はじめに
Sentinel data lake は、低コストで大量のログを格納・分析できる新しいサービスです。Defender ポータルでは data lake に対して KQL クエリによる対話的なログ検索が提供されていますが、UI の使い勝手やクエリの行数・データ量・タイムアウト制限など、いくつかの課題や制約がありました。
一方、Visual Studio Code (VSCode) の Sentinel 拡張機能を利用することで、Jupyter Notebook を使ったより柔軟なログ検索が可能となり、タイムアウトも最大 2 時間まで拡張されます。本記事では、VSCode 上での対話的なログ検索方法について確認していきます。
初期設定
初期設定の詳細は、以下の公式ドキュメントをご参照ください。
試してみる
まずはモジュールを読み込みます。
from sentinel_lake.providers import MicrosoftSentinelProvider
data_provider = MicrosoftSentinelProvider(spark)

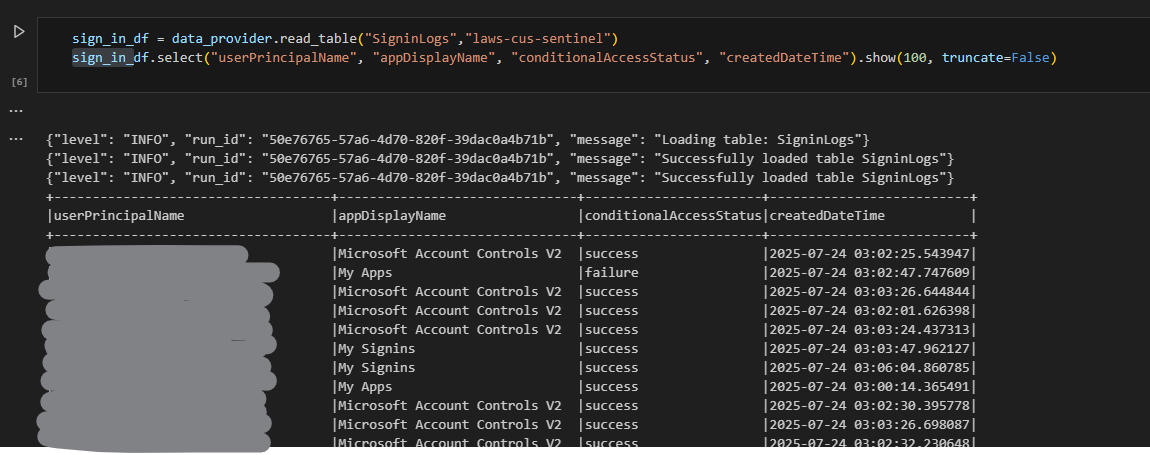
次に、SigninLogs を取得します。
sign_in_df = data_provider.read_table("SigninLogs","laws-cus-sentinel")
sign_in_df.select("userPrincipalName", "appDisplayName", "conditionalAccessStatus", "createdDateTime").show(100, truncate=False)
結果を markdown 形式で出力する例です。
from IPython.display import display, Markdown
# 結果をPandas DataFrameに変換し、Markdown形式で表示
sign_in_pd = sign_in_df.select("userPrincipalName", "appDisplayName", "conditionalAccessStatus", "createdDateTime").toPandas()
markdown_table = sign_in_pd.to_markdown(index=False)
display(Markdown(markdown_table))

GitHub Copilot の活用
公式ドキュメントにも記載されていますが、GitHub Copilot を利用することで、Jupyter Notebook 内でのコード生成やエラー修正が容易になります。
[Generate] をクリックしてコードを生成します。
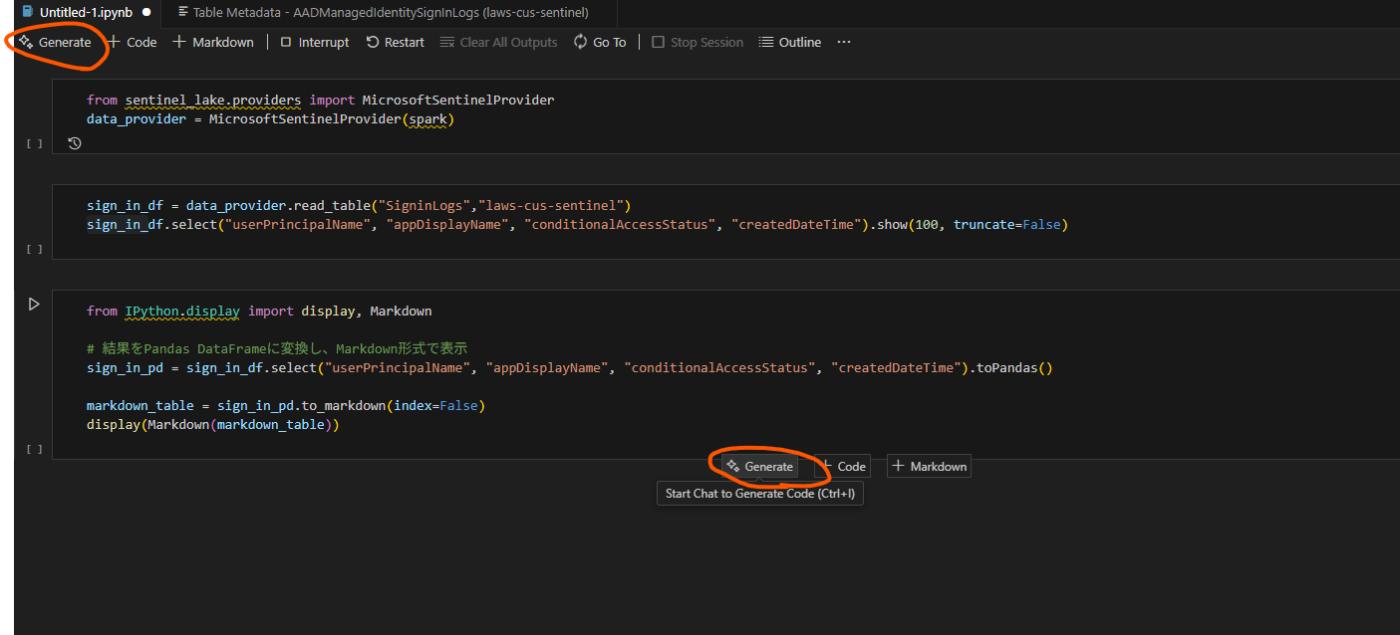
検索したい内容を記入し、実行後 [Accept] をクリックします。
Azure のアクティビティログから仮想マシンに関する操作を抜き出してください


言語指定がない場合は セル右下の言語選択で Python を明示的に指定して実行します。

エラーが発生したため、Copilot に修正を依頼します。

他の箇所でも同様にエラーが出たため、都度修正を依頼します。
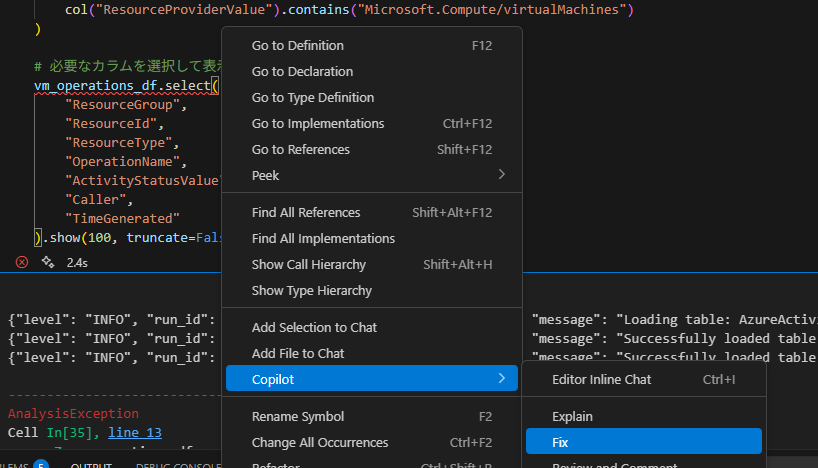

正常に実行できても結果が取得できないため、一覧出力してフィルタ条件を確認し、再修正を依頼します。
ResourceProviderValue ではなく、OperationNameValue を使って大文字小文字区別なくフィルタ出来るようにしたい

最終的に意図した結果が得られます。

別のシナリオでも試してみます。
Entra のサインインログでログイン失敗の件数を1週間分集計し、1時間ごとの件数をグラフで表示してください。その際、異常値と思われる箇所は赤くマークを付けて分かるようにしてください。


以下のように表示できます。(検証環境のため、ログイン失敗件数が少なくあまり参考になりませんが)
日本語のタイトルは文字化けしています。

すべてのサインインログを対象とした場合の例です。

いくつか動作確認しましたが、テーブル構成やスキーマの情報が求められるコードの生成はミスが多いように思います。そのため、このあたりはエラー内容を確認できるスキルが求められます。
一方で、グラフ描画や数値処理のコード生成の正確性は高い印象です。
Notebook ジョブの作成
作成した Jupyter Notebook をジョブとして定期実行することも可能です。
設定手順は以下の通りです。
- エクスプローラーで Jupyter Notebook を格納したフォルダを開く
- Jupyter Notebook ファイルを開き、認証する
- Jupyter Notebook ファイルを右クリック > [Microsoft Sentinel] > [Create Scheduled Job] を選択
作成した Notebook をジョブとして設定し、右上の [Publish Job] をクリックします。
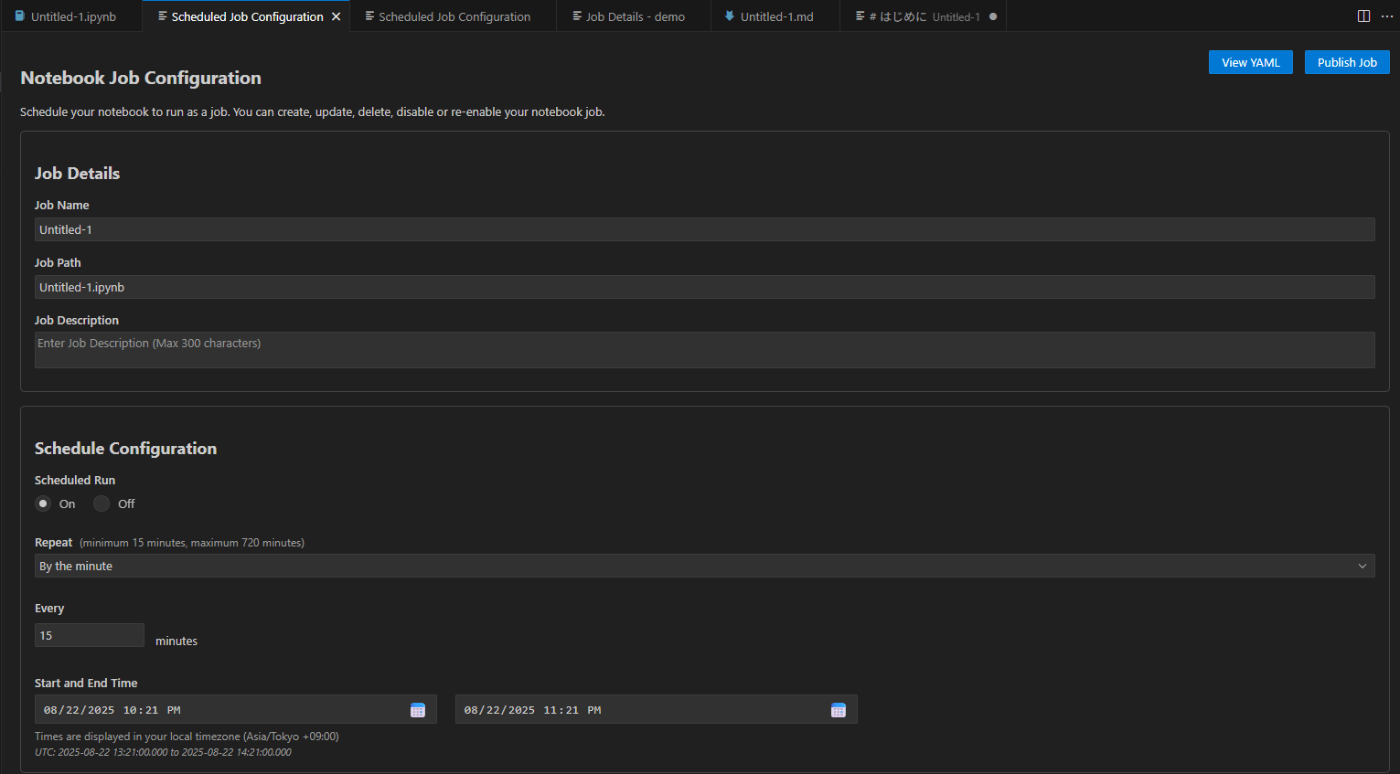
Sentinel 拡張機能の [JOBS] 欄に表示されます。

Defender ポータル側にも表示されます。

実行後、結果が確認できます。
Notebook では新規テーブル作成や既存テーブルへの追記による検索結果の保存ができるため、このような処理の自動化に使用することが主なシナリオと考えられます。


(参考) テーブルへの書き込み
詳細は公式ドキュメントをご参照ください。
Analytics 層や data lake 層のテーブル作成・書き込みが可能で、default ワークスペースにも作成できます。
以下は Azure アクティビティの検索結果をテーブルに保存する例です。エラーが出たため、列名のリネーム処理を GitHub Copilot で修正・追加しています。これらは Spark SQL の規則に従うためのものです。
from pyspark.sql.functions import col
# Azure のアクティビティログから仮想マシンに関する操作を抽出
activity_log_df = data_provider.read_table("AzureActivity", "laws-cus-sentinel")
# 仮想マシンに関する操作をフィルタリング
vm_operations_df = activity_log_df.filter(
col("OperationNameValue").rlike("(?i)virtualmachines")
)
# 必要なカラムを選択して表示
selected_columns = [
"ResourceGroup",
"OperationNameValue",
"ActivityStatusValue",
"Caller",
"TimeGenerated"
]
vm_operations_df = vm_operations_df.select(*selected_columns)
# 列名を規則に従ってリネーム(例: 必要に応じて)
valid_col_names = [col_name if col_name[0].isalpha() and col_name.replace("_", "").isalnum() else f"col_{i}"
for i, col_name in enumerate(vm_operations_df.columns)]
rename_exprs = [col(old).alias(new) for old, new in zip(vm_operations_df.columns, valid_col_names)]
vm_operations_df = vm_operations_df.select(*rename_exprs)
vm_operations_df.show(100, truncate=False)
# テーブルに保存
data_provider.save_as_table(vm_operations_df, "VMOpsEvents_SPRK", "default")
# テーブルに追記
# write_options = {
# 'mode': 'append'
# }
# data_provider.save_as_table(vm_operations_df, "VMOpsEvents_SPRK", write_options=write_options)
default ワークスペースにテーブルが作成され、Defender ポータルでも確認できます。


コスト
Kernel のサイズと動作時間によってコストが決まります。
高度なデータ分析情報の料金は、データ レイク探索ノートブック セッションを使用するか、データ レイク探索ノートブック ジョブを実行するときに使用されるコンピューティング時間ごとに発生します。コンピューティング時間は、ノートブック用に選択されたプール内のコア数と、セッションがアクティブであったかジョブが実行されていた時間を乗算して計算されます。
https://learn.microsoft.com/ja-jp/azure/sentinel/billing?tabs=simplified%2Ccommitment-tiers#data-lake-tier
Tips
-
右側のテーブル一覧からスキーマを確認できます。

-
Kernel の切り替えは右上のプールから可能で、セッション開始まで 3~5 分かかります。

-
時間が空くと認証エラーが出る場合があるため、その際は左側のテーブルを再読み込みしてください。

まとめ
VSCode 拡張機能と Jupyter Notebook を活用することで、Sentinel data lake のログ検索が柔軟かつ効率的に行えます。GitHub Copilot を組み合わせることで、Python や Notebook の知識がなくても操作しやすくなります。コンピューティング課金は発生しますが、KQL クエリよりも高度な分析に適している印象です。

Discussion