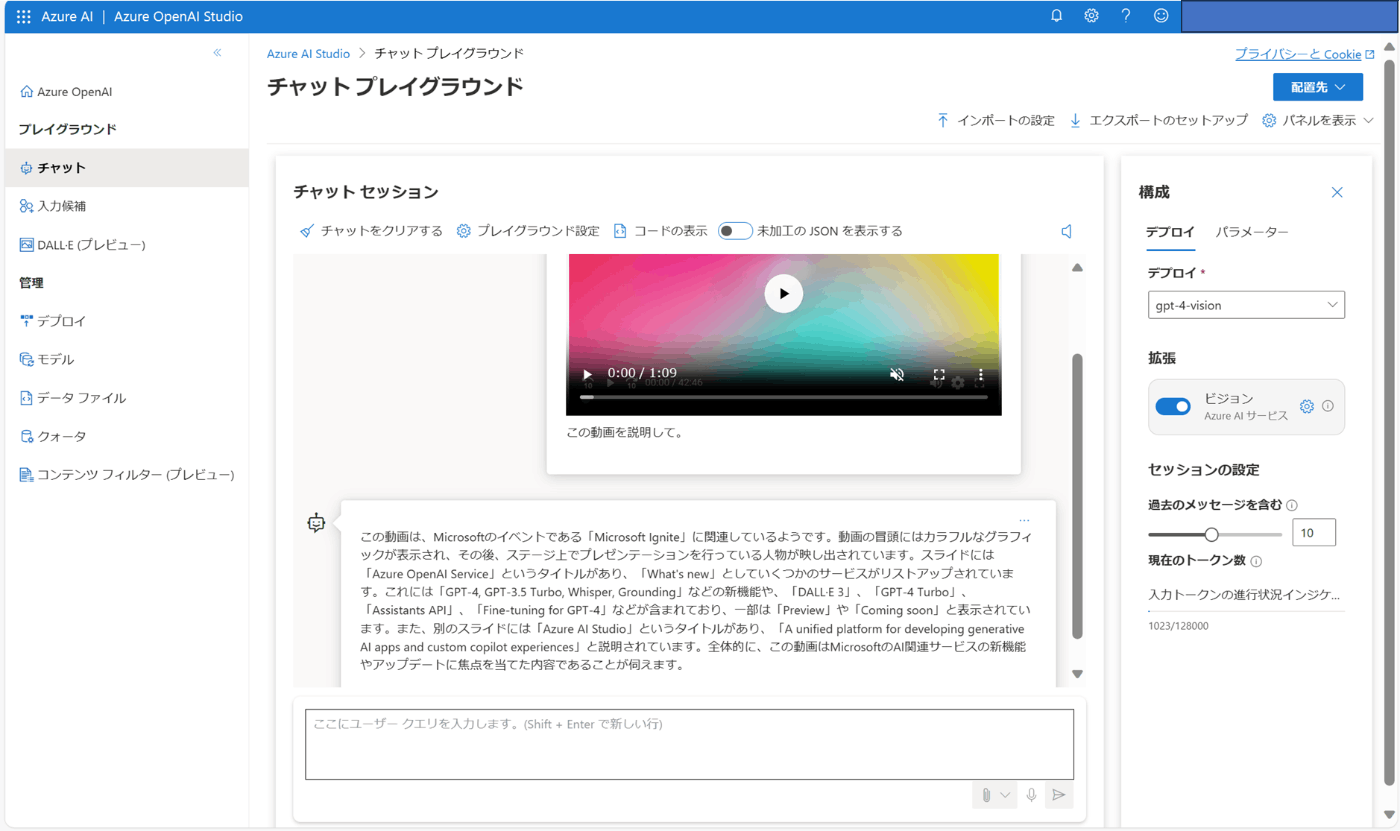
REST API からリクエストを行う場合は以下のようにして dataSources パラーメーターで Azure AI Vision の情報を設定します。動画ファイルは Blob Storage にアップロードして SAS URL で指定します。
{
"enhancements": {
"video": {
"enabled": true
}
},
"dataSources": [
{
"type": "AzureComputerVisionVideoIndex",
"parameters": {
"endpoint": "<your_computer_vision_endpoint>",
"key": "<your_computer_vision_key>",
"computerVisionBaseUrl": "<your_computer_vision_endpoint>",
"computerVisionApiKey": "<your_computer_vision_key>",
"indexName": "<name_of_your_index>",
"videoUrls": ["<your_video_SAS_URL>"]
}
}],
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Describe this video:"
}
]
},
{
"role": "user",
"content": [
{
"type": "acv_document_id",
"acv_document_id": "<your_video_ID>"
}
]
}
]
}
参考
- ビデオで Vision 拡張機能を使用する
- Video Retrieval: GPT-4 Turbo with Vision Integrates with Azure to Redefine Video Understanding
- Azure OpenAI Service REST API reference
- ほぼリアルタイムでビデオを分析する
- ベクトル化を使用してビデオ検索を行う (バージョン 4.0 プレビュー)
- Shared Access Signatures (SAS) を使用して Azure Storage リソースへの制限付きアクセスを許可する
おわりに
今後はマルチモーダルモデルの活用シナリオ検討がはかどりそうです。
以上です。🍵

Discussion