
本記事の概要
Azure OpenAI Service の gpt-4o-realtime-preview についての解説とVoiceRAGのハンズオンを行います。
- Voice RAGへDeepDive
Azure OpenAI Service の gpt-4o-realtime-preview について
2024年10月1日にOpenAI社からgpt-4o-realtime-previewというパブリックベータ版がリリースされました。
音声とオーディオ用 Azure OpenAI GPT-4o Realtime API は、GPT-4o モデル の一つであり、speach to speachという音声で入力し、音声で出力することができます。 (すごいですよね)
今までだと、ユーザの音声をSpeach to Textの機能を使ってテキストに変換し、OpenAIのAPIにリクエストを送り、その結果をText to Speechを用いて音声に変換していました。
アーキテクチャにするとこんな感じ。
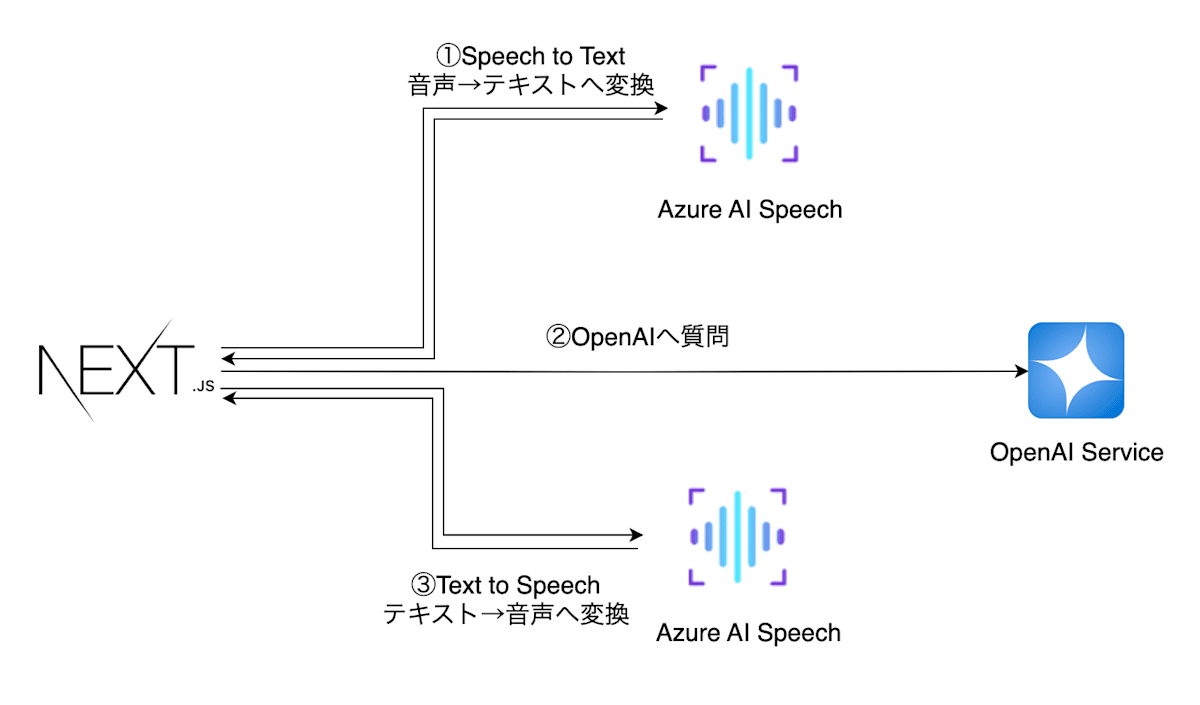
これでもなかなかのスピードが出せていたのですが、やはり生成AIと会話している感じが出ているなぁという感じでした。
今回、このgpt-4o-realtime-previewを使うと、人との会話スピードを実現出来るどころか、食い気味で会話してくれます。
アーキテクチャとしてはこんな感じです。

本記事では、gpt-4o-realtime-previewの基本的な知識と共に、VoiceRAGのハンズオンを行います🚀
まずは、Azureでのgpt-4o-realtime-previewについて詳しく見ていきましょう。
サポートされていいるバージョンと地域
現在 gpt-4o-realtime-preview はバージョン:2024-10-01-preview のみでサポートされています。
gpt-4o-realtime-preview モデルは、East US2 とSweden Centralのグローバル デプロイで使用できます。
日本にも早くきてほしいですね...!!
モデルの制限について
token数の入力と出力、最新のトレーニングデータの学習日は以下の通りです。
| モデル ID | 説明 | 最大要求 (トークン) | トレーニング データ (最大) |
|---|---|---|---|
| gpt-4o-realtime-preview (2024-10-01-preview) | GPT-4o audio リアルタイム オーディオ処理のためのオーディオ モデル | 入力: 128,000 出力: 4,096 |
2023年10月 |
リアルタイム オーディオ (gpt-4o-realtime-preview) の現在のレート制限は、1 分あたりの新しい Websocket 接続の数として定義されます。
例えば、1 分あたり 6 要求 (RPM) は、1 分あたり 6 つの新しい接続を意味します。 Websocketの接続にて1分あたり6つの接続が可能ということですね。
現時点ではプレビュー版なので、gpt-4o-realtime-preview の使用は新機能開発の為に使うのが良いですね。
気になるコスト
RealTime APIのコストは以下の通りです。
| Model | Type | Pricing (1M Tokens) |
|---|---|---|
| GPT-4o-Realtime-Preview-Global | Text | Input: ¥767.4001 Output: ¥3,069.600004 |
| Audio | Input: ¥15,348.0001 Output: ¥30,696.000031 |
こちらだけ見ると、1M tokenって約100万~150万文字程度とされているので、それだったらこんなもんなのかなと思いきや、GPT-4oと比較してみましょう。
| Model | Pricing (1M Tokens) | Pricing with Batch API (1M Tokens) |
|---|---|---|
| GPT-4o-2024-08-06 Global | Input: ¥383.70001 Cached Input: ¥191.8501 Output: ¥1,534.8001 |
Not Specified |
同じ1MでもGPT-4o-Realtime-Preview-GlobalのAudioだとなかなかいいお値段しますね。
これぐらいの価格でもリアルタイム性を追求したい!というスピード狂の方に是非おすすめしたいモデルとなっております。
VoiceRAG
基本的な概念について
gpt-4o-realtime-previewと掛け合わせて音声でのRAGアーキテクチャも構築出来ます。
通常、RAGアーキテクチャだと返答までに時間がかかるのですが、gpt-4o-realtime-previewを使うことで、RAGを使ってもかなりリアルタイム性を追求した会話が可能です。
今回、ハンズオンする構成は以下になります。
アプリケーションの大まかな流れは以下の通りです。

- デバイスのマイクで音声入力を取得
- 取得した音声をバックエンドにリアルタイムで送信
- Azure OpenAI GPT-4o Realtime APIで入力音声をテキストに変換
- Azure AI Searchを使用してナレッジベースから関連情報を検索
- 検索結果があればGPT-4o Realtime APIに送信し、応答音声(とテキスト)を生成
- 生成された音声をリアルタイムにブラウザから出力
サーバサイドにはAPIとして、/realtime と /chat/completions の2つのエンドポイントがあります。
このプレビューでは、モデル ファミリ/realtimeの新しい API エンドポイントが導入されています。
低遅延の「音声入力、音声出力」会話インタラクションをサポートされており、テキストメッセージ、関数ツールの呼び出し、および他のエンドポイントからの多くの既存の機能と連携します。exdpointは /chat/completions
また、サポートエージェント、アシスタント、翻訳者、およびユーザーとの高度な応答性を必要とするその他のユースケースに最適です。
/realtimeは、エンド ユーザーとモデル間の完全に非同期のストリーミング通信を容易にするためにWebSocket API上に構築されています。
エンド ユーザーへの接続とモデル エンドポイント接続の両方を管理する、信頼できる中間サービスのコンテキストで使用するように設計されています。
信頼できないエンド ユーザー デバイスから直接使用するようには設計されておらず、オーディオ データのキャプチャやレンダリングなどのデバイスの詳細は、API の範囲外となります。
概要レベルでは、その上に構築されるエクスペリエンスのアーキテクチャは/realtime次のようになります (前述のように、ユーザー インタラクションは API 自体の一部ではないことに注意してください)。
接続と認証について
API/realtimeには、サポートされているリージョンに既存の Azure OpenAI リソース エンドポイントが必要です。完全な要求 URI は、以下を連結して作成できます。
- セキュアなWebSocket(wss://)プロトコル
- Azure OpenAIリソースエンドポイントのホスト名、例:my-aoai-resource.openai.azure.com
- APIopenai/realtimeパス
- api-versionサポートされているAPIバージョンのクエリ文字列パラメータ(最初は、2024-10-01-preview
- モデル展開deploymentの名前を含むクエリ文字列パラメータgpt-4o-realtime-preview
完全な例にまとめると、次の/realtimeリクエスト URI は適切に構築されます。
wss://my-eastus2-openai-resource.openai.azure.com/openai/realtime?api-version=2024-10-01-preview&deployment=gpt-4o-realtime-preview-1001
上記を認証するにはどのように構築するか
- Microsoft Entra の使用:/realtimeマネージド ID が有効になっている適切に構成された Azure OpenAI サービス リソースに対するトークンベースの認証をサポートします。取得した認証トークンを適用するには、ヘッダーBearer付きのトークンを使用しますAuthorization。
- API キーの使用:api-key次の 2 つの方法のいずれかで提供できます。
- ハンドシェイク前の接続で接続ヘッダーを使用するapi-key(注: ブラウザ環境では使用できません)
- api-keyリクエスト URI でクエリ文字列パラメータを使用する(注: https/wss を使用する場合、クエリ文字列パラメータは暗号化されます)
APIの概念
APIの /realtimeは以下の概念に基づいて構築されています。
- websocketの接続を確立し/realtime、新しいsessionを作成します。
- session入力と出力のオーディオの動作、音声アクティビティ検出動作、その他の共有設定をカスタマイズするように構成できます。
- sessionをデフォルトで自動的に作成します。
- 注: 将来的には複数の同時会話がサポートされる可能性がありますが、現在は利用できません。(※現在の制限は6接続まで)
- 発信者による直接のコマンドまたは音声アクティビティベースのターン検出によって自動的に開始されるconversationまで入力信号を蓄積します。
- それぞれはresponse1つ以上ので構成されitems、メッセージ、関数呼び出し、その他の情報をカプセル化できます。
- メッセージitemには がありcontent_part、複数のモダリティ(テキスト、音声)を単一のアイテムで表現できます。
- session発信者入力処理(ユーザーオーディオなど)と共通出力/生成処理の構成を管理します。
- 必要に応じて、各呼び出し元が開始したresponse.create出力動作の一部をオーバーライドできます。
- サーバーで作成されたitemとcontent_partメッセージ内の は、非同期かつ並列で取り込まれる可能性があります。たとえば、オーディオ、テキスト、および機能情報を同時に受信します。
APIの詳細
WebSocket 接続セッションが/realtime確立され、認証されると、WebSocket メッセージの送受信を介して機能的なやり取りが行われます。
ここでは、推論のために既に存在するコンテンツを含む「メッセージ」の概念との曖昧さを避けるために、「コマンド」と呼びます。
これらのコマンドはそれぞれ JSON オブジェクトの形式をとります。コマンドは並行して送受信することができ、アプリケーションは通常、コマンドを同時に、また非同期で処理する必要があります。
セッション構成とターン処理モード
多くの場合、新しく確立されたセッションで呼び出し元から送信される最初のコマンドはsession.updateになります。このコマンドは、入力と出力の幅広い動作を制御し、出力と応答の生成部分は、必要に応じて後でresponse.createプロパティを介して上書きできます。
セッション全体の重要な設定の 1 つは でturn_detection、これは呼び出し元とモデル間のデータ フローの処理方法を制御します。
- server_vadは、音声アクティビティ検出器 (VAD) コンポーネントを使用して、着信ユーザー オーディオ (経由で送信input_audio_buffer.append) を評価し、音声の終了が検出されると、そのオーディオを自動的に使用して該当する会話に対する応答生成を開始します。VAD の無音検出は、検出モードを指定するときに構成できますserver_vad。
- noneinput_audio_buffer.commitは、発信者が開始したコマンドに依存して会話を進め、出力を生成します。これは、プッシュツートーク アプリケーションや、外部オーディオ フロー制御 (発信者側 VAD コンポーネントなど) がある状況で役立ちます。これらの手動信号は、VAD が開始した応答生成を補足するために、モードresponse.createでも使用できることに注意してください。server_vad
ユーザー入力オーディオの文字起こしは、 プロパティを介してオプトインされますinput_audio_transcription。この構成で文字起こしモデルを指定すると、イベントwhisper-1の配信が有効になります。conversation.item.audio_transcription.completed
session.updateツールを含むセッションのいくつかの側面を構成する例を次に示します。すべてのセッション パラメータはオプションであり、すべてを構成する必要はありません。
ちなみに、session.updateは以下のようなリクエスト内容になります。
{
"type": "session.update",
"session": {
"voice": "alloy",
"instructions": "Call provided tools if appropriate for the user's input.",
"input_audio_format": "pcm16",
"input_audio_transcription": {
"model": "whisper-1"
},
"turn_detection": {
"threshold": 0.4,
"silence_duration_ms": 600,
"type": "server_vad"
},
"tools": [
{
"type": "function",
"name": "get_weather_for_location",
"description": "gets the weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": [
"c",
"f"
]
}
},
"required": [
"location",
"unit"
]
}
}
]
}
}
コマンドについて
requestとresponseのコマンドについて説明します。
なかなかの量がありますが、理解すると非常に柔軟な実装が可能なので、是非チェックしてみてください。
- request : 発信者から/realtimeエンドポイントに送信されるコマンド
| リクエスト | type | 説明 |
|---|---|---|
| セッション構成 | ||
| session.update | セッション構成 | 共有オーディオ入力処理や共通応答生成特性など、会話セッションの接続全体の動作を構成します。これは通常、接続直後に送信されますが、セッション中の任意の時点で送信して、現在の応答 (進行中の場合) が完了した後の動作を再構成することもできます。 |
| 入力オーディオ | ||
| input_audio_buffer.append | 入力オーディオ | server_vad turn_detection共有ユーザー入力バッファにオーディオ データを追加します。このオーディオは、モードで音声の終了が検出されるか、マニュアルresponse.createが送信されるまで (どちらの構成でも) 処理されませんturn_detection。 |
| input_audio_buffer.clear | 入力オーディオ | 現在のオーディオ入力バッファをクリアします。これは、すでに進行中の応答には影響しないことに注意してください。 |
| input_audio_buffer.commit | 入力オーディオ | ユーザー入力バッファの現在の状態をサブスクライブされた会話にコミットし、次の応答の情報として含めます。 |
| アイテム管理 | 履歴を確立したり、音声以外のアイテム情報を含めたりする場合 | |
| conversation.item.create | アイテム管理 | 会話に新しい項目を挿入します。オプションで に従って配置されますprevious_item_id。これにより、ユーザーからの新しい非音声入力 (テキスト メッセージなど)、ツールの応答、または別のインタラクションからの履歴情報を提供して、生成前に会話履歴を形成できます。 |
| conversation.item.delete | アイテム管理 | 既存の会話からアイテムを削除します |
| conversation.item.truncate | アイテム管理 | メッセージ内のテキストや音声コンテンツを手動で短縮します。これは、リアルタイムよりも高速なモデル生成によって重要な追加データが生成されたが、後で中断によってスキップされたような状況で役立つ場合があります。 |
| レスポンス管理 | ||
| response.create | レスポンス管理 | 未処理の会話入力のモデル処理を開始し、発信者の論理ターンの終了を示します。server_vad turn_detectionモードは、スピーチの終了時に自動的に生成をトリガーしますが、会話を続行する必要があることを通知するために、response.create他の状況 (テキスト入力、ツールの応答、noneモードなど) で呼び出す必要があります。注: ツール呼び出しに応答する場合は、すべてのツール呼び出しとその他のメッセージが提供されたことを確認するモデルからのコマンドの後にresponse.create呼び出す必要があります。response.done |
| response.cancel | レスポンス管理 | 進行中の応答をキャンセルします。 |
- response : モデルから/realtimeエンドポイントに送信されるコマンド
| 応答 | type | 説明 |
|---|---|---|
| セッション | ||
| session.created | セッション | 接続が正常に確立されるとすぐに送信されます。デバッグやログ記録に役立つ接続固有の ID を提供します。 |
| session.updated | セッション | イベントへの応答として送信されsession.update、セッション構成に加えられた変更を反映します。 |
| 発信者アイテム確認 | ||
| conversation.item.created | 発信者アイテム確認 | 新しい会話項目が会話に挿入されたことを通知します。 |
| conversation.item.deleted | 発信者アイテム確認 | 既存の会話項目が会話から削除されたことを通知します。 |
| conversation.item.truncated | 発信者アイテム確認 | 会話内の既存の項目が切り捨てられたことを通知します。 |
| 応答フロー | ||
| response.created | 応答フロー | 会話に対して新しい応答が開始されたことを通知します。 |
| response.done | 応答フロー | 会話の応答生成が完了したことを通知します。 |
| rate_limits.updated | 応答フロー | 直後に送信されresponse.done、終了したばかりの応答の消費後の更新されたステータスを反映した現在のレート制限情報を提供します。 |
| レスポンス内のアイテムフロー | ||
| response.output_item.added | レスポンス内のアイテムフロー | サーバーによって生成された新しい会話アイテムが作成されていることを通知します。 |
| response.output_item.done | レスポンス内のアイテムフロー | 新しい会話アイテムが会話への追加を完了したことを通知します。 |
| 回答項目内のコンテンツフロー | ||
| response.content_part.added | 回答項目内のコンテンツフロー | 進行中の応答の会話項目内に新しいコンテンツ部分が作成されていることを通知します。 |
| response.content_part.done | 回答項目内のコンテンツフロー | 新しく作成されたコンテンツ部分が完了したことを通知します。 |
| response.audio.delta | 回答項目内のコンテンツフロー | モデルによって生成されたバイナリ オーディオ データ コンテンツ部分に増分更新を提供します。 |
| response.audio.done | 回答項目内のコンテンツフロー | オーディオ コンテンツ部分の増分更新が完了したことを通知します。 |
| response.audio_transcript.delta | 回答項目内のコンテンツフロー | モデルによって生成された出力オーディオ コンテンツに関連付けられたオーディオ トランスクリプションの増分更新を提供します。 |
| response.audio_transcript.done | 回答項目内のコンテンツフロー | 出力オーディオの音声転写の増分更新が完了したことを通知します。 |
| response.text.delta | 回答項目内のコンテンツフロー | 会話メッセージ項目内のテキスト コンテンツ部分に増分更新を提供します。 |
| response.text.done | 回答項目内のコンテンツフロー | テキスト コンテンツ部分への増分更新が完了したことを通知します。 |
| response.function_call_arguments.delta | 回答項目内のコンテンツフロー | 会話内の項目内で表される関数呼び出しの引数に増分更新を提供します。 |
| response.function_call_arguments.done | 回答項目内のコンテンツフロー | 増分関数呼び出し引数が完了し、累積された引数全体を使用できるようになったことを通知します。 |
| ユーザー入力音声 | ||
| input_audio_buffer.speech_started | ユーザー入力音声 | ユーザーの音声の開始が検出されたことを通知します。 |
| input_audio_buffer.speech_stopped | ユーザー入力音声 | ユーザーの音声の終了が検出されたことを通知します。 |
| conversation.item.input_audio_transcription.completed | ユーザー入力音声 | ユーザーの入力オーディオ バッファの補足的な書き起こしが利用可能であることを通知します。 |
| conversation.item.input_audio_transcription.failed | ユーザー入力音声 | 入力音声の文字起こしに失敗したことを通知します。 |
| input_audio_buffer.committed | ユーザー入力音声 | ユーザーのオーディオ入力バッファの現在の状態がサブスクライブされた会話に送信されたことの確認を提供します。 |
| input_audio_buffer.cleared | ユーザー入力音声 | 保留中のユーザー オーディオ入力バッファがクリアされたことを通知します。 |
| その他 | ||
| error | その他 | セッションでデータを処理中に問題が発生したことを示します。error追加の詳細を示すメッセージが含まれます。 |
ここまででお勉強は終わりです!
次章のハンズオンで是非動くものを作っていただければと思います!!
VoiceRAG ハンズオン🚀
では、実際にハンズオンです!
以下のリポジトリをcloneしてください。
次にAzure アカウントにログインします。
azd auth login --use-device-code
envファイルを作成して環境変数を読み込みします。
azd env new
新しい azd 環境を作成します。各リソースのリージョンを選択して
azd up
Azure Portalを確認すると、以下のようなリソースが表示されます。

では、ローカル環境で動作を確認してみましょう。
以下コマンドでフロントサイド・サーバサイド両方が起動します。
./scripts/start.sh
websocketで接続され、音声通話がReadyの状態になります。

以下のローカルのURLでアクセス出来ると記載されていますね。
それではアクセスしてみましょう。
このような画面が表示されましたでしょうか。
(ちょっとデコレーションして私の経営する学習塾のサイトにしてみました)
実際に会話してみたのがこちらです。
3つの質問をしています。
- 私自身の質問 (RAGで参照するドキュメントあり)
- 佐竹塾の質問 (RAGで参照するドキュメントあり)
- RealTime apiの質問 (RAGで参照するドキュメントなし)
- 質問を途中で切断して違う質問に切り替える
このように、リアルタイム性を追求した会話が可能です。
普通の会話の応答速度はもちろん、質問を被せてもスムーズに返答してくれます。
これはすばらしい。
後は日本語が少し気になるところがあるので、そこさえなんとかなれば最高ですね。
最後に
今回はAzure OpenAI Service の gpt-4o-realtime-preview についての解説とVoiceRAGのハンズオンを行いました。
生成AIとここまで滑らかに話せる時代がきて、本当に驚きですね。
皆様のサービス開発に是非取り入れてみてください。
それでは👋
スタートアップ企業様向けのお知らせ
日本マイクロソフトでは、スタートアップ企業様向けに、ビジネスを支援するプログラムをご提供しています。
Azureの無料クレジットが最大$150,000もらえるので、是非チェックしてみてください。
参考文献

Discussion