はじめまして!0017-altという名前でZennの投稿を始めようと思います。
現在、日本マイクロソフトでCloud Solution Architectとして2カ月間インターンをしており、その中で一番面白いなと思ったAzureのサービス「Azure AI Search」についてご紹介できればと思っています。
ちなみに、この記事の内容は第8回JAZUG for Womenでお話をしたものです。楽しかった😊
Azure AI Searchについて
そもそもAzure AI Searchってなんだっけ? Microsoft Docsには以下のように書いてありました。
Azure AI Search は、異種コンテンツのインデックスを作成し、API、アプリケーション、AI エージェントを使用した取得を可能にするスケーラブルな検索インフラストラクチャです。 このプラットフォームは、Azure の AI スタック (OpenAI、AI Foundry、Machine Learning) とのネイティブ統合を提供し、サードパーティとオープンソースのモデル統合のための拡張可能なアーキテクチャをサポートします。
このサービスは、会話型 AI アプリケーションの従来の検索ワークロードと最新の RAG (検索拡張生成) パターンの両方を処理します。 これにより、エンタープライズ検索シナリオだけでなく、チャット完了モデルによる動的なコンテンツ生成を必要とする AI を利用したカスタマー エクスペリエンスにも適しています。
参考: https://learn.microsoft.com/ja-jp/azure/search/search-what-is-azure-search
ということで、どう上手く情報を検索をするか?というサービスなんですね🔍
RAGなどのシステムを構築するときに使えるものです。
Azure AI Searchの検索手法
大きく分けて5つあります。
- ベクトル検索:コンテンツをベクトル化・インデックス化し、クエリベクトルに最も類似したベクトルを取得する形で情報を検索
- フルテキスト検索:インデックスに格納されたプレーンテキストと照合する形で情報を検索
- マルチモーダル検索:テキスト・画像・ビデオ・オーディオなど、複数のコンテンツタイプ間で情報を検索
- エージェント検索:LLM を使って複雑な質問をいくつかのサブクエリに分割し、並列で実行。検索した情報を意味の近い順にランク付けし、LLM の回答生成に使用
- ハイブリッド検索:ベクトル検索とフルテキスト検索の合わせ技
ちなみに、ハイブリッド検索が一般的には最も精度がよいそうです。コミュニティのブログでは、以下のようなベンチマーク評価結果が掲載されており、ハイブリッド手法とさらにセマンティックランキング(後述)をしようしたものは精度が最も良いそうです。
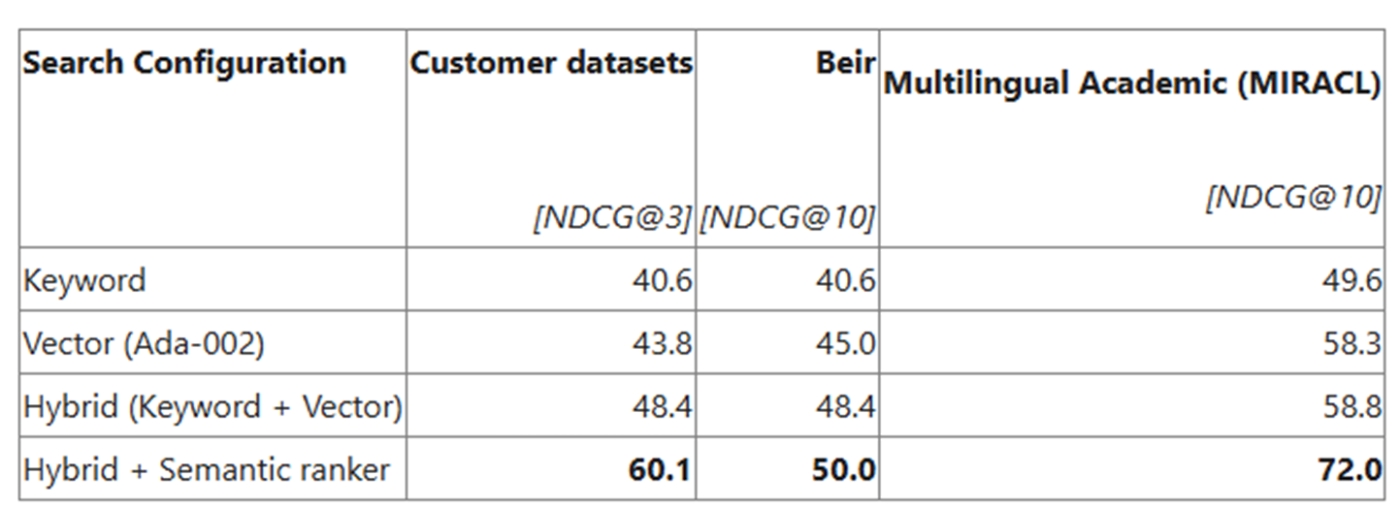
参考:https://techcommunity.microsoft.com/blog/azure-ai-foundry-blog/azure-ai-search-outperforming-vector-search-with-hybrid-retrieval-and-reranking/3929167
内部の仕組み
ユーザーはあらかじめPDFなどのドキュメントをストレージやデータベースに用意しておきます。それを、AI Searchはインデックス化してくれて、できたインデックスを検索していくというのが主な流れです。
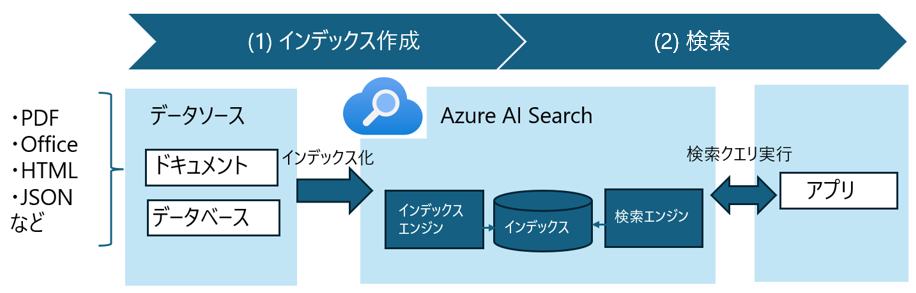
インデックス化
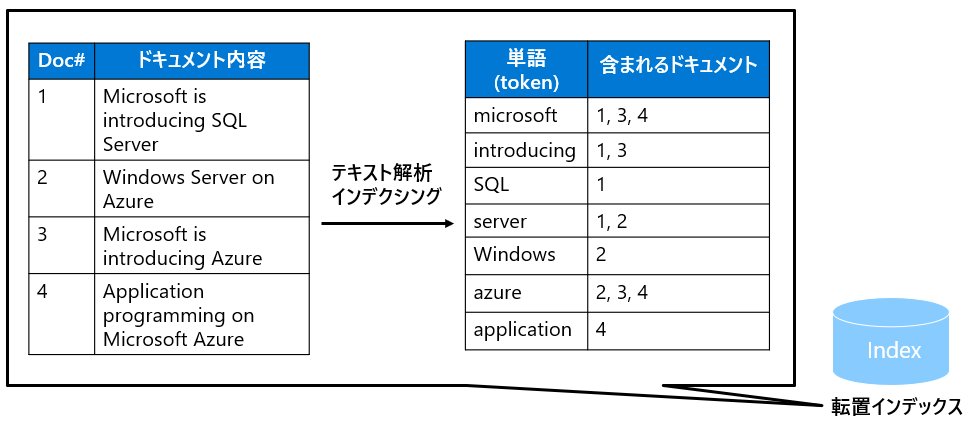
インデックス化の過程では、まずファイルやメタファイルからテキストを抽出し、それを転置インデックスに置くという作業が行われます。その中で、Analyzerによるテキスト解析が行われます。

転置インデックスとは、もともと「このドキュメントにはこの内容が書いてあって、このドキュメントには...」という内容のテーブルをくるっと転置して、「この単語はこのドキュメントに書いてあります!」という風に書き換えたものです。
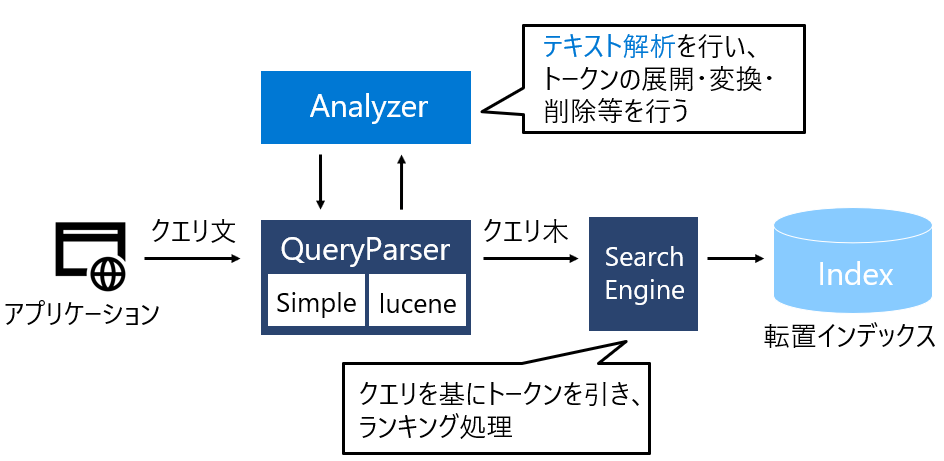
検索
ここまででインデックスはできたので続いて検索をしていくわけですが、さきほどのインデックスと似ています。ユーザーのクエリ文をパースし、それをもとにSearch Engineが転置インデックスを引きに行くということをします。
Search Engineは、クエリ文との類似度スコアの高いドキュメントを順番に返していく、ということをするのですが、そこをどううまくするのか?!というのが一番面白いところです。もっと深堀してみましょう🏖
スコアのつけ方
スコアは2段階に分けてつけられます。「L1ランキング」→「L2ランキング」という順番です。それぞれ以下のようなものがあります。
- L1ランキング
- BM25
- HNSW
- RRF
- L2ランキング
- セマンティックランキング
「L1ランキング」だけでスコアリングを返すこともできますが、そうすると比較的シンプルな類似度を考えることになります。L1ランキングの結果を踏まえてL2ランキングを行うと、より意味論的関連度に基づいた類似度を得られるんですね。
それぞれどう組み合わせるとどういう検索手法になるのかということを、以下にまとめました。

以下で、具体的なスコアリングの方法についてみていきましょう。詳細なアルゴリズム自体の説明はそれ専用の記事や本に譲るとして、ここではゆるく気持ちだけ説明していきます。
BM25
これはフルテキスト検索で使われる手法で、一言でいうと「クエリと文書の類似度を求める」というものになります。
うわーん数式だーと思ってもいったん逃げないでください🥺
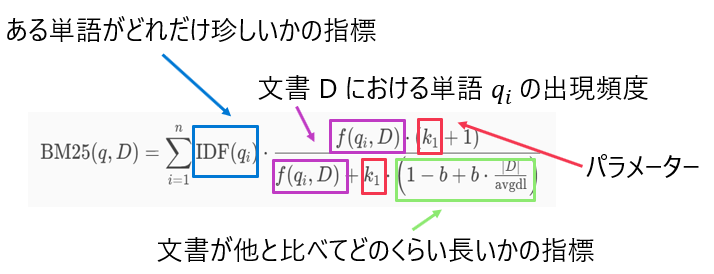
色を付けて見やすくしました。ポイントは3点です!
- 紫色の項(
f(q_i,D) - 文章が長いほどいろんな単語が一般的には出てくるので、↑の紫色の項が影響を受けてしまうことが考えられます。そこで、文書の長さを表す指標である緑色の項 (
(1-b+b \cdot \frac{|D|}{\text{avgdl}}) - また、
k, b
このように、いろいろ工夫が詰まったこのアルゴリズム、"BM"というのは"Best Matching"の略だそうです。たしかに良くマッチングするものを検索できそう😍
HNSW
続いてベクトル検索に使われているアルゴリズムです。一言でいうと、「近似最近傍探索 (ANN) を高速・高精度に実現」できます。ベクトル検索ではeKNNという手法も使われていますが、ここではHNSWのみ紹介します。
ちなみに、HNSWは"Hierarchical Navigable Small World"の略だそうですが、Small Worldってあまりにもかっこいい、、、!(ここでIt's a small worldを聞く)
このアルゴリズムは「グラフ構築」「グラフ探索」の2ステップに分かれていますが、私の推しは「グラフ構築」です。
グラフ構築
まずは一番下のレイヤー (Layer 0)にはすべてのノード (各ドキュメントをベクトルで表したもの)が載っています。各ノードは、類似度の高いもの上位一定数がエッジでつながれている状態です。
ここからレイヤーを上げていくのですが、あるレイヤーが1つ上のレイヤーに載る確率は
面白いのは、このように確率的にいろいろ操作をしても上手くいくということです!言語モデルもそうですが、確率的になにかをしてもなぜかうまくいく...というお話はかなり胸躍りませんか??💃

参考: https://www.pinecone.io/learn/series/faiss/hnsw/
グラフ探索
ここまで来たらグラフを探索します。探索は構築とは逆で、レイヤーの上から下へ下がっていきます。
まず、ユーザーのクエリをベクトル化して、一番上のレイヤーで最も類似度の高いノードを取得し、そこからエッジをたどってどんどん下のレイヤーへ降りていく...ということをします。
すると、はじめは大まかに探索してそこからだんだん細かく見ていくということができて、高速なのに高精度!という探索が可能になるのです!すごい!!
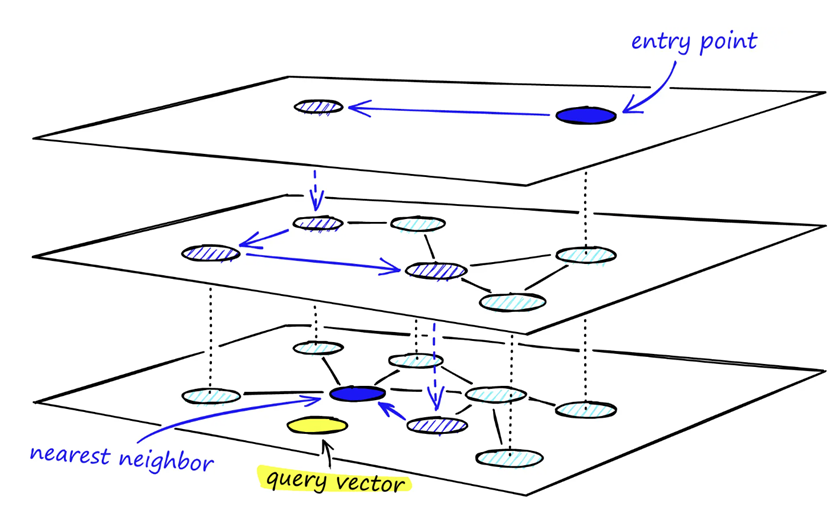
参考: https://www.pinecone.io/learn/series/faiss/hnsw/
RRF
ハイブリッド検索についてです。たとえばフルテキスト検索とベクトル検索のハイブリッドだと、既にスコアが2つある状態です。ここでどう複数のスコアを組み合わせるのか?というのがこのRRFのコンセプトです。
アルゴリズムはシンプルで、ユーザーが定めたパラメータと各ランキング結果を足して逆数の足し算をしますよーというもの。

セマンティックランキング
この手法は、「L1ランキングの結果に対し、意味的な関連性に基づく再評価を行う」というものです。
具体的には以下のステップに従います。
- L1ランキングの結果から上位50件の結果のみ収集
- 各ドキュメントを2,048トークン以内に要約・切り取り
- Microsoft Bingに使われるDeep Learningモデルを使用して各ドキュメントにスコア付け
- スコアの高い順に返す
こちらも中身はブラックボックス化されていますが、これで意味的に関連ある項目を検索できるなんて素敵...!🤩
補足:マルチモーダル検索について
マルチモーダル検索は音声・動画・画像の検索があり難しそう...ですが、実はここまでで紹介した手法を押さえておけば大丈夫です。
- ドキュメントから画像とテキストを抽出
- 画像のキャプションを作成
- テキストと画像の両方を共有ベクター空間に埋め込み
- 後で注釈として使用するためにイメージも保存
- フルテキスト/ベクトル/ハイブリッドいずれかの検索を実行
という流れで行われるのですが、基本的には「テキスト以外のものはキャプションをつけて、そのキャプション (=テキスト)をフルテキスト/ベクトル/ハイブリッド検索する!」ということなんです!
デモ
AI Searchのさまざまな手法を試すことができるレポジトリを公開しました。
どんな検索手法を入れようかな...と迷ったのですが、Azure OpenAI On Your Dataで提供されている5つの手法の名前をお借りして、オリジナルに実装しています (On Your Dataの実際の実装はどこにも見つからなかった...)。
ちなみに、ここでは検索するドキュメントとして
- それなりの量があって
- 意味的に関連していて
- 公開しても問題なさそう
なものを頑張って探して、docs/配下に源氏物語から「桐壺」~「雲隠」を入れています!
azd upでデプロイが完了したら、源氏物語に関する何かを検索してみてください。ドキュメントを変えたい場合はdocs/の配下に好きなものを入れてください。デプロイ時にドキュメントをアップロードできます。
たとえば、以下のような例があります。
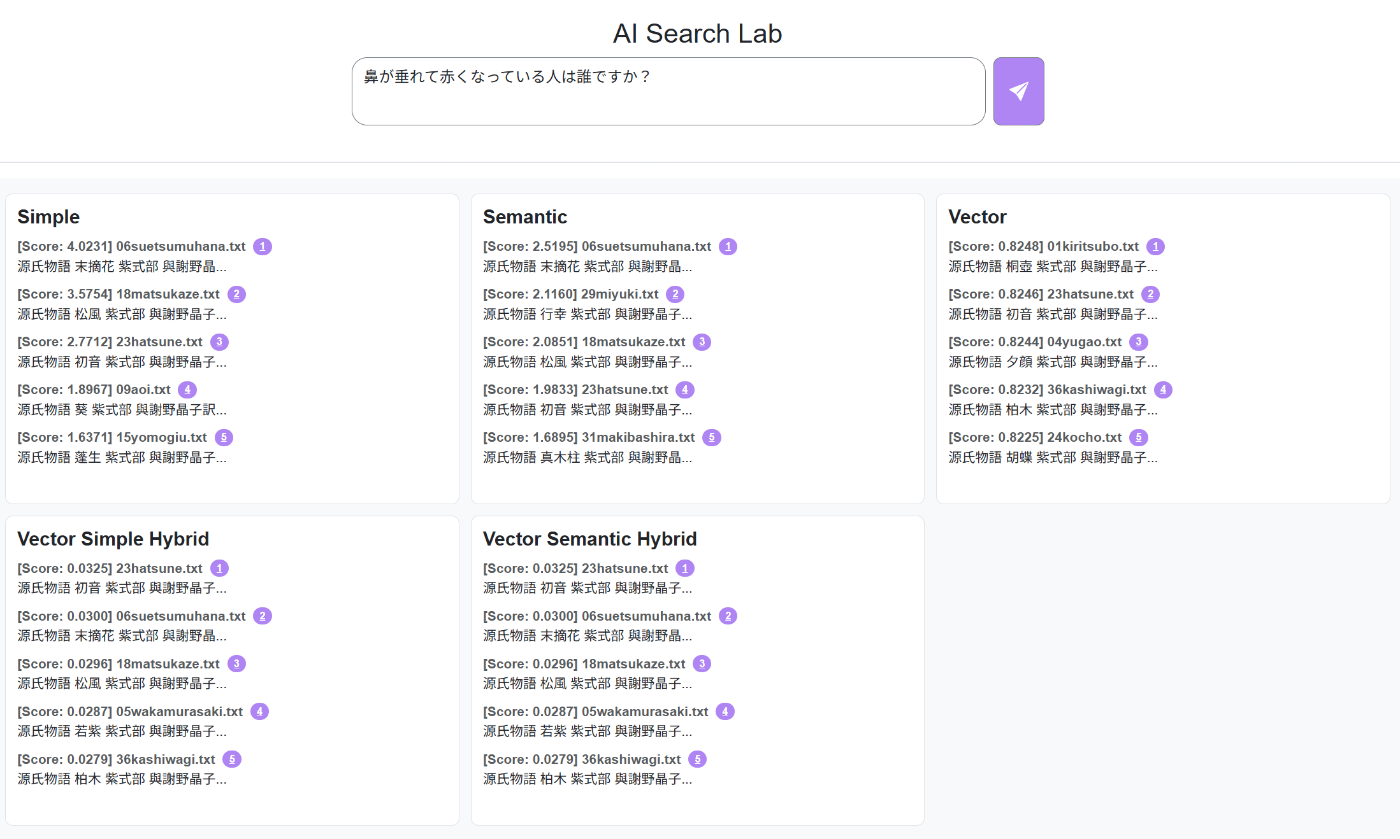
これは末摘花について聞きたかったのですが、確かに「末摘花」「初音」など末摘花が出てきそうなところが検索できていそうです。どれがベストかというのは正直わからないのですが...
こういう形で遊んでみてください。
まとめ
Azure AI Searchには5つの手法があります。
- ベクトル検索
- フルテキスト検索
- マルチモーダル検索
- エージェント検索
- ハイブリッド検索
ぜひいろいろ組み合わせて試してみてください✨組み合わせはスタバのカスタムよりも奥深いはず(?)です☕
読んでいただいてありがとうございました!

Discussion